MySQL基础篇
数据库基础
1.MySQL的命令
1.1 操作数据库
1.1.1 mysql服务的启动和停止
net stop mysql
net start mysql
1.1.2 增加新用户
grant 权限 on 数据库.* to 用户名@登录主机 identified by "密码"
权限: select,insert,update,delete
数据库:数据名后面的.的星星可以指定表
登录主机:限定登录的ip,localhost或者其他ip
1.1.3 导入.SQL
use 数据库名;
source d:/mysql.sql;
如果.sql文件中有创建数据库的操作,也可以不指定使用哪个数据库。
1.2 导出和导入数据
1.2.1 导出
mysqldump --opt rent > rent-mysql.data
即将数据库rent数据库导出到rent-mysql.data文本文件
例:mysqldump -u root -p用户密码 --databases dbname > rent-mysql.data
1.2.2 导入
mysqlimport -u root -p 用户密码 < rent-mysql.data
2. 数据类型
2.1 常用数据类型

2.2 详细数据类型
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 整数类型 | tinyInt | 很小的整数,1字节 |
| smallint | 小的整数,2字节 | |
| mediumint | 中等大小的整数,3字节 | |
| int(integer) | 普通大小的整数,4字节 | |
| bigint | 大整数,8字节 | |
| 小数类型 | float | 单精度浮点数,4字节 |
| double | 双精度浮点数,8字节 | |
| decimal(m,d) | 压缩严格的定点数, m表示数字总位数,d表示保留到小数点后d位,不足部分就添0,如果不设置m、d,默认保存精度是整型 | |
| 日期类型 | year | 年份 YYYY 1901~2155,1字节 |
| time | 时间 HH:MM:SS -838:59:59~838:59:59,3字节 | |
| date | 日期 YYYY-MM-DD 1000-01-01~9999-12-3,3字节 | |
| datetime | 日期时间 YYYY-MM-DD HH:MM:SS 1000-01-01 00:00:00~ 9999-12-31 23:59:59,8字节 | |
| timestamp | 时间戳 YYYY-MM-DD HH:MM:SS 19700101 00:00:01 UTC~2038-01-19 03:14:07UTC,4字节 | |
| 文本、二进制类型 | CHAR(M) | M为0~255之间的整数,固定长度为M,不足后面补全空格 |
| VARCHAR(M) | M为0~65535之间的整数 | |
| TINYBLOB | 允许长度0~255字节 | |
| BLOB | 允许长度0~65535字节 | |
| MEDIUMBLOB | 允许长度0~167772150字节 | |
| LONGBLOB | 允许长度0~4294967295字节 | |
| TINYTEXT | 允许长度0~255字节(0 ~ 2^8 - 1) | |
| TEXT | 允许长度0~65535字节(0 ~ 2^16 - 1) | |
| MEDIUMTEXT | 允许长度0~167772150字节(2^24 - 1) | |
| LONGTEXT | 允许长度0~4294967295字节(2^32 - 1) | |
| VARBINARY(M) | 允许长度0~M个字节的变长字节字符串 | |
| BINARY(M) | 允许长度0~M个字节的定长字节字符串 |
BOOLEAN在数据库保存的是tinyInt类型,false为0,true就是1
char是定长,varchar是变长,char存储时,如果字符数没有达到定义的位数,后面会用空格填充到指定长度,而varchar没达到定义位数则不会填充,按实际长度存储。
char长度固定,char存取速度还是要比varchar要快得多,方便程序的存储与查找;但是char也为此付出的是空间的代价,因为其长度固定,所以会占据多余的空间,可谓是以空间换取时间效率。varchar则刚好相反,以时间换空间。
3.SQL语句分类
- DDL (Data Definition Language)
- 数据定义语言,对表结构的增删改
- create,alter,drop
- DML (Data Manipulation Language)
- 数据操作语言,对表中的行数据进行增删改
- insert,delete,update等
- DCL (Data Control Language)
- grant授权,revoke撤销权限
- DQL (Data Query Language)
- select
- 查询语言
3.1 DDL 数据定义
3.1.1 建表
CREATE TABLE u_user(
USER_ID INT NOT NULL AUTO_INCREMENT COMMENT '用户ID' ,
ROLE_ID INT NOT NULL DEFAULT 2 COMMENT '角色ID' ,
USERNAME VARCHAR(90) NOT NULL UNIQUE COMMENT '用户名',
SEX VARCHAR(32) DEFAULT 2 COMMENT '性别' ,
CREATED_TIME TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' , # 默认当前时间
UPDATE_TIME TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间' , # 默认当前时间,更新也是当前时间
PRIMARY KEY (USER_ID),
FOREIGN KEY(ROLE_ID) REFERENCES u_role(ROLE_ID) #外键约束
) COMMENT = '用户名表' ENGINE=INNODB DEFAULT CHARSET=UTF8MB4; # 表注释,所用引擎,字符集
注意:
不得使用外键与级联,一切外键概念必须在应用层解决。
因为外键可能出现闭环、性能开销、扩展差!
3.1.2 删表改表
DROP TABLE IF EXISTS u_user;
改表:一是不常用,二是可视化操作更好。
3.2 DML 行数据操作
3.2.1 insert
Insert into 表名 [字段1,字段2,......] values (值1,值2,......); /*插入单条记录*/
Insert into 表名 [字段1,字段2,......] values (值1,值2,......), (值1,值2,......); /*插入多条记录*/
如果字段1,字段2省略,那么values的值一定要写全,对于有默认或者主键自增值的可以填null
3.2.2 update
update 表名 set 字段1 = 值1 where 条件;
3.2.3 delete和速删
delete from 表名 where 条件;
truncate table 表名; #快速删除且不可恢复
3.3 DCL 数据控制
–查看该用户的权限
show grants for ‘usertest’@’%’;
3.3.1 创建用于和授权
create user 'username'@'%' indentified by '密码';
grant all privileges on 数据库名.* to 'username'@'%'; #*所有表,%所有ip
3.3.2 撤销
revoke delete,insert,select,alter on mydb.* from 'username'@'%'
3.3.3 查看
show grants for 'username'@'%';
3.4 DQL 查询 (重点)
此乃天道!必须全部掌握~
3.4.1 select 模板
SELECT [ALL | DISTINCT]
字段名
FROM 表名
[left | right | inner join table_name2] #联合查询
[WHERE ...] #指定结果需满足的条件
[GROUP BY ...] #指定结果按照哪几个字段来分组
[HAVNG ...] #过滤分组的记录必须满足的次要条件
[ORDER BY ...] #指定查询记录按一个或多个条件排序
[LIMIT { [offset,]row_count | row_count OFFSET offset}]; #指定查询的记录从哪条至哪条
3.4.2 [ALL | DISTINCT]
SELECT DISTINCT 字段名1... FROM 表名
- ALL :默认值,查询所有数据。
- DISTINCT:去除重复行,只有待查询纵向所有字段重复了才会去除。
3.4.3 WHERE 条件
3.4.3.1 逻辑操作
| 操作符名称 | 语法 | 描述 |
|---|---|---|
| AND或&& | a AND b 或 a && b | 逻辑与,同时为真,结果才为真 |
| OR 或 || | a OR b 或 a ||b | 逻辑或,只要一个为真,则结果为真 |
| NOT或 ! | NOT a 或 !a | 逻辑非,若操作数为假,结果则为真 |
3.4.3.2 比较操作
| 操作符名称 | 语法 | 描述 |
|---|---|---|
| IS NULL | a IS NULL | 若a=null,真 |
| IS NOT NULL | a IS NOT NULL | 若a=null,真 |
| BETWEEN | a BETWEEN b and c | 若a∈[b,c],则结果为真 |
| LIKE | a LIKE b | _ 匹配一个字符,%匹配任意个字符 |
| IN | a IN (a1,a2,a3,…) | 若a∈{a1,a2,a3},则真 |
| REGEXP | a REGEXP b | b是正则表达式 |
3.4.4 inner join 内连接
3.4.4.1 等值连接
SELECT *
FROM table1,table2 # 等价 from table1 inner join table2
WHERE table1.字段X = table2.字段Y;
以上,先笛卡尔积,后去除无效行
# 避免笛卡尔积
SELECT *
FROM table1 join table2
on table1.id = table2.id #表连接条件
[WHERE # 筛选条件]
以上,连接时就有条件,可以避免大量笛卡尔积。
局部笛卡尔积:table1.id中有两个为110,同样table2.id也有为110,那么就会产生4条结果!
3.4.4.2 非等值连接
SELECT 字段1,字段2,....
FROM table1 join table2
on 连接条件
where table1.id between a and b;
发生笛卡尔积!
3.4.4.3 自连接
就是将自己与自己连接,一定起别名区分
SELECT 字段1,字段2,....
FROM table1 t1 join table1 t2;
on t1.id = t2.id
3.4.5 out join 外连接
3.4.5.1 左外连接
右表为主表,即使右表没有与左表与之对应,没有对应的字段显示为null
SELECT 字段1,字段2,...
FROM table1
LEFT JOIN table2
ON 条件
- 把 left 换为right 则是右外连接。
3.4.6 GROUP BY 分组
对所有数据进行分组统计。分组的依据字段可以有多个,并依次分组。
与HAVING结合使用,进行分组后的数据筛选。
GROUP BY的语句顺序在WHERE后面,ORDER BY 的前面。
通常在对数据使用计算统计的时候,会用到GROUP BY分组。
select sex
from table1
group by sex,...; #根据性别,等等来分组
- ==注意:==使用分组后,便只能 select 分组依据的字段或分组函数!!
- 因为比如按性别分组,自然有男\女,但是也只有两组,要求select 出id,那么这个id是男的谁的id?女的又是谁的id? 因此只能select 分组的依据字段或分组函数
- 如果分组的依据是唯一的,比如id,那么就不会报错!
- 分组函数一般都会和group by联合使用,所以称之为分组函数
3.4.7 分组函数
| 函数类型 | 函数名 | 描述 |
|---|---|---|
| 数学函数 | ||
| ABS() | 绝对值 | |
| CEILING() | 向上取整 | |
| FLOOR() | 向下取整 | |
| RAND() | 0~1随机数 | |
| SIGN() | 正数1,负数0 | |
| 字符串函数 | ||
| CHAR_LENGTH() | 返回字符串中包含的字符数 | |
| CONCAT() | 合并字符串,参数可有多个,用逗号隔开 | |
| INSERT() | 替换字符串,从某个位置开始,替换某个长度如: INSERT(‘我爱课工场’,1,3,‘很爱’) | |
| LOWER() | 变小写 | |
| UPPER() | 变大写 | |
| LEFT() | 从左边截取几位,如:LEFT(‘你好’,2) | |
| RIGHT() | 从右边截取几位 | |
| REPLACE() | 替换指定字符,如:REPLACE(‘欢迎你,你好’,‘你’,‘你好’) | |
| SUBSTR() | 截取,从哪个位置开始截取,截取多长如:SUBSTR(‘课工场欢迎你’,1,3) | |
| REVERSE() | 反转字符串 | |
| 日期和时间函数 | ||
| CURRENT_DATE() | 等同于 CURDATE() 获取当前日期 | |
| CURRENT_TIMESTAMP() | 获取时间戳 | |
| NOW() | 获取当前日期和时间 | |
| YEAR(NOW()) | 年 | |
| MONTH(NOW()) | 月 | |
| DAY(NOW()) | 日 | |
| HOUR(NOW()) | 小时 | |
| MINUTE(NOW()) | 分钟 | |
| SECOND(NOW()) | 秒 |
3.4.8 HAVING 再筛选
- 在GROUP BY分组之后并select选择完成,再进行条件筛选。
- 可选条件规则与WHERE一致。
- GROUP BY执行之后便是轮到了HAVING,因此WHERE中不能使用分组函数。
3.4.9 ORDER BY 排序
对查询结果排序
- 升序(默认):ASC
- 降序:DESC
select * from table ORDER BY 列名1[,列名2,...] ASC/DESC
3.4.10 LIMIT 分页
-
显示n行
select * from table limit n; -
每页显示pageSize条记录,第pageNO页
#limit n m ; n为起始行,m为偏移量 limit (pageNO-1)*pageSize , pageSize
3.4.11 子查询
即查询sql的嵌套.
典型应用:分组函数的使用,将复杂查询语句化简。
#查找最高分的学生姓名
select name
from table
where score =
(select max(socre) from table )
4. 事务
4.1 事务四个特性
- ACID
- 原子性
- 原⼦性是指事务是⼀个不可分割的⼯作单位,事务中的操作要么都发⽣,要么都不发⽣。
- 一致性
- 一致性的意思是指数据库一直处于一致的状态,在事务开始前是一个一致状态,事务结束后是另一个一致状态。
- 独立性
- 独立性是指并发的事务之间不会受到互相影响,相对而言是独立的个体。
- 持久性
- 持久性的指的是一旦事务提交后,所做的修改将会被永久保存在数据库中,不会丢失。
4.2 事务的四种粒度
- 读未提交
- 事务A可以读取事务B尚未提交的数据。
- 脏读
- 读已提交
- 即事务B尚未提交时,事务A读取的还是原来的值,哪怕事务B已使用update。一旦事务B提交了,事务A读到的数据就改变了。
- 不可重复读
- 可重复读
- 事务A可以读一数据,不管事务B对该数据的怎么写,提交还是未提交
- 事务B可以对表插入多行数据,但是事务A却能够查到事务B新插入的数据。
- MySQL 的的 InnoDB 引擎默认的隔离级别。
- 幻读。
- 序列化读
- 最高级别隔离,排队执行事务。
4.3 MySQL 如何实现事务隔离
4.3.1 排它锁&共享锁
读的时候加共享锁,也就是其他事务可以并发读,但是不能写。
写的时候加排它锁,其他事务不能并发写也不能并发读。
4.3.2 可重复读
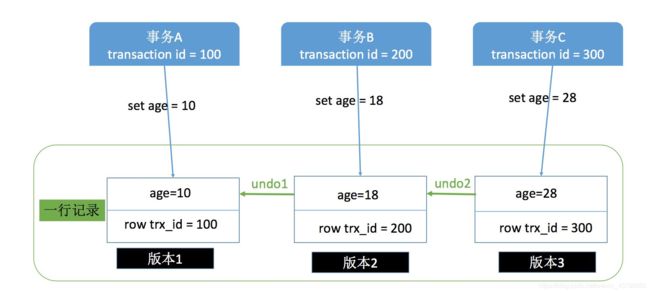
可重复读是在事务开始的时候生成一个当前事务全局性的快照,所以可以读到原来的值而不改变,而读提交则是每次执行语句的时候都重新生成一次快照。
4.3.3 并发写问题
假设事务A执行 update 操作, update 的时候要对所修改的行加行锁,这个行锁会在提交之后才释放。而在事务A提交之前,事务B也想 update 这行数据,于是申请行锁,但是由于已经被事务A占有,事务B是申请不到的,此时,事务B就会一直处于等待状态,直到事务A提交,事务B才能继续执行,如果事务A的时间太长,那么事务B很有可能出现超时异常。
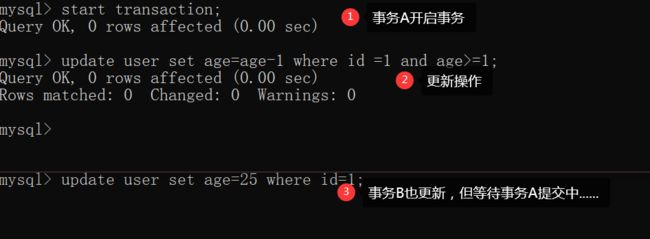
重点!!
- 所以在java当中,我们不应该在java中select出一个值为a,然后a-1,之后通过update将age=a-1.
- 因为在该事务没有执行update之前,并不会加行锁。若此时有事务B修改了age,那么事务A之后执行update 的age=a-1,将会导致错误!!
因此我们要在原基础上修改值,我们要写成age=age-1,让MySQL保证原子性,而不是通过java保证!
当然where要加入age>1,避免在满足java的条件之后,update执行之前,age值发生改变!
改进:
select ... for update;
update ...
- 这样也可以加行级锁(排它锁),之后再执行update语句也不会发生并发写问题。
select ... lock in share mode; # 加共享锁
update ...
4.3.3.1 MySQL中的行锁时机
加锁的过程要分有索引和无索引两种情况,比如下面这条语句
update user set age=11 where id = 1
id 是这张表的主键,是有索引的情况,那么 MySQL 直接就在索引数中找到了这行数据,然后干净利落的加上行锁就可以了。
而下面这条语句
update user set age=11 where age=10
表中并没有为 age 字段设置索引,所以, MySQL 无法直接定位到这行数据。那怎么办呢,当然也不是加表锁了。MySQL 会为这张表中所有行加行锁,没错,是所有行。但是呢,在加上行锁后,MySQL 会进行一遍过滤,发现不满足的行就释放锁,最终只留下符合条件的行。虽然最终只为符合条件的行加了锁,但是这一锁一释放的过程对性能也是影响极大的。所以,如果是大表的话,建议合理设计索引,如果真的出现这种情况,那很难保证并发度。
4.3.4 解决幻读
事务第三级的隔离级别,可以实现重复读,但是会出现幻读问题(其他事务新增行)。MySQL通过间隙锁( Next-Key )解决了幻读问题。
-
间隙锁:即索引当中的间隙,如id从1~10这个间隙,如果被加锁,那么id=1~10的行记录将不能被插入数据,即可解决幻读。
- 如修改id=1的行时:负无穷~1,1~下个行数据(如id=10),这两个区间将不能允许其他事务插入数据。
-
详细解释:(不重要)

此时,在数据库中会为索引维护一套B+树,用来快速定位行记录。B+索引树是有序的,所以会把这张表的索引分割成几个区间。
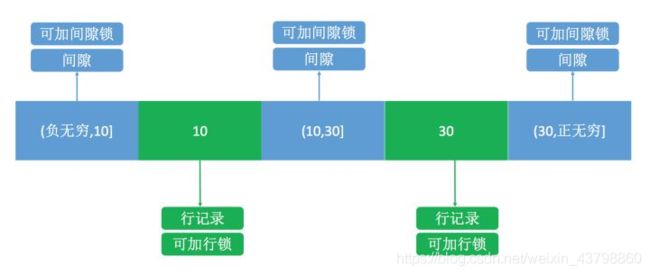
上面存在三个间隙,分成了3 个区间,(负无穷,10]、(10,30]、(30,正无穷],在这3个区间是可以加间隙锁的。
5. 索引
请看MySQL进阶篇
6. 范式
- 第一范式
- 所有字段不可再分,即要求分割到最小字段
- 第二范式
- 所有非主属性完全依赖于主键,不能产生部分依赖。
- 第三范式
- 所有非主属性直接依赖于主码,不能产生传递依赖。
- 提醒:在实际开发中,为了满足客户的需求为主,有的时候会拿冗余换执行速度。
7. 外键&触发器&存储过程&视图
以上在实际开发中非常少使用,因此简单介绍。
7.1 外键
外键就是外键约束。若外键所依赖的键非主码,则可以本身可以为空。
....
FOREIGN KEY(字段1) REFERENCES 表名2(字段2)
....
存在问题:
- 级联问题
- 因为每次级联delete或update的时候,都要级联操作相关的外键表,不论有没有这个必要,由其在高并发的场景下,这会导致性能瓶颈
- 增加数据库压力
- 外键等于把数据的一致性事务实现,全部交给数据库服务器完成
- 死锁问题
- 开发不方便
- 有外键时,无论开发还是维护,需要手工维护数据时,都不太方便
7.2. 触发器&存储过程
- 触发器: trigger, 事先为某张表绑定好一段代码 ,当表中的某些内容发生改变的时候(增删改)系统会自动触发代码,执行.
- 触发器: 事件类型, 触发时间, 触发对象
- 事件类型: 增删改, 三种类型insert,delete和update
- 触发时间: 前后: before和after
- 触发对象: 表中的每一条记录(行)
- 存储过程
- 存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存在问题:
- 均不推荐使用!
- 触发器难以维护,出现bug无法在java中排查错误、可读性差
- 存储过程也是,移植性差,不好维护。
7.3 视图
视图是逻辑上存在的表,真实的数据仍然在表中,不占用空间,可以当成普通表一样操作。
创建视图
create view 视图名 as <select ...>
删除视图
drop view 视图名
存在问题:
- 在web+mysql设计中,由于追求高伸缩性,不依赖于数据库本身实现,一般不使用视图来做数据查询,也就是web程序拼好sql字符串,让数据库执行。这样业务逻辑在程序中,方便调试,测试,修改,分布式运行。
- 视图还引入了一些其他的问题,使得其背后的逻辑非常复杂。
8. 数据库开发原则
以下部分收录来自阿里巴巴Java开发手册
8.1 建表规约
-
【强制】表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint
( 1 表示是, 0 表示否) 。
说明: 任何字段如果为非负数,必须是 unsigned。
正例: 表达逻辑删除的字段名 is_deleted, 1 表示删除, 0 表示未删除。 -
【强制】表名、字段名必须使用小写字母或数字, 禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
说明: MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、表名、字段名,都不允许出现任何大写字母,避免节外生枝。
正例: aliyun_admin, rdc_config, level3_name
反例: AliyunAdmin, rdcConfig, level_3_name -
【强制】表名不使用复数名词。
说明: 表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO 类名也是单数形式,符合表达习惯。 -
【强制】禁用保留字,如 desc、 range、 match、 delayed 等, 请参考 MySQL 官方保留字.
-
【强制】 主键索引名为 pk_字段名; 唯一索引名为 uk_字段名; 普通索引名则为 idx_字段名。
说明: pk_ 即 primary key; uk_ 即 unique key; idx_ 即 index 的简称。 -
【强制】小数类型为 decimal,禁止使用 float 和 double。
说明: float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。 -
【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
-
【强制】 varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
-
【强制】表必备三字段: id, gmt_create, gmt_modified。
说明: 其中 id 必为主键,类型为 unsigned bigint、单表时自增、步长为 1。 gmt_create,gmt_modified 的类型均为 date_time 类型,前者现在时表示主动创建,后者过去分词表示被动更新。 -
【强制】对于一定是非负的字段,就要设置成无符号值,无符号值可以避免误存负数, 且扩大了表示范围。
正例:比如人的年龄,乌龟的岁数,化石年龄,太阳年份等。
8.2 索引规约
-
【强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
说明: 不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的; 另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。 -
【强制】超过三个表禁止 join。需要 join 的字段,数据类型必须绝对一致; 多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、 SQL 性能。 -
【强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据, 长度为 20 的索引,区分度会高达 90%以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。 -
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明: 索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。 -
【推荐】 SQL 性能优化的目标:至少要达到 range 级别, 要求是 ref 级别, 如果可以是 consts
最好。
说明:
1) consts 单表中最多只有一个匹配行(主键或者唯一索引) ,在优化阶段即可读取到数据。 2) ref 指的是使用普通的索引(normal index) 。
3) range 对索引进行范围检索。
反例: explain 表的结果, type=index,索引物理文件全扫描,速度非常慢,这个 index 级别比较 range 还低,与全表扫描是小巫见大巫
8.3 SQL语句
-
【强制】不要使用 count(列名)或 count(常量)来替代 count(*), count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明: count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。 -
【强制】 count(distinct col) 计算该列除 NULL 之外的不重复行数, 注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
-
【强制】当某一列的值全是 NULL 时, count(col)的返回结果为 0,但 sum(col)的返回结果为NULL,因此使用 sum()时需注意 NPE 问题。
正例: 可以使用如下方式来避免 sum 的 NPE 问题: SELECT IF( ISNULL(SUM ( g ) ),0,SUM(g)) FROM table; -
【强制】使用 ISNULL()来判断是否为 NULL 值。
说明: NULL 与任何值的直接比较都为 NULL。
1) NULL<>NULL 的返回结果是 NULL, 而不是 false。
2) NULL=NULL 的返回结果是 NULL, 而不是 true。
3) NULL<>1 的返回结果是 NULL,而不是 true。 -
【强制】 在代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句。
-
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明: 以学生和成绩的关系为例, 学生表中的 student_id 是主键,那么成绩表中的 student_id则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新, 即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群; 级联更新是强阻塞,存在数据库更新风暴的风险; 外键影响数据库的插入速度。 -
【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
-
【强制】数据订正时,删除和修改记录时,要先 select,避免出现误删除,确认无误才能执行更新语句。
9. 连接数据库
url=jdbc:mysql://120.76.137.145:3306/rent?useSSL=false&serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true