Redis总结
1、Redis概述:
Redis将数据以键值对(Key,Value)的形式存放在内存中,具有读写快的优点,被广泛应用与缓存方向。
Redis内设置了多种数据类型实现,包括String、Hash、Set、Bitmap。且Redis 还支持事务 、持久化(将内存中的数据保存在磁盘中)、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
Redis快的原因:1)基于内存,访问速度是磁盘的上千倍;2)基于Reactor模式设计了一个高效的事件处理模式,主要是单线程循环和IO多路复用;3)内置了多种优化过后的数据结构
2、缓存数据处理流程:
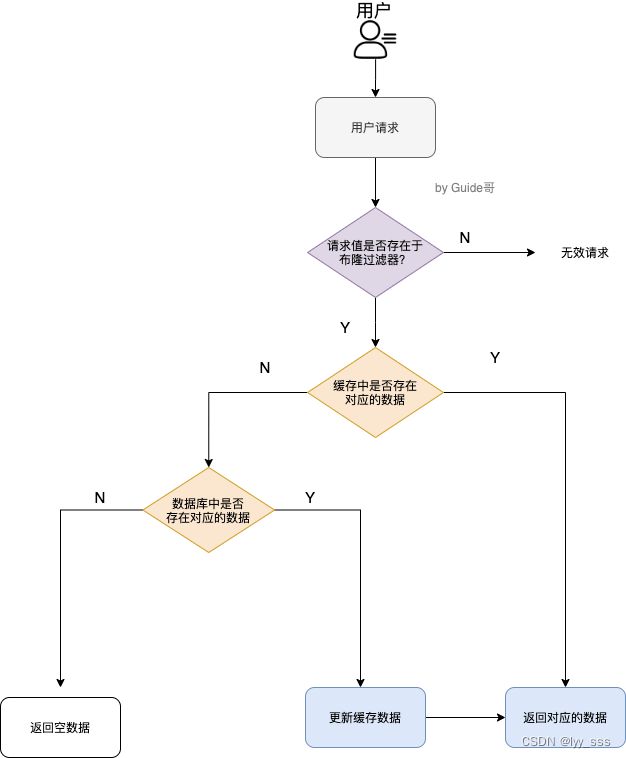
用户请求--------》缓存中是否存在对应数据------------》数据库是否存在对应数据
当用户需要请求某个数据时,首先会在缓存中进行查找,若缓存中存在该数据则直接返回,若缓存中不存在该数据则进入数据库进行查找,若数据库中也没有该数据则返回空数据。
缓存优势:高性能和高并发。1)访问数据库都是从磁盘进行读取,速度慢,通过将一些高频访问数据存在缓存中可以有效提高性能;2)数据库的吞吐量(QPS)是有限的,通过将数据库中的部分数据(高频访问)转移到缓存中可以有效减少对数据库的请求,转而从缓存中获取信息,提高系统整体的并发。
3、Redis的其他功能:
1)分布式锁 : 通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁
2)3 种特殊数据结构 :HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
4、Redis常用数据结构:
1)5 种基础数据结构 :String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
2)限流 :一般是通过 Redis + Lua 脚本的方式来实现限流
3)消息队列 :Redis 自带的 list 数据结构可以作为一个简单的队列使用
5、给数据设置缓存过期时间的作用:
由于内存空间是有限的,因此通过设置缓存过期时间缓解内存的消耗;其次,业务场景需求,如验证码时效、用户登录的tocken时效通过设置缓存过期时间可以有效解决。
6、Redis判定数据是否过期:
Redis通过过期字典(可以看做hash表)保存数据的过期时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间
7、缓存中过期数据的删除方法
1)惰性删除:只会在去除key的时候才对数据进行过期检查。优点是对CPU友好,缺点是可能导致太多过期的数据没有删除
2)定期删除:每隔一段时间抽取一批key执行删除过期key操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
Redis采用的是定期删除+惰性删除的方法
8、Redis内存淘汰机制
仅仅通过给key设置过期时间,以及利用定期删除+惰性删除的方法清理过期key,还是有可能导致大量的过期key堆积在内存中,然后导致内存爆满,因此Redis采用内存淘汰机制进行进一步的优化。
Redis提供6种数据淘汰策略:
1)volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
2)volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
3)volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
4)allkeys-lru(least recently used):当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
5)allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
6)no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。
4.0版本以后新增以下两种:
7)volatile-lfu(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
8)allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
9、Redis持久化机制-----》Redis挂掉之后数据可以进行恢复的原因
Redis支持持久化,且支持两种不同方式的持久化操作。Redis 的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file, AOF)
快照(持久化默认方式):Redis通过快照获得某个时间点上存储在内存里面的数据的副本,通过快照进行备份,并复制到其他服务器从而创建具有相同数据的服务器副本,还可以将快照留在原地以便重启服务器的时候使用。
只追加文件:AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到内存缓存中,然后根据配置决定何时将该命令同步到硬盘中的AOF文件。由此可以看出AOF的持久化实时性能更好。
10、Redis事务
开始事务(MULTI):使用 MULTI 命令后可以输入多个命令,然后将这些命令放到队列等待执行
执行事务(EXEC):使用EXEC执行队列中的命令(先进先出原则)
取消事务(DISCARD):使用DISCARD命令取消一个事务,队列中所有保存的命令都会被清空
WATCH命令用于监听指定的键,当一个被WATCH命令监听的键被修改的话,整个事务都不会执行,直接返回失败。
11、Redis不支持原子性
Redis 事务在运行错误的情况下,除了执行过程中出现错误的命令外,其他命令都能正常执行。并且,Redis 是不支持回滚(roll back)操作的。因此,Redis 事务其实是不满足原子性的(而且不满足持久性)。因此Redis事务不建议在开发中使用。
12、Redis缓存穿透
缓存穿透的本质是:大量请求的key不存在与缓存中,导致请求直接到了数据库上
缓存穿透的解决办法:1)做好参数校验,不合法的参数请求直接抛出异常信息返回给客户端;2)使用布隆过滤器对用户请求值进行判定,用户请求值不存在与布隆过滤器中则返回参数错误信息给客户端。(布隆过滤器存在误判的情况,布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。)
13、Redis缓存雪崩
缓存在同一时间大面积失效(同一时间大量的key失效),导致请求都直接落到数据库上,造成数据库短时间内承受大量请求。还有一种场景是:有一些被大量访问数据(热点缓存)在某一时刻大面积失效,导致对应的请求直接落到了数据库上。
解决办法:
针对Redis服务不可用的情况:1)采用Redis集群,避免单机出现问题导致整个缓存服务没办法使用;2)限流,避免同时处理大量的请求
针对热点缓存失效的情况:1)设置不同的失效时间(避免热点缓存同一时间失效),如随机设置缓存失效时间;2)将热点缓存设置永不失效(占用资源)
13、如何保证缓存和数据库的一致性
保证数据库一致性需要在数据发生更新时,对数据库和缓存都进行操作。具体就是修改一条数据时,不仅要更新数据库也要更新缓存。
数据库和缓存更新存在先后问题,在不考虑异常的情况下两种方式都可以让两者保持一致。因为操作分为两步,那么就很有可能存在「第一步成功、第二步失败」的情况发生,该情况的影响如下
1)先更新缓存,后更新数据库—》数据库更新失败,缓存更新成功;此时读请求访问缓存可以获取正确值,当缓存失效后悔直接获取数据库值并重新更新到缓存,此时获取的值就是错误的。
2)先更新数据库,后更新缓存—》数据库更新成功,缓存更新失败;此时读请求访问缓存数据获取的值是错误值,当缓存失效后,直接从数据库获取值并更新到缓存,此时获取的才是正确值。
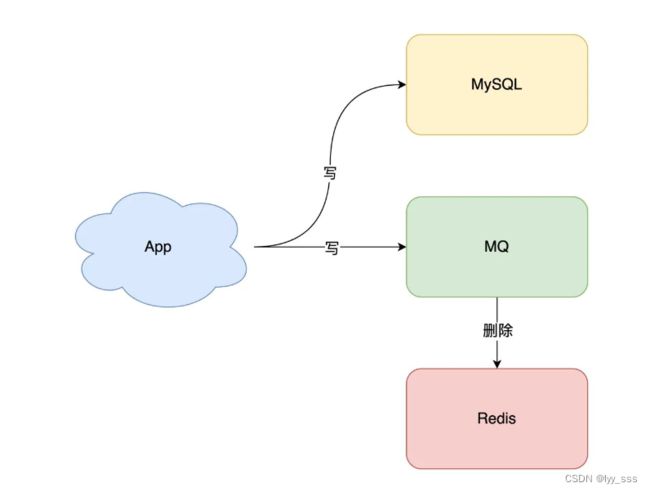
当对数据库和缓存进行更新过程中有一个出现异常时,也会导致缓存与数据库的不一致,解决该方法的思路是重试,但立即重试很大概率还是会失败,且重试会一致占用这个线程资源,无法服务其他客户端请求。为此更好的解决方案是异步重试。
异步重试:把重试请求写到消息队列中(RabbitMQ或其他中间件),由专门的消费者来重试,直到成功
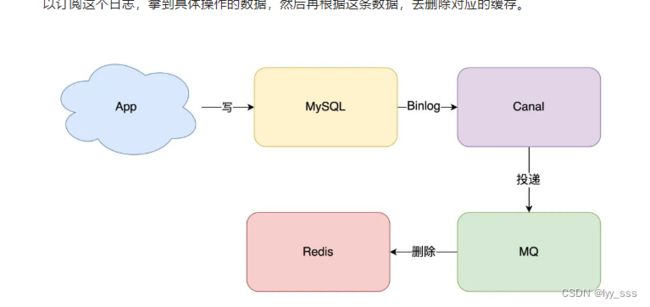
另一个方案:订阅数据库变更日志,再操作缓存,该方法使得业务应用在修改数据库时,只需修改数据库无需操作缓存,缓存通过订阅的数据库日志更变进行自动更新。