pandas的分层索引 (MultiIndex) 讲解
pandas库的名字来源于3种主要数据结构开头字母的缩写:Panel,Dataframe,Series。其中Series表示一维数据,Dataframe表示二维数据,Panel表示三维数据。当数据高于二维时,一般却不用 Panel 表示,一般用包含多层级索引的Dataframe进行表示,而不是使用Panel。原因是使用多层级索引展示数据更加直观,操作数据更加灵活,并且可以表示3维,4维乃至任意维度的数据。
# 导包
import numpy as np
import pandas as pd
from pandas import Series,DataFrame一、单层索引
sa = pd.Series([1, 2, 3], index=list('abc'))结果:

二、多层索引
分层索引是pandas中一个重要的特性,能让我们在一个轴(axis)上有多个index levels(索引层级)。它可以让我们在低维格式下处理高维数据。


1、Series 多层索引
import pandas as pd
s = pd.Series([1,2,3,4,5,6],index=[['张三','张三','李四','李四','王五','王五'],
['期中','期末','期中','期末','期中','期末']])

从图中数据可以看出,张三那一列是数据的第一层索引,期中那一列是数据的第二层索引,而第二层索引值是和数据一一对应的。
但是,我们在创建的时候发现,也需要将名字和考试阶段一一对应,才可以。

2、DataFrame多层索引
#导入numpy并改名为np
import numpy as np
# np.random.randint(0,100,size=(6,3)) 是使用numpy中的随机模块random中,生成随机整数方法randint,
# 里面的参数size是指定生成6行3列的数据,并且每个数字的范围在0到100之间。
da = np.random.randint(100,size=(6,3))
df1 = pd.DataFrame(da,index=[["a","a","b","b","c","c"],
["期末","期中","期末","期中","期末","期中"]],
columns=["语文","英语","数学"])
df1
3、pd.MultiIndex
上面建索引的⽅式写起来很麻烦,我们要写很多重复的内容,所以pandas给我们提供了另⼀ 种⽅式(MultiIndex.from_product() )来构建多层索引。
使⽤MultiIndex.from_product()方法构建,⾸先我们把每层需要的索引写⼊到⼀个列表中,将这些列表在存⼊到⼀个新的列表当中,作为 参数传⼊MultiIndex.from_product()方法中,把结果赋值给变量index,那么这个index就 是我们构造好的索引,我们只需要在创建Series的时候传入索引即可。
# Series
names=["a","b","c"]
exems=["期中","期末"]
index=pd.MultiIndex.from_product([names,exems])
df = pd.Series(np.random.randint(0,150,size=6),index=index)
df
# DataFrame
names=["a","b","c"]
exems=["期中","期末"]
columns = ["语文","英语","数学"]
index=pd.MultiIndex.from_product([names,exems])
df2 = pd.DataFrame(da,index=index,columns=columns)
df2 
该MultiIndex对象是标准Index对象的分层模拟 ,通常将轴标签存储在pandas对象中。您可以将其MultiIndex视为一个元组数组,其中每个元组都是唯一的。
MultiIndex可以从
数组列表(使用 MultiIndex.from_arrays())、
元组数组(使用 MultiIndex.from_tuples())、
可迭代的交叉集(使用 MultiIndex.from_product())
或DataFrame(使用 MultiIndex.from_frame()) 创建。
该Index构造函数将尝试返回MultiIndex时,它传递一个元组列表。
4、set_index
# 方法将普通列转成多层级索引
da = np.random.randint(100,size=(6,3))
dic = {"class":["class1","class1","class2","class3"],
"name":["linda","mark","lily","cherich"],
"score":[100,123,120,116]}
df3 = pd.DataFrame(dic)
df3.set_index(["class","name"]) 
5、groupby
# 用来聚合计算,比如mean
df3.groupby(['class','name']).mean() 
6、pivot_table
# 类似于excel的透视表,数据动态排布,分类汇总
df3.pivot_table(index=["class","name"]) 
三、多层索引的取值
1、直接提取[ ]
# 取单个值
df["a"] 
#结果:69
df["a","期中"]# 取多个不连续值
df[["a","c"]] 
# 取多个连续的值
df[:"b"] 
2、标签取值 loc[], loc 按自定义的行、列的数据进行取值,不遵循左闭右开
# 取单个值
df.loc[:"a"]
# 取多个不连续值
df.loc[["a","c"]]
# 取多个连续的值
df.loc[:"b"] 
3、下标取值 iloc[], iloc 按默认的行、列索引的数据进行取值
# 取一个值
df4.iloc[0,3]
# 取多个值
df4.iloc[0,[3,5]]
# 取连续值 遵循左闭右开
df4.iloc[0:1,3:5]
四、多层索引的排序
1、按照索引排序,sort_index()
- level=0 表示按照第⼀层索引进⾏排序,默认为0,为1表示优先按照第⼆层索引 ...
- ascending=False 表示从⼤到⼩进⾏排列,默认为True(从⼩到⼤排序)
names=[1,2,3]
exems=["a","b"]
index=pd.MultiIndex.from_product([names,exems])
data1 = pd.Series([89,53,56,89,78,90],index=index)
# level = 0 则按照第一层索引排序 1 按照第二层
# ascending=False 降序 大到小 True 从小到大
data1.sort_index(level=0,ascending=False)
2、按照具体值(列名)排序,sort_value()
# series
data1.sort_values(ascending=False)
# dataFrame
df1.sort_values(by="语文",ascending=False)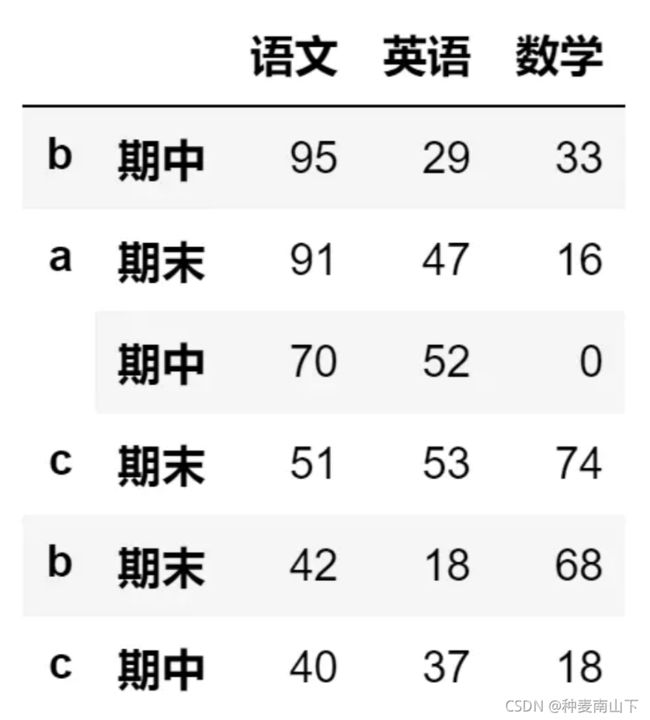
参考:https://www.jianshu.com/p/10b96a839134