Python爬虫的基本原理简介及内容汇总
Python爬虫的基本原理简介及内容汇总
- 一、爬虫网页请求方法介绍
-
- 1.1 网页主要请求方法
- 1.2 网页的主要请求头
- 二、爬虫网页响应方法介绍
-
- 2.1 网页响应状态码
- 2.2 网页响应头
- 2.3 网页响应体
- 三、提取网页响应的特定内容神器:xpath工具、lxml类库
-
- 3.1 Xpath工具
- 3.2 lxml类库
- 四、Python爬虫实例——爬取网页文章信息
通过Python的
requests库可以非常容易的实现简单爬虫。但是这种语言层面上的简单是建立在熟悉网页请求、网页响应原理的基础上的。因此,本文通过在简要介绍网页请求、网页响应原理的基础上,采用Python的requests库实现几个简单的爬虫示例。
一、爬虫网页请求方法介绍
1.1 网页主要请求方法
1、常用网页请求方法简介
| 方法 | 描述 |
|---|---|
GET |
请求页面,并返回页面内容 |
HEAD |
类似于GET请求,只不过返回的响应中没有具体内容,主要用于获取报头 |
POST |
大多用于提交表单或上传文件,数据包含在请求体中 |
PUT |
从客户端向服务器传送的数据取代指定文档中的内容 |
DELETE |
请求服务器删除指定的页面 |
CONNECT |
把服务器当作跳板,让服务器代替客户端访问其他网页 |
OPTIONS |
允许客户端查看服务器的性能 |
TRACE |
回显服务器收到的请求,主要用于测试或诊断 |
其中,GET、POST、PUT、DELETE是经常使用的网页请求方法,尤其是在做网站开发或者小程序app开发时。
2、requests库的GET请求方法示例
采用Python的requets库,通过下面四条代码就实现了爬取指定网页内容。这里需要留意如何设置网页头部信息headers。
import requests
# (1)得到需要爬取的网址url
url = 'https://blog.csdn.net/weixin_37926734/article/details/123267870?spm=1001.2014.3001.5501'
# (2)添加头部信息,以字典形式存储。
# 如果不添加头部信息,爬取不到网页内容
headers = {
'User-Agent' :
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
# (3)使用requests库的get函数爬取网页上的内容
requests_exam = requests.get(url, headers=headers)
获取想要爬取网页的头部信息方法:打开想要爬取的网页,按下F12,弹出了该网页的Web开发者工具,选择网络,然后选取一个状态为200的网页,再点击所有中的信息头,找到User-Agent后面的内容就是网页的头信息,如下图所示:
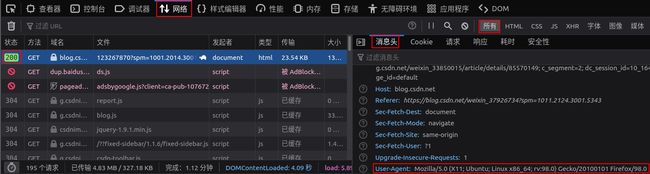
1.2 网页的主要请求头
另外,请求网址是统一资源定位符URL,它可以唯一确定我们请求的资源。因此,我们在爬虫的时候,接触非常多的就是URL。与URL密切相关的是网页的请求头,即HTTP头字段,下面列出与Python爬虫密切相关的几个:
| 请求头 | 描述 |
|---|---|
Accpet |
告诉WEB服务器自己接收什么介质类型,比如/表示任何类型,而type/*表示该类型下所有子类型(type/sub-type) |
Accpet-Language |
用于浏览器申明接收的语言 |
Accpet-Encoding |
接收字符集:用于浏览器申明自己接收的编码方法,通常指定压缩方法、是否支持压缩以及支持什么压缩方法 |
Host |
客户端指定自己想要访问的WEB服务器的域名/IP地址和端口号,比如Host: editor.csdn.net |
Cookie |
用于保存客户端中简单的文本文件,这个文件与特定的Web文档关联在一起,保存了客户端访问该Web文档时的信息,当客户端再次访问这个Web文档时候可供再次使用 |
Referer |
浏览器WEB服务器表明自己是从哪个网页URL,获得/点击当前请求中的网站/URL。例如,Refer:https://mp.csdn.net/ |
User-Agent |
浏览器表明自己的身份(是哪种浏览器),即浏览器的指纹信息。例如:Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:98.0) Gecko/20100101 Firefox/98.0 |
二、爬虫网页响应方法介绍
网页响应,即由服务端返回给客户端,可分为三部分:响应状态码(Response Statues Code)、响应头(Response Headers)和响应体(Response Body)。
2.1 网页响应状态码
响应状态码表示服务器的响应状态,在爬虫中,我们可以根据状态码来判断服务器响应状态,来作出相应的网页操作。下面列出网络响应错误代码及产生错误的原因:
| 状态码 | 说明 | 详情 |
|---|---|---|
100 |
继续 | 请求者应当继续提出请求。服务器已收到请求的一部分,正在等待其余部分 |
101 |
切换协议 | 请求者已要求服务器切换协议,服务器已确认并准备切换 |
200 |
成功 | 服务器已成功处理请求 |
201 |
已创建 | 请求成功并且服务器创建了新的资源 |
202 |
已接受 | 服务器已接受请求,但尚未处理 |
203 |
非授权信息 | 服务器已成功处理了请求,但返回的信息可能来自另一个源 |
204 |
无内容 | 服务器成功处理了请求,但没有返回任何内容 |
205 |
重置内容 | 服务器成功处理了请求,内容被重置 |
206 |
部分内容 | 服务器成功处理了部分请求 |
300 |
多种选择 | 针对请求,服务器可执行多种操作 |
301 |
永久移除 | 请求的网页已永久移动到新位置,即永久重定向 |
302 |
临时移动 | 请求的网页暂时跳转到其他页面,即暂时重定向 |
303 |
查看其他位置 | 如果原来的请求是POST,重定向目标文件文档应该通过GET提取 |
304 |
未修改 | 此次请求返回的网页未修改,继续使用上次的资源 |
305 |
使用代理 | 请求者应该使用代理访问该网页 |
307 |
临时重定向 | 请求的资源临时从其他位置响应 |
400 |
错误请求 | 服务器无法解析该请求 |
401 |
未授权 | 请求没有进行身份验证或验证未通过 |
403 |
禁止访问 | 服务器拒绝此请求 |
404 |
未找到 | 服务器找不到请求的网页 |
405 |
方法禁用 | 服务器禁用了请求中指定的方法 |
406 |
不接受 | 无法使用请求的内容响应请求的网页 |
407 |
需要代理授权 | 请求需要代理授权 |
408 |
请求超时 | 服务器请求超时 |
409 |
冲突 | 服务器在完成请求时发生冲突 |
410 |
已删除 | 请求的资源已永久删除 |
411 |
需要有效长度 | 服务器不接受不含有有效长度标头字段的请求 |
412 |
未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件 |
413 |
请求实体过大 | 请求实体过大,超出服务器的处理能力 |
414 |
请求URL过长 | 请求网址过长,服务器无法处理 |
415 |
不支持类型 | 请求格式不被请求页面支持 |
416 |
请求范围不符 | 页面无法提供请求的范围 |
417 |
未满足期望值 | 服务器未满足期望请求标头字段的要求 |
500 |
服务器内部错误 | 服务器遇到错误,无法完成请求 |
501 |
未实现 | 服务器不具备完成请求的功能 |
502 |
错误网关 | 服务器作为网关或代理,从上游服务器收到无效响应 |
503 |
服务器不可用 | 服务器目前无法使用 |
504 |
网关超时 | 服务器作为网关或代理,但是没有及时从上游服务器收到请求 |
505 |
HTTP版本不支持 | 服务器不支持请求中所用的HTTP协议版本 |
2.2 网页响应头
响应头包含服务器对请求的应答信息,比如Content-Type、Server、Set-Cookie等,下面列出一些常用的网页响应头:
| 响应头 | 描述 |
|---|---|
Date |
标识响应产生的时间 |
Last-Modified |
指定资源的最后修改时间 |
Content-Encoding |
指定响应内容的编码 |
Server |
包含服务器的信息,比如名称、版本等信息 |
Content-Type |
文档类型,指定返回的数据类型,比如,text/html表示返回HTML文档,application/x-javascript表示返回JavaScript文件,image/jpeg表示返回图片 |
Set-Cookie |
设置Cookie,指定浏览器需要将此内容放到Cookies中,下次请求携带Cookies请求 |
Expires |
指定响应的过期时间,可以使用代理服务器或者浏览器将要加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载 |
2.3 网页响应体
爬虫中的网页响应中最重要的就是响应体:网页响应的正文数据就是在响应体中。比如,在请求网页时,响应体就是网页的
HTML代码;请求一张图片时,响应体就是图片的二进制数据。做网页请求网页时,我们要解析的内容就是响应体。
三、提取网页响应的特定内容神器:xpath工具、lxml类库
3.1 Xpath工具
Xpath(XML Path Language)是一门XML文档中查找信息的语言,同时它也可以搜索HTML文档。Xpath可用来在XML或者HTML文档中对元素和属性进行遍历。Xpath使用路径表达式子XML文档中进行导航,所以我们可以使用Xpath工具访问网页中指定的内容。
XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。另外,在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
幸运的是,在本文Python爬虫中的应用,我们目前还不必过多的关注Xpath的细节,我们只需要了解它的一些基本概念,会运用Firefox网页指定内容Xpath路径表达式提取方法即可,比如我们想从一个博客文档中提取标题的Xpath路径表达式的方式如下图:
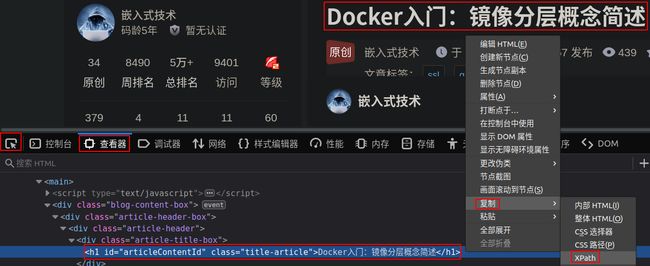
如上图所示,打开选定的文章博客网页,按F12打开Firefox的Web开发者工具,点击查看器 → \to →选取页面中元素,然后点击网页上的标题,点击鼠标右键,在下拉菜单中选取复制 → \to →Xpath,就得到了网页文章博客标题的Xpath路径表达://*[@id="articleContentId"],这个路径表达式是一个网页元素对象,我们如果想爬取标题的文本文件还需要指明Xpath具体读取文本内容://*[@id="articleContentId"]/text()。
3.2 lxml类库
lxml类库是一个HTML/XML解析器,用于解释和提取HTML/XML数据。它可以利用Xpath语法来定位网页上特定的元素和节点信息。在实际应用中,lxml解析器会自动修复和补全HTML代码中不规范、不完整的代码,从而提高开发效率。
本下面的提取文档标题的Python爬虫编程中,主要使用lxml类库的解析字符串HTML代码块的功能:
假设我们有一个text的字符串格式HTML代码块,我们可以使用如下语句将text转换为HTML格式对象:
from lxml import etree
# 定义一个text的字符串格式HTML代码块
text = '''
'''
# 将字符串text解析为html格式的对象
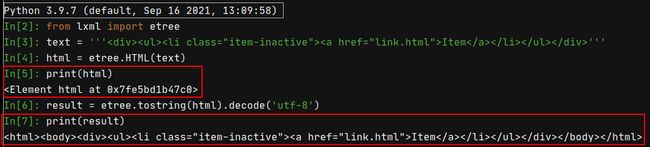
html = etree.HTML(text)
print(html)
# 同样的,我们还可以使用etree的tostring方法,
# 将HTML格式对象转换为字符串格式
result = etree.tostring(html).decode('utf-8')
print(result)
上面代码的两个print输出结果如下所示:
四、Python爬虫实例——爬取网页文章信息
本文Python爬虫主要包括以下三个步骤:
(1)找地址、(2)发送网页请求、(3)提取网页响应。
代码及解释如下所示:
import requests
from lxml import etree
# 该示例展示如何提取三篇博客文章的标题
# 创建一个向网页发出请求的函数:
def url_request():
'''1、找地址的主要内容包括:
1.1 找网址
1.2 添加头文件'''
# 1.1 找网址
# 首先创建地址列表,下面网页的地址分别对应
# 3篇不同的网页文章网络地址。
url_list = [
# 我的CSDN文章1:Docker入门:镜像分层概念简述
'https://blog.csdn.net/weixin_37926734/article/details/123267870?spm=1001.2014.3001.5501',
# 我的CSDN文章2:Docker入门:容器卷——容器持久化,实现容器间继承和数据共享
'https://blog.csdn.net/weixin_37926734/article/details/123278466?spm=1001.2014.3001.5501',
# 我的CSDN文章3:Docker入门:私有库(Docker Registry)简介及使用方法(防踩坑)
'https://blog.csdn.net/weixin_37926734/article/details/123279987?spm=1001.2014.3001.5501'
]
# 1.2 添加头文件
# 添加头部信息,以字典形式存储。
# 对于同一台电脑同一个浏览器,3篇
# 文章的头部信息一样。
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
'''发送网页请求、提取网页响应、数据入库,均在以下的for循环中实现:'''
for url in url_list:
'''2、发送网页请求:使用get网页请求方法,
对网页发出请求,并返回网页内容'''
res = requests.get(url, headers=headers)
'''3、提取网页响应主要内容:
3.1 提取网页的html元素对象
3.2 提取网页中特定位置的元素对象'''
# 使用解析器lxml中的etree提取网页的html元素对象
html = etree.HTML(res.text)
# 使用xpath工具提取网页html元素中的标题元素对象
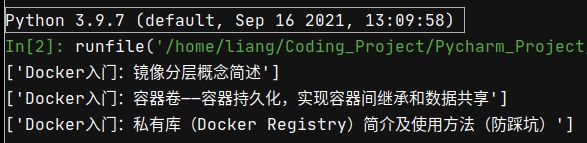
title = html.xpath('//*[@id="articleContentId"]/text()')
# 查看输出结果
print(title)
# 调用函数,执行代码,实现找地址与发送请求
url_request()
执行上面的代码,输入结果如下所示: