Opencv 快速使用(基础使用&手势识别)
文章目录
- 环境准备
- 资源读取
-
- 读取图片
- 读取视频
- 资源操作
-
- 修改图片
-
- 绘制图形
- 尺寸修改
- 灰度处理图片
-
- 图片保存
- 使用模型
- 模型训练
- 训练模型加载
- 手势识别
-
- 纯opencv版本
- mediapipe版本
-
- HandTrackingModule.py
- Main.py
环境准备
编辑器 pycharm
python 版本3.7x
pip3 install opencv-python
pip3 install opencv-contrib-python
基本要求:
熟练掌握 python3.x
懂得基本Pycahrm操作以及图片基本知识
资源读取
读取图片
import cv2.cv2 as cv
Image = cv.imread("Image/face1.jpg")
cv.imshow("Image",Image)
cv.waitKey(0)
cv.destroyAllWindows()
读取视频
import cv2
cap = cv2.VideoCapture(0)
# 0 表示读取摄像头
# 加入具体资源路径就表示直接读取路径对应的媒体资源
while True:
flag,img = cap.read()
cv2.imshow("Vido",img)
if(cv2.waitKey(1)==ord("q")):
#cv2.waitKey(0) 表示死循环等待
#cv2.waitKey(time)表示等待time ms 记录用户的输入获取对应的ASCII值
#这里表示等待一ms并且如果用户输入 q 就退出
break
资源操作
修改图片
绘制图形
这个在我们的图片框选当中是很有必要的
#绘制直线
cv2.line( img , (0,0),(511,511),( 255,0,0),5)
#绘制矩形
cv2.rectangle(img,(x,y,x+w,y+h),color=(0,0,255),thickness=1) # 方框颜色,粗细 -1表示实心
#绘制圆形
cv2.circle(img,center=(x+w,y+h),radius=100,color=(255,0,0),thickness=5)
#写字
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img , ' OpencV',(10,500), font,4,(255,255,255),2,cv.LINE_AA)
#在哪显示,显示字体,显示位置(开始),字体,大小,颜色,线条粗细,什么线条(实线,虚线...)
尺寸修改
Image_resize = cv.resize(Image,dsize=(200,200))
灰度处理图片
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
事实上
Image = cv.imread("Image/face1.jpg",0)
也可以,但是我们读取摄像头的时候是吧,有要处理的。
例如:
import cv2
cap = cv2.VideoCapture(0)
cap.set(3,640)
cap.set(4,480)
while True:
flag,img = cap.read()
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv2.imshow("Vido",img)
if(cv2.waitKey(1)==ord("q")):
#cv2.waitKey(0) 表示死循环等待
#cv2.waitKey(time)表示等待time ms 记录用户的输入获取对应的ASCII值
#这里表示等待一ms并且如果用户输入 q 就退出
break
图片保存
cv2.imwrite(filename,imgage)
使用模型
import cv2.cv2 as cv
import cv2.data as data
#读取图像
img = cv.imread('Image/face1.jpg')
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_alt2.xml")
face = face_detect.detectMultiScale(gary)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.imshow('result',img)
cv.waitKey(0)
#释放内存
cv.destroyAllWindows()
CascadeClassifier()就是加载
例如:
import cv2.cv2 as cv
import cv2.data as data
cap = cv.VideoCapture(0)
cap.set(3,640)
cap.set(4,480)
while True:
flag,img = cap.read()
gary = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detect = cv.CascadeClassifier(data.haarcascades + "haarcascade_frontalface_alt2.xml")
face = face_detect.detectMultiScale(gary)
for x, y, w, h in face:
cv.rectangle(img, (x, y), (x + w, y + h), color=(0, 0, 255), thickness=2)
cv.imshow("Vido",img)
if(cv.waitKey(1)==ord("q")):
#cv2.waitKey(0) 表示死循环等待
#cv2.waitKey(time)表示等待time ms 记录用户的输入获取对应的ASCII值
#这里表示等待一ms并且如果用户输入 q 就退出
break
cap.release()
#释放内存
cv.destroyAllWindows()
模型训练
recognizer=cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids))
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
加载预测模型
这个直接看例子吧:
import os
import cv2.cv2 as cv
import numpy as np
import cv2.data as data
def getImageIds(path):
#函数作用是提取人脸然后返回人物的人脸和id
faceseare=[] # 保存检测出的人脸
ids=[] #
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#人脸检测
face_detector = cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xml")
if imagePaths:
print('训练图片为:',imagePaths)
else:
print("请先录入人脸")
return
for imagePath in imagePaths:
#二值化处理
img = cv.imread(imagePath)
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
img_numpy=np.array(img,'uint8')#获取图片矩阵
faces = face_detector.detectMultiScale(img_numpy)
id = int(os.path.split(imagePath)[1].split('.')[0])
for x,y,w,h in faces:
ids.append(id)
faceseare.append(img_numpy[y:y+h,x:x+w])
print('已获取id:', id)
return faceseare,ids
if __name__ == '__main__':
#图片路径
path='Image/InPutImg'
#获取图像数组和id标签数组和姓名
faces,ids=getImageIds(path)
#获取训练对象
recognizer=cv.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids)) #把对应的人脸和id联系起来训练
#保存训练文件
model_save = "trainer/"
if not os.path.exists(model_save):
os.makedirs(model_save)
recognizer.write('trainer/trainer.yml')
完整的例子如下:
https://blog.csdn.net/futerox/article/details/120685898
训练模型加载
这个也是例子
使用
recogizer=cv.face.LBPHFaceRecognizer_create()#加载训练数据集文件
recogizer.read(‘trainer/trainer.yml’)
import cv2.cv2 as cv
import os
import cv2.data as data
recogizer=cv.face.LBPHFaceRecognizer_create()#加载训练数据集文件
recogizer.read('trainer/trainer.yml')
names=[]
warningtime = 0
#准备识别的图片
def face_detect_demo(img):
global warningtime
gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
face_detector=cv.CascadeClassifier(data.haarcascades+"haarcascade_frontalface_default.xm")
face=face_detector.detectMultiScale(gray)
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人脸识别
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
if confidence > 80: #评分越大可信度越低
warningtime += 1
if warningtime > 100:
warningtime = 0
print("未识别出此人") #这块的话其实可以再搞一套对应的惩罚机制
cv.putText(img, 'unkonw', (x + 10, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
#这里也对应一套识别后的机制
cv.putText(img,str(names[ids-1]), (x + 10, y - 10), cv.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv.imshow('result',img)
def get_name(names):
path = 'Image/InPutImg/'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)
cap=cv.VideoCapture(0)
get_name(names)
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
if ord(' ') == cv.waitKey(10): #按下空格关了
break
cap.release()
cv.destroyAllWindows()
手势识别
纯opencv版本
这个的话有点超纲了,在本篇博文,其实写这篇博文的目的还是翻笔记的时候找到了这篇笔记,顺便整理一下,其实就是那篇
分分钟自制人脸识别(如何快速识别心仪的小姐姐~)
的边角料
但是,突然想到最近那个手势识别比较火,那就来一下呗。识别你的手势是哪个数字,识别1~5
这个原理如下:
1.选择手势区域,我们这个比较那啥需要选定一个区域来放置我们的手势
2. 进行高斯滤波
3.之后我们就能够通过找到手的轮廓,之后找到凹凸位置,那么这样一来就能够判断你的手势是几
那么这个局限性也就很明显了,我们是通过凹凸点来确定你的手势是数字几的,这个就有点那啥了,只能说能用。
import cv2
import numpy as np
import math
cap = cv2.VideoCapture(0)
while (cap.isOpened()):
ret, frame = cap.read() # 读取摄像头每帧图片
frame = cv2.flip(frame, 1)
kernel = np.ones((2, 2), np.uint8)
roi = frame[100:600, 100:600] # 选取图片中固定位置作为手势输入
cv2.rectangle(frame, (100, 100), (600, 600), (0, 0, 255), 0) # 用红线画出手势识别框
# 基于hsv的肤色检测
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
lower_skin = np.array([0, 28, 70], dtype=np.uint8)
upper_skin = np.array([20, 255, 255], dtype=np.uint8)
# 进行高斯滤波
mask = cv2.inRange(hsv, lower_skin, upper_skin)
mask = cv2.dilate(mask, kernel, iterations=4)
mask = cv2.GaussianBlur(mask, (5, 5), 100)
# 找出轮廓
contours, h = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnt = max(contours, key=lambda x: cv2.contourArea(x))
epsilon = 0.0005 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
hull = cv2.convexHull(cnt)
areahull = cv2.contourArea(hull)
areacnt = cv2.contourArea(cnt)
arearatio = ((areahull - areacnt) / areacnt) * 100
# 求出凹凸点
hull = cv2.convexHull(approx, returnPoints=False)
defects = cv2.convexityDefects(approx, hull)
# 定义凹凸点个数初始值为0
l = 0
for i in range(defects.shape[0]):
s, e, f, d, = defects[i, 0]
start = tuple(approx[s][0])
end = tuple(approx[e][0])
far = tuple(approx[f][0])
pt = (100, 100)
a = math.sqrt((end[0] - start[0]) ** 2 + (end[1] - start[1]) ** 2)
b = math.sqrt((far[0] - start[0]) ** 2 + (far[1] - start[1]) ** 2)
c = math.sqrt((end[0] - far[0]) ** 2 + (end[1] - far[1]) ** 2)
s = (a + b + c) / 2
ar = math.sqrt(s * (s - a) * (s - b) * (s - c))
# 手指间角度求取
angle = math.acos((b ** 2 + c ** 2 - a ** 2) / (2 * b * c)) * 57
if angle <= 90 and d > 20:
l += 1
cv2.circle(roi, far, 3, [255, 0, 0], -1)
cv2.line(roi, start, end, [0, 255, 0], 2) # 画出包络线
l += 1
font = cv2.FONT_HERSHEY_SIMPLEX
# 条件判断,知道手势后想实现的功能
if l == 1:
if areacnt < 2000:
cv2.putText(frame, "put hand in the window", (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
else:
if arearatio < 12:
cv2.putText(frame, '0', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif arearatio < 17.5:
cv2.putText(frame, "1", (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
else:
cv2.putText(frame, '1', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 2:
cv2.putText(frame, '2', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 3:
if arearatio < 27:
cv2.putText(frame, '3', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
else:
cv2.putText(frame, '3', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 4:
cv2.putText(frame, '4', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
elif l == 5:
cv2.putText(frame, '5', (0, 50), font, 2, (0, 0, 255), 3, cv2.LINE_AA)
cv2.imshow('frame', frame)
cv2.imshow('mask', mask)
key = cv2.waitKey(25) & 0xFF
if key == ord('q'): # 键盘q键退出
break
cv2.destroyAllWindows()
cap.release()
此外的话还有一个版本的,这个是我在找资料的时候发现的,他这个是使用了 mediapipe 这个玩意来做的,结合opencv
mediapipe版本
参考这几个人的博客:
https://blog.csdn.net/weixin_43654363/article/details/120809464
https://blog.csdn.net/qq_43550173/article/details/116273477
以及这个视频(满屏咖喱味)
https://www.bilibili.com/video/BV1V34y1Q7ka?from=search&seid=13134349602411946620&spm_id_from=333.337.0.0
这里的代码是CV调试之后的,原来的别人写的代码有点问题,我这边调试了。
两个脚本
HandTrackingModule.py
import cv2
import mediapipe as mp
class HandDetector:
"""
使用mediapipe库查找手。导出地标像素格式。添加了额外的功能。
如查找方式,许多手指向上或两个手指之间的距离。而且提供找到的手的边界框信息。
"""
def __init__(self, mode=False, maxHands=2,comPlexity=1, detectionCon=0.5, minTrackCon=0.5):
"""
:param mode: 在静态模式下,对每个图像进行检测
:param maxHands: 要检测的最大手数
:param detectionCon: 最小检测置信度
:param minTrackCon: 最小跟踪置信度
"""
self.mode = mode
self.maxHands = maxHands
self.detectionCon = detectionCon
self.minTrackCon = minTrackCon
self.comPlexity = comPlexity
self.mpHands = mp.solutions.hands
self.hands = self.mpHands.Hands(self.mode, self.maxHands,self.comPlexity,
self.detectionCon, self.minTrackCon)
self.mpDraw = mp.solutions.drawing_utils
self.tipIds = [4, 8, 12, 16, 20]
self.fingers = []
self.lmList = []
def findHands(self, img, draw=True):
"""
从图像(BRG)中找到手部。
:param img: 用于查找手的图像。
:param draw: 在图像上绘制输出的标志。
:return: 带或不带图形的图像
"""
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 将传入的图像由BGR模式转标准的Opencv模式——RGB模式,
self.results = self.hands.process(imgRGB)
if self.results.multi_hand_landmarks:
for handLms in self.results.multi_hand_landmarks:
if draw:
self.mpDraw.draw_landmarks(img, handLms,
self.mpHands.HAND_CONNECTIONS)
return img
def findPosition(self, img, handNo=0, draw=True):
"""
查找单手的地标并将其放入列表中像素格式。还可以返回手部周围的边界框。
:param img: 要查找的主图像
:param handNo: 如果检测到多只手,则为手部id
:param draw: 在图像上绘制输出的标志。(默认绘制矩形框)
:return: 像素格式的手部关节位置列表;手部边界框
"""
xList = []
yList = []
bbox = []
bboxInfo =[]
self.lmList = []
if self.results.multi_hand_landmarks:
myHand = self.results.multi_hand_landmarks[handNo]
for id, lm in enumerate(myHand.landmark):
h, w, c = img.shape
px, py = int(lm.x * w), int(lm.y * h)
xList.append(px)
yList.append(py)
self.lmList.append([px, py])
if draw:
cv2.circle(img, (px, py), 5, (255, 0, 255), cv2.FILLED)
xmin, xmax = min(xList), max(xList)
ymin, ymax = min(yList), max(yList)
boxW, boxH = xmax - xmin, ymax - ymin
bbox = xmin, ymin, boxW, boxH
cx, cy = bbox[0] + (bbox[2] // 2), \
bbox[1] + (bbox[3] // 2)
bboxInfo = {"id": id, "bbox": bbox,"center": (cx, cy)}
if draw:
cv2.rectangle(img, (bbox[0] - 20, bbox[1] - 20),
(bbox[0] + bbox[2] + 20, bbox[1] + bbox[3] + 20),
(0, 255, 0), 2)
return self.lmList, bboxInfo
def fingersUp(self):
"""
查找列表中打开并返回的手指数。会分别考虑左手和右手
:return:竖起手指的数组(列表),数组长度为5,
其中,由大拇指开始数,立起标为1,放下为0。
"""
if self.results.multi_hand_landmarks:
myHandType = self.handType()
fingers = []
# Thumb
if myHandType == "Right":
if self.lmList[self.tipIds[0]][0] > self.lmList[self.tipIds[0] - 1][0]:
fingers.append(1)
else:
fingers.append(0)
else:
if self.lmList[self.tipIds[0]][0] < self.lmList[self.tipIds[0] - 1][0]:
fingers.append(1)
else:
fingers.append(0)
# 4 Fingers
for id in range(1, 5):
if self.lmList[self.tipIds[id]][1] < self.lmList[self.tipIds[id] - 2][1]:
fingers.append(1)
else:
fingers.append(0)
return fingers
def handType(self):
"""
检查传入的手部是左还是右
:return: "Right" 或 "Left"
"""
if self.results.multi_hand_landmarks:
if self.lmList[17][0] < self.lmList[5][0]:
return "Right"
else:
return "Left"
Main.py
import cv2
from Head.HandTrackingModule import HandDetector
class Main:
def __init__(self):
self.camera = cv2.VideoCapture(0,cv2.CAP_DSHOW)
self.camera.set(3, 640)
self.camera.set(4, 480)
def Gesture_recognition(self):
while True:
self.detector = HandDetector()
frame, img = self.camera.read()
img = self.detector.findHands(img)
lmList, bbox = self.detector.findPosition(img)
if lmList:
x_1, y_1 = bbox["bbox"][0], bbox["bbox"][1]
x1, x2, x3, x4, x5 = self.detector.fingersUp()
if (x2 == 1 and x3 == 1) and (x4 == 0 and x5 == 0 and x1 == 0):
cv2.putText(img, "2", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif (x2 == 1 and x3 == 1 and x4 == 1) and (x1 == 0 and x5 == 0):
cv2.putText(img, "3", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif (x2 == 1 and x3 == 1 and x4 == 1 and x5 == 1) and (x1 == 0):
cv2.putText(img, "4", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif x1 == 1 and x2 == 1 and x3 == 1 and x4 == 1 and x5 == 1:
cv2.putText(img, "5", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif x2 == 1 and (x1 == 0, x3 == 0, x4 == 0, x5 == 0):
cv2.putText(img, "1", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
elif x1 and (x2 == 0, x3 == 0, x4 == 0, x5 == 0):
cv2.putText(img, "GOOD!", (x_1, y_1), cv2.FONT_HERSHEY_PLAIN, 3,
(0, 0, 255), 3)
cv2.imshow("camera", img)
if cv2.getWindowProperty('camera', cv2.WND_PROP_VISIBLE) < 1:
break
if cv2.waitKey(1)==ord("q"):
break
if __name__ == '__main__':
Solution = Main()
Solution.Gesture_recognition()
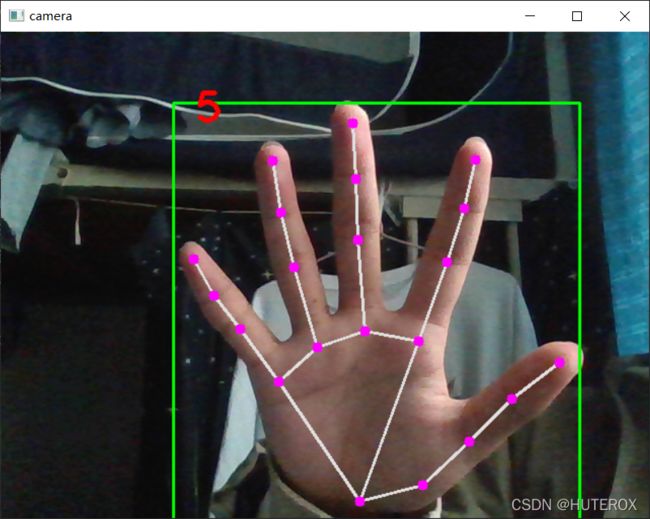
效果