Pytoch随笔(光速入门篇)
文章目录
- Pytorch梯度
- 线性回归
-
- 原始版
- 高级API版
- 优化器
-
- 梯度下降算法(batch gradient descent BGD)
- 随机梯度下降法(Stochastic gradient descent SGD)
- 小批量梯度下降(Mini-batch gradient descent MBGD)
- 动量法(Momentum)
- AdaGrad
- RMSProp
- Adam
- 手写数字案例
-
- 数据集
- 数据划分
- 网络构建
- 训练与验证
- 完整代码
- 总结
本文仅针对像我这样的小白,大佬请绕路!
以前翻阅笔记的时候发现了这么一篇博文:
啊哈~花一天快速上手Pytorch(可能是全网最全流程从0到部署)
但是发现有个关于梯度的部分没有说清楚,因为不同意tensorflow,pytorch由于没有声明式的去使用计算图,所以导致梯度的计算等等很容易出现消失的情况,然后就蹦了,这个问题经常遇到,比如我写第一个GAN网络,写第一个RL项目以及最近的目标检测框架的时候都会遇到。主要还是对它的一个梯度的记录传递方式有歧义,所以特地补充一下,在《啊哈~花一天快速上手Pytorch(可能是全网最全流程从0到部署)
》篇文章当中。
基本上这篇博文涵盖了很多内容,所以想要“光速”入门还需要把上面的博文看一下,大概看到这里:

就可以看到这里了。
Pytorch梯度
如果有了解过神经网络,或者线性回归的基本原理的话(我们这里待会依然使用线性回归作为例子)应该是知道的,求导,求梯度是非常重要的,并且手写偏导其实是有点复杂的,尤其是正对深层次的网络 ,值得庆幸的是,Pytorch自带微分库,并且可以直接求取出梯度,帮助我们运算。
而在这里numpy当中的数据和我们tensor的一个区别就是,我们的tensor具备梯度(虽然默认的时候不具备)
但是我们可以这样,让一个变量具备梯度:
a = torch.tensor(5.0,requires_grad=True)
然后我们这样操作:
a = torch.tensor(5.0,requires_grad=True)
b = a*5
c = b/2
print(b)
print(c)
with torch.no_grad():
d = b*c
print(d)
c.backward()
然后我们可以看到结果:
tensor(25., grad_fn=)
tensor(37.5000, grad_fn=)
tensor(937.5000)
我们先来分析dada
我们引入一个计算图的概念,这个在tensorflow里面太常见了,但是pytorch为了降低难度自动处理了。
我们创建了一个a变量,于是我们也对应的创建了一个正对a的计算链路,并且把他们放在一个图当中。
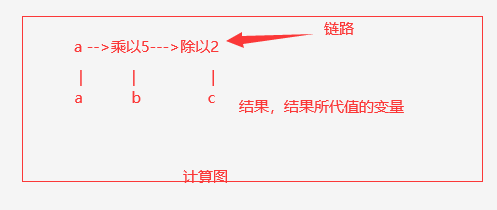
当我们的C反向传播的时候,我们先找到对应的链路,一直追溯,之后我们找到了a,最终得到了a的偏导。
所以这个时候你发现,无论你后面做了啥操作,我们一开始都可以定位到a,因为初始的a的内存是没有发生改变的,也就是说变量a并没有发生inplace操作,也就是a的内存没有发生改变,此时是正常的。
现在我们来模拟一些权重更新,我们引入另一个变量a2.代码变成这样。
import torch
a = torch.tensor(5.0,requires_grad=True)
a2 = torch.tensor(5.0,requires_grad=True)
b = a*5
c = b/2+a2*5
print(b)
print(c)
with torch.no_grad():
d = b*c
print(d)
c.backward()
于是在我们的图里面是这样的,我们加入了一个变量,但是最后两个变量需要一起计算,所以,我们从后往前计算的话,其实是可以知道a和a2是在一个图里面的

当C再次反向传播的时候,分别求导,然后追踪链路。
我们可以看到对应的梯度:
print(a.grad)
print(b.grad)
print(a2.grad)
tensor(2.5000)
None
tensor(5.)
并且注意到b并没有梯度,因为b只是中间变量。你可以理解为他只是一个值。
线性回归
原始版
现在我们再来看看线性回归。原先的例子是使用高级API,那么现在我们结合梯度,我们来看看最原始的写法(基于pytorch,更加原始的是基于numpy手动求导,感兴趣可以查看这篇文章《逻辑回归dome演示》。虽然是逻辑回归,但是和线性回归相比多了只是多一个激活函数,具体的步骤还是类似的,在理论推导上复杂一点,但是里面的代码我写的简单。
import torch
import numpy as np
from matplotlib import pyplot as plt
#1,准备数据y=3X+0.8,准备参数
x = torch.rand([500,1])
# 这个是我们需要拟合的目标函数
y=3*x+0.8
w=torch.rand([1,1],requires_grad=True)
b=torch.tensor(0,requires_grad=True,dtype=torch.float32)
leanning = 0.01
for i in range(100):
y_predict = torch.matmul(x,w)+b
loss = (y - y_predict).pow(2).mean()
if(w.grad is not None):
w.grad.data.zero_()
if(b.grad is not None):
b.grad.data.zero_()
loss.backward()
w.data = w.data - leanning*w.grad
b.data = b.data - leanning*b.grad
# 在net当中会自动更新,咱们这个是最古老的版本
if((1+i)%100==0):
print("w,b,loss",w.item(),b.item(),loss.item())
fig, ax = plt.subplots() # 创建图实例
ax.plot(x.numpy().reshape(-1),y.numpy().reshape(-1),label='y_true')
y_predict = torch.matmul(x,w)+b
ax.plot(x.numpy().reshape(-1),y_predict.detach().numpy().reshape(-1),label='y_pred')
结果如图:

高级API版
现在我们来使用高级一点的API,咱们来构建一下咱们的网络,是的我们可以使用这个神经网络来完成线性回归,因为神经网络里面其实就是线性层加激活函数,也就是线性回归之后再加入一个函数,然后求偏导。
import torch
import torch.nn as nn
from torch.optim import SGD
x=torch.rand([500,1])
y_true=3*x+0.8
#1.定义模型
class MyLinear(nn.Module):
def __init__(self):
super(MyLinear,self).__init__()
self.linear=nn.Linear(1,1)
def forward(self,x):
out=self.linear(x)
return out
#2.实例化模型,优化器类实例化,0ss实例化
my_linear=MyLinear()
optimizer=SGD(my_linear.parameters(),0.001)
#优化器,更新权重的 相当于这个
#w.data = w.data - leanning*w.grad
#b.data = b.data - leanning*b.grad
loss_fn=nn.MSELoss()
#3.循环,进行梯度下降,参数的更新
for i in range(2000):
y_predict=my_linear(x)
loss=loss_fn(y_predict,y_true)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if ((i+1)%100==0):
print(loss.item(),list(my_linear.parameters()))
优化器
这个也是我要补充的地方,这个正如你所见,这个优化器其实就是去更新咱们W 权重的玩意。
但是为什么要单独把这个说出来呢,原因很简单,任何优化算法基本上都无法避免出现一些收敛的问题,当然最重要的是原来那篇博文没说。
那么在神经网络里面的话,这个问题就在咱们的这个优化器里面,这个优化器是用来更新权重的,虽然这玩意的超参数只有一个
那就是学习率,但是这个学习率的影响对整个网络的收敛还是很大的,并且优化器是求导,如果目标函数存在多峰,那么对算法本身是否会产生局部最优
从而导致得到的模型并不是那么理想的模型,当然这个决定模型优劣的因素还有很多,事实上在现在细致推导学习一些机器学习算法之后,完整的模型运作推导都是模糊的,事实上我也想过这些优化器是否会有更好的优化再结合一些启发算法,最终我被一条定律定住了:天下没有免费午餐。在算力合适的情况下,在不完美的数据下,在“廉价”的算法下,得到一个看起来并不完美但是在执行范围内有一定可靠性是完全可以接受的,因为存在太多不确定性,通俗来说就是,不靠谱的不靠谱很有可能是靠谱…。当然这也是连接主义的魅力,至少相对于统计主义我不会掉那么多头发,公式是真难推,推起来是真累。
![]()
实时上,人家也是有讲究的。
我们来说说几个常见的。
这里咱们过一下就好,只需要知道,咱们有些优化器也是比较复杂的,理由有一些超参数的设定,在训练过程当中也是可以保存的,那么为什么能够保存,就是下面的原因。
(在网页当中Latex排版有点问题)
梯度下降算法(batch gradient descent BGD)
每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优
化,就是咱们先前的那个最原始的玩意,我们这里就只拿那个线性回归的例子来看,因为损失函数是单峰可导的。
随机梯度下降法(Stochastic gradient descent SGD)
针对梯度下降算法训练速度过慢的缺点,提出了随机梯度下降算法,随机梯度下降算法算法是从样
本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情
况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的横型了。
小批量梯度下降(Mini-batch gradient descent MBGD)
SGD相对来说要快很多,但是也有存在问题,由于单个样本的训练可能会带来很多噪声,使得SGD
并不是每次迭代都向若整体最优化方向,因此在刚开始训练时可能收敛得很快,但县训练一段时间
后就会变得很慢。在此基础上又提出了小批量梯度下降法,它是每次从样本中随机抽取一小批进行
训川练,而不是一组,这样即保证了效果又保证的速度。
动量法(Momentum)
mini-batch SGD算法虽然这种算法能够带来很好的训炼速度,但是在到达最忧点的时候并不能够总
是真正到达最优点,而是在最优点附近徘徊。
另一个缺点就是mini-batch SGDi需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,
会导致网格在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅
度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网终在优化的时候网络的损失函
数有一个很好的收敛速度同时又不至于摆动幅度太大。
所以Momentum优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平
均,对网格的参数进行平滑处理的,让梯度的摆动幅度变得更小。
v = 0.8 v + 0.2 ∇ w , ∇ w 示前 − 次的梯度 w = w − α v , α 表示学习率 \begin{align*} &v = 0.8v + 0.2 \nabla w &,\nabla w示前-次的梯度\\ &w = w - \alpha v &, \alpha表示学习率 \end{align*} v=0.8v+0.2∇ww=w−αv,∇w示前−次的梯度,α表示学习率
AdaGrad
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方系加后在开方,用全局学习率除以这个
数,作为学习率的动态更新,从而达到自适应学习率的效果
g r a d e n t = g r a d e n t + ( ∇ w ) 2 w = w − α g r a d e n t + δ ∇ w , δ 大约设置为 1 0 − 7 \begin{align*} &gradent = gradent + (\nabla w)^2 \\ &w = w-\frac{\alpha}{\sqrt{gradent}+\delta}\nabla w , &\delta 大约设置为10^{-7} \end{align*} gradent=gradent+(∇w)2w=w−gradent+δα∇w,δ大约设置为10−7
RMSProp
Momentum优化停法中,虽然初步解决了优化中摆动幅度大的问题,为了进一步优化损失函数在更
新中存在摆动幅度过大的问题,并旦进一步加快函数的收敛速度,RMSProp算法对参数的梯度使用
了平方加权平均数。
g r a d e n t = 0.8 ∗ h i s t o r y − g r a d e n t + 0.2 ∗ ( V w ) 2 w = w − α V w g r a d e n t + δ \begin{align*} gradent=0.8* history_ {-} gradent+0.2* (Vw)^ {2} \\ w=w - \alpha \frac {Vw}{\sqrt {gradent}+\delta } \end{align*} gradent=0.8∗history−gradent+0.2∗(Vw)2w=w−αgradent+δVw
Adam
Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用
的一种算法能够达到防止梯度的摆幅多大,同时还能够加开收敛速度
1. 需要初始化梯度的累积量和平方累积量 v w = 0 , s w = 0 2. 第 t 轮训练中 , 我们首先可以计算得到 M o m e n t u m 和 R M S P r o p 的参数更新 v w = 0.8 v + 0.2 V w , M o m e n t u m 计算的梯度 s w = 0.8 ∗ s + 0.2 ∗ ( V w ) 2 , R M S P r o p 计算的梯度 3. 对其中的值过行处理后 , 得到 : w = w − α v w s m + δ \begin{align*} 1.需要初始化梯度的累积量和平方累积量\\ v_ {w} =0, s_ {w} =0 \\ 2.第t轮训练中, 我们首先可以计算得到Momentum和RMSProp的参数更新\\ v_ {w} =0.8v+0.2Vw ,Momentum计算的梯度\\ s_ {w} =0.8*s+0.2* (Vw)^ {2} , RMSProp计算的梯度\\ 3.对其中的值过行处理后, 得到: w=w- \alpha \frac {v_ {w}}{\sqrt {s_ {m}+\delta }} \\ \end{align*} 1.需要初始化梯度的累积量和平方累积量vw=0,sw=02.第t轮训练中,我们首先可以计算得到Momentum和RMSProp的参数更新vw=0.8v+0.2Vw,Momentum计算的梯度sw=0.8∗s+0.2∗(Vw)2,RMSProp计算的梯度3.对其中的值过行处理后,得到:w=w−αsm+δvw
手写数字案例
这个案例的话其实就是因为,在我们上一篇文章当中呢,稍微复杂了一下,尤其是后面还涉及到部署到底问题,然后里面的卷积啥的也是复杂一点,所以这里用一个更加简单的案例去做。
数据集
这个数据集咱们就直接使用Pytorch为我们提供的。
from torchvision.datasets import MNIST
mnist = MNIST(root="./data",train=True,download=True)
print(mnist)
这个玩意会帮我们下载,自动下载的。训练集和测试集人家都有。
那么这个数据呢他会自动下载如果你指定的地方没有人家会自动下载的。
就像这样:

然后这个数据长这样:

首先训练有6W张图片,验证集有1W张,但都是小图片,所以下载很快很小。它的数据是1张图片+图片的数字是啥,一张图片的大小是28x28只有一个通道,因为是黑白的。
数据划分
所以搞明白了这个,咱们就可以划分数据集了。
我们先写一个加载函数:
def get_dataloader(train=True):
transform_fn =Compose([
ToTensor(),
Normalize(mean=(0.1307,),std=(0.3081,))
#mean和std的形状和通道数相同
])
dataset=MNIST(root="./data",train=train,transform=transform_fn)
data_loader=DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True)
return data_loader
其中涉及到图片转换,这个那篇文章有。
train_loader = get_dataloader() #训练数据集
test_loader=get_dataloader(train=False) # 验证数据集
网络构建
我们这里构建一个非常简单的网络,并且由于图片格式非常小,所以我们这里也不需要使用卷积,直接去做全连接,这部分。
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet,self).__init__()
self.fc1=nn.Linear(28*28,28)#定义Linear的偷入和偷出的形状
self.fc2=nn.Linear(28,10)#定义Linear的输入和输出的形状
def forward(self,x):
x=x.view(-1,28*28)#对数据形状变形,-1示该位五根据后面的形状自动调整
x=self.fc1(x)#[batch_size,28]
x=F.relu(x)#[batch_size,28]
x=self.fc2(x)#[batch_size,10]
return x
训练与验证
这个训练部分和咱们刚刚的线性回归是类似的。
def train(epochs,test_times = 1):
for epoch in range(epochs):
for i, data in enumerate(train_loader):
inputs, labels = data
outputs = mnistNet(inputs)
optimizer.zero_grad()
loss = criterion(outputs,labels)
loss.backward()# backward之后计算出梯度
optimizer.step()
if((i+1)%100==0):
print(epoch,i,loss.item())
if((epoch+1)%20==0):
#每训练20次临时保存一次
torch.save(mnistNet.state_dict(),"./model_temp.pt")
torch.save(optimizer.state_dict(),'./optimizer_temp.pt')
if((epoch+1)%test_times==0):
test()
torch.save(mnistNet.state_dict(),"./model_last.pt")
torch.save(optimizer.state_dict(),'./optimizer_last.pt')
但是验证是什么意思呢,其实就是评估,咱们训练了一个模型,之后输入新的数据,然后看看输出结果对得到多少个,来评判我们模型的好坏。
def test():
test_loss =0
correct = 0
mnistNet.eval()
with torch.no_grad():
#不计算其悌度
for data,target in test_loader:
output=mnistNet(data)
loss = criterion(output,target)
test_loss+=loss.item()
pred=output.data.max(1,keepdim=True)[1]#获取最大值的位置, [batch_size,1]
correct+=pred.eq(target.data.view_as(pred)).sum()#预测的数字在一个batchsize里面对了几个
test_loss/=len(test_loader)
print('\nTest set:Avg.loss:{:.4f},Accuracy:{}/{}({:.2f}%)'.format(
test_loss,correct,len(test_loader.dataset),100.0*(correct/len(test_loader.dataset))
)
)
完整代码
from torch.utils.data import DataLoader
import torch.nn as nn
from torch.optim import Adam
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torchvision.transforms import Compose,ToTensor,Normalize
import torch
import os
BATCH_SIZE =128
#1.准备数据集
def get_dataloader(train=True):
transform_fn =Compose([
ToTensor(),
Normalize(mean=(0.1307,),std=(0.3081,))
#mean和std的形状和通道数相同
])
dataset=MNIST(root="./data",train=train,transform=transform_fn)
data_loader=DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True)
return data_loader
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet,self).__init__()
self.fc1=nn.Linear(28*28,28)#定义Linear的偷入和偷出的形状
self.fc2=nn.Linear(28,10)#定义Linear的输入和输出的形状
def forward(self,x):
x=x.view(-1,28*28)#对数据形状变形,-1示该位五根据后面的形状自动调整
x=self.fc1(x)#[batch_size,28]
x=F.relu(x)#[batch_size,28]
x=self.fc2(x)#[batch_size,10]
return x
#pytorch 的交叉熵自带softmax
criterion=nn.CrossEntropyLoss()
mnistNet = MnistNet()
optimizer = Adam(mnistNet.parameters(),lr=0.001)
train_loader = get_dataloader() #训练数据集
test_loader=get_dataloader(train=False) # 验证数据集
if(os.path.exists("./model_last.pt")):
mnistNet.load_state_dict(torch.load("./model_last.pt"))
if(os.path.exists("./optimizer_last.pt")):
optimizer.load_state_dict(torch.load("./optimizer_last.pt"))
def test():
test_loss =0
correct = 0
mnistNet.eval()
with torch.no_grad():
#不计算其悌度
for data,target in test_loader:
output=mnistNet(data)
loss = criterion(output,target)
test_loss+=loss.item()
pred=output.data.max(1,keepdim=True)[1]#获取最大值的位置, [batch_size,1]
correct+=pred.eq(target.data.view_as(pred)).sum()#预测的数字在一个batchsize里面对了几个
test_loss/=len(test_loader)
print('\nTest set:Avg.loss:{:.4f},Accuracy:{}/{}({:.2f}%)'.format(
test_loss,correct,len(test_loader.dataset),100.0*(correct/len(test_loader.dataset))
)
)
def train(epochs,test_times = 1):
for epoch in range(epochs):
for i, data in enumerate(train_loader):
inputs, labels = data
outputs = mnistNet(inputs)
optimizer.zero_grad()
loss = criterion(outputs,labels)
loss.backward()# backward之后计算出梯度
optimizer.step()
if((i+1)%100==0):
print(epoch,i,loss.item())
if((epoch+1)%20==0):
#每训练20次临时保存一次
torch.save(mnistNet.state_dict(),"./model_temp.pt")
torch.save(optimizer.state_dict(),'./optimizer_temp.pt')
if((epoch+1)%test_times==0):
test()
torch.save(mnistNet.state_dict(),"./model_last.pt")
torch.save(optimizer.state_dict(),'./optimizer_last.pt')
train(2)
总结
至此,恭喜你完成了光速入门!