GhostNet网络思路整理(讨论)
GhostNet介绍
GhostNet是由华为诺亚方舟实验室研究出新的网络神经框架在2020年CVPR上发布文章,该模型和代码已在GitHub上开源。
GhostNet论文:link.
GitHub代码:link
Ghost Module
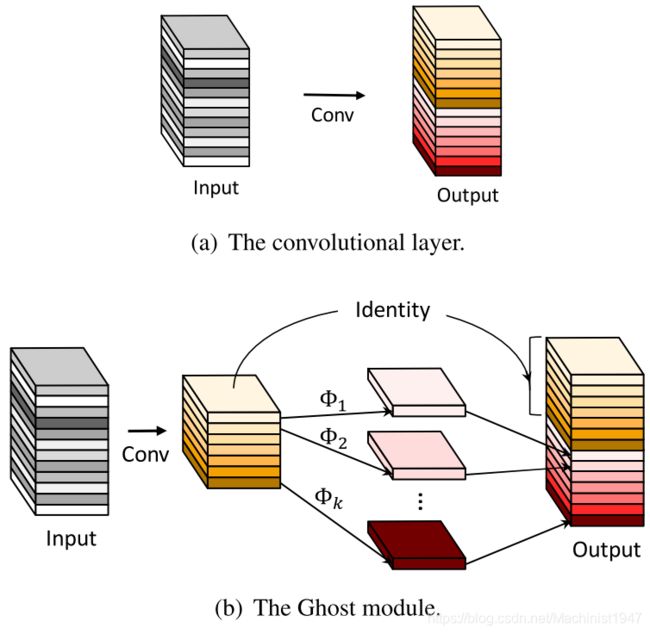
如上图,图(a)表示卷积,特征图(feature map)由输入图像进行卷积操作得到.图(b)表示Ghost Module需要进行两步卷积操作,由输入图像进行第一次卷积操作生成一部分feature map1,在由feature map1进行第二次卷积操作生成更多的feature map2,将两次卷积生成的feature map进行串联输出。Ghost Module源代码如下。
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
在输入参数inp第一次卷积输入通道数,oup表示Ghost Module输出张量通道数,init_channels是第一次卷积操作输出通道数,new_channels是第二次卷积操作输出通道数,ratio是原文中的s,primary_conv(b图中左半部分)点卷积操作卷积核大小等于1,stride等于1,padding等于0,输出图像大小不变。cheap_operation(b图右半部分)深度卷积操作卷积核大小等于3,stride等于1,padding等于1,输出图像大小不变。输入图像分别经过primary_conv和cheap_operation,使用torch.cat将两次卷积输出串联,截取oup数目的通道数输出。
我个人觉的在GhostNet原文中对Ghost Module模块的描述与源程序中有些不一样(有明白的小伙伴欢迎评论指导)。
Ghost bottleneck
Ghost bottleneck是由Ghost Module丢叠出来的,有两种形势如下图所示。
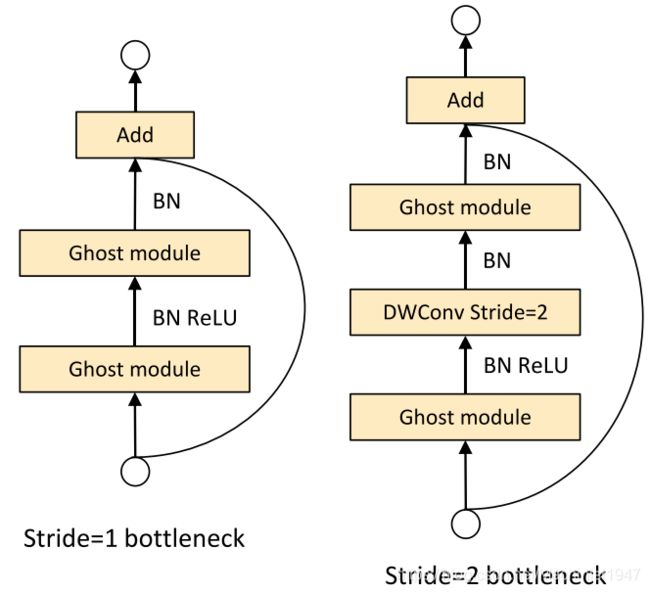
两种Ghost bottleneck主要的区别方式就是stride值。
Ghost bottleneck(stride=1)
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.): #
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += residual
return x
在stride=1时,Ghost bottleneck由两个Ghost Module构成,在正向传播时运用了残差思想(我个人理解),讲输出与输入相加。
Ghsot bottleneck(stride=2)
在说Ghsot bottleneck(stride=2)之前先解释下什么是SE块,shortcut块。
SE块是为了解决在卷积池化过程中feature map的不同通道所占的重要性不同带来的损失。主要包括两部分squeeze和Excitation两部分,如下图所示:

设输入图像(C,H,W),首先使用全局池化(Global average pooling),核大小为(H,W),输出图像为(C,1,1),在使用点卷积对(C,1,1)进行通道数压缩输出图像为(C1,1,1),且C1小于C。经过非线性变换(ReLU)后,使用点卷积对(C1,1,1)进行通道数扩增输出图像为(C,1,1),进行sigmoid变化,将输出与输入图像(C,H,W)相乘,为图像每个通道赋权重。GhostNet中使用SE块代码如下
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None,
act_layer=nn.ReLU, gate_fn=hard_sigmoid, divisor=4, **_):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
其中_make_divisible函数它确保所有层都有一个可被8整除的通道号码。代码如下。
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor # 16 4 4
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
shortcut(结合网上的个人观点),shortcut最早出现在论文Training Very Deep Networks中的第二节。为解决深度网络训练中梯度发散难以训练的问题所提出的shortcut。一般的前馈神经网络中x表示输入y表示输出,Wh表示权重,H表示非线性变换,输入x与输出y具有下图中一般前馈神经网络。shortcut是在一般前馈神经网络上增加T和C非线性变换。在残差块中T和C等于1。在Dense中T和C等于1并串联输出。
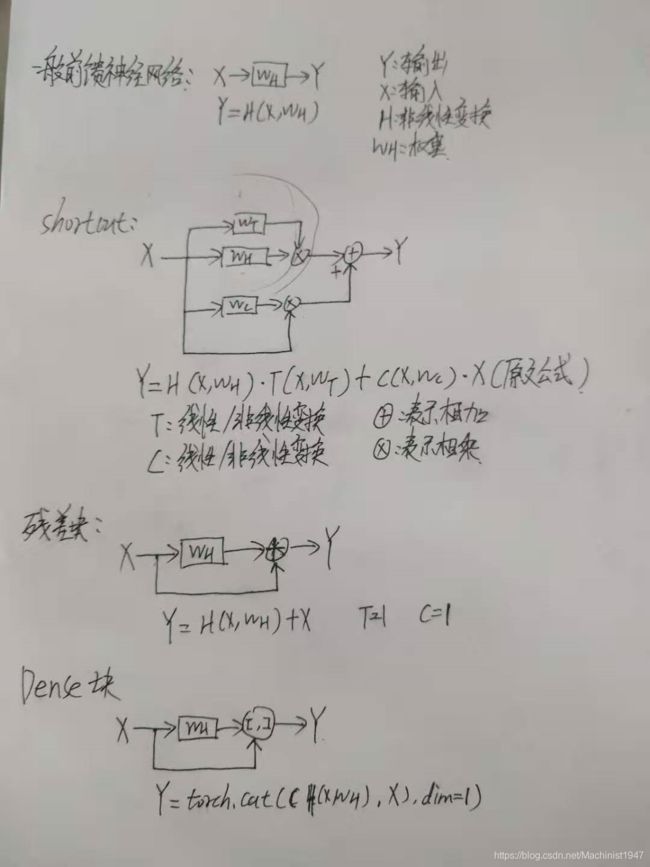
Ghsot bottleneck(stride=2)也借用shortcut思想在前馈网络中增加非线性变换,在Ghsot bottleneck(stride=2)中输入与前馈神经网络连接处。
Ghsot bottleneck(stride=2)源代码如下所示:
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.): #
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride, padding=(dw_kernel_size-1)//2, groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x
与Ghsot bottleneck(stride=1)区别在于经过ghost1后接的是一个深度卷积卷积层(核大小为3,stride为1,padding为1输出图像大小保持不变)、一个批量归一化层(作用是利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定)和SE块。SE块后接ghost2,ghost2与shortcut输出相加。
shortcut结构是由深度卷积接批量归一化层接点卷积(改变通道数)接批量归一化层构成的。接下来就是Ghost Net整体结构。
GhostNet
源代码中与论文中只有每个block中Ghost bottleneck个数不同,整体结构相同,文中以源代码结构说明,源代码如下所示。
# 2020.06.09-Changed for building GhostNet
# Huawei Technologies Co., Ltd. GhostNet主要是由5个block组成,每个block由堆叠的Ghost bottleneck组成。
GhostNet最开始是一个卷积块1包含卷积层(kernel=3,stride=2,padding=1),批量归一化层和激活函数层,目的是将输入图像大小减半;
block1包含一个Ghost bottleneck(stride=1);
block2包含Ghost bottleneck(stride=2)和Ghost bottleneck(stride=1);
block3包含Ghost bottleneck(stride=2)和Ghost bottleneck(stride=1);
block4包含Ghost bottleneck(stride=2)和5个Ghost bottleneck(stride=1);
block5包含Ghost bottleneck(stride=2)和4个Ghost bottleneck(stride=1);
block5后接卷积块2包含一个点卷积,批量归一化层和激活函数层,作用是改变图像通道数。
卷积块2后接全局池化层对feature map进行降维。后接点卷积来改变通道数。
最后是全连接分类层(我记的是这个名),输出通道数为数据类别数。
这就是整个GhostNet结构。
有错误的地方法欢迎各位小伙伴指出。