MySQL8.0 MGR介绍
常见的数据库高可用是通过创建计算数据节点冗余来确保数据库的节点宕机不会影响系统的运行,但这会导致数据库的架构复杂,运维成本提升,此外,还需要解决分布式可能所带来的脑裂,数据一致性问题。
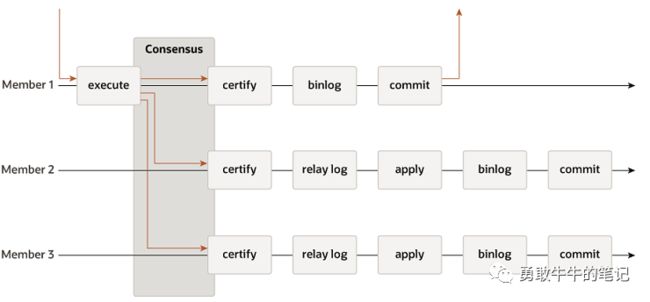
MySQL MGR插件基于分布式Paxos算法,协调多个数据库节点进行数据复制,事务一致性检验,故障自动检测选主,节点添加删除,MGR有两种模式,单主模式以及多主模式。
MGR复制与传统复制的区别:
异步复制:复制性能没有损耗,主库提交事务不需要从库的确认,数据一致性没法保证。
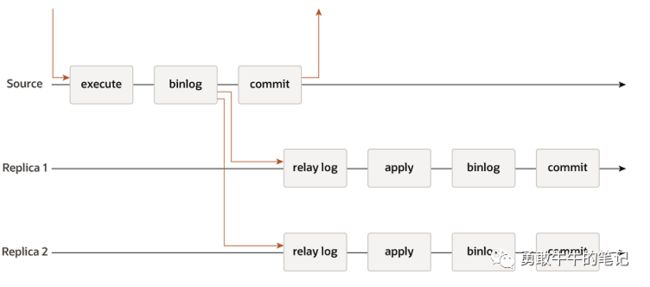
半同步复制:主库提交事务需要等待从库的确认,复制性能会有损耗,保证数据一致性
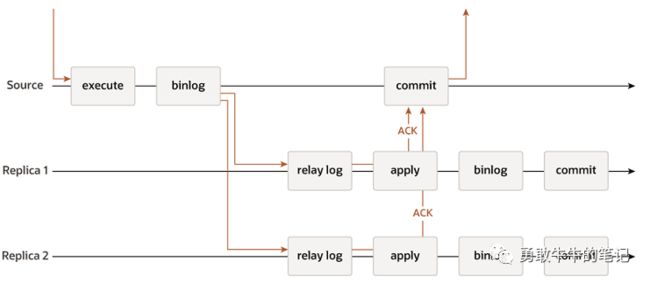
MGR复制:组复制采用Paxos分布式算法以及原子消息广播,主节点提交的事务会原子广播write set(由唯一标识以及更新的数据组成)到其他节点进行验证,由于采用原子广播的技术,全部节点要么全部接收或者全部没有接受,如果出现两个以上的事务操作同一行数据,产生数据冲突,会采用提交时间优先的原则,假设t1以及t2同时更新相同的一行数据,t2的提交操作在t1之前,则发生数据冲突时,t1的数据会被回滚,复制性能会有损坏,保证数据一致性。
单主模式与多主模式:
单主模式:
在单主模式下,只有一个主节点可以进行写入,其他节点都为只读状态,由于只有一个主节点写入,与多主模式相比,数据事务一致性的检测不需要严格,DDL同步也不需要额外的处理。
单主模式下,主节点在以下方式会进行改变:
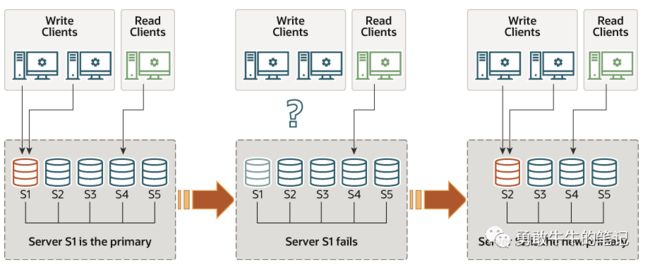
主节点由于异常或者人为的操作导致离开组,这时候新的主节点将会被自动的选举。
使用函数group_replication_set_as_primary指定主节点。
使用group_replication_switch_to_single_primary_mode进行多主到单主的切换,这时候一个新的主节点会被自动的选举出来。
单主切换流程图:
单主选主算法:
自动选主过程每个成员都会查看组的新视图,对潜在的组成员排序优先级,选择出最合适的组成员,每个组成员会根据自身MySQL版本的选组算法做出自己的决定,因为全部的组成员需要做出一致的决定,所以如果组成员中有MySQL较低版本的成员,则成员需要会调整选主的算法,以达到与同组较低版本的成员具有相同的准则。
主成员选举有以下需要考虑的因素
1 第一个考虑的因素是组或者成员中运行的最低MySQL版本,如果全部成员都运行在MySQL8.0.17及以上,则按补丁号进行排序,如果有其中一个成员跑在5.7 or 8.0.16及以下,则按大版本排序,忽略补丁版本。
2 如果超过一个成员运行在MySQL低版本,则第二个考虑的因素为成员在组里面的权重,系统变量group_replication_member_weight所识别的大小,如果存在一个成员运行在MySQL 5.7版本的,则变量是无效的,需要忽略该因素。
3 如果超过一个成员运行在MySQL低版本并且其中一个以上的成员具有最高的成员权重(或成员权重被忽略),则考虑第三个因素每个成员产生的UUID的字段顺序,最低顺序的uuid成员将被选为主节点,这个因素是一个有保证并且适用于每个MySQL版本以确保在任何因素都无法确定的情况下,所有小组成员都能做出相同的决定。
多主模式:
在多主模式下,每个节点都可以读写事务,不需要指定专门的节点角色,相比单主模式,需要严格的数据事务一致性检测以及DDL复制处理。
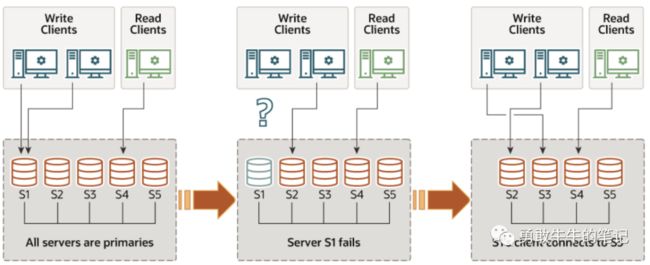
如果出现节点不可访问或者节点离开组的情况,只需要客户端完成连接重定向,连接到其他节点即可,不需要进行主切换,但MGR不负责连接的重定向,需要proxy或者应用自己完成。
在多主模式下,会进行以下严格的事务检测
1 如果事务执行在serializable隔离级别,当同步到其他节点时,事务会提交失败。
2 如果事务执行在带有外键约束的表,当同步到其他节点时,事务会提交失败。
在多主模式下,进行DDL语句操作时,需要把DDL操作以及DML操作都在同一个节点发起,或者会造成数据的冲突或者不一致。
为了获得最佳的兼容性与性能,全部组复制成员都应该运行在相同的MySQL版本,在多主模式下,这是必须的,因为如果组成员的版本不一致,可能导致组成员存在不一致的功能组件,函数,当成员加入组时,会进行版本的检测,如果加入成员的版本高于现有成员中的最低版本,则加入的成员会被保持只读状态运行 ,MySQL 8.0.17 或更高版本的成员在检查其兼容性时会考虑发行版的补丁版本,运行 MySQL 8.0.16 或更低版本或 MySQL 5.7 的成员仅考虑主要版本。
多主模式中,在使用不同MySQL Server版本的组中,MGR自动管理运行MySQL 8.0.17 或更高版本的成员的读写和只读状态。如果成员离开组,运行现在最低版本的成员将自动设置为读写模式。当单主模式下运行的组更改为在多主模式下运行时,使用group_replication_switch_to_multi_primary_mode()函数,组复制会自动将成员设置为正确的模式。如果成员运行的MySQL服务器版本高于组中存在的最低版本,则成员将自动置于只读模式,而运行最低版本的成员将置于读写模式。
组成员资格:
在MySQL组复制,复制组由若干服务器节点组成,每个组都有一个uuid的命名,组是动态的,成员可以随时离开或者加入。
如果一个新服务加入组,他会通过从现有的服务去获取缺失的状态来更新自己,而一个服务离开组,则其他现有的成员会察觉到该成员的离开并自动更新组信息。
MGR有一个组成员服务,他定义了当前组里面在线参与了哪些成员,在线成员信息会关联显示到视图,每个成员都有一致性的视图,视图会显示在给定的时间点活跃加入组的成员。
组成员不但需要确认事务的提交,还要维护当前成员视图信息,如果当前成员同意新新成员加入组,成为组的一部分,这会触发视图的改变,同样,如果一个服务离开组,不管是自愿还是非自愿,组将会动态的重新配置并触发视图的改变。
在组成员自愿离开组的情况下,首先需要初始化动态组配置,期间所有成员必须在没有离开服务下就新视图达成一致,然而,如果出现成员非自愿的离开,例如由于异常的宕机,网络故障,这时候无法进行初始化配置,在这种情形下,MGR故障检测机制会在短时间内发现失败成员的离开,在不需要失败成员的参与下进行重配置组,重配置组需要大多数成员达成一致,然而,可能出现成员不能达成一致的情况,例如由于组成员服务器划分问题,导致大部分的成员没有在线,这样没法完成重配置,为了防止脑裂的发生,组复制将不会对外提供服务,这种情况需要DBA介入处理。
一个成员可能会在短时间内下线,然后在故障检测机制检测到其故障之前以及在重新配置组以删除该成员之前再次尝试重新加入该组。在这种情况下,重新加入的成员会忘记其先前的状态,但如果其他成员向其发送旨在用于其崩溃前状态的消息,这可能会导致问题,包括可能的数据不一致。如果处于这种情况的成员参与 XCom 的共识协议,则可能会导致 XCom 在失败前后做出不同的决定,从而为同一轮共识提供不同的值。
为了应对这种可能性,从 MySQL 5.7.22 和 MySQL 8.0 开始,Group Replication 会检查同一服务器的新版本尝试加入组而其旧版本(具有相同地址和端口号)仍然存在的情况。新的化身被阻止加入组,直到旧的化身可以通过重新配置移除。 通过 group_replication_member_expel_timeout 系统变量可以添加剔除等待时间,以允许成员在被驱逐之前有额外的时间重新连接到该组,如果被剔除的节点在等待时间之内重新连接到组,则它可以作为其当前化身再次活跃在组里。当成员超过等待时间并被驱逐出组时或者当组复制在服务器上由 STOP GROUP_REPLICATION 语句或服务器故障停止时,它必须作为新的化身重新加入。
故障检测:
MGR的故障检测机制是一种分布式服务,它能够识别出组中哪一个服务器没有与其他服务器通信,并推测出异常的成员,组成员会做出协调一致决定开除该成员。开除通信异常的成员是必要的,因为该组需要其大多数成员就事务或视图更改达成一致。如果成员不参与这些决策,则组必须将其删除以增加该组包含大多数正确工作成员的机会,从而可以继续处理事务。
在复制组中,每个成员都有一个到其他成员的点对点通信通道,从而创建一个全连接图。这些连接由组通信引擎(XCom,Paxos )管理并使用 TCP/IP socket。一个通道用于向成员发送消息,另一个通道用于接收来自成员的消息。如果一个成员在 5 秒内没有收到另一个成员的消息,则怀疑该成员发生故障,并在自己的 Performance Schema 表 replication_group_members 中将该成员的状态列为 UNREACHABLE。通常,两个成员会怀疑对方失败了,因为他们彼此之间没有交流。或者存在成员 A 怀疑成员 B 失败但成员 B 不怀疑成员 A 失败,这种情况发生概率较低,通常是由于路由或防火墙问题。成员也可以对自己产生怀疑,与其他成员隔离的成员怀疑所有其他成员都失败了。
如果怀疑持续超过 10 秒,则怀疑成员会尝试将其认为可疑成员有错误的观点传播给该组的其他成员。可疑成员仅在它是通知者时才这样做,根据其内部 XCom 节点编号计算得出。如果一个成员实际上与该组的其他成员隔离,它可能会尝试传播其观点,但这不会产生任何后果,因为它无法确保其他成员的法定人数同意它。仅当成员是通知者时,怀疑才会产生后果,并且其怀疑持续时间足够长以传播给该组的其他成员,并且其他成员对此表示同意。在这种情况下,可疑成员在协调决策中被标记为从组中驱逐,并在 group_replication_member_expel_timeout 设置的超时时间到期并且驱逐机制检测并实施驱逐后被驱逐。
在网络不稳定且成员之间经常以不同的组合方式失去和恢复连接的情况下,理论上一个组可以最终将其所有成员标记为驱逐,之后该组将不复存在并重新建立。为了应对这种可能性,从MySQL 8.0.20开始,MGR的Group Communication System (GCS)会跟踪已标记为驱逐的组成员,并在确认是否有多数成员同意将他们视为可疑成员组中的成员 . 这确保了至少一个成员保留在组中并且组可以继续存在。 当一个被开除的成员实际上已从组中删除时,GCS会删除其标记该成员为驱逐的记录,以便该成员可以重新加入该组。
故障冗余:
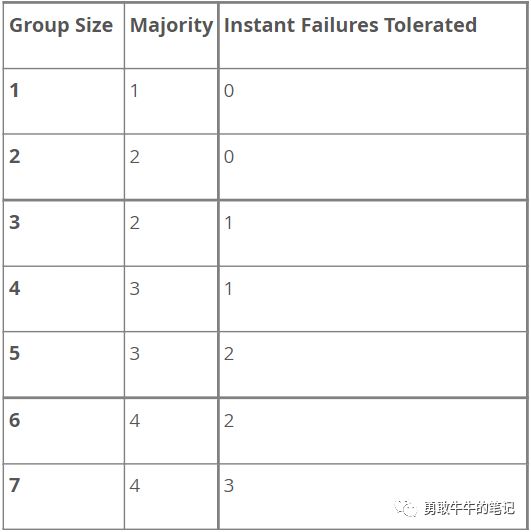
MGR建立在Paxos 分布式算法的实现之上,以提供服务器之间的分布式协调。因此,它需要大多数服务器处于活动状态才能达到法定人数并做出决定。 这直接影响系统在不影响自身及其整体功能的情况下可以容忍的故障数量。 容忍 f 次故障所需的服务器数量 (n) 为 n = 2 x f + 1。实际上,这意味着要容忍一个故障,组中必须有三台服务器。 因此,如果一台服务器出现故障,仍然有两台服务器构成多数(三分之二),并允许系统继续自动做出决策并取得进展。 但是,如果第二台服务器非自愿发生故障,则该组(仅剩一台服务器)会阻塞,因为没有多数人可以做出决定。
可观察:
MGR可以通过Performance用户下的表查询系统的整个状态(包括视图、冲突统计和服务状态)。 复制协议的分布式特性以及组成员事务和元数据上的同步,使得检查组的状态变得更加简单。 例如,您可以连接到组中的单个服务器,并通过在组复制相关的Performance用户表上来获取本地和全局信息。
MGR插件结构:
MGR是一个MySQL插件,它建立在现有的MySQL复制基础架构之上,利用了二进制日志、基于行的日志记录和全局事务标识符等功能。它与当前的 MySQL框架集成,例如performance schema 或插件和服务基础架构。
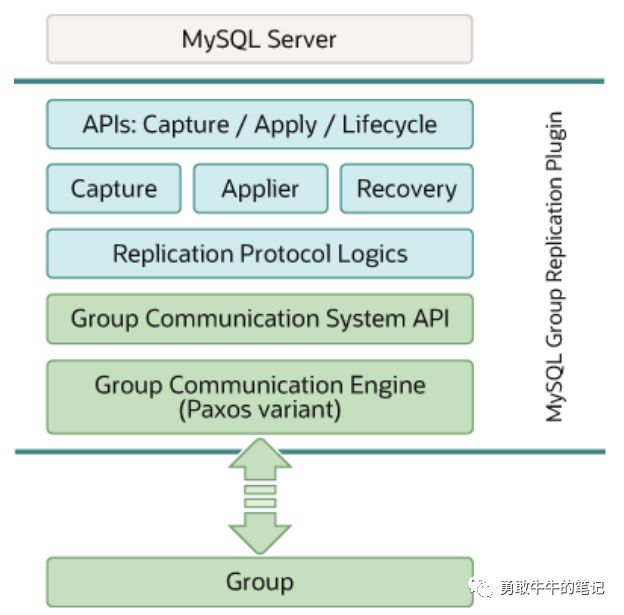
MGR 插件包括一组用于捕获、应用和生命周期的 API,它们控制插件与 MySQL 服务器的交互方式。有一些接口可以使信息从服务器流向插件,反之亦然。这些接口将 MySQL Server 核心与 Group Replication 插件隔离开来,并且主要是放置在事务执行管道中。在一个方向,从服务器到插件,有事件通知,例如服务器启动、服务器恢复、服务器准备接受连接以及服务器即将提交事务。另一方面,插件指示服务器执行诸如提交或中止正在进行的事务或在中继日志中排队事务等操作。
MGR插件架构的下一层是一组组件,这些组件在将通知路由到它们时做出反应。捕获组件负责跟踪与正在执行的事务相关的上下文。应用程序组件负责在数据库上执行远程事务。恢复组件管理分布式恢复,并负责通过选择捐助者、管理追赶程序和对捐助者故障作出反应来使加入组的服务器数据达到一致。
继续往下看,复制协议模块包含复制协议的特定逻辑。它处理冲突检测,并接收事务并将其传播到组。
组复制插件架构的最后两层是组通信系统 (GCS) API,以及基于 Paxos 的组通信引擎 (XCom) 的实现。 GCS API 是一个高级 API,它抽象了构建复制状态机所需的属性。因此,它将消息传递层的实现与插件的其余上层分离。组通信引擎处理与复制组成员的通信。