文字合成语音的方法 -两个离线包,百度接口,一个开源项目
目标是将我们输入的文本文字转换为语音。
使用 pyttsx 将文本转化为语音
使用名为 pyttsx 的 python 包,你可以将文本转换为语音。直接使用 pip 就可以进行安装,
命令:pip install pyttsx3
使用实例:
import pyttsx3 as pyttsx
engine = pyttsx.init()
engine.say('你好吗')
engine.runAndWait()使用 SpeechLib将文本转化为语音
使用 SpeechLib,可以从文本文件中获取输入,再将其转换为语音。先使用 pip 安装。
命令:pip install comtypes
使用实例:
from comtypes.client import CreateObject
from comtypes.gen import SpeechLib
#实例化拼读对象
engine=CreateObject('SAPI.SpVoice')
#实例化文件流对象
stream=CreateObject('SAPI.SpFileStream')
infile='demo.txt'
outfile='demo_audio.wav'
# 打开流文件,以读文本录入
stream.open(outfile,SpeechLib.SSFMCreateForWrite)
#输出方式流媒体
engine.AudioOutputStream=stream
#读取文本内容
f=open(infile,'r',encoding='utf-8')
theText=f.read()
f.close()
engine.speak(theText)
stream.close()使用 百度接口api
使用 百度接口,可以从文本文件中获取输入,再将其转换为语音。不过超过免费额度之后会收费。
API_KEY ,SECRET_KEY 码需要去百度ai平台注册,领取。
使用实例:
import sys
import json
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
API_KEY = '******************************'
SECRET_KEY = '******************************'
TEXT = "三分钟前,由北京市顺义区二经路与二纬路交汇处北侧,北京首都国际机场T3航站楼 去往 东城区北三环东路36号喜来登大酒店(北京金隅店)"
TTS_URL = 'http://tsn.baidu.com/text2audio'
""" TOKEN start """
TOKEN_URL = 'http://openapi.baidu.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.code))
result_str = err.read()
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'audio_tts_post' in result['scope'].split(' '):
print ('please ensure has check the tts ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
""" TOKEN end """
if __name__ == '__main__':
token = fetch_token()
tex = quote_plus(TEXT) # 此处TEXT需要两次urlencode
params = {'tok': token, 'tex': tex, 'cuid': "quickstart",
'lan': 'zh', 'ctp': 1} # lan ctp 固定参数
data = urlencode(params)
req = Request(TTS_URL, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
headers = dict((name.lower(), value) for name, value in f.headers.items())
has_error = ('content-type' not in headers.keys() or headers['content-type'].find('audio/') < 0)
except URLError as err:
print('http response http code : ' + str(err.code))
result_str = err.read()
has_error = True
save_file = "error.txt" if has_error else u'大姚的订单信息.mp3'
with open(save_file, 'wb') as of:
of.write(result_str)
if has_error:
if (IS_PY3):
result_str = str(result_str, 'utf-8')
print("tts api error:" + result_str)
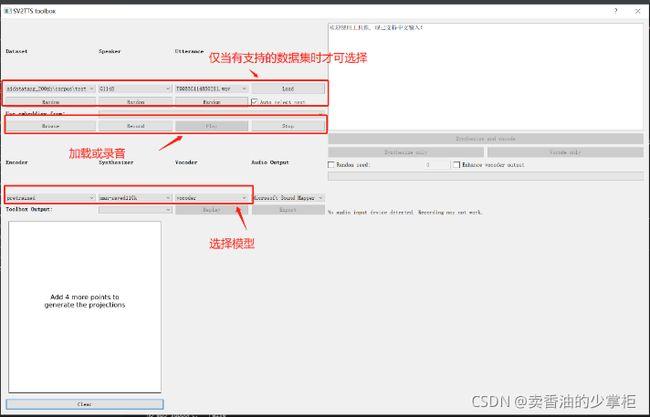
print("file saved as : " + save_file)推荐一个Git开源项目通过神经网络合成声音
项目名称:
Mocking Brid -----gitee地址:
MockingBird: AI拟声: 克隆您的声音并生成任意语音内容 Clone a voice in 5 seconds to generate arbitrary speech in real-time
文件结构:
├─archived_untest_files 废弃文件
├─encoder encoder模型
│ ├─data_objects
│ └─saved_models 预训练好的模型
├─samples 样例语音
├─synthesizer synthesizer模型
│ ├─models
│ ├─saved_models 预训练好的模型
│ └─utils 工具类库
├─toolbox 图形化工具箱
├─utils 工具类库
├─vocoder vocoder模型(目前包含hifi-gan、wavrnn)
│ ├─hifigan
│ ├─saved_models 预训练好的模型
│ └─wavernn
└─web
├─api
│ └─Web端接口
├─config
│ └─ Web端配置文件
├─static 前端静态脚本
│ └─js
├─templates 前端模板
└─__init__.py Web端入口文件
使用方法:
1, 安装相关环境依赖:
命令:pip install -r requirements.txt,
pip install webrtcvad-wheels,
安装pyTorch : Start Locally | PyTorch
2, 准备预训练模型: 可以训练自己专属的模型或者下载社区他人训练好的模型,这里我们可以先下载别人训练好的模型:
百度盘链接:https://pan.baidu.com/s/1VHSKIbxXQejtxi2at9IrpA
提取码:i183
3, 将下载好的模型放在synthesizer/saved_models/mandarin路径下。
4, 启动Web程序
python web.py 运行成功后在浏览器打开地址, 默认为 http://localhost:8080

5, 也可以使用工具箱启动:
命令:python demo_toolbox.py -d