硬刚Doris系列」Apache Doris基本使用和数据模型
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜
![]()
轻戳有惊喜:八股文教给我,你们专心刷题和面试
一. 基础使用
1.1 创建数据库
MySQL> CREATE DATABASE example_db;
MySQL> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| example_db |
| information_schema |
+--------------------+
2 rows in set (0.00 sec)1.2 建表
Doris支持支持”单分区"和""复合分区""两种建表方式。
在复合分区中:
第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
以下场景推荐使用复合分区
有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不使用复合分区,即使用单分区。则数据只做 HASH 分布。
下面以聚合模型为例,分别演示两种分区的建表语句。
1.2.1 单分区
建立一个名字为 table1 的逻辑表。分桶列为 siteid,桶数为 10。
这个表的 schema 如下:
siteid:类型是INT(4字节), 默认值为10
citycode:类型是SMALLINT(2字节)
username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
建表语句如下:
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");1.2.2 复合分区
建立一个名字为 table2 的逻辑表。
这个表的 schema 如下:
event_day:类型是DATE,无默认值
siteid:类型是INT(4字节), 默认值为10
citycode:类型是SMALLINT(2字节)
username:类型是VARCHAR, 最大长度为32, 默认值为空字符串
pv:类型是BIGINT(8字节), 默认值是0; 这是一个指标列, Doris 内部会对指标列做聚合操作, 这个列的聚合方法是求和(SUM)
我们使用 event_day 列作为分区列,建立3个分区: p201706, p201707, p201708
p201706:范围为 [最小值, 2017-07-01)
p201707:范围为 [2017-07-01, 2017-08-01)
p201708:范围为 [2017-08-01, 2017-09-01)
注意区间为左闭右开。
每个分区使用 siteid 进行哈希分桶,桶数为10
建表语句如下:
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p201706 VALUES LESS THAN ('2017-07-01'),
PARTITION p201707 VALUES LESS THAN ('2017-08-01'),
PARTITION p201708 VALUES LESS THAN ('2017-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");表建完之后,可以查看 example_db 中表的信息:
MySQL> SHOW TABLES;
+----------------------+
| Tables_in_example_db |
+----------------------+
| table1 |
| table2 |
+----------------------+
2 rows in set (0.01 sec)
MySQL> DESC table1;
+----------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-------+---------+-------+
| siteid | int(11) | Yes | true | 10 | |
| citycode | smallint(6) | Yes | true | N/A | |
| username | varchar(32) | Yes | true | | |
| pv | bigint(20) | Yes | false | 0 | SUM |
+----------+-------------+------+-------+---------+-------+
4 rows in set (0.00 sec)
MySQL> DESC table2;
+-----------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-------+---------+-------+
| event_day | date | Yes | true | N/A | |
| siteid | int(11) | Yes | true | 10 | |
| citycode | smallint(6) | Yes | true | N/A | |
| username | varchar(32) | Yes | true | | |
| pv | bigint(20) | Yes | false | 0 | SUM |
+-----------+-------------+------+-------+---------+-------+
5 rows in set (0.00 sec)注意事项:
上述表通过设置 replication_num 建的都是单副本的表,Doris建议用户采用默认的 3 副本设置,以保证高可用。
可以对复合分区表动态的增删分区。
数据导入可以导入指定的 Partition。
可以动态修改表的 Schema。
可以对 Table 增加上卷表(Rollup)以提高查询性能。
表的列的Null属性默认为true,会对查询性能有一定的影响。
1.3 导入数据
1.3.1 Broker 导入
示例:以 "table1_20170708" 为 Label,将 HDFS 上的文件导入 table1 表
LOAD LABEL table1_20170708
(
DATA INFILE("hdfs://your.namenode.host:port/dir/table1_data")
INTO TABLE table1
)
WITH BROKER hdfs
(
"username"="hdfs_user",
"password"="hdfs_password"
)
PROPERTIES
(
"timeout"="3600",
"max_filter_ratio"="0.1"
);1.3.2 Routine 导入
创建Kakfa例行导入作业
CREATE ROUTINE LOAD db1.job1 on tbl1
PROPERTIES
(
"desired_concurrent_number"="1"
)
FROM KAFKA
(
"kafka_broker_list"= "broker1:9091,broker2:9091",
"kafka_topic" = "my_topic",
"property.security.protocol" = "ssl",
"property.ssl.ca.location" = "FILE:ca.pem",
"property.ssl.certificate.location" = "FILE:client.pem",
"property.ssl.key.location" = "FILE:client.key",
"property.ssl.key.password" = "abcdefg"
);1.3.3 其他导入方式
SparkLoad, S3 load, streamLoad、删除操作
二. Doris介绍
2.1 Doris简介
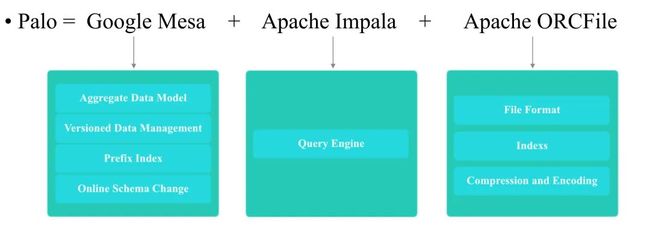
Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在2017年开源,2018年8月进入 Apache 孵化器。(区别于DorisDB,Apache Doris 属于开源版本,属于DorisDB的标准版,目前一些公众号宣传的DorisDB属于商业版本,性能比Apache Doris好)
主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩) 的技术。
2.2 核心特性

2.3 使用场景
三. 数据模型
在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。
Doris 的数据模型主要分为3类:
Aggregate
Uniq
Duplicate
3.1 Aggregate 模型
我们以实际的例子来说明什么是聚合模型,以及如何正确的使用聚合模型。
示例1:导入数据聚合
假设业务有如下数据表模式:
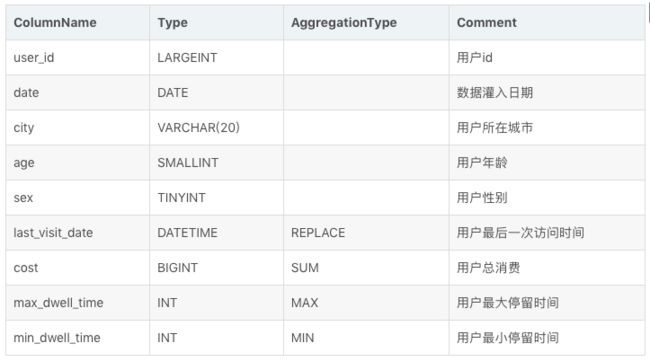
如果转换成建表语句则如下(省略建表语句中的 Partition 和 Distribution 信息)
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
... /* 省略 Partition 和 Distribution 信息 */
;可以看到,这是一个典型的用户信息和访问行为的事实表。在一般星型模型中,用户信息和访问行为一般分别存放在维度表和事实表中。这里我们为了更加方便的解释 Doris 的数据模型,将两部分信息统一存放在一张表中。
表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age ... 等称为 Key,而设置了 AggregationType的称为 Value。
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType进行聚合。AggregationType 目前有以下四种聚合方式:
SUM:求和,多行的 Value 进行累加。
REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
MAX:保留最大值。
MIN:保留最小值。
假设我们有以下导入数据(原始数据):
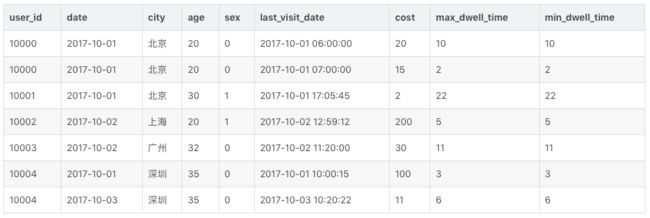
我们假设这是一张记录用户访问某商品页面行为的表。那么当这批数据正确导入到 Doris 中后,Doris 中最终存储如下:
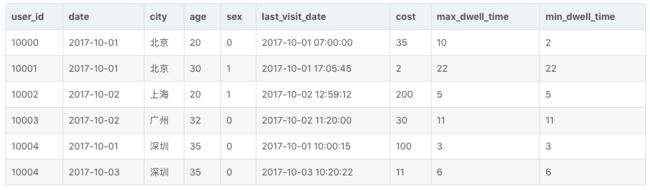
可以看到,用户 10000 只剩下了一行聚合后的数据。而其余用户的数据和原始数据保持一致。
经过聚合,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
示例2:保留明细数据
接示例1,我们将表结构修改如下:
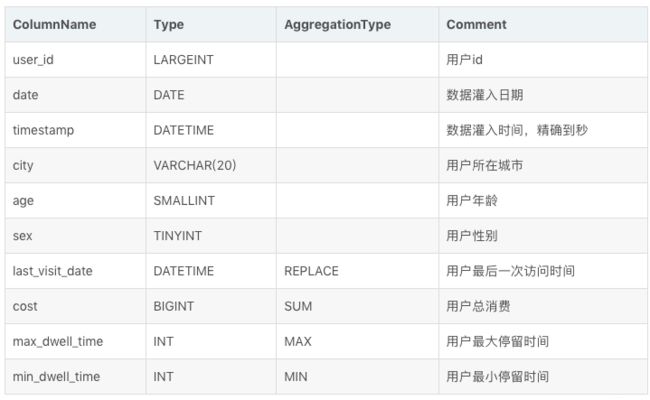
即增加了一列 timestamp,记录精确到秒的数据灌入时间。
导入数据如下:
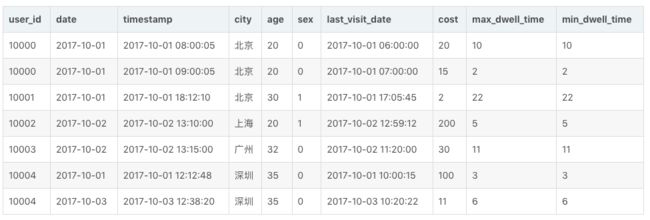
那么当这批数据正确导入到 Doris 中后,Doris 中最终存储如下:
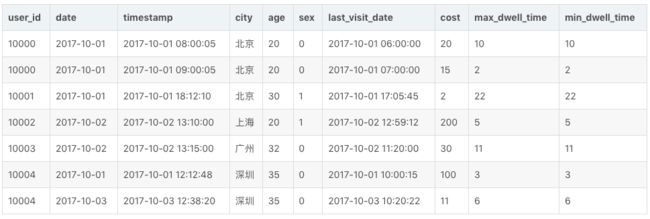
我们可以看到,存储的数据,和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了 timestamp 列,所有行的 Key 都不完全相同。也就是说,只要保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。

示例3:导入数据与已有数据聚合
接示例1。假设现在表中已有数据如下:
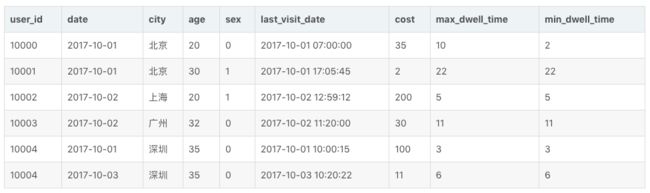
我们再导入一批新的数据:
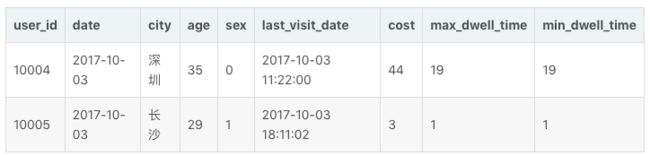
那么当这批数据正确导入到 Doris 中后,Doris 中最终存储如下:
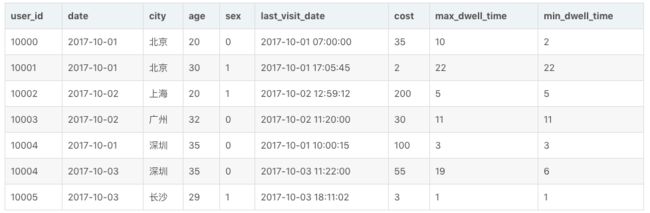
可以看到,用户 10004 的已有数据和新导入的数据发生了聚合。同时新增了 10005 用户的数据。
数据的聚合,在 Doris 中有如下三个阶段发生:
每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。
3.2 Uniq 模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。我们举例说明。
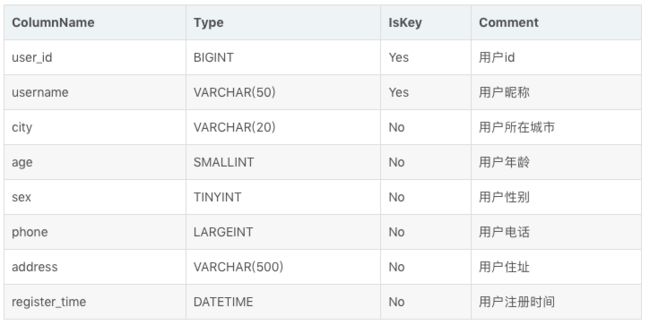
这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username)。那么我们的建表语句如下:
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `user_name`)
... /* 省略 Partition 和 Distribution 信息 */
;即 Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。这里不再继续举例说明。
而这个表结构,完全同等于以下使用聚合模型描述的表结构:
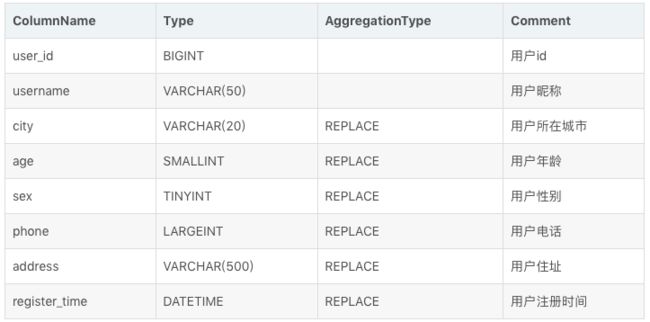
及建表语句:
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) REPLACE COMMENT "用户所在城市",
`age` SMALLINT REPLACE COMMENT "用户年龄",
`sex` TINYINT REPLACE COMMENT "用户性别",
`phone` LARGEINT REPLACE COMMENT "用户电话",
`address` VARCHAR(500) REPLACE COMMENT "用户地址",
`register_time` DATETIME REPLACE COMMENT "用户注册时间"
)
AGGREGATE KEY(`user_id`, `user_name`)
... /* 省略 Partition 和 Distribution 信息 */
;即 Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。这里不再继续举例说明。
3.3 Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求。举例说明。
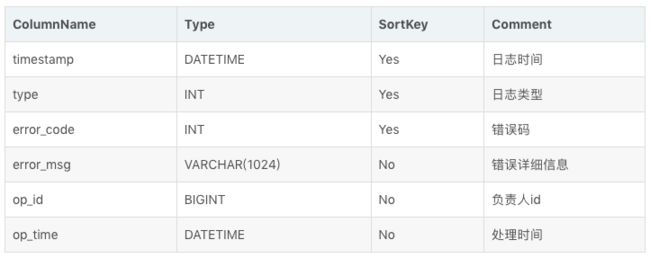
建表语句如下:
sqlCREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`)
... /* 省略 Partition 和 Distribution 信息 */
;这种数据模型区别于 Aggregate 和 Uniq 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。(更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型。在 DUPLICATE KEY 的选择上,我们建议适当的选择前 2-4 列就可以。
这种数据模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据的存储。
3.4 ROLLUP
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
Base:基表。
Rollup:一般指基于 Base 表创建的 Rollup 表,但在一些场景包括 Base 以及 Rollup 表。
3.4.1 基本概念
在 Doris 中,我们将用户通过建表语句创建出来的表成为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
下面我们用示例详细说明在不同数据模型中的 ROLLUP 表及其作用。
3.4.2 Aggregate 和 Uniq 模型中的 ROLLUP
因为 Uniq 只是 Aggregate 模型的一个特例,所以这里我们不加以区别。
示例1:获得每个用户的总消费
Base 基础表结构如下:
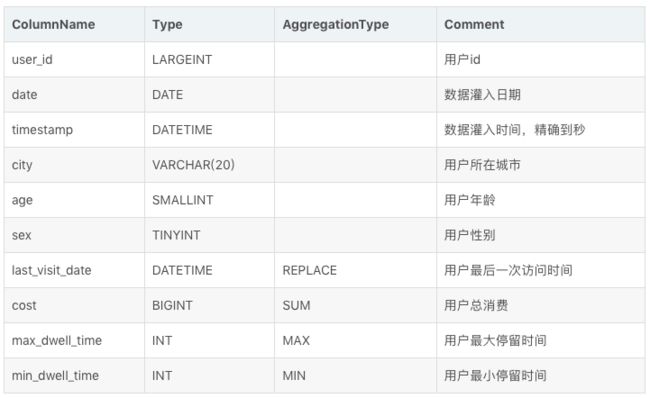
存储的数据如下:
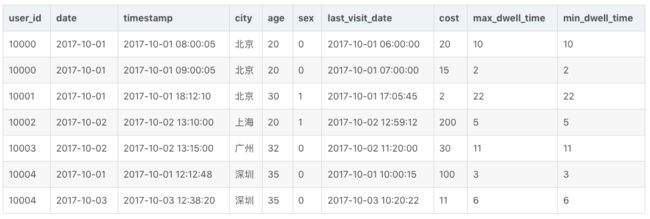
在此基础上,我们创建一个 ROLLUP:

该 ROLLUP 只包含两列:user_id 和 cost。则创建完成后,该 ROLLUP 中存储的数据如下:
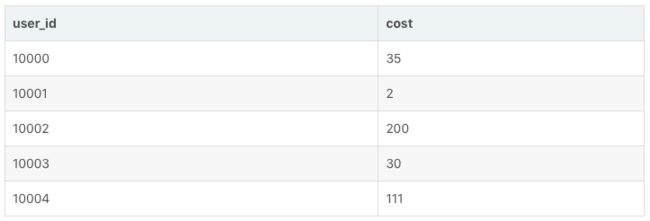
可以看到,ROLLUP 中仅保留了每个 user_id,在 cost 列上的 SUM 的结果。那么当我们进行如下查询时:
SELECT user_id, sum(cost) FROM table GROUP BY user_id;Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
示例2:获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间
紧接示例1。我们在 Base 表基础之上,再创建一个 ROLLUP:
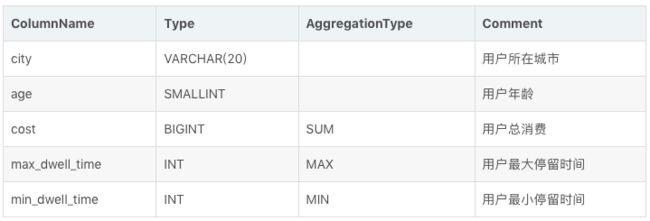
则创建完成后,该 ROLLUP 中存储的数据如下:
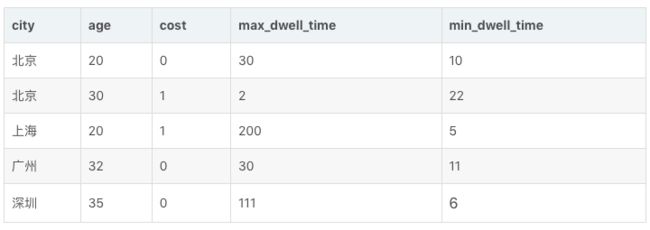
- `SELECT city, age, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city, age;`
- `SELECT city, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city;`
- `SELECT city, age, sum(cost), min(min_dwell_time) FROM table GROUP BY city, age;Doris 会自动命中这个 ROLLUP 表。
3.4.3 Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷”这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。
3.5 前缀索引与 ROLLUP
在 Doris 里 Rollup 作为一份聚合物化视图,其在查询中可以起到两个作用:
索引
聚合数据(仅用于聚合模型,即aggregate key)
但是为了命中 Rollup 需要满足一定的条件,并且可以通过执行计划中 ScanNdoe 节点的 PreAggregation 的值来判断是否可以命中 Rollup,以及 Rollup 字段来判断命中的是哪一张 Rollup 表。
Doris 会把 Base/Rollup 表中的前 36 个字节(有 varchar 类型则可能导致前缀索引不满 36 个字节,varchar 会截断前缀索引,并且最多使用 varchar 的 20 个字节)在底层存储引擎单独生成一份排序的稀疏索引数据(数据也是排序的,用索引定位,然后在数据中做二分查找),然后在查询的时候会根据查询中的条件来匹配每个 Base/Rollup 的前缀索引,并且选择出匹配前缀索引最长的一个 Base/Rollup。
-----> 从左到右匹配
+----+----+----+----+----+----+
| c1 | c2 | c3 | c4 | c5 |... |如上图,取查询中 where 以及 on 上下推到 ScanNode 的条件,从前缀索引的第一列开始匹配,检查条件中是否有这些列,有则累计匹配的长度,直到匹配不上或者36字节结束(varchar类型的列只能匹配20个字节,并且会匹配不足36个字节截断前缀索引),然后选择出匹配长度最长的一个 Base/Rollup,下面举例说明,创建了一张Base表以及四张rollup:
+---------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+---------------+-------+--------------+------+-------+---------+-------+
| test | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index1 | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index2 | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index3 | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index4 | k4 | BIGINT | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
+---------------+-------+--------------+------+-------+---------+-------+三张表的前缀索引分别为
Base(k1 ,k2, k3, k4, k5, k6, k7)
rollup_index1(k9,k1 ,k2, k3, k4, k5, k6, k7,...)
rollup_index2(k9,k2 ,k1, k3, k4, k5, k6, k7)
rollup_index3(k4, k5, k6, k1, k2, k3, k7)
rollup_index4(k4, k6, k5, k1, k2, k3, k7)-- 命中test
SELECT * FROM test WHERE k1 = 1 AND k2 > 3;
-- rollup_index3
SELECT * FROM test WHERE k4 = 1 AND k5 > 3;
-- rollup_index1
SELECT * FROM test WHERE k9 IN ("xxx", "yyyy") AND k1 = 10;
-- rollup_index3
SELECT * FROM test WHERE k4 < 1000 AND k5 = 80 AND k6 >= 10000;-- 不能命中前缀索引
SELECT * FROM test WHERE k4 < 1000 AND k5 = 80 OR k6 >= 10000;如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」