一文速学-时间序列分析算法之移动平均模型(MA)详解+Python实例代码
目录
前言
一、移动平均模型(MA)
模型原理
自回归
移动平均模型
自相关系数
常用的 MA 模型的自相关系数
通用:
MA(1)模型:
MA(2)模型:
自协方差函数
二、Python案例实现
平稳时间序列建模步骤
平稳性检验
输出内容解析:
补充说明:
MA预测模型
消除趋势和季节性变化
差分Differencing
分解Decomposition
ACF自协方差和PACF偏自相关函数
模型建立
编辑 MA与AR模型的对比
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
参阅:
前言
有一段时间没有继续更新时间序列分析算法了,传统的时间序列预测算法已经快接近尾声了。按照我们系列文章的讲述顺序来看,还有四个算法没有提及:

平稳时间序列预测算法都是大头,比较难以讲明白。但是这个系列文章如果从头读到尾,细细品味研究的话,会发现时间序列预测算法从始至终都在做一件事,也就是如何更好的利用到历史数据,挖掘历史数据中蕴含的周期性规律或者是趋势。在看完这个系列的上述文章要理解平稳时间序列预测算法并不是一件难事,真正难的是原理和推导,以及实际起来运用方式,这是十分重要的。关键还是在于如何理解此类算法,好了就让我们开始一步一步完成此算法的推导以及代码编写到实际案例的运用。
博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、移动平均模型(MA)
移动平均模型MA是和自回归模型AR多少是有点联系的,它并非是历史时序值的线性组合而是历史白噪声的线性组合。与AR最大的不同之处在于,AR模型中历史白噪声的影响是间接影响当前预测值的(通过影响历史时序值)。AR模型是把随机部分简化,保留历史序列部分,那么对偶地,MA模型是将历史序列值简化,保留随机部分。
我们通过原理和公式与AR模型进行对比,就能更好的理解MA模型。
模型原理
根据我们上篇文章的基础内容和AR模型的讲解:时间序列分析算法之平稳时间序列预测算法和自回归模型(AR)详解+Python代码实现
自回归
自回归只适用于预测与自身前期相关的现象,数学模型表达式如下:

其中![]() 是当前值,
是当前值,![]() 是常数项,
是常数项,![]() 是阶数,
是阶数,![]() 是自相关系数,
是自相关系数,![]() 是误差,同时
是误差,同时![]()
要符合正态分布。该模型反映了在t时刻的目标值值与前t-1~p个目标值之前存在着一个线性关系,即:

移动平均模型
移动平均模型(MA)关注的是自回归模型中的误差项的累加,数学模型表达式如下:

该模型反映了在t时刻的目标值值与前t-1~p个误差值之前存在着一个线性关系,即:
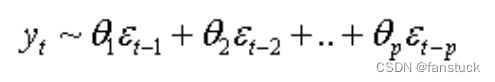
对两边求期望方差,可以得到:
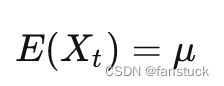
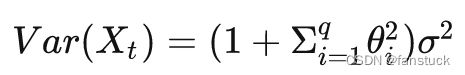
MA模型总是弱平稳的。特别的,当![]() =0,成为中心化MA(q)模型。
=0,成为中心化MA(q)模型。
自相关系数
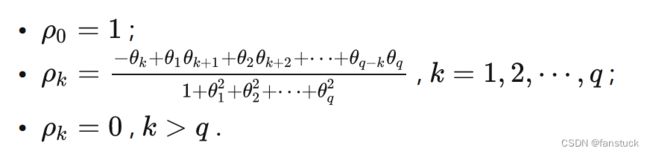
MA模型的自相关系数是q阶截尾的。
常用的 MA 模型的自相关系数
通用:

MA(1)模型:
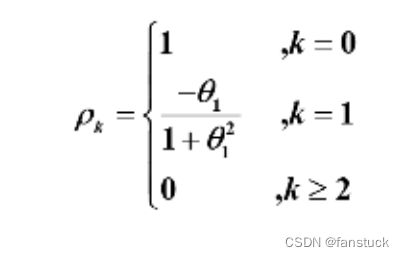
MA(2)模型:

自协方差函数

二、Python案例实现
平稳时间序列建模步骤
由AR模型、MA模型和ARMA模型的 自相关系数和偏自相关系数 的性质,选择出合适的模型。
AR、MA和ARMA模型自相关系数和偏自相关系数的性质如下:
| AR(p) | MA(q) | ARMA(p,q) | |
| 模型方程 | |||
| 平稳性条件 | 无 | ||
| 可逆性条件 | 无 | ||
| 自相关函数 | 拖尾 | Q步截尾 | 拖尾 |
| 偏相关函数 | P步截尾 | 拖尾 | 拖尾 |
平稳性检验
单位根检验(Unit Root Test)单位根检验是针对宏观经济数据序列、货币金融数据序列中是否具有某种统计特性而提出的一种平稳性检验的特殊方法,单位根检验的方法有很多种,包括ADF检验、PP检验、NP检验等。
#导入包
from statsmodels.tsa.stattools import adfuller
def test_stationarity(timeseries):
#Determing rolling statistics
rolmean=timeseries.rolling(7).mean()
rolstd=timeseries.rolling(7).std()
#Plot rolling statistics:
orig=plt.plot(timeseries,color='blue',label='Original')
mean=plt.plot(rolmean,color='red',label='Rolling Mean') #均值
std=plt.plot(rolstd,color='black',label='Rolling Std') #标准差
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
#Perform Dickey-Fuller Test:
print('Results of Dickey-Fuller Test:')
dftest=adfuller(timeseries,autolag='AIC')
dfoutput=pd.Series(dftest[0:4],index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key]=value
print(dfoutput)
#检验结果
test_stationarity(df_test['客流量'])

Results of Dickey-Fuller Test: Test Statistic -4.608773 p-value 0.000124 #Lags Used 15.000000 Number of Observations Used 483.000000 Critical Value (1%) -3.443962 Critical Value (5%) -2.867543 Critical Value (10%) -2.569967 dtype: float64
输出内容解析:
- ADF:float,测试统计。
- pvalue:float,probability value:MacKinnon基于MacKinnon的近似p值(1994年,2010年)。
- usedlag:int,使用的滞后数量。
- NOBS:int,用于ADF回归和计算临界值的观察数。
- critical values:dict,测试统计数据的临界值为1%,5%和10%。基于MacKinnon(2010)。
- icbest:float,如果autolag不是None,则最大化信息标准。
- resstore:ResultStore, optional,一个虚拟类,其结果作为属性附加
Returns
-------
adf : float
The test statistic.
pvalue : float
MacKinnon"s approximate p-value based on MacKinnon (1994, 2010).
usedlag : int
The number of lags used.
nobs : int
The number of observations used for the ADF regression and calculation
of the critical values.
critical values : dict
Critical values for the test statistic at the 1 %, 5 %, and 10 %
levels. Based on MacKinnon (2010).
icbest : float
The maximized information criterion if autolag is not None.
resstore : ResultStore, optional
A dummy class with results attached as attributes.
补充说明:
-
该模型要求序列必须是平稳的时间序列数据。通过分析t值,分析其是否可以显著地拒绝序列不平稳的原假设
-
若呈现显著性(p<0.05或0.01),则说明拒绝原假设,该序列为一个平稳的时间序列,反之则说明该序列为一个不平稳的时间序列
-
临界值(1%、5%、10%不同程度拒绝原假设的统计值)和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设
-
Lag值:最优的滞后阶数
-
差分阶数:本质上就是下一个数值 ,减去上一个数值,主要是消除一些波动使数据趋于平稳,非平稳序列可通过差分变换转化为平稳序列
-
AIC值:衡量统计模型拟合优良性的一种标准,数值越小越好
-
临界值:临界值是对应于一个给定的显着性水平的固定值
该序列检验的结果显示,基于字段客流量:
在差分为0阶时,显著性P值为0.000**,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
MA预测模型
数据经过调整后,一般有两种情况:
1)严格平稳序列,各值之间不存在相关性,这是我们可以对残差的白噪声进行建模的一个简单的例子。但非常罕见。
2)值之间有显著相关性的序列。需要使用一些统计模型。
移动平均模型关注的是自回归模型中的误差项的累加。它能够有效地消除预测中的随机波动。
消除趋势和季节性变化
差分Differencing
取某一时刻的观测值与前一时刻的观测值之差。
分解Decomposition
对趋势和季节性进行建模,并将其从模型中移除
取某一时刻的观测值与前一时刻的观测值之差:
df_diff=df_test['客流量']-df_test['客流量'].shift()
df_diff.dropna(inplace=True)
test_stationarity(df_diff)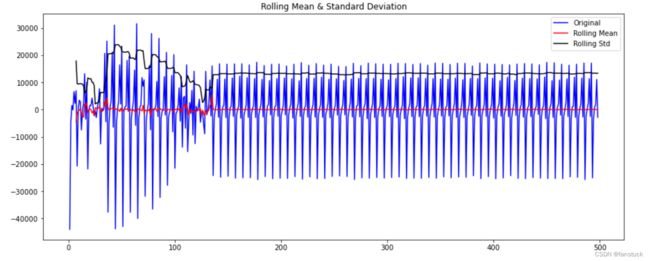
ACF自协方差和PACF偏自相关函数
- ACF:时间序列Xt的自协方差是信号与其经过时间平移的信号之间的协方差。例如将t1,t2与t1-5和t2-5 相比。将有序的随机变量序列与其自身相比较,它反映了同一序列在不同时序的取值之间的相关性。
- PACF:偏自相关函数(PACF)计算的是严格的两个变量之间的相关性,是剔除了中间变量的干扰之后所得到的两个变量之间的相关程度。对于一个平稳的AR§模型,求出滞后为k的自相关系数p(k)时,实际所得并不是x(t)与x(t-k)之间的相关关系。这是因为在这两个变量之间还存在k-1个变量,它们会对这个自相关系数产生一系列的影响,而这个k-1个变量本身又是与x(t-k)相关的。这对自相关系数p(k)的计算是一个不小的干扰。而偏自相关函数可以剔除这些干扰。
#ACF and PACF plots:
from statsmodels.tsa.stattools import acf,pacf
lag_acf=acf(df_diff,nlags=20)
lag_pacf=pacf(df_diff,nlags=20,method='ols')
#Plot ACF:
plt.subplot(121)
plt.plot(lag_acf)
plt.axhline(y=0,linestyle='--',color='gray')
plt.axhline(y=-1.96/np.sqrt(len(df_diff)),linestyle='--',color='gray')
plt.axhline(y=1.96/np.sqrt(len(df_diff)),linestyle='--',color='gray')
plt.title('Autocorrelation Function')
#Plot PACF:
plt.subplot(122)
plt.plot(lag_pacf)
plt.axhline(y=0,linestyle='--',color='gray')
plt.axhline(y=-1.96/np.sqrt(len(df_diff)),linestyle='--',color='gray')
plt.axhline(y=1.96/np.sqrt(len(df_diff)),linestyle='--',color='gray')
plt.title('Partial Autocorrelation Function')
plt.tight_layout()
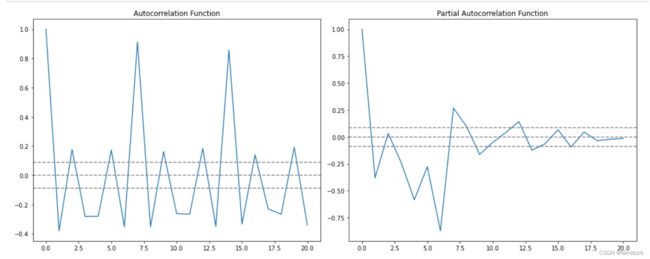
在这个图上,两条在0附近的虚线是置信区间,可以用来决定’p’和‘q’
模型建立
df_diff=df_test['客流量']-df_test['客流量'].shift()
import statsmodels.api as sm
model = sm.tsa.arima.ARIMA(df_test['客流量'],order=(0,1,2))
results_MA=model.fit()
plt.plot(df_diff)
plt.plot(results_MA.fittedvalues,color='red')
plt.title('RSS: %.4f'% ((results_MA.fittedvalues-df_diff)**2).sum())
print((results_MA.fittedvalues-df_diff).sum())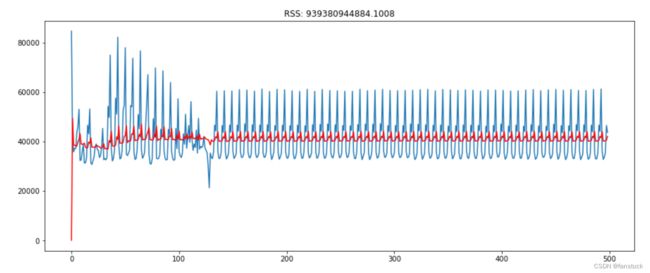 MA与AR模型的对比
MA与AR模型的对比

点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
参阅:
使用Python建立时间序列(ARIMA、MA、AR)预测模型_Avasla的博客-CSDN博客_ma模型 python
ARMA模型的性质之MA模型_洋洋菜鸟的博客-CSDN博客_ma模型