2018年第九届蓝桥杯【C++省赛B组】【第八题:日志统计】
2018年第九届蓝桥杯【第八题:日志统计】
-
- 1. 问题
-
- 1.1 题目:日志统计
- 1.2 输入输出格式
- 1.3 测试样例
- 2.分析
-
- 2.1 数据存储
- 2.2 热帖计算
- 3.代码实现
- 4.总结
1. 问题
1.1 题目:日志统计
小明维护着一个程序员论坛。现在他收集了一份"点赞"日志,日志共有N行。其中每一行的格式是:
ts id
表示在ts时刻编号id的帖子收到一个"赞"。
现在小明想统计有哪些帖子曾经是"热帖"。如果一个帖子曾在任意一个长度为D的时间段内收到不少于K个赞,小明就认为这个帖子曾是"热帖"。
具体来说,如果存在某个时刻T满足该帖在 [ T , T + D ) [T, T+D) [T,T+D)这段时间内(注意是左闭右开区间)收到不少于K个赞,该帖就曾是"热帖"。
给定日志,请你帮助小明统计出所有曾是"热帖"的帖子编号。
1.2 输入输出格式
【输入格式】
第一行包含三个整数N、D和K。
以下N行每行一条日志,包含两个整数ts和id。
对于50%的数据,1 ≤ K ≤ N ≤ 1000
对于100%的数据,1 ≤ K ≤ N ≤ 100000, 0 ≤ ts ≤ 100000, 0 ≤ id ≤ 100000
【输出格式】
按从小到大的顺序输出热帖id。每个id一行。
1.3 测试样例
【输入样例】(行号除外)
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
【输出样例】(行号除外)
1
3
资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
2.分析
通过题意对输入输出数据分析,发现这样一个现象,那就是数据没有按照ts进行排序,也没有按照id排序,而结果明确要求输出id按照排序输出。如果数据是已经按照ts排序的数据,计算热帖也更方便。因此代码编写前,需要设计一个合适的数据存储结构,将能大大方便算法实现。(如果使用C++,可以直接使用STL模板库中的数据结构,编写代码会简单很多,但是需要对STL有一定的理解和掌握,利弊看大家自己选择了)。
2.1 数据存储
考虑到 N ≤ 10000 , 那么所有数据存储下来,至少需要给系统预留 100000 × 2 =200000字节,即大约196KB内存,相比限制条件中的256MB基本上不存在什么问题,因此数据的存储不必考虑效率问题,例如直接使用数组存储,只要按照程序计算的需要设计就可以了。
程序数据通过终端输入,所以可以考虑在数据存储时就对数据进行排序,可以考虑使用木桶排序,也就是将每条日志输入的时候,直接保存在按照日志id为下表的数组中,当数据存好后,所有的数据就是已经按照id排序的了。
如果按照以上的存储方案,还有一个需要解决的问题,就是相同id的多条日志怎么存储在同一个数组单元中呢?可以考虑使用链表的方式动态存储。并且,存储的时候就可以按照ts进行顺序存储。
以上的存储用UML图表示如下:
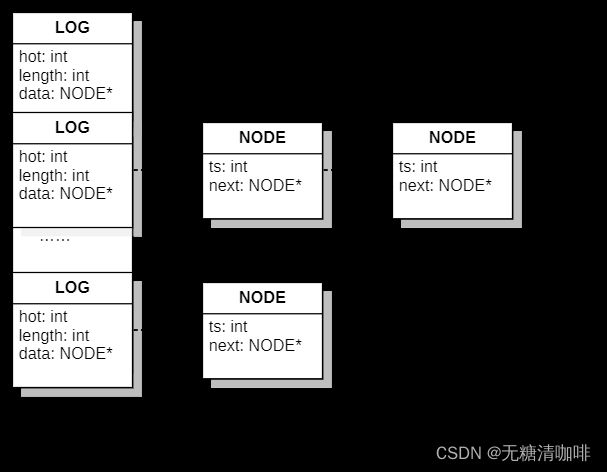
说明:
- 左侧的是LOG结构体数组,结构体中包含了hot成员变量,用于表示此id对应的贴子是否是热帖;length表示此id的日志数量; NODE*是一个指针变量,指向NODE结构体。
- NODE结构体是存放每一条具体日志记录的时间,因此,它只有一个数据成员ts字段,而next指针字段则是为了构建单链表需要的。
2.2 热帖计算
有了前面设计的数据结构,按照题意进行热帖计算就很简单了。算法简述如下:
- 从LOG就结构体数组中遍历每一个LOG结构体
- 判断结构体length,如果大于0,那么使用尺取法,检测该贴子是否是热帖。
- 如果是热帖,那么令LOG结构体中hot=1。
- 全部遍历完LOG数组后,从头开始输出,即对每个LOG结构体中hot==1的数组下标进行输出。
3.代码实现
完整代码如下:
#include 4.总结
按照以上思路求解题目过程主要需要熟练掌握结构体数组,单链表,基本排序算法,指针操作等程序设计能力,对算法的要求并不是很高。
如果使用C++ STL库,以上的代码还会更精简,可以参考本文 2018年第九届蓝桥杯【C++省赛B组】【第八题:日志统计】——附解题代码
本文中的算法相对简单,但是数据结构的设计相比其他的解决方案更复杂,对链表,内存管理等C语言基本要求比较高,在实际的比赛中,可能不必设计这么复杂,比如全部都存储在一个结构体数组中处理,避免链表操作,在代码编写上可能更简洁。