文章目录
- 1.烟台市1月与6月日最高气温散点图(散点图)
- 2.内地票房前五名 上映次日票房比较(单次条形图)
- 3.内地票房前五名 上映前三日票房比较(多次条形图)
- 4. 250部经典影片时长统计
- 5.数组与数据类型
- 6.数组的大小 与 范围改变
- 7.数组的运算 与 广播机制
1.烟台市1月与6月日最高气温散点图(散点图)
from matplotlib import pyplot as plt
import matplotlib as mtb
#实现中文输出
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#设置大小 和 分辨率
plt.figure(figsize = (15,5) , dpi = 80)
#设置范围
y_1 = [7,0,3,2,2,5,7,7,4,0,-1,0,0,3,5,0,2,5,-2,-1,3,1,1,4,4,3,2,1,3,4,0]
y_6 = [28,27,28,31,27,30,31,25,34,33,35,27,29,31,31,31,28,32,26,29,28,26,28,33,28,29,31,29,28,29]
x_1 = range(1,32)
x_6 = range(51,81)
#设置折线
plt.scatter(x_1 , y_1 , label = "自己" , color = "#4B0082" )
plt.scatter(x_6 , y_6 , label = "同桌" , color = "#006400" )
# #设置横纵坐标刻度
# #两种用法 直接放范围 或者 把范围对应到字符串
xticks_lables = ["1月{}日".format(i) for i in x_1]
xticks_lables += ["6月{}日".format(i - 50) for i in x_6]
x = list(x_1) + list(x_6)
plt.xticks(x[::2] , xticks_lables[::2] , rotation = 45)
plt.yticks(range(-2,35,2))
#设置标签
plt.xlabel("日期")
plt.ylabel("温度(℃)")
plt.title("烟台市1月与6月日最高气温散点图")
#设置网格 alpha 是清晰度
# plt.grid(alpha = 0.3 , color = "#006400")
#设置图例
#两步 , 先在折线中设置标签 , 再用legend函数显示
plt.legend(loc = 2)
#显示图像
plt.show()

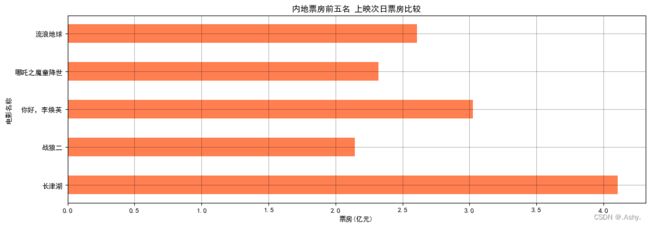
2.内地票房前五名 上映次日票房比较(单次条形图)
from matplotlib import pyplot as plt
import matplotlib as mtb
#实现中文输出
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#设置大小 和 分辨率
plt.figure(figsize = (15,5) , dpi = 80)
#设置范围
x = ['长津湖','战狼二','你好,李焕英','哪吒之魔童降世','流浪地球']
y = [4.108 , 2.147 , 3.024 , 2.321 , 2.608]
#设置折线
plt.barh(x , y , height = 0.5, color = "#FF7F50" )
# plt.bar(x , y , width = 0.5, color = "#4B0082" )
#barh 横 bar 纵
#设置标签
plt.xlabel("票房(亿元)")
plt.ylabel("电影名称")
plt.title("内地票房前五名 上映次日票房比较")
#设置网格 alpha 是清晰度
plt.grid(alpha = 0.3 , color = "#000000")
#显示图像
plt.show()
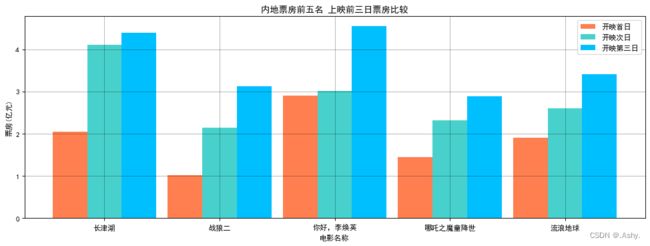
3.内地票房前五名 上映前三日票房比较(多次条形图)
from matplotlib import pyplot as plt
import matplotlib as mtb
#实现中文输出
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#设置大小 和 分辨率
plt.figure(figsize = (15,5) , dpi = 80)
#设置范围
x = ['长津湖','战狼二','你好,李焕英','哪吒之魔童降世','流浪地球']
y_1 = [2.05 , 1.02 , 2.91 , 1.44 , 1.91]
y_2 = [4.11 , 2.15 , 3.02 , 2.32 , 2.61]
y_3 = [4.39 , 3.13 , 4.56 , 2.89 , 3.42]
x_1 = list(range(len(x)))
x_2 = [i + 0.3 for i in x_1]
x_3 = [i + 0.6 for i in x_1]
#设置折线
plt.bar(x_1 , y_1 , width = 0.3, color = "#FF7F50" , label = "开映首日" )
plt.bar(x_2 , y_2 , width = 0.3, color = "#48D1CC" , label = "开映次日" )
plt.bar(x_3 , y_3 , width = 0.3, color = "#00BFFF" , label = "开映第三日" )
# plt.bar(x , y , width = 0.5, color = "#4B0082" )
#barh 横 bar 纵
plt.xticks(x_2 , x)
#设置标签
plt.xlabel("电影名称")
plt.ylabel("票房(亿元)")
plt.title("内地票房前五名 上映前三日票房比较")
#设置网格 alpha 是清晰度
plt.grid(alpha = 0.3 , color = "#000000")
plt.legend()
#显示图像
plt.show()
4. 250部经典影片时长统计
from matplotlib import pyplot as plt
import matplotlib as mtb
#实现中文输出
mtb.rcParams['font.sans-serif'] = ["SimHei"]
mtb.rcParams["axes.unicode_minus"] = False
#设置大小 和 分辨率
plt.figure(figsize = (15,5) , dpi = 80)
#设置范围
date = [139, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]
# [78 , 156] 取值范围
# 设置组距
d = 5
#如何设置 hist 函数 和 坐标函数是 这个直方图的重点
# 用 极差 和 组距 求最大整除组数
num = (max(date) - min(date))
# 这里不一定能整除 , 比如质数 , 所以 bins 参数传一个列表进去
#列表范围[78 , 158] d = 5 一定注意是 num + 2
plt.hist(date , [min(date) + i * d for i in range(num + 2)], color = "#FF7F50")
# 设置横坐标
plt.xticks(range(min(date) , max(date) + 2 * d , d))
plt.yticks(range(1,40,2))
#设置标签
plt.xlabel("时长(min)")
plt.ylabel("数量")
plt.title("250部经典影片时长统计")
# 设置网格 alpha 是清晰度
plt.grid(alpha = 0.3 , color = "#000000")
#显示图像
plt.show()
#思考:如何变成频率分布直方图呢?
#1. plt.hist(date , [min(date) + i * d for i in range(num + 2)], color = "#FF7F50") 中加上 density = True
#2. 去掉 plt.yticks(range(1,40,2)) 因为纵坐标要进行概率操作 ,再进行纵坐标设置就把之前的操作覆盖了

5.数组与数据类型
import numpy as np
import random as rd
# numpy 数组的创建 三种方法
ls = [rd.random() for i in range(1,10)]
a = np.array(range(1,10))
b = np.array(ls)
c = np.arange(1,10)
print(a)
print(b)
print(c)
#用 dtype 规定数据类型
a = np.array(range(0,10) , dtype = "int8")
print(a)
print(a.dtype)
#用 astype 转换数据类型
#这个函数有返回值 ,不改变本身数据类型
a1 = a.astype("bool")
print(a1)
print(a1.dtype)
# 保留 n 位小小数
c = b.round(2)
print(c)
# nan not a number 0/0
# inf 无穷大 x/0 (x!=0)
6.数组的大小 与 范围改变
import numpy as np
t = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]])
print(t)
#reshpe 重新定义大小
t1 = t.reshape((16,))
print(t1)
#不知道范围 , 转化为一维数组
t2 = t1.flatten()
print(t2)
7.数组的运算 与 广播机制
# 1. 数组与数之间运算 , 数组中的每一个元素都与数进行运算
# 2. 数组与数组之间运算 , 如果两个数组大小相同 , 直接运算 , 大小不同 , 满足广播机制
# 广播机制的大意就是 如果
#两个范围大小相同 ,比如说(1,3,4,1) , (4,3,1,2) 位数都是 4 就算相同 , 位数相同的两个范围 , 所有不同位只要满足有一个是 1 就满足广播机制 , 可以进行运算
#两个范围大小不同 ,需要小范围是大范围的前缀才可以进行运算 , 比如说 大范围(1,2,3,4) , 小范围需要是(1) (1,2) (1,2,3) 才能与大范围进行运算
import numpy as np
t = np.array(range(24)).reshape(2,3,4)
# print(t)
t1 = np.array(range(12)).reshape(3,4)
print(t + t1)