机器学习——K近邻算法(KNN)及其python实现
参考视频与文献:
https://www.bilibili.com/video/BV1HX4y137TN/?spm_id_from=333.788&vd_source=77c874a500ef21df351103560dada737
统计学习方法(第二版)李航(编著)
k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显式的学习过程。k近邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。k值的选择、距离度量及分类决策规则是k近邻法的三个基本要素。
k值的选择会对k近邻法的结果产生重大影响。
如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错。换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合。
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测。其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大就意味着整体的模型变得简单。
如果k=N,那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的。
在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。

此时K=3,待确定的样本寻找离它最近的三个样本
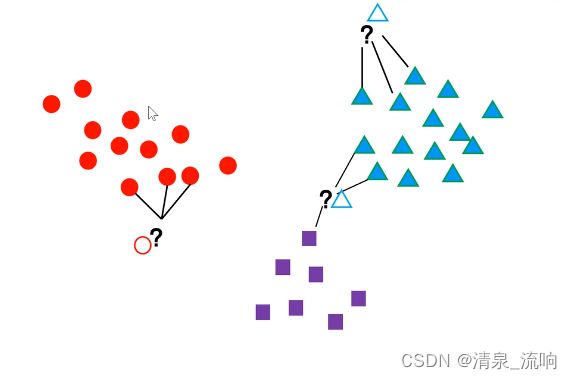


程序如下:
import numpy as np
import operator
'''
trainData - 训练集 N,D
testData - 测试 1,D
labels - 训练集标签
'''
# k一般取奇数
def knn(trainData, testData, labels, k):
# 计算训练样本的行数
rowSize = trainData.shape[0]
# 计算训练样本和测试样本的差值
diff = np.tile(testData, (rowSize, 1)) - trainData # 把测试样本复制N份,然后与训练样本相减
# 计算差值的平方和
sqrDiff = diff ** 2 # 计算欧氏距离
sqrDiffSum = sqrDiff.sum(axis=1) # 沿着D的维度求和
# 计算距离
distances = sqrDiffSum ** 0.5
# 对所得的距离从低到高进行排序
sortDistance = distances.argsort() # 返回的输入数据的位置
count = {}
for i in range(k):
vote = labels[sortDistance[i]]
# print(vote)
count[vote] = count.get(vote, 0) + 1
# 对类别出现的频数从高到低进行排序
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True)
# 返回出现频数最高的类别
return sortCount[0][0]
file_data = 'iris.data'
# 数据读取
data = np.loadtxt(file_data,dtype = float, delimiter = ',',usecols=(0,1,2,3)) # 取出输入数据前4列
lab = np.loadtxt(file_data,dtype = str, delimiter = ',',usecols=(4)) # 取出输入数据最后一列
# 分为训练集和测试集和
N = 150
N_train = 100
N_test = 50
perm = np.random.permutation(N)
index_train = perm[:N_train]
index_test = perm[N_train:]
data_train = data[index_train,:]
lab_train = lab[index_train]
data_test = data[index_test,:]
lab_test = lab[index_test]
# 参数设定
k= 5
n_right = 0
for i in range(N_test):
test = data_test[i,:]
det = knn(data_train, test, lab_train, k)
if det == lab_test[i]:
n_right = n_right+1
print('Sample %d lab_ture = %s lab_det = %s'%(i,lab_test[i],det))
# 结果分析
print('Accuracy = %.2f %%'%(n_right*100/N_test))
KNN算法的优势和劣势
了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。那我们就来看看KNN算法都有哪些优势以及其缺陷所在!
KNN算法优点
简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
预测效果好。
对异常值不敏感
KNN算法缺点
对内存要求较高,因为该算法存储了所有训练数据
预测阶段可能很慢
对不相关的功能和数据规模敏感
简单得说,当需要使用分类算法,且数据比较大的时候就可以尝试使用KNN算法进行分类了。