数据清洗和准备
讨论用于缺失值、重复值、字符串操作和其他分析数据转换的工具
1.缺失值
1.1. 处理缺失值
pandas对象的所有描述性统计信息默认情况下是排除缺失值的
对于数值型数据,pandas使用浮点数NaN(Not a Number来表示缺失值)
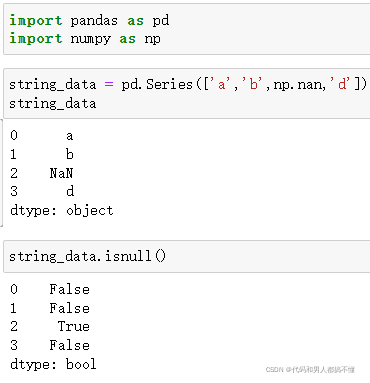
在统计学应用中,NA数据可以是不存在的数据或者是存在但不可观察的数据(例如在数据收集过程中出现了问题)
当清洗数据用于分析时,对缺失数据本身进行分析以确定数据收集问题或数据丢失导致的数据偏差通常很重要。
Python内建的None值在对象数组中也被当作NaN处理

1.2 过滤缺失值
可以使用pandas.isnull和布尔值索引手动地过滤缺失值
也可以用dropna过滤缺失值(在Series上使用dropna会返回Series中所有的非空数据及其索引值)

处理DataFrame对象时,dropna默认情况下会删除包含缺失值的行,所以要用how选项来选择。
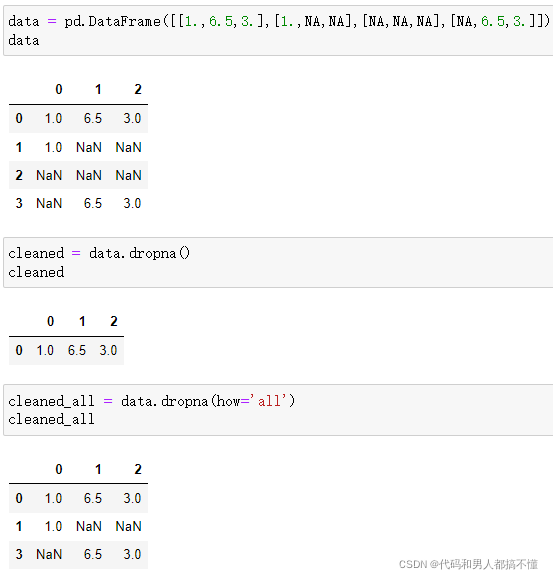
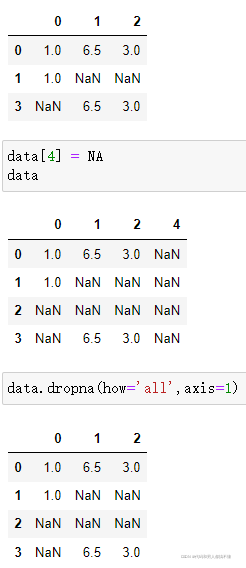
传入how='all'时,将删除所有值均为NAN的行
如果要用同样的方式删除列,传入参数axis=1
只想保留包含一定数量的观察值的行,可以用thresh参数来表示

这一行除去NA值,剩余数值的数量大于等于n,便显示这一行
1. 3. 补全缺失值
大多数情况下,用fillna()方法来补全缺失值。调用fillna()时,可以使用一个常数来替代缺失值。

调用fillna时使用字典,可以为不同列设定不同的填充值

fillna()返回的是一个新的对象,但也可以修改已经存在的对象。

使用fillna可以将Series的平均值或者中位数用于填充缺失值。

1.4 数据转换
1.4.1 删除重复值
由于各种原因,DataFrame会出现重复行,例如:

DataFrame的duplicated()方法:返回一个布尔值Series,反映的是每一行是否存在重复(与之前出现过的行相同)情况。

drop_duplicates()返回的是DataFrame,内容是duplicated返回数组中为False的部分。

这些方法默认都是对列进行操作,可以指定数据的任何子集来检测是否有重复。

我们有一个额外的列,并想基于'k1'列去除重复值
duplicated和drop_duplicates默认都是保留第一个观测到的值。传入参数keep='last'将会返回最后一个。

1.4.2 替代值
使用fillna填充缺失值是通用值替换的特殊案例。
map可用来修改一个对象中的子集的值,但是replace提供更为灵活简单的实现。
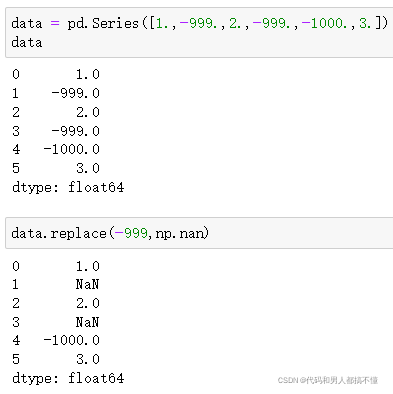
-999可能是缺失值的标识,可以用replace()方法生成新的Series(传入inplace=True则是在原Series做修改)

如果想要一次替代多个值,可传入一个列表和替代值。

参数也可以通过字典传递:

data.replace()方法与data.str.replace()方法不同
1.4.3 重命名轴索引
和Series中的值一样,可以通过函数或某种形式的映射对轴标签进行类似的转换,生成新的且带有不同标签的对象。也可以在不生成新的数据结构的情况下修改轴。

与Series类似,轴索引也有一个map方法:
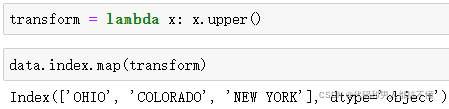
可以赋值给index,修改DataFrame:

要赋值给data.index才能修改原DataFrame哦!
简便方法————用rename()创建数据集转换后的版本,且不修改原有的数据集。
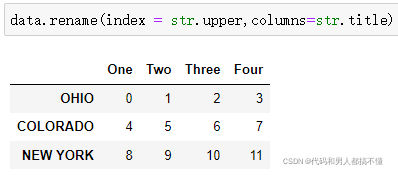

rename可以结合字典型对象使用,为轴标签的子集提供新的值:
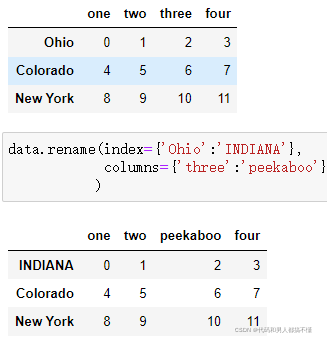
rename()可以不再手动复制DataFrame并为其分配索引和列属性。
传入inplace=True,修改原有的数据集。
1.4.4 离散化和分箱
连续值经常需要离散化,或者分离成“箱子”进行分析。
假设有某项研究中一组人气的数据,想将他们进行分组,放入离散的年龄框中:

将这些年龄放入18~25,26~35,36~60以及61及以上等若干组。
可以用pandas中的cut实现
pandas 返回的对象是一个特殊的Categorical对象,看到的输出描述了由pandas.cut计算出的箱。
可将它当作一个表示箱名的字符串数组,它在内部包含一个categories(类别)数组,指定了不同的类别名称以及codes属性中的ages数据标签

这里相当于是有4个类别数组,分别用0,1,2,3表示,然后给对应的ages属性贴上这个类别标签就表示属于哪个类别。

pd.value_counts(cats):对pandas.cut的结果中的箱数量的计数。

传递right=False来改变右边是开区间还是闭区间
可以通过向labels选项传递一个列表或数组来传入自定义的箱名

如果传给cut整数个的箱来代替显示的箱,pandas将根据数剧中的最小值和最大值计算出等长的箱

precision = 2的选项将十进制精度限制在两位

注意:它是根据最大值-最小值的区间将区间平均分成等值的箱,不是均匀的将样本点落在指定的箱子数里,也就是说不是每个箱子里都有同等的样本数。
qcut()是基于样本分位数进行分箱,所以可以通过它获得等长的箱。
使用cut()通常不会使每个箱具有相同数据量的数据点。

可以看到,cut()是根据样本区间等分箱,qcut()是根据样本分位数进行等分箱

qcut()可传入自定义的分位数(0和1之间的数据,包括边)
上面的例子就是,总共是20个数据,qcut里参数传入一个含有5个0-1的值的数组,5个值分成4个区间,0-0.1就是说在这个区间里的数据占整个数据的10%,所以总共20个数据希望在这个区间(第一个区间)里的数据占两个,同理可得0.5这个分位数希望0-0.5的数占50%,也就是前面两个区间有的数据量占总的50%。
1.4.5 检测和过滤异常值

生成一个100行4列的符合正太分布的DataFrame
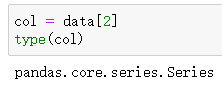
找出该DataFrame中col[2](下标为2)的数值的绝对值大于2的行下标号
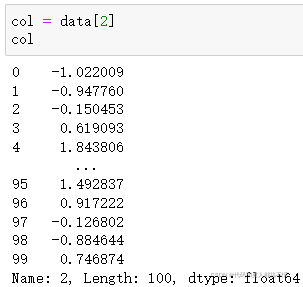
data[2]返回的是该DataFrame下标为2 的所有行,用一个Series表示
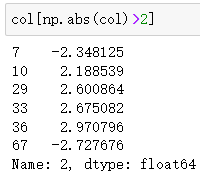
返回该列值绝对值大于2的行下标值

可以详细展开发现确实如此
将F1中符合条件的值赋值为另外一个矩阵F2中应的值:用DataFrame而不是Ndarray
例子

创建两个ndarray,当选满足条件的n1发现只选出来满足条件的数,并没有按原先的格式保存显示,所以无法将其赋值为新的n2中对应的值。

所以将其赋值的时候会报错
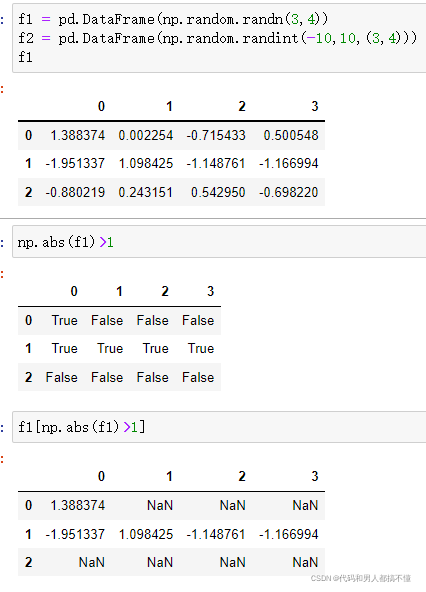
当创建矩阵时用DataFrame,后续选择满足条件的值的时候还保存了格式,所以可以进行后续赋值

将f1中绝对值大于1的替换成f2的值


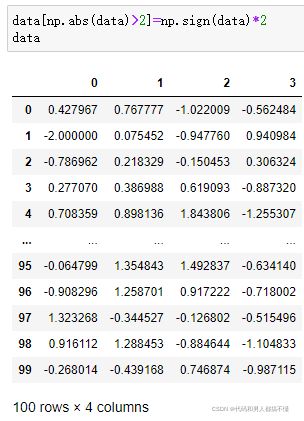
所以,类似的,可将该矩阵中满足条件的数值换成sign()函数中对应的数值


np.sign(data)根据数据中的值的正负分别生成1和-1的数值
1.4.6 置换和随机抽样
使用numpy.random.permutation()方法对DataFrame中的Series或行进行置换(随机重排序)。


可以看到默认只将行进行随机重排序(并不是在原先的DataFrame上修改哦!)
当你想要按照指定的表示新顺序的整数数组
先用np.random.permutations(想要的轴长度)
然后可以用在基于iloc的索引或等价的take()函数中


注意:下面这样是不行的
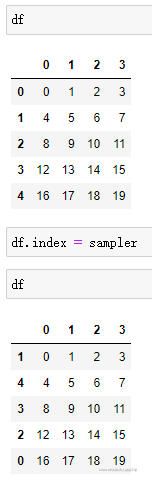
这样并没有将行号对应的Series整个调换,只是调换了index,也就是说只是index序列按新的顺序排列。
进一步对sample()函数进行测试
DataFrame.sample()方法主要是用来对DataFrame进行简单随机抽样的,也就是说他不能用来进行系统抽样、分层抽样的。它可以从DataFrame中随机抽取行,也可以随机抽取列。
sample()方法的参数不多,只有6个,接下来一一实验。
1.n:一个int类型的参数,用来指定随机抽取的样本数目(行数目或者列数目),默认随机抽取行数据。这个参数不能与frac参数同时使用,如果没有指定frac参数,n参数的默认值是1

不指定n,也不指定frac时,默认随机抽取一行数据
不设定random_state的话再次执行sample()方法则由随机生成三行

2.frac:该参数接收一个float类型数据,指定随机抽取行或列的比例,这个参数不能和n参数同时使用。
随机抽取80%的行数据

如果原数据的行数*frac是一个小数,采用五舍六入的原则
另外,官方文档中并没有限定frac参数必须接收0~1之间的数,这暗示frac可以接收大于1的浮点数,这时其实执行的是upsampling。frac如果接收了大于1的浮点数,需要对replace参数进行设置。也就是说,要抽样取出的样本数要大于原有的数量。

3.replace:该参数接收一个bool类型数据,False表示执行无放回抽样,True表示执行有放回抽样,默认为False,即执行无放回抽样。(无放回抽样只可能会被抽到一次)

当frac接收了大于1的浮点数,这意味着sample方法返回的样本量大于原始数据的样本量。只有有放回抽样才能做到这一点,因此此时replace参数必须指定为True

同理可得当参数n指定的数目大于样本数目时,也需要指定replace=True

4.weights:可以给这个参数传递两种类型数据,一种是str类型,一种是Series类型。用来指定抽样权重的,权重越大表示该行数据或者该列数据被抽到的概率越大。这个参数默认值是None,表示此时执行等概率抽样。
——如果是str类型,这个str要求是DataFrame中的一个列名(即执行行抽样)
pandas将str这个列的取值作为该行数据的抽样权重进行抽样,如果列中数据相加和不等于1,则该列数据将被标准化到和为1。列中如果有缺失值,该行数据的抽样权重被视为0,即不抽取这一行数据。


可以看到以df的c列来看,第三行和第四行的数值最大,转换成抽样权重最大,也就是说它俩最容易被抽到,因为c列数值加起来总和不为1,所以首先应该标准化。
——如果是Series类型,此时Series的长度可以和数据中行或者列的长度不同。
以行抽样为例,在进行抽样前,pandas会先进行索引对齐,相当于对DataFrame和Series做一个左连接。DataFrame没有匹配到的索引对应的行抽样权重为0.

背后的机制是首先pandas将df和s进行左连接,df为左表,s为右表,返回如下结果:
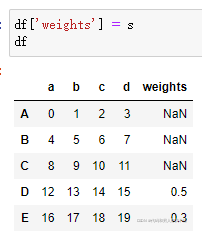
可以看到从s中,df中的D和E行数据匹配到了抽样权重,分别为0.5和0.3,由于前三列weights均为缺失值,也就是抽样权重为0,因此在抽样时将排除该三行,即有效的行为D行和E行。
由于这两行的数据抽样权重分别为0.5和0.3和为0.8不是1,所以在抽样前会标准化为1,最终两行的抽样权重分别为:62.5%和37.5%,也就是说第一行有62.5%的概率被抽到,第二行有37.5%概率被抽到。
5.random_state:这个参数接收一个int类型,可以复现抽样结果。不设置这个参数默认情况下每次抽样是不一样的,即不能复现,但设置了这个参数后就可以复现了。
6.axis:这个参数指定为0或者'index'时,对行进行抽样;指定为1或者'col'时,对列进行抽样。默认执行的是行抽样。

1.4.7 计算指标/虚拟变量
将分类变量转换为“虚拟”或“指标”矩阵是另一种用于统计建模或机器学习的转换操作。如果DataFrame中的一列有k个不同的值,则可以衍生一个k列的值为1和0的矩阵或者DataFrame。pandas有一个get_dummies()函数用于实现该功能。
下面简单讲述get_dummies()方法
使用场景:在对变量进行独热(one-hot)编码时使用。例如:某一列类别型变量是季节,取值为春、夏、秋、冬,当我们对其进行建模时,需要将其进行独热编码,这时pd.get_dummies便派上了用场。

columns:指定需要实现类别转换的列名
prefix: get_dummies转换后,列名的前缀,默认为None(可能之后想与其他数据合并)
prefix_sep:分隔符