基于7.6ElstaicSearch 语法的基本用法
基于7.6ElstaicSearch 语法糖的基本用法
此文章将用最简短的话让你快速认识ElasticSearch的基本语法糖,即CRUD,话不多说,直接开干。
下载
这里需要去官网下载,目前版本已经是8.3了;由于7.x和8.x版本变动较大,这里我们先学习使用7.x版本,在后续我们将过度到8.x版本的使用。
由于是直接在kibana中操作的,所以我们还需要下载对应版本的kibana然后也是打开bin目录下的kibana.bat文件运行即可,然后输入http://localhost:5601/即可。
下载完毕后,解压,运行bin目录下的elasticsearch.bat文件即可,运行成功后如下图所示:
然后在浏览器输入http://localhost:9200/

出现如图即可代表成功。
数据格式
我们这里类别Mysql数据库。
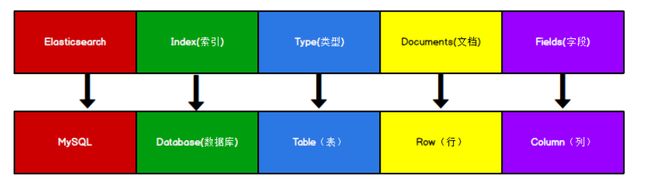
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 Index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。即我们只需要知道索引Index与文档Document即可。
RestFul格式操作
索引操作
# 创建一个基本索引,即不包含任何mapping
PUT /school
# 结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "school"
}
# 创建映射索引
PUT /books
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"type": {
"type": "keyword"
},
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "books"
}
上面的analyzer是指使用的分词器类型为ik_max_word类型,这里不过多阐述,详细可百度。
# 得到索引
GET /books
# 结果
{
"books" : {
"aliases" : { },
"mappings" : {
"properties" : {
"all" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"description" : {
"type" : "text",
"copy_to" : [
"all"
],
"analyzer" : "ik_max_word"
},
"id" : {
"type" : "keyword"
},
"name" : {
"type" : "text",
"copy_to" : [
"all"
],
"analyzer" : "ik_max_word"
},
"type" : {
"type" : "keyword"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1659784542301",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "2Zs9nBz4Ruq1-lnEHk-u4A",
"version" : {
"created" : "7060199"
},
"provided_name" : "books"
}
}
}
}
# 删除索引
DELETE /books
# 结果
{
"acknowledged" : true
}
文档操作
由于文档是基于索引进行操作的,故我们首先需要先创建好索引才能进行文档的创建
这里我们仍然使用books索引进行使用
即首先创建一个索引
# 创建映射索引
PUT /books
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"type": {
"type": "keyword"
},
"all": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 创建文档的两种方式
POST /books/_doc/1
{
"name": "springboot",
"type": "springboot",
"description": "springboot"
}
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
POST /books/_create/3
{
"name": "springboot good",
"type": "springboot good",
"description": "springboot good"
}
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
这里我们需要注意你创建的文档的id,对应结果中的_id,如果不指定id的话,ES会自动给你创建一个id,不过一般我们都需要指定id进行创建。
# 不指定id进行创建文档
POST /books/_doc
{
"name": "springboot1",
"type": "springboot1",
"description": "springboot1"
}
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "UJTmcoIBhiUQRODZJQzV",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
由上代码可以看出_id值。
# 查询books索引下的所有文档
GET /books/_search
# 结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "springboot",
"type" : "springboot",
"description" : "springboot"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "springboot good",
"type" : "springboot good",
"description" : "springboot good"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "UJTmcoIBhiUQRODZJQzV",
"_score" : 1.0,
"_source" : {
"name" : "springboot1",
"type" : "springboot1",
"description" : "springboot1"
}
}
]
}
}
# 根据id查询文档
GET /books/_doc/1
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "springboot",
"type" : "springboot",
"description" : "springboot"
}
}
# 条件查询文档
GET /books/_search/?q=name:good
# 结果
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.81427324,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.81427324,
"_source" : {
"name" : "springboot good",
"type" : "springboot good",
"description" : "springboot good"
}
}
]
}
}
# 删除文档
DELETE /books/_doc/3
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "3",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
# 覆盖修改
PUT /books/_doc/1
{
"name": "springboot very good",
"type": "springboot good",
"description": "springboot good"
}
# 然后查询
GET /books/_doc/1
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 4,
"_seq_no" : 6,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "springboot very good",
"type" : "springboot good",
"description" : "springboot good"
}
}
# 部分修改
POST /books/_update/1
{
"doc": {
"name": "springboot3.0 very good"
}
}
# 然后查询
GET /books/_doc/1
# 结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "springboot3.0 very good",
"type" : "springboot",
"description" : "springboot"
}
}
练习
# 设置该索引的文档数据
PUT /test1/type1/1
{
"name": "王心凌",
"age": 20
}
# 设置索引类型
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
GET test2
PUT /test3/_doc/1
{
"name": "王心凌",
"age": 20,
"birth": "2002-08-23"
}
GET _cat/health
GET _cat/indices?v
PUT /test1/_doc/1
{
"name": "王心凌甜妹",
"age": 20
}
POST /test1/_update/1
{
"doc": {
"name": "王心凌甜妹哦"
}
}
# 删除索引
DELETE test2
# 创建索引
PUT test1/_doc/1
{
"name": "王心凌",
"age": 20,
"desc": "甜妹啊"
}
# 获取索引
GET test1
# 修改索引 一般使用post _update 进行修改 不会进行覆盖操作
POST test1/_update/1/
{
"doc": {
"name": "甜妹王心凌",
"age": 18,
"desc": "我爱心凌姐姐"
}
}
GET test1/_doc/1
# 查询 重点
GET test1/_search?q=name:王心凌
# 复杂查询
# 先在test1索引中多插入几个数据
PUT /test1/_doc/2
{
"name": "小腾",
"age":19,
"desc":"小腾最酷"
}
GET test1/_doc/2
PUT /test1/_doc/3
{
"name": "小叶",
"age":20,
"desc":"是个沙比"
}
PUT /test1/_doc/4
{
"name": "Cyndi",
"age": 20,
"desc": "心凌姐姐啊"
}
GET test1
# 查询匹配
# match:匹配(会使用分词器解析(先分析文档,然后进行查询))
# _source:过滤字段
# sort:排序
# from、size 分页
GET /test1/_search
{
"query": {
"match": {
"name": "小"
}
},
"_source": ["name", "age"],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
# 多条件查询(bool)
# must 相当于 and
# should 相当于 or
# must_not 相当于 not (... and ...)
# filter 过滤
GET /test1/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"desc": "心凌"
}
},
{
"match": {
"age": 20
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
}
}
}
# 匹配数组
# 貌似不能与其它字段一起使用
# 可以多关键字查(空格隔开)— 匹配字段也是符合的
# match 会使用分词器解析(先分析文档,然后进行查询)
# 必须先插入带有数组
GET /test1/_search
{
"query": {
"match": {
"name": "牛 厉害"
}
}
}
# 精确查询(必须全部都有,而且不可分,即按一个完整的词查询)
# term 直接通过 倒排索引 指定词条查询
# 适合查询 number、date、keyword ,不适合text
# 记住 不适合text
# 创建新的索引 并指定类型
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "long"
},
"birth": {
"type": "date"
}
}
}
}
# 插入数据
PUT /test2/_doc/1
{
"name": "甜妹王心凌",
"age":20,
"birth": "2002-01-01"
}
GET /test2/_doc/1
GET /test2/_search
{
"query": {
"term": {
"name": "甜妹王心凌"
}
}
}
# text和keyword
# 测试keyword和text是否支持分词
PUT /test4
{
"mappings": {
"properties": {
"text": {
"type": "text"
},
"keyword": {
"type": "keyword"
}
}
}
}
# 设置字段数据
PUT /test4/_doc/1
{
"text":"测试keyword和text是否支持分词",
"keyword":"测试keyword和text是否支持分词"
}
# 可以查到
GET /test4/_search
{
"query": {
"match": {
"text": "测试"
}
}
}
# 查不到 必须是 "测试keyword和text是否支持分词" 才能查到
GET test4/_search
{
"query": {
"match": {
"keyword": "测试"
}
}
}
# 不会分词 即 王心凌
GET _analyze
{
"analyzer": "keyword",
"text": ["王心凌"]
}
# 会分词 即 测 王 心 凌
GET _analyze
{
"analyzer": "standard",
"text": ["王心凌"]
}
# 高亮查询
GET test1/_search
{
"query": {
"match": {
"desc": "心凌"
}
},
"highlight": {
"fields": {
"desc": {}
}
}
}
# 自定义前缀和后缀
GET test1/_search
{
"query": {
"match": {
"desc": "心凌"
}
},
"highlight": {
"pre_tags": "",
"post_tags": "
",
"fields": {
"desc": {}
}
}
}
Spring Boot整合操作
首先需要导入maven坐标
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
接下来就开始愉快的开始写代码啦
package com.lt.eslearning;
import com.alibaba.fastjson.JSON;
import com.lt.eslearning.entity.User;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchAllQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.naming.directory.SearchResult;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* SpringBoot 整合
*/
@SpringBootTest
class EsLearningApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 测试索引的创建, Request PUT liuyou_index
*/
@Test
public void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("liuyou_index");
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
// 查看是否创建成功
System.out.println(response.isAcknowledged());
// 查看返回对象
System.out.println(response);
restHighLevelClient.close();
}
/**
* 测试获取索引,并判断是否存在
*/
@Test
public void indexIsExistsTest() throws IOException {
GetIndexRequest request = new GetIndexRequest("index");
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
// 查看索引是否存在
System.out.println(exists);
restHighLevelClient.close();
}
/**
* 测试删除索引
*/
@Test
public void deleteIndexTest() throws IOException {
// 不要导错包
DeleteIndexRequest request = new DeleteIndexRequest("liuyou_index");
AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
// 查看是否删除
System.out.println(response.isAcknowledged());
restHighLevelClient.close();
}
/**
* 测试添加文档(先创建一个User实体类,添加fastjson依赖)
*/
@Test
public void addDocumentTest() throws IOException {
User user = new User("liuyou", 18);
// 创建请求
IndexRequest request = new IndexRequest("liuyou_index");
// 指定规则 put /liuyou_index/_doc/1
// 设置文档id
request.id("1");
request.timeout(TimeValue.timeValueMillis(1000L));
// 将我们的数据放入请求中
request.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求,获取响应的结果
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
// 获取建立索引的状态信息 created
System.out.println(response.status());
/**
* IndexResponse[index=liuyou_index,type=_doc,id=1,version=1,result=created,seqNo=0,
* primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
*/
System.out.println(response);
}
/**
* 测试获得文档信息
*/
@Test
public void getDocumentTest() throws IOException {
GetRequest request = new GetRequest("liuyou_index", "1");
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
// 打印文档内容
System.out.println(response.getSourceAsString());
// 返回的全部内容和命令是一样的
System.out.println(request);
restHighLevelClient.close();
}
/**
* 文档的获取,并判断是否存在
*/
@Test
public void documentIsExistsTest() throws IOException {
GetRequest request = new GetRequest("liuyou_index", "1");
// 不获取返回的 _source的上下文了
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none_");
boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
/**
* 文档的更新
*/
@Test
public void updateDocumentTest() throws IOException {
UpdateRequest request = new UpdateRequest("liuyou_index", "1");
User user = new User("kxt", 19);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
// OK
System.out.println(response.status());
restHighLevelClient.close();
}
/**
* 文档的删除
*/
@Test
public void deleteDocumentTest() throws IOException {
DeleteRequest request = new DeleteRequest("liuyou_index", "1");
request.timeout("1s");
DeleteResponse response = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println(response.status());
}
/**
* 文档的查询
* SearchRequest 搜索请求
* SearchSourceBuilder 条件构造
* HighlightBuilder 高亮
* TermQueryBuilder 精确查询
* MatchAllQueryBuilder
* xxxQueryBuilder ...
*/
@Test
public void searchTest() throws IOException {
// 1.创建查询请求对象
SearchRequest request = new SearchRequest();
// 2.构造搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// (1)查询条件 使用QueryBuilders工具类创建
// 精确查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "liuyou");
// 匹配查询
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// (2)其他<可有可无>:(可以参考 SearchSourceBuilder 的字段部分)
// 设置高亮
searchSourceBuilder.highlighter(new HighlightBuilder());
// 分页
searchSourceBuilder.from();
searchSourceBuilder.size(2);
searchSourceBuilder.timeout(new TimeValue(60L, TimeUnit.SECONDS));
// (3)条件投入
searchSourceBuilder.query(termQueryBuilder);
// 3.添加条件到请求
request.source(searchSourceBuilder);
// 4.客户端查询请求
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
// 5.查看返回结果
SearchHits hits = response.getHits();
System.out.println(JSON.toJSONString(hits));
System.out.println("=========================");
for (SearchHit documentFields : hits.getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
/**
* 上面的这些api无法批量增加数据(只会保留最后一个source)
*/
@Test
public void test() throws IOException {
// 没有id会自动生成一个随机ID
IndexRequest request = new IndexRequest("xinling");
request.source(JSON.toJSONString(new User("wang", 1)), XContentType.JSON);
request.source(JSON.toJSONString(new User("xin", 2)), XContentType.JSON);
request.source(JSON.toJSONString(new User("ling", 3)), XContentType.JSON);
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
// CREATED
System.out.println(response.status());
}
/**
* 批量添加数据
*/
@Test
public void batchAddTest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
List<User> users = new ArrayList<>();
users.add(new User("liuyou-1", 1));
users.add(new User("liuyou-2", 2));
users.add(new User("liuyou-3", 3));
users.add(new User("liuyou-4", 4));
users.add(new User("liuyou-5", 5));
users.add(new User("liuyou-6", 6));
// 批量请求处理
for (int i = 0; i < users.size(); i++) {
bulkRequest.add(
// 这里是数据信息
new IndexRequest("xinling")
.id("" + (i + 1))
.source(JSON.toJSONString(users.get(i)), XContentType.JSON)
);
}
BulkResponse response = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
// OK
System.out.println(response.status());
}
}