pytorch构建CycleGAN

给定两个无序图像集合X和Y,该算法能够自动学习到将一种风格的图像转化为另一种风格的图像,例如将horse转化为zebra,或者将zebra转化为horse。
pytorch实现cycleGAN(Horse和Zebra的风格转化)
数据可以自行去Kaggle下载
Abstract
图像对图像的转化过程是一类视觉和图形问题,其目标是学习图像之间的映射
输入图像和使用图像的训练集的输出图像对齐的图像。

我们看到上述两组图像,左图为一组对其的图像,也就是图像的轮廓细节部分大致相同,而右图就是两种风格完全不同的图像。但是对于很多实际的任务来说,很难配套备有成对的图像(成本比较高)。
在论文https://openaccess.thecvf.com/content_ICCV_2017/papers/Zhu_Unpaired_Image-To-Image_Translation_ICCV_2017_paper.pdf
中主要展现的是通过相应的网络模型捕捉到一种图像集合的相关特征信息,然后通过对输入图片进行此类相关特征的转化达到风格转换的目的(在此过程中完全不需要配对的图片)。
具体工作
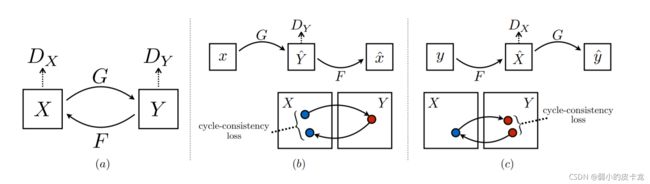
换个图解释

- 我们可以看到图中包含着两个生成器Generator1和Generator2,分别对应这两个输入的数据Horse和Zebra,那么呢既然输入的图片时Horse,那么对应着的目标自然而然的Generator1的目标是是产生Zebra,同样的输入Zebra的Generator2的目标是产生Horse。
- 再看判别器,DIscriminator1的输入数据来源为真实数据Horse以及Generator2产生的假的Horse用fake_horse表示(Generator2本质的数据来源于Zebra数据集),所以损失函数就是MSELoss(Discriminator1(Horse), torch.ones_like(Discriminator1(Horse))) + MSELoss(Discriminator1(Fake_Horse), torch.zeros_like(Discriminator1(Fake_Horse))) 对于Discriminator2来说输入的数据来源为Zebra数据集以及Generator1产生的Fake_Zebra(本质上Generator1的输入数据来源为Horse数据集),所以Discriminator2的损失函数为MSELoss(Discriminator2(Zebra), torch.ones_like(Discriminator2(Zebra))) + MSELoss(Discriminator2(Fake_Zebra), torch.zeros_like(Discriminator2(Fake_Zebra)))
- 对于Generator1以及Generator2来说它们的任务在于骗过判别器所以其中的损失函数分别为MSELoss(Discriminator2(fake_zebra), torch.ones_like(Discriminator2(fake_zebra))) (Generator1的目标是根据horse数据集产生Zebra,由Discriminator2判别真伪),同理Generator2的其中一个损失函数为MSELoss(Discriminator1(fake_Horse), torch.ones_like(Discriminator1(fake_Horse)))
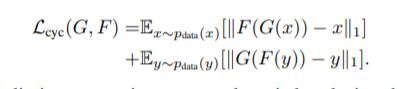
其中提到循环对抗生成网络,其中还包含一个cycleloss,主要是用来衡量该生成器产生的图片与输入图片的一个关系,该损失也属于生成器损失的一部分用L1LOSS来衡量L1loss(Horse, Generator1(Horse)) * r, 一般会乘上一个系数关系r,但是添加此项反而会使性能下降(实操)
代码如下
discriminator
import torch
import torch.nn as nn
class Block(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(Block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
kernel_size=4,
padding=1,
bias=True,
padding_mode="reflect"
),
nn.InstanceNorm2d(num_features=out_channels),
nn.LeakyReLU(0.2)
)
def forward(self, x):
return self.conv(x)
class Discriminator(nn.Module):
def __init__(self, in_channels, features=[64, 128, 256, 512]):
super(Discriminator, self).__init__()
self.initial = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=features[0],
kernel_size=4,
padding=1,
stride=2,
padding_mode="reflect"
),
nn.LeakyReLU(0.2),
)
layers = []
in_channels = features[0]
for feature in features[1:]:
layers.append(Block(in_channels=in_channels, out_channels=feature, stride=1 if feature==features[-1] else 2))
in_channels=feature
layers.append(nn.Conv2d(in_channels=in_channels, out_channels=1, kernel_size=4, stride=1, padding=1, padding_mode="reflect"))
self.model = nn.Sequential(*layers)
def forward(self, x):
x = self.initial(x)
return torch.sigmoid(self.model(x))
def test():
x = torch.randn((1, 3, 256, 256))
model = Discriminator(in_channels=3)
r = model(x)
print(r.size())
if __name__ == '__main__':
test()
Generator
import torch
import torch.nn as nn
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, down=True, use_act=True, **kwargs):
super(ConvBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, padding_mode="reflect", **kwargs)
if down
else nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, **kwargs),
nn.InstanceNorm2d(out_channels),
nn.ReLU(inplace=True) if use_act else nn.Identity()
)
def forward(self, x):
return self.conv(x)
class ResidualBlock(nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
ConvBlock(in_channels=channels, out_channels=channels, kernel_size=3, padding=1),
ConvBlock(in_channels=channels, out_channels=channels, use_act=False, kernel_size=3, padding=1),
)
def forward(self, x):
return x + self.block(x)
class Generator(nn.Module):
def __init__(self, img_channels, num_features = 64, num_residuals=9):
super(Generator, self).__init__()
# (batch_size, img_channels, 256, 256) ----> (batch_size, num_features, 256, 256)
self.initial = nn.Sequential(
nn.Conv2d(in_channels=img_channels, out_channels=num_features, kernel_size=7, stride=1, padding=3, padding_mode="reflect"),
nn.ReLU(inplace=True)
)
# (batch_size, num_features, 256, 256) ----> (batch_size, num_features*2, 128, 128)
# (batch_size, num_features*2, 128, 128) ----> (batch_size, num_features*4, 64, 64)
self.down_blocks = nn.ModuleList(
[
ConvBlock(in_channels=num_features, out_channels=num_features*2, kernel_size=3, stride=2, padding=1),
ConvBlock(in_channels=num_features*2, out_channels=num_features*4, kernel_size=3, stride=2, padding=1),
]
)
self.residual_block = nn.Sequential(
*[ResidualBlock(num_features*4) for _ in range(num_residuals)]
)
# (batch_size, num_features*4, 64, 64) ----> (batch_size, num_features*2, 128, 128)
# (batch_size, num_features * 2, 128, 128) ----> (batch_size, num_features, 256, 256)
self.up_blcoks = nn.ModuleList(
[
ConvBlock(num_features*4, num_features*2, down=False, kernel_size=3, stride=2, padding=1, output_padding=1),
ConvBlock(num_features*2, num_features*1, down=False, kernel_size=3, stride=2, padding=1, output_padding=1),
]
)
# (batch_size, num_features, 256, 256) ----> (batch_size, 3, 256, 256)
self.last = nn.Conv2d(in_channels=num_features*1, out_channels=img_channels, kernel_size=7, stride=1, padding=3, padding_mode="reflect")
def forward(self, x):
x = self.initial(x)
for layer in self.down_blocks:
x = layer(x)
x = self.residual_block(x)
for layer in self.up_blcoks:
x = layer(x)
return torch.tanh(self.last(x))
def test():
x = torch.randn((1, 3, 256, 256))
model = Generator(img_channels=3)
r = model(x)
print(r.size())
if __name__ == '__main__':
test()
train
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
import torchvision
import torchvision.transforms as Transforms
from torch.utils.tensorboard import SummaryWriter
import os
from torch.utils.data import Dataset, dataloader
from CYCLEGAN.config import *
from CYCLEGAN.dataset import HorseZebraDataset
from CYCLEGAN.discriminator import Discriminator
from CYCLEGAN.generator import Generator
from PIL import Image
class cycleGan():
def __init__(self, pretrain=False):
# 参数存放在config文件中
self.lr = LEARNING_RATE
# 批处理大小
self.batch_size = BATCH_SIZE
# 迭代次数
self.epoch = EPOCH
# horse图片保存的路径
self.horse_root = HORSE_ROOT
# zebra图片保存的路径
self.zebra_root = ZEBRA_ROOT
# 图片的通道数
self.image_channels = IMAGE_CHANNELS
# 权重保存的路径
self.D_H_save_path = D_H_SAVE_PATH
self.D_Z_save_path = D_Z_SAVE_PATH
self.G_H_save_path = G_H_SAVE_PATH
self.G_Z_save_path = G_Z_SAVE_PATH
self.transforms = DataSetTransformes
self.pretrain = pretrain
self.device = DEVICE
def train(self):
D_H = Discriminator(in_channels=self.image_channels).to(self.device)
D_Z = Discriminator(in_channels=self.image_channels).to(self.device)
G_H = Generator(img_channels=self.image_channels).to(self.device)
G_Z = Generator(img_channels=self.image_channels).to(self.device)
if self.pretrain:
# 加载horse判别器权重
if os.path.exists(self.D_H_save_path):
D_H.load_state_dict(torch.load(self.D_H_save_path))
print(self.D_H_save_path + '权重加载完成')
else:
print(self.D_H_save_path + '权重加载失败')
# 加载zebra判别器权重
if os.path.exists(self.D_Z_save_path):
D_Z.load_state_dict(torch.load(self.D_Z_save_path))
print(self.D_Z_save_path + '权重加载完成')
else:
print(self.D_Z_save_path + '权重加载失败')
# 加载horse生成器权重
if os.path.exists(self.G_H_save_path):
G_H.load_state_dict(torch.load(self.G_H_save_path))
print(self.G_H_save_path + '权重加载完成')
else:
print(self.G_H_save_path + '权重加载失败')
# 加载zebra生成器权重
if os.path.exists(self.G_Z_save_path):
G_Z.load_state_dict(torch.load(self.G_Z_save_path))
print(self.G_Z_save_path + '权重加载完成')
else:
print(self.G_Z_save_path + '权重加载失败')
# 损失函数
MSE = nn.MSELoss()
L1 = nn.L1Loss()
# 优化器(两个判别器的参数一同更新)
opt_D = torch.optim.Adam(params=list(D_H.parameters()) + list(D_Z.parameters()), lr=self.lr, betas=(0.5, 0.999))
# (两个判别器的参数一同更新)
opt_G = torch.optim.Adam(params=list(G_H.parameters()) + list(G_Z.parameters()), lr=self.lr, betas=(0.5, 0.999))
dataset = HorseZebraDataset(horse_root=self.horse_root, zebra_root=self.zebra_root, transforms=self.transforms)
mydataloader = DataLoader(dataset=dataset,
batch_size=self.batch_size,
shuffle=True)
step = 1
writer_horse_path = "fake_horse"
writer_zebra_path = "fake_zebra"
writer_horse = SummaryWriter(writer_horse_path)
writer_zebra = SummaryWriter(writer_zebra_path)
H_reals = 0
H_fakes = 0
for i in range(self.epoch):
for index, data in enumerate(mydataloader, 1):
print(index)
horse_img, zebra_img = data
horse_img = horse_img.to(self.device)
zebra_img = zebra_img.to(self.device)
# horse
fake_horse = G_H(zebra_img)
D_H_real = D_H(horse_img)
D_H_fake = D_H(fake_horse.detach())
H_reals += D_H_real.mean().item()
H_fakes += D_H_fake.mean().item()
D_H_real_loss = MSE(D_H_real, torch.ones_like(D_H_real))
D_H_fake_loss = MSE(D_H_fake, torch.zeros_like(D_H_fake))
D_H_loss = D_H_real_loss + D_H_fake_loss
# Zebra
fake_zebra = G_Z(horse_img)
D_Z_real = D_Z(zebra_img)
D_Z_fake = D_Z(fake_zebra.detach())
D_Z_real_loss = MSE(D_Z_real, torch.ones_like(D_Z_real))
D_Z_fake_loss = MSE(D_Z_fake, torch.zeros_like(D_Z_fake))
D_Z_loss = D_Z_real_loss + D_Z_fake_loss
# 总损失
D_loss = (D_H_loss + D_Z_loss) / 2
opt_D.zero_grad()
D_loss.backward()
opt_D.step()
# adversarial loss for both generators
D_H_fake = D_H(fake_horse)
D_Z_fake = D_Z(fake_zebra)
loss_G_H = MSE(D_H_fake, torch.ones_like(D_H_fake))
loss_G_Z = MSE(D_Z_fake, torch.ones_like(D_Z_fake))
# cycle loss
cycle_zebra = G_Z(fake_horse)
cycle_horse = G_H(fake_zebra)
cycle_zebra_loss = L1(zebra_img, cycle_zebra)
cycle_horse_loss = L1(horse_img, cycle_horse)
# total loss
G_loss = (
loss_G_Z
+ loss_G_H
+ 10 * cycle_horse_loss
+ 10 * cycle_horse_loss
)
opt_G.zero_grad()
G_loss.backward()
opt_G.step()
if index % 10 == 0:
with torch.no_grad():
D_H.eval()
D_Z.eval()
G_H.eval()
G_Z.eval()
image_grad_horse = torchvision.utils.make_grid(
fake_zebra, normalize=True
)
writer_zebra.add_image("fake_zebra", image_grad_horse, global_step=step)
step += 1
D_H.train()
D_Z.train()
G_H.train()
G_Z.train()
print("[%d/epoch], H_reals: %f, H_fakesL %f" % (index, H_reals, H_fakes))
self.save_weights(G_H, "epoch" + str(i) + '_G_H_' + str(H_reals) + "_" + str(H_fakes))
self.save_weights(G_Z, "epoch" + str(i) + '_G_Z_' + str(H_reals) + "_" + str(H_fakes))
self.save_weights(D_Z, "epoch" + str(i) + '_D_Z_' + str(H_reals) + "_" + str(H_fakes))
self.save_weights(D_H, "epoch" + str(i) + '_D_H_' + str(H_reals) + "_" + str(H_fakes))
# 生成horse风格或者zebra风格的特征图
def GeneratorImg(self, zebra=True):
generator = Discriminator(in_channels=self.image_channels)
if zebra:
if os.path.exists(self.G_Z_save_path):
generator.load_state_dict(torch.load(self.G_Z_save_path))
else:
if os.path.exists(self.G_H_save_path):
generator.load_state_dict(torch.load(self.G_H_save_path))
while True:
img_path = str(input())
img = Image.open(img_path)
img = self.transforms(img)
img.unsqueeze_(dim=0)
result_img = generator(img)
result_img.squeeze_(dim=0)
result_img = Transforms.ToPILImage()
result_img.show()
def save_weights(self, module, path):
if os.path.exists(path):
print(path + '文件已存在')
else:
torch.save(module.state_dict(), path)
if __name__ == '__main__':
cycleGan = cycleGan()
cycleGan.train()
–来自百度网盘超级会员V2的分享
hi,这是我用百度网盘分享的内容~复制这段内容打开「百度网盘」APP即可获取
链接:https://pan.baidu.com/s/1AyfMG6fVpqWZ7GZO5TzMYA
提取码:awmg