08_实践:使用Sequential Model搭建VGG16进行猫狗识别
08_实践:使用Sequential Model搭建VGG16进行猫狗识别
-
- 1.搭建VGG16模型
- 2.训练猫狗识别模型
-
- 2.1 数据预处理
- 2.2 导入模型
- 2.3训练并保存模型:
- 3.测试训练好的模型
1.搭建VGG16模型
本部分搭建一个通用的VGG16模型,本部分参考了:
- Very Deep Convolutional Networks for Large-Scale Image Recognition (ICLR 2015)
- keras官方:vgg16.py
我觉得学习Keras官方代码中构建模型的样例是很有必要的,阅读源码不仅可以学到框架的使用方法,其中的源代码作者的编程风格和编程规范也是很值得去学习领悟的。
首先导入需要用的函数:
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.utils import *
import os
预训练好的权重文件的下载链接,如果使用代码不好下载可以在迅雷中输入下面的链接下载,这样会快很多:
VGG16_WEIGHTS_PATH = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.1/'
'vgg16_weights_tf_dim_ordering_tf_kernels.h5')
VGG16_WEIGHTS_PATH_NO_TOP = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.1/'
'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
定义生成VGG16模型的方法:
def vgg16(include_top=True,weights='imagenet',
input_shape=None,pooling=None,classes=1000):
"""使用tf.keras sequential model构建VGG16模型
# Arguments
include_top:是否包含网络最后的3层全连接层,默认为包含。
weights:选择预训练权重,默认为'imagenet',可选'None'为随机初始化权重或者其他权重的路径。
input_shape:输入的尺寸,应该是一个元组,当include_top设为True时默认为(224,224,3),否则应当被
定制化,因为输入图像的尺寸会影响到全连接层参数的个数。
pooling:指定池化方式。
classes:类别数量。
# Returns
返回一个tf.keras sequential model实例。
# Raises
ValueError:由于不合法的参数会导致相应的异常。
"""
# 检测weights参数是否合法,如果不合法会引发异常
if not(weights in {'imagenet',None} or os.path.exists(weights)):
raise ValueError("the input of weights is not valid")
# 检测include_top和classes是否冲突,如果不合法会引发异常
if weights=='imagenet' and include_top and classes!=1000:
raise ValueError("if using weights='imagenet' and include_top=True,classes should be 1000.")
# 开始定义模型
model = Sequential()
# Block 1
model.add(Conv2D(input_shape=input_shape,filters=64,kernel_size=3,
strides=1,padding='same',activation='relu',name='block1_conv1'))
model.add(Conv2D(64,3,strides=1,padding='same',activation='relu',name='block1_conv2'))
model.add(MaxPooling2D(2,2,'same',name='block1_maxpool'))
# Block 2
model.add(Conv2D(128,3,strides=1,padding='same',activation='relu',name='block2_conv1'))
model.add(Conv2D(128,3,strides=1,padding='same',activation='relu',name='block2_conv2'))
model.add(MaxPooling2D(2,2,'same',name='block2_maxpool'))
# Block 3
model.add(Conv2D(256,3,strides=1,padding='same',activation='relu',name='block3_conv1'))
model.add(Conv2D(256,3,strides=1,padding='same',activation='relu',name='block3_conv2'))
model.add(Conv2D(256,3,strides=2,padding='same',activation='relu',name='block3_conv3'))
model.add(MaxPooling2D(2,2,'same',name='block3_maxpool'))
# Block 4
model.add(Conv2D(512,3,strides=1,padding='same',activation='relu',name='block4_conv1'))
model.add(Conv2D(512,3,strides=1,padding='same',activation='relu',name='block4_conv2'))
model.add(Conv2D(512,3,strides=1,padding='same',activation='relu',name='block4_conv3'))
model.add(MaxPooling2D(2,2,'same',name='block4_maxpool'))
# Block 5
model.add(Conv2D(512,3,strides=1,padding='same',activation='relu',name='block5_conv1'))
model.add(Conv2D(512,3,strides=1,padding='same',activation='relu',name='block5_conv2'))
model.add(Conv2D(512,3,strides=1,padding='same',activation='relu',name='block5_conv3'))
model.add(MaxPooling2D(2,2,'same',name='block5_maxpool'))
if include_top: #包含默认的全连接层
model.add(Flatten(name='flatten'))
model.add(Dense(4096,activation='relu',name='fc_layer1'))
model.add(Dense(4096,activation='relu',name='fc_layer2'))
model.add(Dense(classes,activation='softmax',name='predictions_layer'))
else:
if pooling == 'avg':
model.add(GlobalAveragePooling2D())
elif pooling == 'max':
model.add(GlobalMaxPooling2D())
# 加载权重
if weights == 'imagenet':# 从Github下载权重
if include_top:
weights_path = get_file(
'vgg16_weights_tf_dim_ordering_tf_kernels.h5',
VGG16_WEIGHTS_PATH,
cache_subdir='models',
file_hash='64373286793e3c8b2b4e3219cbf3544b')
else:
weights_path = get_file(
'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5',
VGG16_WEIGHTS_PATH_NO_TOP,
cache_subdir='models',
file_hash='6d6bbae143d832006294945121d1f1fc')
model.load_weights(weights_path)
print("Loading weigths from "+weights_path+" finished!")
elif weights is not None: # 从指定路径加载权重
model.load_weights(weights)
print("Loading weigths from "+weights+" finished!")
# 返回定义好的模型
return model
函数解析:
include_top可以决定返回的模型是只有卷积层还是包括卷积层和全连接层。weights参数可以决定从哪里加载好预先训练好的权重文件,设置None则从头开始训练。input_shape设置模型输入尺寸,是一个元组。pooling设置全局池化的方法,这个只在include_top为False的情况下有用。classes分类的类别数。- 后面训练的时候
include_top设为False去除全连接层,从而只保留卷积层,然后自己构建全连接层加到VGG16卷积层后面去。
本部分完整代码:
vgg.py
2.训练猫狗识别模型
2.1 数据预处理
# 处理数据
train_datagen = ImageDataGenerator(
rotation_range = 40,width_shift_range = 0.2,height_shift_range = 0.2, rescale = 1/255,shear_range = 20,
zoom_range = 0.2,horizontal_flip = True,fill_mode = 'nearest',)
test_datagen = ImageDataGenerator(rescale = 1/255,) # 数据归一化
batch_size = 32
# train_data
train_generator = train_datagen.flow_from_directory(
'01_tf_keras/sequential_model/data/cat_vs_dog/train',
target_size=(150,150),
batch_size=batch_size)
# test_data
test_generator = test_datagen.flow_from_directory(
'01_tf_keras/sequential_model/data/cat_vs_dog/test',
target_size=(150,150),
batch_size=batch_size )
2.2 导入模型
# 导入模型
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.preprocessing.image import *
from vgg import vgg16
# 指定权重路径从本地加载权重
weights_path = '01_tf_keras/sequential_model/weights/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5'
# include_top设为False
model = vgg16(weights=weights_path,
include_top=False,input_shape=(150,150,3),classes=2)
# 自定义全连接层
model.add(Flatten(input_shape=model.output_shape[1:],name='flatten'))
model.add(Dense(256,activation='relu',name='fc_layer1'))
model.add(Dropout(0.3,name='dropout1'))
model.add(Dense(2,activation='softmax',name='predictions_layer'))
model.summary()
2.3训练并保存模型:
# train
model.compile(optimizer=SGD(lr=0.001,momentum=0.9),loss='categorical_crossentropy',metrics=['accuracy'])
model.fit_generator(train_generator,steps_per_epoch=len(train_generator),
epochs=50,validation_data=test_generator,
validation_steps=len(test_generator))
model.save('01_tf_keras/sequential_model/weights/model_vgg16.h5')
迭代了50次之后准确率达到了91.5%。
本部分完整代码:
07_fintune_vgg16_cat_vs_dog.py
3.测试训练好的模型
使用方法:
python 08_predict_cat_or_dog.py -i 图片路径
导入load_model方法来加载之前保存的模型:
import argparse as ap
import numpy as np
import cv2 as cv
from tensorflow.keras.preprocessing.image import *
from tensorflow.keras.models import load_model
加载模型,使用opencv来读取图片,并将读入的图片处理成模型需要的输入格式:
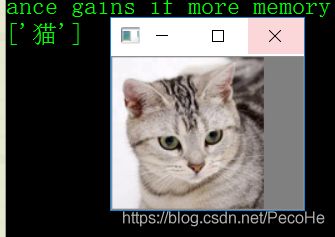
label = np.array(['猫','狗'])
model = load_model('/home/peco/Desktop/Learn_TensorFlow2.0/01_tf_keras/sequential_model/weights/model_vgg16.h5')
def pred(img):
image = load_img(img)
cv.imshow("input",cv.cvtColor(np.asarray(image),cv.COLOR_RGB2BGR))
image = image.resize((150,150))
image = img_to_array(image)
image = image/255
image = np.expand_dims(image,0)
image.shape
print(label[model.predict_classes(image)])
cv.waitKey(0)
pred(args.image_path)
结果检测: