Spark RDD 论文详解(四)表达 RDDs
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
目录
Spark RDD 论文详解(一)摘要和介绍
Spark RDD 论文详解(二)RDDs
Spark RDD 论文详解(三)Spark 编程接口
Spark RDD 论文详解(四)表达 RDDs
Spark RDD 论文详解(五)实现
Spark RDD 论文详解(六)评估
Spark RDD 论文详解(七)讨论
Spark RDD 论文详解(八)相关工作和结尾
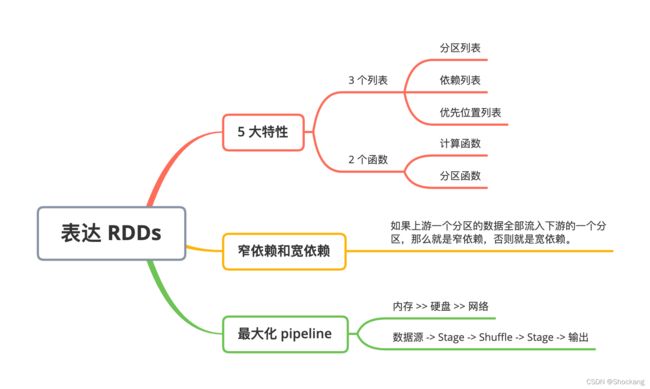
思维导图
正文
4、表达 RDDs
原文翻译
在抽象 RDDs 的过程中,一个比较大的挑战是怎么表达出 RDDs 可以追踪很多transformations 之间的血缘关系。
理想的情况下,一个实现了 RDDs 的系统应该是尽可能多的提供 transformations 操作(比如表二中的操作),并且可以让用户以任意的方式来组合这些 transformations 操作。
我们提出了基于图的 RDDs 展现方式来达到以上的目的。
我们在 Spark 中利用这种展现方式实现了,不需要调度系统为每一个 transformation 操作增加任何的特殊逻辑,就可以支持大量的 transformations 操作,这样极大的简化了我们的系统设计。
概括的说,以下五个信息可以表达 RDDs:
- 一个分区列表,每一个分区就是数据集的原子块。
- 一个父亲 RDDs 的依赖列表。
- 一个计算父亲的数据集的函数。
- 分区模式的元数据信息。
- 数据存储信息。
比如,基于一个 HDFS 文件创建出来的的 RDD 中文件的每一个数据块就是一个分区,并且这个 RDD 知道每一个数据块存储在哪些机器上,同时,在这个 RDD 上进行 map 操作后的结果有相同的分区数,当计算元素的时候,将 map 函数应用到父亲 RDD 数据中的。
我们在表三总结了这些接口:
| 操作接口 | 含义 |
|---|---|
| partitions() | 返回一个分区对象的列表 |
| preferredLocations(p ) | 分区p数据存储在哪些机器节点中 |
| dependencies() | 返回一个依赖列表 |
| iterator(p, parentIters) | 根据父亲分区的数据输入计算分区p的所有数据 |
| partitioner() | 返回这个RDD是hash还是range分区的元数据信息 |
表三:Spark 中表达 RDDs 的接口
在设计如何表达 RDDs 之间依赖的接口是一个非常有意思的问题。
我们发现将依赖定义成两种类型就足够了:
- 窄依赖,表示父亲 RDDs 的一个分区最多被子 RDDs 一个分区所依赖。
- 宽依赖,表示父亲 RDDs 的一个分区可以被子 RDDs 的多个子分区所依赖。
比如,map 操作是一个窄依赖,join 操作是一个宽依赖操作(除非父亲 RDDs 已经被 hash 分区过),图四显示了其他的例子:
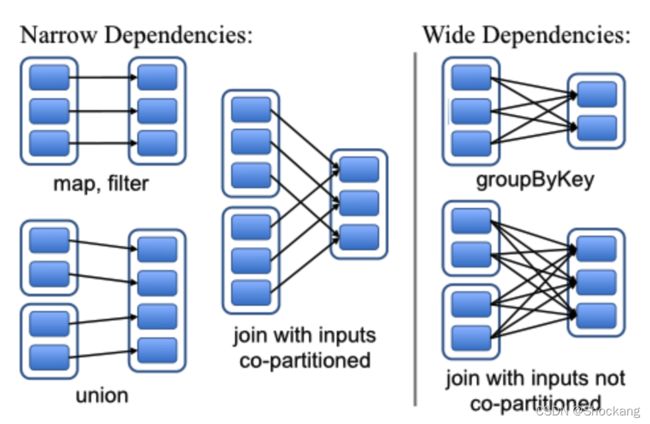
以下两个原因使的这种区别很有用
-
第一,窄依赖可以使得在集群中一个机器节点上面流水线式执行所有父亲的分区数据,比如,我们可以将每一个元素应用了 map 操作后紧接着应用 filter 操作,与此相反,宽依赖需要父亲 RDDs 的所有分区数据准备好并且利用类似于 MapReduce 的操作将数据在不同的节点之间进行Shuffle。
-
第二,窄依赖从一个失败节点中恢复是非常高效的,因为只需要重新计算相对应的父亲的分区数据就可以,而且这个重新计算是在不同的节点进行并行重计算的,与此相反,在一个含有宽依赖的血缘关系 RDDs 图中,一个节点的失败可能导致一些分区数据的丢失,但是我们需要重新计算父 RDD 的所有分区的数据。
Spark 中的这些 RDDs 的通用接口使的实现很多 transformations 操作的时候只花了少于 20 行的代码。
实际上,新的 spark 用户可以在不了解调度系统的细节之上来实现新的 transformations 操作(比如,采样和各种 join 操作)。
下面简要的概括了一些 RDD 的实现:
- HDFS files:抽样的输入 RDDs 是 HDFS 中的文件。对于这些 RDDs,partitions 返回文件中每一个数据块对应的一个分区信息(数据块的位置信息存储在 Partition 对象中),preferredLocations 返回每一个数据块所在的机器节点信息,最后 iterator 负责数据块的读取操作。
- map:对任意的 RDDs 调用 map 操作将会返回一个 MappedRDD 对象。这个对象含有和其父亲 RDDs 相同的分区信息和数据存储节点信息,但是在 iterator 中对父亲的所有输出数据记录应用传给 map 的函数。
- union:对两个 RDDs 调用 union 操作将会返回一个新的 RDD,这个 RDD 的分区数是他所有父亲 RDDs 的所有分区数的总数。每一个子分区通过相对应的窄依赖的父亲分区计算得到。
- sample:sampling 和 mapping 类似,除了 sample RDD 中为每一个分区存储了一个随机数,作为从父亲分区数据中抽样的种子。
- join:对两个 RDDs 进行 join 操作,可能导致两个窄依赖(如果两个 RDDs 都是事先经过相同的 hash/range 分区器进行分区),或者导致两个宽依赖,或者一个窄依赖一个宽依赖(一个父亲 RDD 经过分区而另一个没有分区)。不论哪种情况,join 之后的输出 RDD 会有一个 partitioner(从父亲 RDD 中继承过来的或者是一个默认的 hash partitioner)。
解析
5 大特性
Spark RDD 的 5 大特性实际上总结起来就是 3 个列表,2 个函数。
3 个列表分别是分区列表,依赖列表,优先位置列表。
2 个函数是计算函数和分区函数。
窄依赖和宽依赖
如果上游一个分区的数据全部流入下游的一个分区,那么就是窄依赖,否则就是宽依赖。
之所以区分窄依赖和宽依赖,其实就是遵循一个最大化 pipeline 的思想。
在大数据技术框架中,有一个思想其实贯穿始终:
内存 >> 硬盘 >> 网络
内存,硬盘和网络之间的速度差异都是非常大的,在任何时候,我们首先应该考虑的是:能不能直接利用内存来存储计算?
最大化pipeline 就是代表一个数据计算流程中内存计算的比例达到最大。
窄依赖就是说数据在一个节点上面的内存里面就能够完成所有计算,宽依赖就是说单个节点还不行,必须得走网络传输(在 Spark/MR 体系中,这被称为 Shuffle)。
区分好了窄依赖和宽依赖,我们就能以此为边界,对计算流程进行分步骤,我们通常以宽依赖为边界,对于同一个节点上面的计算就构成了一个 Stage。
Spark 中单个 Job 的流程一般遵循着下面的步骤:
数据源 -> Stage -> Shuffle -> Stage -> 输出
其中 Stage 和 Shuffle 都是可以交替重复的。