基于Python实现的人工智能作业小车问题
目录
1 任务描述 2
2 环境配置 2
3 算法设计 2
3.1 离散版本 − 2
(1)问题背景 2
(2)Q-learning 算法 2
(3)程序流程 3
3.2 连续版本 3
3.3 其他算法(选做) 4
(1)SARSA 4
(2)() 4
(3)DQN 4
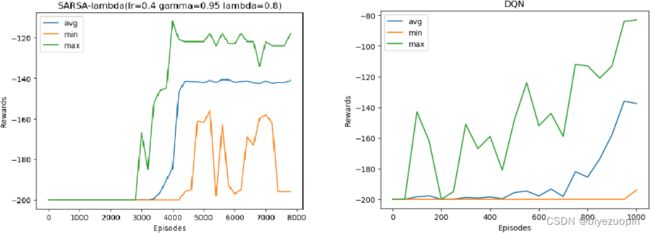
3.4 算法对比 5
4 参数调整及优化1 6
·回报 reward: 6
5 总结与反思 7
6 参考文献和资料 7
1任务描述
·必做:使用强化学习算法,解决MountainCar − v0;
使用强化学习算法,解决MountainCarContinous − v0
·选做:使用其他强化学习算法解决上述问题
2环境配置
·python(3.6) + gym(0.15.4) + tensorflow(1.2.1) + keras(2.2.4)
3算法设计
3.1 离散版本 −
(1)问题背景
现有一小车在两座山峰之间的谷底,小车动力有限,无法直接登上右侧山峰,需要借助 动能和势能之间的转化才能到达目的地。本文转载自http://www.biyezuopin.vip/onews.asp?id=16767在离散版本的MountainCar中,小车的行为(action) 是离散的,有向左、向右、静止三个选项,每个状态(state)下小车的观测值包含位置(position)和速度(velocity)两个方面,小车从-0.4—-0.6 之间的任意位置开始运动,在一个 episode
(200 步)内抵达 0.5 处即为成功,每走一步获得-1 的回报值。
本次设计为强化学习方面的程序设计,通过这次作业我加深了对 Q-learning 和 SARSA 两类算法的理解,用实践巩固了理论知识,并从程序结果更清晰地体会到了不同算法之间的差异,新学习了 SARSA(λ)和函数逼近的 DQN 算法,也是对之前监督学习的一个回顾,同时, 我掌握并锻炼了 python 语言的编写,熟悉了 pycharm 平台的相关操作,有了上大作业的经验,这次配置环境、安装数据包等都熟练了很多。这是人工智能课程最后一个作业了,在这门课上真的收获很多,感谢老师和助教本学期以来的帮助!
# DQN 离散
import gym
import numpy as np
import matplotlib.pyplot as plt
from keras import models
from keras.layers import Dense, Activation
from keras.optimizers import Adam
from collections import deque
import random
from tqdm import tqdm
env = gym.make("MountainCar-v0")
env.reset()
ACTION_SPACE_SIZE = env.action_space.n
REPLAY_MEMORY_SIZE = 50000
MIN_REPLAY_MEMORY_SIZE = 1000
MINIBATCH_SIZE = 64
UPDATE_TARGET_EVERY = 5
DISCOUNT = 0.99
EPISODES = 1000
# 参数设置
epsilon = 1 # 动态变化
EPSILON_DECAY = 0.995
MIN_EPSILON = 0.001
ep_rewards = []
AGGREGATE_STATS_EVERY = 50
MIN_EPSILON = 0.001
recorder = {"epsode": [], "epsilon": []}
for epsode in range(EPISODES):
if epsilon > MIN_EPSILON:
epsilon *= EPSILON_DECAY
epsilon = max(MIN_EPSILON, epsilon)
recorder["epsode"].append(epsode)
recorder["epsilon"].append(epsilon)
plt.plot(recorder["epsode"], recorder["epsilon"])
plt.show()
# 创建网络模型
def create_model():
model = models.Sequential()
model.add(Dense(16, input_shape=(env.observation_space.shape)))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(16))
model.add(Activation('relu'))
model.add(Dense(ACTION_SPACE_SIZE))
model.add(Activation('linear'))
print(model.summary())
model.compile(loss='mse', optimizer=Adam(lr=0.001), metrics=['accuracy'])
return model
# DQN智能体
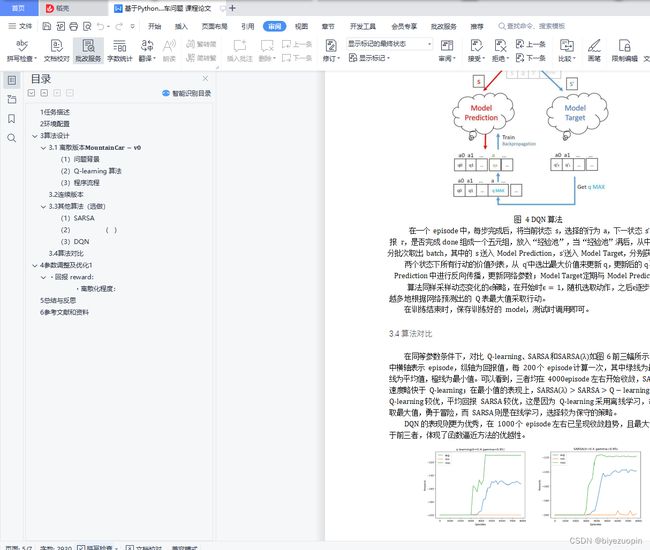
class DQNAgent:
def __init__(self):
# 记忆池
self.replay_memory = deque(maxlen=REPLAY_MEMORY_SIZE)
# 创建Prediction Network
self.model_prediction = create_model()
# 创建Target Network
self.model_target = create_model()
self.model_target.set_weights(self.model_prediction.get_weights())
# 计数,到一定次数更新Target Network
self.target_update_counter = 0
# 添加一组新数据到记忆池
# (current_state, action, reward, next_state, done)
def update_replay_memory(self, transition):
self.replay_memory.append(transition)
# 预测Q表
def get_qs(self, state):
return self.model_prediction.predict(np.array(state).reshape(-1, *state.shape))[0]
# 训练
def train(self, terminal_state, step):
# 如果记忆池未满,退出
if len(self.replay_memory) < MIN_REPLAY_MEMORY_SIZE:
return
# 从记忆池中取一个batch
minibatch = random.sample(self.replay_memory, MINIBATCH_SIZE)
# 获取batch中的s,送入Prediction Network获得q表current_qs_list输出
current_states = np.array([transition[0] for transition in minibatch])
current_qs_list = self.model_prediction.predict(current_states)
# 获取batch中的s',送入Target Network获得q'表target_qs_list
next_states = np.array([transition[3] for transition in minibatch])
target_qs_list = self.model_target.predict(next_states)
X = []
y = []
# 遍历batch中元素,对每一组数据
for index, (current_state, action, reward, next_state, done) in enumerate(minibatch):
# q=learning算法
if not done:
max_target_q = np.max(target_qs_list[index])
new_q = reward + DISCOUNT * max_target_q
else:
new_q = reward
# 更新q表
current_qs = current_qs_list[index]
current_qs[action] = new_q
# 将状态s和q表添加至网络的输入x和输出y
X.append(current_state)
y.append(current_qs)
# Fit on all samples as one batch, log only on terminal state
self.model_prediction.fit(np.array(X), np.array(y), batch_size=MINIBATCH_SIZE, verbose=0,
shuffle=False if terminal_state else None)
# 计数,定期更新Target Network参数,使之与Prediction同步
if terminal_state:
self.target_update_counter += 1
if self.target_update_counter > UPDATE_TARGET_EVERY:
self.model_target.set_weights(self.model_prediction.get_weights())
self.target_update_counter = 0
# 实例化
agent = DQNAgent()
aggr_ep_rewards = {'ep': [], 'avg': [], 'min': [], 'max': []}
for episode in tqdm(range(1, EPISODES + 1), ascii=True, unit='episodes'):
# Restarting episode - reset episode reward and step number
episode_reward = 0
step = 1
current_state = env.reset()
done = False
while not done:
# epsilon-greedy策略
if np.random.random() > epsilon:
# 利用网络训练出的q表取最大
action = np.argmax(agent.get_qs(current_state))
else:
# 随机
action = np.random.randint(0, ACTION_SPACE_SIZE)
next_state, reward, done, _ = env.step(action)
episode_reward += reward
# 每个episode更新记忆池,并训练
agent.update_replay_memory((current_state, action, reward, next_state, done))
agent.train(done, step)
current_state = next_state
step += 1
# 记录数据
ep_rewards.append(episode_reward)
if not episode % AGGREGATE_STATS_EVERY or episode == 1:
average_reward = sum(ep_rewards[-AGGREGATE_STATS_EVERY:]) / len(ep_rewards[-AGGREGATE_STATS_EVERY:])
min_reward = min(ep_rewards[-AGGREGATE_STATS_EVERY:])
max_reward = max(ep_rewards[-AGGREGATE_STATS_EVERY:])
aggr_ep_rewards['ep'].append(episode)
aggr_ep_rewards['avg'].append(average_reward)
aggr_ep_rewards['min'].append(min_reward)
aggr_ep_rewards['max'].append(max_reward)
# 动态降低epsilon
if epsilon > MIN_EPSILON:
epsilon *= EPSILON_DECAY
epsilon = max(MIN_EPSILON, epsilon)
env.close()
agent.model_prediction.save('dqn_1.model')
plt.plot(aggr_ep_rewards['ep'], aggr_ep_rewards['avg'], label='avg')
plt.plot(aggr_ep_rewards['ep'], aggr_ep_rewards['min'], label='min')
plt.plot(aggr_ep_rewards['ep'], aggr_ep_rewards['max'], label='max')
plt.legend(loc='upper left')
plt.xlabel('Episodes')
plt.ylabel('Rewards')
plt.show()