「ClickHouse系列」实时分析优化AggregateFunction及物化视图
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜
八股文教给我,你们专心刷题和面试
![]()
Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
AggregateFunction
AggregatingMergeTree有些许数据立方体的意思,它能够在合并分区的时候,按照预先定义的条件,聚合数据。
同时,根据预先定义的聚合函数,计算数据并通过二进制的格式存入表内。
将同一分组下的多行数据,聚合成一行,既减少了数据行,又降低了后续聚合查询的开销。
-- 建表语句
CREATE TABLE agg_table(
id String,
city String,
code AggregateFunction(uniq,String),
value AggregateFunction(sum,UInt32),
create_time DateTime
)
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,city)
PRIMARY KEY id其中的uniq、sum是指定的聚合函数。大家可以在官网aggregate-functions 下查看更多的相关函数。
AggregateFunction是ClickHouse提供的一种特殊的数据类型,它能够以二进制的形式存储中间状态结果。
其使用方法也十分特殊,对于AggregateFunction类型的列字段,数据的写入和查询都与寻常不同。
在写入数据时,需要调用State函数。而在查询数据时,则需要调用相应的Merge函数。
例如:在写入数据时需要调用与uniq、sum对应的uniqState和sumState函数,并使用INSERT SELECT 语法:
-- 写入测试数据id = A000, code相同;
INSERT INTO TABLE agg_table SELECT 'A000','test', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
INSERT INTO TABLE agg_table SELECT 'A000','test', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
-- 写入测试数据id = A001, code不同;
INSERT INTO TABLE agg_table SELECT 'A001','test', uniqState('code1'), sumState(toUInt32(100)), '2019-08-10 17:00:00';
INSERT INTO TABLE agg_table SELECT 'A001','test', uniqState('code2'), sumState(toUInt32(50)), '2019-08-10 17:00:00';而在查询数据时,如果直接使用列名访问code和value,将会是无法显示的二进制。
此时,则需要调用与uniq、sum对应的uniqMerge、sumMerge函数:
SELECT id,city,uniqMerge(code),sumMerge(value) FROM agg_table GROUP BY id,city;
┌─id───┬─city─┬─uniqMerge(code)─┬─sumMerge(value)─┐
│ A001 │ test │ 2 │ 150 │
│ A000 │ test │ 1 │ 200 │
└──────┴──────┴─────────────────┴─────────────────┘
2 rows in set. Elapsed: 0.002 sec.可以看到id = A000 的uniqMerge(code) 为1、可见uniq函数是生效的。
但是你是否会认为AggregatingMergeTree使用起来过于繁琐呢?
连正常进行数据写入都行不通,还需要借助INSERT…SELECT的句式并调用特殊函数。如果直接像刚才示例中那样使用AggregatingMergeTree,确实会非常的麻烦。
不过各位读者并不需要忧虑,因为目前介绍的这种使用方式,并不是它的主流用法。
物化视图
AggregatingMergeTree更为常⻅的应用方式,是结合物化视图使用,将它作为物化视图的表引擎。
而这里的物化视图,则是作为其他数据表上层的一种查询视图。
现在用一组示例说明它的用法,首先,建立明细数据表,也就是俗称的底表。
CREATE TABLE agg_table_basic( id String,
city String,
code String,
value UInt32
)ENGINE = MergeTree() PARTITION BY city ORDER BY (id,city)通常会使用MergeTree作为底表,用于存储全部的明细数据,并以此对外提供实时查询。
接着,新建一张物化视图:
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id,city)
AS SELECT id,
city,
uniqState(code) AS code,
sumState(value) AS value
FROM agg_table_basic GROUP BY id, city;物化视图使用AggregatingMergeTree表引擎,用于特定场景的数据查询,相比MergeTree它拥有更高的性能。
在新增数据时,面向的对象是底表MergeTree:
INSERT INTO TABLE agg_table_basic VALUES
('A000','wuhan','code1',100),
('A000','wuhan','code2',200),
('A000','zhuhai','code1',200);数据会自动同步到物化视图,并按照AggregatingMergeTree引擎的规则处理。
在查询数据时,面向的对象则是物化视图AggregatingMergeTree:
SELECT id, sumMerge(value), uniqMerge(code) FROM agg_view GROUP BY id, city;
┌─id───┬─sumMerge(value)─┬─uniqMerge(code)─┐
│A000│ 200 │ 1 │
│A000│ 300 │ 2 │
└──────┴───────────────┴───────────────┘接下来,简单梳理一下AggregatingMergeTree的处理逻辑:
使用ORBER BY排序键,作为聚合数据的条件Key
使用AggregateFunction字段类型,定义聚合函数的类型以及聚合的字段
只有在合并分区的时候,才会触发聚合计算的逻辑
以数据分区为单位,聚合数据。当分区合并时,同一数据分区内,聚合Key相同的数据,会合并计算;而不同分区之间,那些跨越分区的数据,则不会被计算
在进行数据计算时,因为分区内的数据已经基于ORBER BY排序,所以能够找到那些相邻的,拥有 相同聚合Key的数据
在聚合数据时,同一分区内,相同聚合Key的多行数据,会合并成一行。对于那些非主键、非AggregateFunction类型字段,则会使用第一行数据的取值
AggregateFunction类型的字段使用二进制存储,在写入数据时,需要调用State函数;而在查询数据时,则需要调用相应的Merge函数。其中,*表示定义时使用的聚合函数
AggregatingMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用
物化视图完整语法:
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name]
[ENGINE = engine] [POPULATE] AS SELECT ...当物化视图创建之后,如果源表被写入了新数据,那么物化视图也会同步更新。
POPULATE修饰符决定了物化视图的初始化策略:
如果使用了POPULATE修饰符,那么在创建视图的过程中,会连带将源表中 已存在的数据一并导入,如同执行了SELECT INTO一般;
反之,如果不使用POPULATE修饰符,那么物化视图在创建之后是没有数据的,它只会同步在此之后被写入源表的数据。
物化视图目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保留。
物化视图本质上是一张特殊的数据表,例如使用SHOW TABLE查看数据表的列表:
SHOW TABLES;
┌─name────────┐
│ .inner.view_test2 │ │ .inner.view_test3 │
└───────────┘原理
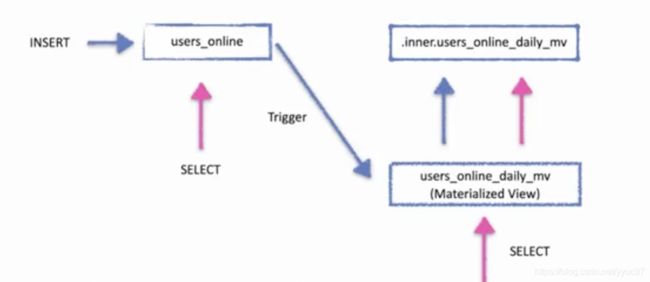
上述的AggregateFunction底层原理是使用的预计算,也就是每写入一批数据,trigger就会触发一次计算结果更新视图。所以在海量数据的场景下这种查询效率也是非常高的。
 如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

 2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」