异常值(离群值)是指距离其他数据值太远的数据值。数据异常值可能是自然产生的,也可能是由于测量不准确、或系统故障造成的。与缺失值类似,异常值会破坏数据科学项目并返回错误的结果或预测。异常值也可能出现在倾斜数据中,这些类型的异常值被认为是自然异常值。
异常值会影响数据的平均值、标准差和四分位范围。如果我们在去除异常值之前和之后计算这些统计数据,我们会得到不同的结果。
异常值如何影响机器学习模型?
如果我们的异常值是自然的而不是由于测量误差,则应该将它保留在数据集中,并执行数据转换来对其进行规范化处理。如果我们的数据集很大,但异常值很少,我们应该保留这些异常值,因为它们不会显著影响结果,并且可以为我们的模型带来泛化的效果。
如果我们非常确定我异常值是由于测量误差带来的,则应该从数据集中删除它们。去除异常值的将减少数据集的大小,并可以让我们的模型的适用到所包含的度量范围。但是要记住去掉自然异常值可能导致模型不准确。
使用可视化工具检测异常值
异常值是不容易被“肉眼”发现的,但是有一些可视化工具可以帮助完成这项任务。最常见的是箱形图和直方图。
和往常一样,我们第一步是加载必要的库和导入/加载数据集。这里将使用insurance.csv(https://www.kaggle.com/datase...)。
import numpy as np
import pandas as pd
import seaborn as sns
import statistics
df = pd.read_csv('insurance.csv')
df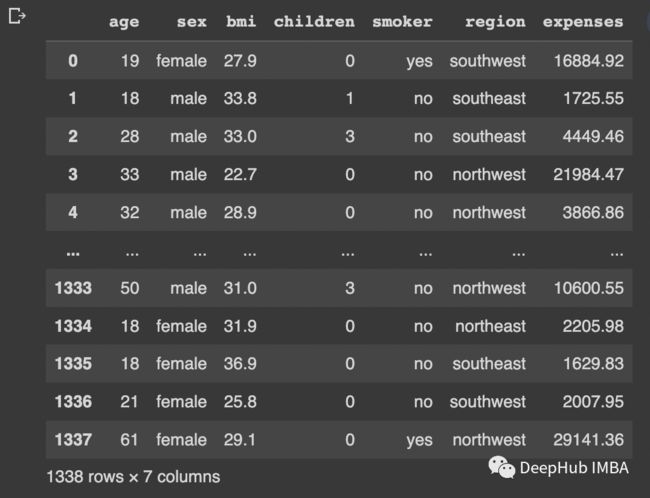
我们将检查age,bmi和expenses的异常值。
第一种方法是用box - plot表示数据分布:
sns.boxplot(y="age", data=df)
sns.boxplot(y="bmi", data=df)
sns.boxplot(y="expenses", data=df)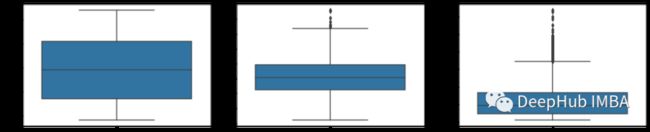
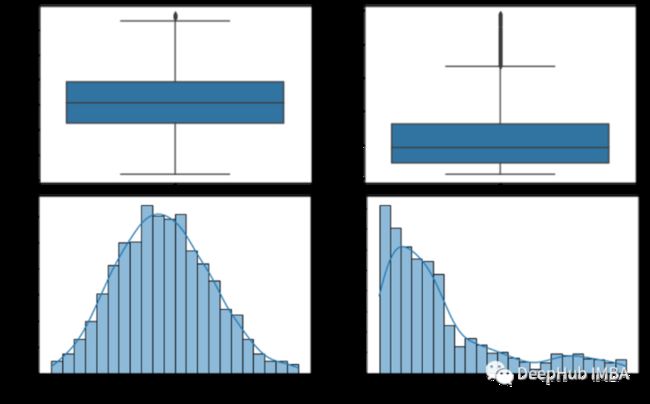
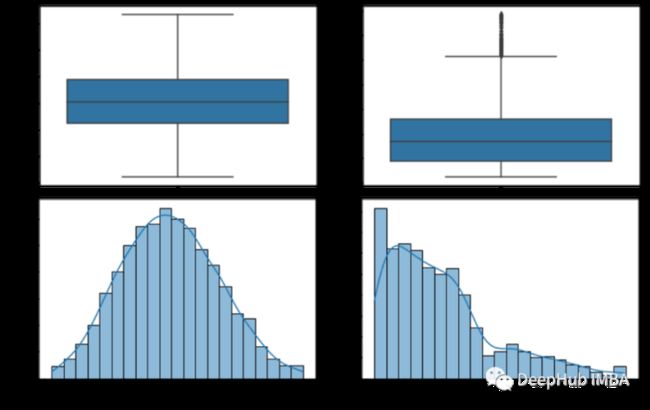
从箱线图我们可以看到age没有异常值bmi在上界有一些异常值,而expenses在上界有很多异常值,这表明了这是一个偏态分布。为了检查这个偏态分布的倾斜程度,我们将使用直方图。
sns.histplot(df, x="age", kde=True)
sns.histplot(df, x="bmi", kde=True)
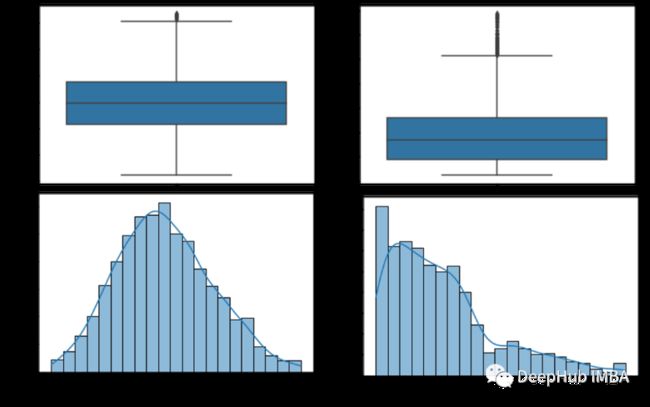
sns.histplot(df, x="expenses", kde=True)从直方图中可以看出,年龄变量均匀分布,bmi接近正态分布,expenses偏态分布。通过分析这两种图形表示,我们可以决定要排除那些数据。对于年龄不排除任何值。对于bmi我们将排除高于47的值,对于费用,我们将排除高于50000的值。
df.drop(df[df['bmi'] >= 47].index, inplace = True)
df.drop(df[df['expenses'] >= 50000].index, inplace = True)现在如果再次检查箱线图和直方图:
用统计方法检测异常值
有两种主要的统计方法可以检测异常值:使用z分数和使用四分位范围。
1、使用Z-score检测异常值
Z-score是一种数学变换,根据其与均值的距离对每个观察结果进行分类。与平均值之间的距离用标准差(SD)来衡量。如果得到的数值为1.59,我们就知道观察值比平均值高出1.59个标准差。同理如果得到-2.4的Z-score,我们就会知道观察值比平均值低-2.4个标准差。高于3SD或低于-3SD的观测值一般会被认为是异常值。
下面我们用代码实现,首先查看age:
df = pd.read_csv('insurance.csv')
mean_age = statistics.mean(df['age'])
stdev_age = statistics.stdev(df['age'])
age_z_score = (df['age']-mean_age)/stdev_age
df['age_z_score'] = age_z_score.tolist()现在查看是否有低于-3SD的值:
df.sort_values(by=['age_z_score'], ascending=True)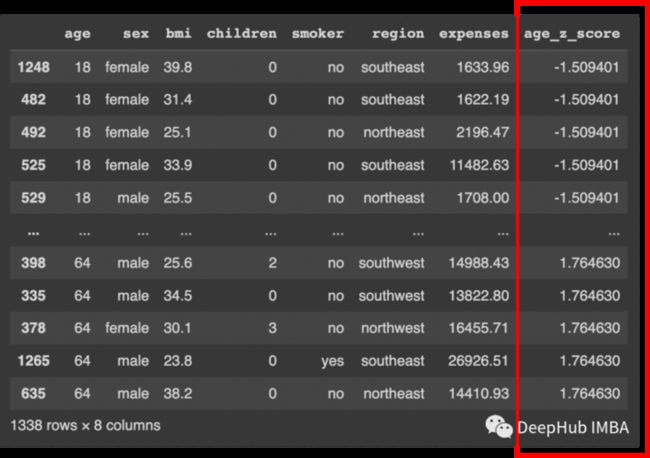
可以看到没有低于-3SD的值。现在检查3SD以上的值:
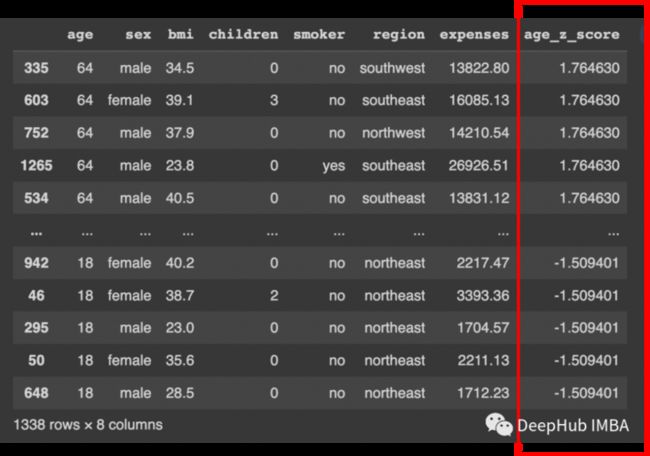
我们可以看到没有高于3SD的值。也就是说age没有异常值。现在对变量bmi做同样的操作:
mean_bmi = statistics.mean(df['bmi'])
stdev_bmi = statistics.stdev(df['bmi'])
bmi_z_score = (df['bmi']-mean_bmi)/stdev_bmi
df['bmi_z_score'] = bmi_z_score.tolist()
df.sort_values(by=['bmi_z_score'], ascending=True)
df.sort_values(by=['bmi_z_score'], ascending=False)查看3SD以上的值:
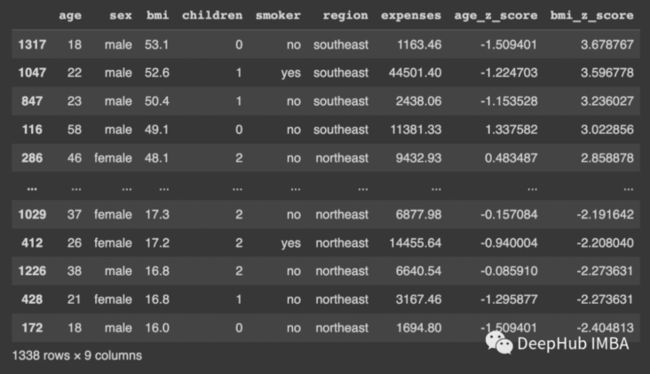
将这些值删除:
df.drop(df[df[‘bmi_z_score’] >= 3].index, inplace = True)下一步用同样的方法计算expenses:
mean_expenses = statistics.mean(df['expenses'])
stdev_expenses = statistics.stdev(df['expenses'])
expenses_z_score = (df['expenses']-mean_expenses)/stdev_expenses
df['expenses_z_score'] = expenses_z_score.tolist()
df.sort_values(by=['expenses_z_score'], ascending=True)
df.sort_values(by=['expenses_z_score'], ascending=False)
df.drop(df[df[‘expenses_z_score’] >= 3].index, inplace = True)删除了数据以后,我们再次可视化数据:
可以看到,一些值已经被移除了
2、使用四分位距检测异常值
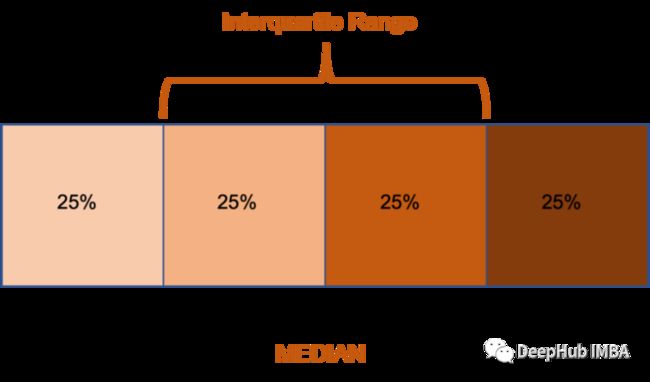
四分位距将数据分布到四个部分,并且从低到高排序,如下图所示,每个部分包含相同数量的样本。第一个四分位(Q1)是边界上的数据点的值。Q2和Q3也是如此。四分位距(IQR)是两个中间部分的数据点(代表50%的数据)。四分位距包含所有高于Q1低于Q3的数据点。如果该点高于Q3 + (1.5 x IQR),则表示包含较高数值离群值,如果Q1−(1.5 x IQR)则存在较低数值的离群值。
代码如下:
df = pd.read_csv('insurance.csv')
q75_age, q25_age = np.percentile(df['age'], [75 ,25])
iqr_age = q75_age - q25_age
iqr_age
age_h_bound = q75_age+(1.5*iqr_age)
age_l_bound = q25_age-(1.5*iqr_age)
print(age_h_bound)
print(age_l_bound)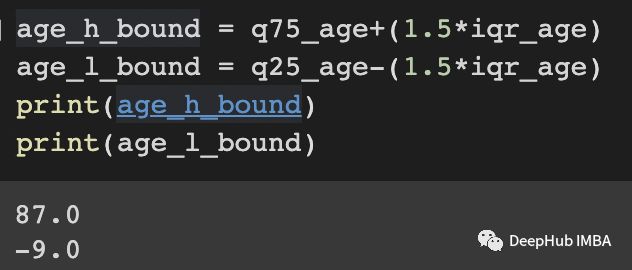
这样就知道了异常值位于87以上或-9以下:
df.sort_values(by=['age'], ascending=True)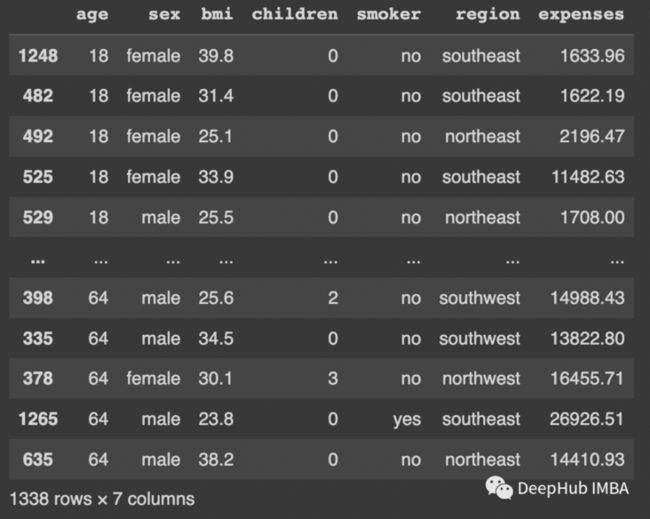
可以看到没有下异常值,现在我们将检查上异常值:
df.sort_values(by=['age'], ascending=False)也没有上异常值。
下面对bmi执行同样的操作:
q75_bmi, q25_bmi = np.percentile(df['bmi'], [75 ,25])
iqr_bmi = q75_bmi - q25_bmi
iqr_bmi
bmi_h_bound = q75_bmi+(1.5*iqr_bmi)
bmi_l_bound = q25_bmi-(1.5*iqr_bmi)
print(bmi_h_bound)
print(bmi_l_bound)
df.sort_values(by=['bmi'], ascending=True)
df.sort_values(by=['bmi'], ascending=False)
df.drop(df[df['bmi'] >= 47.3].index, inplace = True)
df.drop(df[df['bmi'] <= 13.7].index, inplace = True)expenses也是用相同的方法进行处理,我们对结果进行可视化:
可以看到异常值也被删除了
https://avoid.overfit.cn/post/c55c9a078cf44e33912c6f98affdd7c4
作者:Carla Martins