YOLOv5、v7改进之二十六:改进特征融合网络PANet为ASFF自适应特征融合网络
前 言:作为当前先进的深度学习目标检测算法YOLOv5、v7系列算法,已经集合了大量的trick,但是在处理一些复杂背景问题的时候,还是容易出现错漏检的问题。此后的系列文章,将重点对YOLO系列算法的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。
需要更多程序资料以及答疑欢迎大家关注——微信公众号:人工智能AI算法工程师
解决问题:原YOLOv5模型特征融合网络为PANet,虽然较FPN能更好的融合不同尺度目标的特征,从而提升效果,但是还存在改进的空间,还有更加先进的特征融合网络。之前出过改进为BIFPN加权双向特征金字塔有兴趣的朋友可以关注我看下之前的博客。现在介绍加入一种金字塔特征融合策略,称为adaptively spatial feature fusion (ASFF),它能够在空域过滤冲突信息以抑制不一致特征,提升网络对不同尺度目标的特征融合能力。
主要原理:
论文:Learning Spatial Fusion for Single-Shot Object Detectionarxiv.org/abs/1911.09516?context=cs.CV
ASFF用来解决一阶检测器中特征金字塔内部的不一致性。ASFF使网络能够直接学习如何在其他级别对特征进行空间滤波,从而仅保留有用的信息以进行组合。对于某个级别的特征,首先将其他级别的特征调整为相同的分辨率并简单集成,然后训练以找到最佳的融合方式。在每个空间位置,将不同级别的特征自适应地融合在一起,例如:若某位置携带矛盾的信息,则这些特征将会被滤除,若某位置的特征带有更多的区分性线索,则这些特征将会被增强。ASFF的几点好处:(1)由于搜索最优融合的操作是可微的,因此可以方便地利用bp算法学习;(2) 与基础网络无关,可以应用于所有具有特征金字塔结构的单阶检测器;(3) 实现简单,附加计算成本很小。ASFF方法通过学习不同特征图之间的联系来特征金字塔内部的不一致性问题。
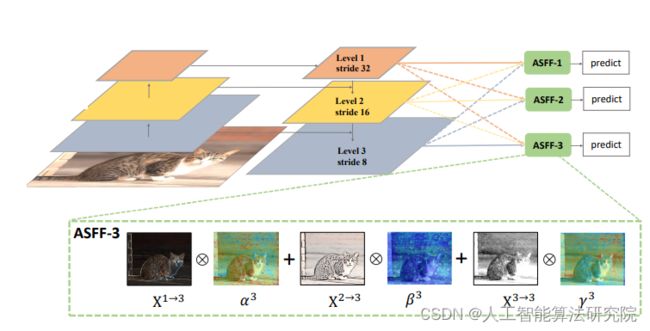
添加方法:
第一步:common.py构建ASFFV5模块。部分代码示例如下。
class ASFFV5(nn.Module):
def __init__(self, level, multiplier=1, rfb=False, vis=False, act_cfg=True):
"""
ASFF version for YoloV5 .
different than YoloV3
multiplier should be 1, 0.5
which means, the channel of ASFF can be
512, 256, 128 -> multiplier=1
256, 128, 64 -> multiplier=0.5
For even smaller, you need change code manually.
"""
super(ASFFV5, self).__init__()
self.level = level
self.dim = [int(1024*multiplier), int(512*multiplier),
int(256*multiplier)]
# print(self.dim)
self.inter_dim = self.dim[self.level]
if level == 0:
self.stride_level_1 = Conv(int(512*multiplier), self.inter_dim, 3, 2)
self.stride_level_2 = Conv(int(256*multiplier), self.inter_dim, 3, 2)
self.expand = Conv(self.inter_dim, int(
1024*multiplier), 3, 1)
elif level == 1:
self.compress_level_0 = Conv(
int(1024*multiplier), self.inter_dim, 1, 1)
self.stride_level_2 = Conv(
int(256*multiplier), self.inter_dim, 3, 2)
self.expand = Conv(self.inter_dim, int(512*multiplier), 3, 1)
elif level == 2:
self.compress_level_0 = Conv(
int(1024*multiplier), self.inter_dim, 1, 1)
self.compress_level_1 = Conv(
int(512*multiplier), self.inter_dim, 1, 1)
self.expand = Conv(self.inter_dim, int(
256*multiplier), 3, 1)
# when adding rfb, we use half number of channels to save memory
compress_c = 8 if rfb else 16
self.weight_level_0 = Conv(
self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = Conv(
self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = Conv(
self.inter_dim, compress_c, 1, 1)
self.weight_levels = Conv(
compress_c*3, 3, 1, 1)
self.vis = vis
def forward(self, x): #l,m,s
"""
# 128, 256, 512
512, 256, 128
from small -> large
"""
x_level_0=x[2] #l
x_level_1=x[1] #m
x_level_2=x[0] #s
# print('x_level_0: ', x_level_0.shape)
# print('x_level_1: ', x_level_1.shape)
# print('x_level_2: ', x_level_2.shape)
if self.level == 0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter = F.max_pool2d(
x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level == 1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized = F.interpolate(
level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized = x_level_1
level_2_resized = self.stride_level_2(x_level_2)
elif self.level == 2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized = F.interpolate(
level_0_compressed, scale_factor=4, mode='nearest')
x_level_1_compressed = self.compress_level_1(x_level_1)
level_1_resized = F.interpolate(
x_level_1_compressed, scale_factor=2, mode='nearest')
level_2_resized = x_level_2
# print('level: {}, l1_resized: {}, l2_resized: {}'.format(self.level,
# level_1_resized.shape, level_2_resized.shape))
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
# print('level_0_weight_v: ', level_0_weight_v.shape)
# print('level_1_weight_v: ', level_1_weight_v.shape)
# print('level_2_weight_v: ', level_2_weight_v.shape)第二步:yolo.py中注册ASFF模块。部分代码示例如下。
class ASFF_Detect(nn.Module): #add ASFFV5 layer and Rfb
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), multiplier=0.5,rfb=False,inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.l0_fusion = ASFFV5(level=0, multiplier=multiplier,rfb=rfb)
self.l1_fusion = ASFFV5(level=1, multiplier=multiplier,rfb=rfb)
self.l2_fusion = ASFFV5(level=2, multiplier=multiplier,rfb=rfb)
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
第三步:修改yaml文件,需要修改head(特征融合网络)。
[[17, 20, 23], 1, ASFF_Detect, [nc, anchors]], # Detect(P3, P4, P5) ]第四步:将train.py中改为本文的yaml文件即可,开始训练。
结 果:本人在多个数据集上做了大量实验,针对不同的数据集效果不同,需要大家进行实验。有效果有提升的情况占大多数。
预告一下:继续分享深度学习相关内容。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:系列改进算法不仅仅是可以添加进YOLOv5,也可以添加进任何其他的深度学习网络,不管是分类还是检测还是分割,主要是计算机视觉领域,都可能会有不同程度的提升效果。
最后,希望能互粉一下,做个朋友,一起学习交流。
需要更多程序资料以及答疑欢迎大家关注——微信公众号:人工智能AI算法工程师