Go语言学习之路(二)
Go语言学习之路(二)
- 面对对象编程思想
-
- 抽象
- 封装
- 继承
- 接口
- 文件
- 命令行参数
- Json
-
- 序列化
- 反序列化(unmarshal)
- 单元测试
- Redis
-
- Redis简介
- Redis基本使用
- Go连接redis
- Redis连接池
- Go面试题
- goroutine和channel (275-283)
-
- 协程 goroutine
- 管道 channel
- 协程配合管道的综合案例
- Go语言如何执行Linux命令
面对对象编程思想
抽象
- 抽象:定义一个结构体时候,实际上就是把一类事物的公有的属性(字段)或行为(方法)提取出来,形成一个物理模型(模板)。这种研究问题的方法称为抽象。

加 * 的意思是定义为指针类型,后面好对内存中真实的数据进行实际修改
go的交互 数据输入方式
https://blog.csdn.net/weixin_45794641/article/details/124645893
第一种:这个可以
var cmdString string
fmt.Scanf("%s", &cmdString)
fmt.Println(cmdString)
第二种:字节类型 这个不能用数字来
reader := bufio.NewReader(os.Stdin)
cmdString, err := reader.ReadString('\n')
cmdString = strings.TrimSuffix(cmdString, "\n")
// cmd := exec.Command(commandString)
// cmd.Stderr = os.Stderr
// cmd.Run()
封装
封装就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其他包只有通过被授权的操作(方法),才能对字段进行操作。
封装的理解和好处
(1)隐藏实现细节
(2)可以对数据进行验证,保证安全合理
如何体现封装
(1)对结构体中的属性进行封装
(2)通过方法,包 实现封装
小写的变量作为struct则只能本包实现
封装的实现步骤
1)将 结构体、字段(属性)的首字母小写 (不能导出,其它包不能使用,类似private)
2)给结构体所在包提供一个工厂模式的函数,首字母大写。类似一个构造函数
3)提供一个首字母大写的Set方法(类似其它语言的public),用于对属性判断并赋值
func(var结构体类型名)SetXxox(参数列表)(返回值列表){
//加入数据验证的业务逻辑
var.字段=参数
}
4)提供一个首字母大写的Get方法(类似其它语言的public),用于获取属性的值
func(var结构体类型名)Getxxx){
return var.字段;
}
模板:
person.go
package model
import "fmt"
type person struct {
Name string
age int //小写其它包不能直接访问..
sal float64
}
//写一个工厂模式的函数,相当于构造函数
//func 函数名(参数列表) (返回值列表) {
func NewPerson(name string) *person {
return &person{
Name : name,
}
}
//为了访问age 和 sal 我们编写一对SetXxx的方法和GetXxx的方法
func (p *person) SetAge(age int) {
if age >0 && age <150 {
p.age = age
} else {
fmt.Println("年龄范围不正确..")
//给程序员给一个默认值
}
}
// 这里的int表示返回值类型,()表示不传参
// func (参数列表) Get方法名(传参) 返回值类型 {}
func (p *person) GetAge() int {
return p.age
}
func (p *person) SetSal(sal float64) {
if sal >= 3000 && sal <= 30000 {
p.sal = sal
} else {
fmt.Println("薪水范围不正确..")
}
}
func (p *person) GetSal() float64 {
return p.sal
}
main.go
package main
import (
"fmt"
"go_code/chapter11/encapsulate/model"
)
func main() {
p := model.NewPerson("smith")
p.SetAge(18)
p.SetSal(5000)
fmt.Println(p)
fmt.Println(p.Name, " age =", p.GetAge(), " sal = ", p.GetSal())
}
main.go
package main
import (
"fmt"
"go_code/chapter11/encapexercise/model"
)
func main() {
//创建一个account变量
account := model.NewAccount("jzh11111", "000", 40)
if account != nil {
fmt.Println("创建成功=", account)
} else {
fmt.Println("创建失败")
}
}
account.go
package model
import (
"fmt"
)
//定义一个结构体account
type account struct {
accountNo string
pwd string
balance float64
}
//工厂模式的函数-构造函数
func NewAccount(accountNo string, pwd string, balance float64) *account {
if len(accountNo) < 6 || len(accountNo) > 10 {
fmt.Println("账号的长度不对...")
return nil
}
if len(pwd) != 6 {
fmt.Println("密码的长度不对...")
return nil
}
if balance < 20 {
fmt.Println("余额数目不对...")
return nil
}
return &account{
accountNo : accountNo,
pwd : pwd,
balance : balance,
}
}
//方法
//1. 存款
func (account *account) Deposite(money float64, pwd string) {
//看下输入的密码是否正确
if pwd != account.pwd {
fmt.Println("你输入的密码不正确")
return
}
//看看存款金额是否正确
if money <= 0 {
fmt.Println("你输入的金额不正确")
return
}
account.balance += money
fmt.Println("存款成功~~")
}
//取款
func (account *account) WithDraw(money float64, pwd string) {
//看下输入的密码是否正确
if pwd != account.pwd {
fmt.Println("你输入的密码不正确")
return
}
//看看取款金额是否正确
if money <= 0 || money > account.balance {
fmt.Println("你输入的金额不正确")
return
}
account.balance -= money
fmt.Println("取款成功~~")
}
//查询余额
func (account *account) Query(pwd string) {
//看下输入的密码是否正确
if pwd != account.pwd {
fmt.Println("你输入的密码不正确")
return
}
fmt.Printf("你的账号为=%v 余额=%v \n", account.accountNo, account.balance)
}
继承
go是没有继承的,但面对相同的代码,如何避免代码冗余? (匿名结构体)
- 当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体(比如Student),在该结构体中定义这些相同的属性和方法。
- 通过一个struct嵌套另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承的特性
嵌套匿名结构体的基本语法
type Goods struct {
Name string
Price int
}
type Book struct {
Goods // 这里就是嵌套匿名结构体Goods
Writer string
}
匿名结构体
package main
import (
"fmt"
)
//编写一个学生考试系统
type Student struct {
Name string
Age int
Score int
}
//将Pupil 和 Graduate 共有的方法也绑定到 *Student
func (stu *Student) ShowInfo() {
fmt.Printf("学生名=%v 年龄=%v 成绩=%v\n", stu.Name, stu.Age, stu.Score)
}
func (stu *Student) SetScore(score int) {
//业务判断
stu.Score = score
}
//给 *Student 增加一个方法,那么 Pupil 和 Graduate都可以使用该方法
func (stu *Student) GetSum(n1 int, n2 int) int {
return n1 + n2
}
//小学生
type Pupil struct {
Student //嵌入了Student匿名结构体
}
//这时Pupil结构体特有的方法,保留
func (p *Pupil) testing() {
fmt.Println("小学生正在考试中.....")
}
//大学生
type Graduate struct {
Student //嵌入了Student匿名结构体
}
//这时Graduate结构体特有的方法,保留
func (p *Graduate) testing() {
fmt.Println("大学生正在考试中.....")
}
//代码冗余.. 高中生....
func main() {
//当我们对结构体嵌入了匿名结构体使用方法会发生变化
pupil := &Pupil{}
pupil.Student.Name = "tom~"
pupil.Student.Age = 8
pupil.testing()
pupil.Student.SetScore(70)
pupil.Student.ShowInfo()
fmt.Println("res=", pupil.Student.GetSum(1, 2))
// 匿名结构体 简写写法,编译器会自己去找本地的,如果不存在就去嵌入的匿名结构体
graduate := &Graduate{}
graduate.Name = "mary~"
graduate.Age = 28
graduate.testing()
graduate.SetScore(90)
graduate.ShowInfo()
fmt.Println("res=", graduate.GetSum(10, 20))
}
-
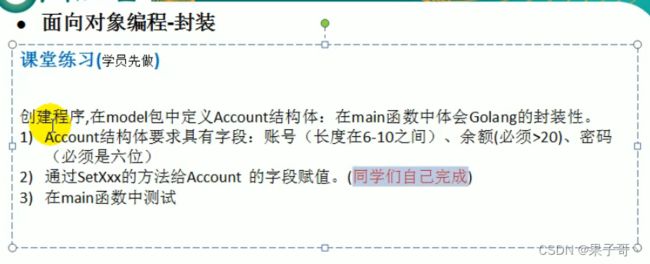
当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近访问原则访问,如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分。 先查自己有没有,逐级的查,查到了距离自己最近的,就屏蔽其他的
-
结构体嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时就必须明确指定匿名结构体名字,否则编译报错
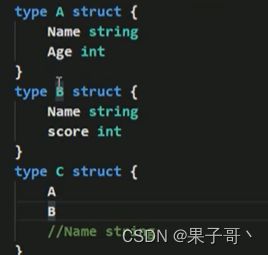
-
有名结构体,必须指定才能调用,如果D中是一个有名结构体,则访问有名结构体的字段时,就必须带上有名结构体的名字,
d.a.Name
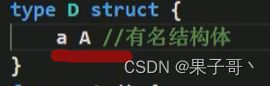
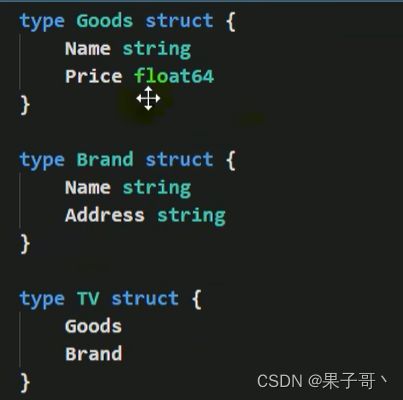
-
嵌套多个匿名结构体(多重继承,尽量不使用),直接指定各个匿名结构体字段的值

接口
文件
1、文件的基本介绍:
文件在程序中以流的形式来操作的。
文件——》(输入流)——》Go程序(内存)
流:数据在数据源(文件)和程序(内存)之间经历的路径
输入流(读文件):数据从数据源(文件)到程序(内存)的路径
输出流(写文件):数据从程序(内存)到数据源(文件)的路径
os.File封装所有文件相关操作,File是一个结构体
type File struct {
// 内含隐藏或非导出字段
}
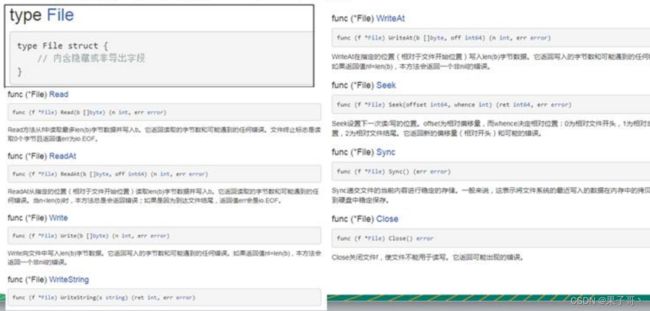
https://studygolang.com/static/pkgdoc/pkg/os.htm#File

2、打开文件和关闭文件
- 打开一个文件进行读和写操作:
func Open(name string) (file *File, err error)
Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。如果出错,错误底层类型是*PathError。
func (f *File) Close() error
Close关闭文件f,使文件不能用于读写。它返回可能出现的错误。
package main
import (
"fmt"
"os"
)
func main() {
//打开文件
//概念说明: file 的叫法,三个叫法都是一个意思
//1. file 叫 file对象
//2. file 叫 file指针
//3. file 叫 file 文件句柄
file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//输出下文件,看看文件是什么, 看出file 就是一个指针 *File
fmt.Printf("file=%v", file)
//关闭文件
err = file.Close()
if err != nil {
fmt.Println("close file err=", err)
}
}
3、读文件:读取文件的内容并显示在终端(带缓冲区的方式 bufio.NewReader)
使用os.Open,file.Close,bufio.NewReader(),reader.ReadString函数和方法
package main
import (
"fmt"
"os"
"bufio"
"io"
)
func main() {
//打开文件
//概念说明: file 的叫法
//1. file 叫 file对象
//2. file 叫 file指针
//3. file 叫 file 文件句柄
file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//defer 当函数退出时,要及时的关闭file
defer file.Close() //要及时关闭file句柄,否则会有内存泄漏.
// 创建一个 *Reader ,是带缓冲的
/*
const (
defaultBufSize = 4096 //默认的缓冲区为4096
)
*/
reader := bufio.NewReader(file)
//循环的读取文件的内容
for {
str, err := reader.ReadString('\n') // 每读到一个换行符就结束
if err == io.EOF { // io.EOF表示文件的末尾
//如果文件读到最后一行readstring就会返回一个io.Eof
break
}
//输出内容
fmt.Printf(str)
}
fmt.Println("文件读取结束...")
}
defer:处理业务或逻辑中涉及成对的操作是一件比较烦琐的事情,比如打开和关闭文件、接收请求和回复请求、加锁和解锁等。在这些操作中,最容易忽略的就是在每个函数退出处正确地释放和关闭资源。
defer 语句正好是在函数退出时执行的语句,所以使用 defer 能非常方便地处理资源释放问题。
4、读文件:读取文件的内容并显示在终端(使用ioutil一次将整个文件读入到内存中)
这种方式适用于文件不大的情况。
func ReadFile(filename string) ([]byte, error)
ReadFile 从filename指定的文件中读取数据并返回文件的内容。成功的调用返回的err为nil而非EOF。因为本函数定义为读取整个文件,它不会将读取返回的EOF视为应报告的错误。
package main
import (
"fmt"
"io/ioutil"
)
func main() {
//使用ioutil.ReadFile一次性将文件读取到位
file := "d:/test.txt"
content, err := ioutil.ReadFile(file)
if err != nil {
fmt.Printf("read file err=%v", err)
}
//把读取到的内容显示到终端
//fmt.Printf("%v", content) // []byte
fmt.Printf("%v", string(content)) // []byte
//我们没有显式的Open文件,因此也不需要显式的Close文件
//因为,文件的Open和Close被封装到 ReadFile 函数内部
}
5、写文件:基本应用实例(一)
func OpenFile(name string, flag int, perm FileMode) (file *File, err error)
OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。
第二个参数:
const (
O_RDONLY int = syscall.O_RDONLY // 只读模式打开文件
O_WRONLY int = syscall.O_WRONLY // 只写模式打开文件
O_RDWR int = syscall.O_RDWR // 读写模式打开文件
O_APPEND int = syscall.O_APPEND // 写操作时将数据附加到文件尾部
O_CREATE int = syscall.O_CREAT // 如果不存在将创建一个新文件
O_EXCL int = syscall.O_EXCL // 和O_CREATE配合使用,文件必须不存在
O_SYNC int = syscall.O_SYNC // 打开文件用于同步I/O
O_TRUNC int = syscall.O_TRUNC // 如果可能,打开时清空文件
)
第三个参数是权限777控制
应用实例:
1)创建一个新文件,写入内容5句"hello,Gardon"
os.O_WRONLY | os.O_CREATE
2)打开一个存在的文件中,将原来的内容覆盖成新的内容10句“你好,尚硅谷!"
os.O_WRONLY | os.O_TRUNC
3)打开一个存在的文件,在原来的内容追加内容’ABC!ENGLISH!!"
os.O_WRONLY | os.O_APPEND
4)打开一个存在的文件,将原来的内容读出显示在终端,并且追加5句“hello,北京!"
os.O_RDWR | os.O_APPEND
使用os.OpenFile(),bufio.NewWriter(),*Writer的WriterString
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
//创建一个新文件,写入内容 5句 "hello, Gardon"
//1 .打开文件 d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
//准备写入5句 "hello, Gardon"
str := "hello,Gardon\r\n" // \r\n 表示换行
//写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
//因为writer是带缓存,因此在调用WriterString方法时,其实
//内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据
//真正写入到文件中, 否则文件中会没有数据!!!
writer.Flush()
}
6、写文件:基本应用实例(二)
编程一个程序,将一个文件的内容,写入到另外一个文件。注:这两个文件已经存在了.
说明:使用ioutil.ReadFile/ioutil.WriteFile完成写文件的任务.
代码实现:
package main
import (
"fmt"
"io/ioutil"
)
func main() {
//将d:/abc.txt 文件内容导入到 e:/kkk.txt
//1. 首先将 d:/abc.txt 内容读取到内存
//2. 将读取到的内容写入 e:/kkk.txt
file1Path := "d:/abc.txt"
file2Path := "e:/kkk.txt"
data, err := ioutil.ReadFile(file1Path)
if err != nil {
//说明读取文件有错误
fmt.Printf("read file err=%v\n", err)
return
}
err = ioutil.WriteFile(file2Path, data, 0666)
if err != nil {
fmt.Printf("write file error=%v\n", err)
}
}
7、写文件:基本应用实例(三)拷贝文件
package main
import (
"fmt"
"os"
"io"
"bufio"
)
//自己编写一个函数,接收两个文件路径 srcFileName dstFileName
func CopyFile(dstFileName string, srcFileName string) (written int64, err error) {
srcFile, err := os.Open(srcFileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
}
defer srcFile.Close()
//通过srcfile ,获取到 Reader
reader := bufio.NewReader(srcFile)
//打开dstFileName
dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//通过dstFile, 获取到 Writer
writer := bufio.NewWriter(dstFile)
defer dstFile.Close()
return io.Copy(writer, reader)
}
func main() {
//将d:/flower.jpg 文件拷贝到 e:/abc.jpg
//调用CopyFile 完成文件拷贝
srcFile := "d:/flower.jpg"
dstFile := "e:/abc.jpg"
_, err := CopyFile(dstFile, srcFile)
if err == nil {
fmt.Printf("拷贝完成\n")
} else {
fmt.Printf("拷贝错误 err=%v\n", err)
}
}
8、写文件:基本应用实例(四)统计文件字符
统计英文、数字、弄个和其他字符数量
package main
import (
"fmt"
"os"
"io"
"bufio"
)
//定义一个结构体,用于保存统计结果
type CharCount struct {
ChCount int // 记录英文个数
NumCount int // 记录数字的个数
SpaceCount int // 记录空格的个数
OtherCount int // 记录其它字符的个数
}
func main() {
//思路: 打开一个文件, 创一个Reader
//每读取一行,就去统计该行有多少个 英文、数字、空格和其他字符
//然后将结果保存到一个结构体
fileName := "e:/abc.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close()
//定义个CharCount 实例
var count CharCount
//创建一个Reader
reader := bufio.NewReader(file)
//开始循环的读取fileName的内容
for {
str, err := reader.ReadString('\n')
if err == io.EOF { //读到文件末尾就退出
break
}
//遍历 str ,进行统计
for _, v := range str {
switch {
case v >= 'a' && v <= 'z':
fallthrough //穿透
case v >= 'A' && v <= 'Z':
count.ChCount++
case v == ' ' || v == '\t':
count.SpaceCount++
case v >= '0' && v <= '9':
count.NumCount++
default :
count.OtherCount++
}
}
}
//输出统计的结果看看是否正确
fmt.Printf("字符的个数为=%v 数字的个数为=%v 空格的个数为=%v 其它字符个数=%v",
count.ChCount, count.NumCount, count.SpaceCount, count.OtherCount)
}
判断文件是否存在,os.stat,如果返回的错误为nil,说明文件或文件夹存在
func Stat(name string) (fi FileInfo, err error)
命令行参数
(1)需求:获取到命令行输入的各种参数 (按顺序)
os.Args是一个string的切片,用来存储所有的命令行参数
package main
import (
"fmt"
"os"
)
func main() {
fmt.Println("命令行的参数有", len(os.Args))
//遍历os.Args切片,就可以得到所有的命令行输入参数值
for i, v := range os.Args {
fmt.Printf("args[%v]=%v\n", i, v)
}
}
(2)flag包解析命令行参数(参数顺序不限制)
Name string // flag在命令行中的名字
Usage string // 帮助信息
Value Value // 要设置的值
DefValue string // 用于使用信息
go build -o test.exe main.go

package main
import (
"fmt"
"flag"
)
func main() {
//定义几个变量,用于接收命令行的参数值
var user string
var pwd string
var host string
var port int
//&user 就是接收用户命令行中输入的 -u 后面的参数值
//"u" ,就是 -u 指定参数
//"" , 默认值
//"用户名,默认为空" 说明
flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为localhost")
flag.IntVar(&port, "port", 3306, "端口号,默认为3306")
//这里有一个非常重要的操作,转换, 必须调用该方法
flag.Parse()
//输出结果
fmt.Printf("user=%v pwd=%v host=%v port=%v",
user, pwd, host, port)
}
Json
JSON易于机器解析和生成,并有效地提升网络传输效率,通常程序在网络传输时会先将数据(结构体、map等) 序列化成json字符串,到接收方得到json字符串时,在反序列化恢复成原来的数据类型(结构体、map等)。这种方式已然成为各个语言的标准。
Json站点:https://www.json.cn/

序列化
结构体、map和切片的序列化
反射机制
需求:按照自己想要的格式,跨包首字母小写的字段不能通过直接通过json包序列化
type Monster struct {
Name string `json:"monster_name"`
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string `json:"monster_name"` //反射机制,通过tag
Age int `json:"monster_age"`
Birthday string //....
Sal float64
Skill string
}
func testStruct() {
//演示
monster := Monster{
Name :"牛魔王",
Age : 500 ,
Birthday : "2011-11-11",
Sal : 8000.0,
Skill : "牛魔拳",
}
//将monster 序列化
data, err := json.Marshal(&monster) //..
if err != nil {
fmt.Printf("序列号错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("monster序列化后=%v\n", string(data))
//不加string看到的是byte的切片
}
//将map进行序列化
func testMap() {
//定义一个map,key是字符串string
var a map[string]interface{}
//使用map,需要make
// 简写成 这样 : a := map[string]interface{}{} 就是直接实例化, 不用make了
a = make(map[string]interface{})
a["name"] = "红孩儿"
a["age"] = 30
a["address"] = "洪崖洞"
//将a这个map进行序列化
//将monster 序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("a map 序列化后=%v\n", string(data))
}
//演示对切片进行序列化, 我们这个切片 []map[string]interface{}
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
//使用map前,需要先make
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = "7"
m1["address"] = "北京"
slice = append(slice, m1)
var m2 map[string]interface{}
//使用map前,需要先make
m2 = make(map[string]interface{})
m2["name"] = "tom"
m2["age"] = "20"
m2["address"] = [2]string{"墨西哥","夏威夷"}
slice = append(slice, m2)
//将切片进行序列化操作
data, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("slice 序列化后=%v\n", string(data))
}
//对基本数据类型序列化,对基本数据类型进行序列化意义不大
func testFloat64() {
var num1 float64 = 2345.67
//对num1进行序列化
data, err := json.Marshal(num1)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("num1 序列化后=%v\n", string(data))
}
func main() {
//演示将结构体, map , 切片进行序列号
testStruct()
testMap()
testSlice()//演示对切片的序列化
testFloat64()//演示对基本数据类型的序列化
}
反序列化(unmarshal)
(1)需要保持数据类型严格的一致
(2)如果json字符串是通过程序获取到的,则不需要再转移处理\
slice:
var slice1 []type = make([]type, len)
var slice []map[string]interface{}
也可以简写为
slice1 := make([]type, len)
s1 := make([]int, 3, 6)
map:
/* 声明变量,默认 map 是 nil /
var map_variable map[key_data_type]value_data_type
/ 使用 make 函数 */
map_variable := make(map[key_data_type]value_data_type)
//定义一个map
var a map[string]interface{}
//使用map,需要make
a = make(map[string]interface{})
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string
Age int
Birthday string //....
Sal float64
Skill string
}
//演示将json字符串,反序列化成struct
func unmarshalStruct() {
//说明str 在项目开发中,是通过网络传输获取到.. 或者是读取文件获取到
str := "{\"Name\":\"牛魔王~~~\",\"Age\":500,\"Birthday\":\"2011-11-11\",\"Sal\":8000,\"Skill\":\"牛魔拳\"}"
//定义一个Monster实例
var monster Monster
// 字符串变成字节,引入传进才能改变真正的值
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 monster=%v monster.Name=%v \n", monster, monster.Name)
}
//将map进行序列化
func testMap() string {
//定义一个map
var a map[string]interface{}
//使用map,需要make
a = make(map[string]interface{})
a["name"] = "红孩儿~~~~~~"
a["age"] = 30
a["address"] = "洪崖洞"
//将a这个map进行序列化
//将monster 序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
//fmt.Printf("a map 序列化后=%v\n", string(data))
return string(data)
}
//演示将json字符串,反序列化成map
func unmarshalMap() {
//str := "{\"address\":\"洪崖洞\",\"age\":30,\"name\":\"红孩儿\"}"
str := testMap()
//定义一个map
var a map[string]interface{}
//反序列化
//注意:反序列化map,不需要make,因为make操作被封装到 Unmarshal函数
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 a=%v\n", a)
}
//演示将json字符串,反序列化成切片
func unmarshalSlice() {
str := "[{\"address\":\"北京\",\"age\":\"7\",\"name\":\"jack\"}," +
"{\"address\":[\"墨西哥\",\"夏威夷\"],\"age\":\"20\",\"name\":\"tom\"}]"
//定义一个slice
var slice []map[string]interface{}
//反序列化,不需要make,因为make操作被封装到 Unmarshal函数
err := json.Unmarshal([]byte(str), &slice)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 slice=%v\n", slice)
}
func main() {
unmarshalStruct()
unmarshalMap()
unmarshalSlice()
}
单元测试
Go语言中自带有一个轻量级的测试框架testing和自带的go test命令来实现单元测试和性能测试(运行的时间),testing框架和其他语言中的测试框架类似,可以基于这个框架写针对相应函数的测试用例,也可以基于该框架写相应的压力测试用例。通过单元测试,可以解决如下问题:
1)确保每个函数是可运行,并且运行结果是正确的
2)确保写出来的代码性能是好的,
3)单元测试能及时的发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
- 测试单个文件,一定要带上被测试的原文件
go test -v cal_test.go cal.go - 测试单个方法
go test -v test.run TestAddUpper
testing 提供对 Go 包的自动化测试的支持。通过 go test 命令,能够自动执行如下形式的任何函数:
func TestXxx(*testing.T)
其中 Xxx 可以是任何字母数字字符串(但第一个字母不能是 [a-z]),用于识别测试程序。
如何进行单元测试?

package cal
//一个被测试函数
func addUpper(n int) int {
res := 0
for i := 1; i <= n - 1; i++ {
res += i
}
return res
}
cal_test.go
package cal
import (
"fmt"
"testing" //引入go 的testing框架包
)
//编写要给测试用例,去测试addUpper是否正确
func TestAddUpper(t *testing.T) {
//调用
res := addUpper(10)
if res != 55 {
//fmt.Printf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n", 55, res)
t.Fatalf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n", 55, res)
}
//如果正确,输出日志
t.Logf("AddUpper(10) 执行正确...")
}
func TestHello(t *testing.T) {
fmt.Println("TestHello被调用..")
}
--- FAIL: TestAddUpper (0.00s)
cal_test.go:14: AddUpper(10) 执行错误,期望值=55 实际值=45
TestHello被调用..
FAIL
Redis
Redis简介
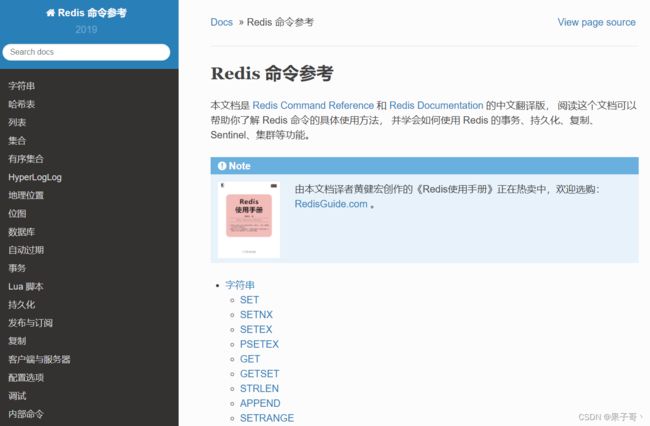
Redis是NoSQL数据库,不是传统的关系型数据库,是高性能的分布式内存数据库,单机能够达到15w qps,通常适合做缓存,也可以持久化,基于内存运行并支持持久化的NoSQL数据库。

Redis的命令一览:http://redisdoc.com
Redis基本使用
说明:Redis安装好后,默认有16个数据库,初始默认使用0号库,编号是0…15
- 添加key-val [set]
set key1 hello - 查看当前redis的所有key [keys *]
- 获取key对应的值 [get key]
- 切换redis数据库 [select index]
- 如何查看当前数据库的key-val数量 [dbsize]
- 清空当前数据库的key-val和清空所有数据库的key-val [flushdb flushall]
字符串String(除普通的字符串外,还可以存放图片等数据):del、get、setex(set with expire)、mset(同时设置一个或多个key-value对)、mget(同时获取多个key-val)
redis中字符串value最大512M
哈希Hash(适合存储对象):hset、hget、hgetall、hlan、hexists

List列表(lpush、rpush、lrange、lpop、rpop、del)
列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
List本质是个链表,List的元素是有序的,元素的值可以重复.


Set集合(sadd、smembers(取出所有值)、sismember(判断值是否是成员),srem(删除指定值))
Redis的Set是string类型的无序集合。底层是HashTable数据结构,Set也是存放很多字符串元素,字符串元素是无序的,而且元素的值不能重复

Go连接redis
- String类型
package main
import (
"fmt"
"github.com/garyburd/redigo/redis" //引入redis包
)
func main() {
//通过go 向redis 写入数据和读取数据
//1. 链接到redis
conn, err := redis.Dial("tcp", "127.0.0.1:6379")
if err != nil {
fmt.Println("redis.Dial err=", err)
return
}
defer conn.Close() //关闭..
//2. 通过go 向redis写入数据 string [key-val]
_, err = conn.Do("Set", "name", "tomjerry猫猫")
if err != nil {
fmt.Println("set err=", err)
return
}
//3. 通过go 向redis读取数据 string [key-val]
r, err := redis.String(conn.Do("Get", "name"))
if err != nil {
fmt.Println("set err=", err)
return
}
//因为返回 r是 interface{}
//因为 name 对应的值是string ,因此我们需要转换
//nameString := r.(string)
fmt.Println("操作ok ", r)
}
- hash类型
package main
import (
"fmt"
"github.com/garyburd/redigo/redis" //引入redis包
)
func main() {
//通过go 向redis 写入数据和读取数据
//1. 链接到redis
conn, err := redis.Dial("tcp", "127.0.0.1:6379")
if err != nil {
fmt.Println("redis.Dial err=", err)
return
}
defer conn.Close() //关闭..
//2. 通过go 向redis写入数据 string [key-val]
_, err = conn.Do("HSet", "user01", "name", "john")
if err != nil {
fmt.Println("hset err=", err)
return
}
_, err = conn.Do("HSet", "user01", "age", 18)
if err != nil {
fmt.Println("hset err=", err)
return
}
//3. 通过go 向redis读取数据
r1, err := redis.String(conn.Do("HGet","user01", "name"))
if err != nil {
fmt.Println("hget err=", err)
return
}
r2, err := redis.Int(conn.Do("HGet","user01", "age"))
if err != nil {
fmt.Println("hget err=", err)
return
}
//因为返回 r是 interface{}
//因为 name 对应的值是string ,因此我们需要转换
//nameString := r.(string)
fmt.Printf("操作ok r1=%v r2=%v \n", r1, r2)
}
HM set
package main
import (
"fmt"
"github.com/garyburd/redigo/redis" //引入redis包
)
func main() {
//通过go 向redis 写入数据和读取数据
//1. 链接到redis
conn, err := redis.Dial("tcp", "127.0.0.1:6379")
if err != nil {
fmt.Println("redis.Dial err=", err)
return
}
defer conn.Close() //关闭..
//2. 通过go 向redis写入数据 string [key-val]
_, err = conn.Do("HMSet", "user02", "name", "john", "age", 19)
if err != nil {
fmt.Println("HMSet err=", err)
return
}
//3. 通过go 向redis读取数据 ,redis.Strings,redis.Int
r, err := redis.Strings(conn.Do("HMGet","user02", "name", "age"))
if err != nil {
fmt.Println("hget err=", err)
return
}
for i, v := range r {
fmt.Printf("r[%d]=%s\n", i, v)
}
}
Redis连接池
说明:通过Golang对Redis操作,还可以通过Redis链接池,流程如下:
1)事先初始化一定数量的链接,放入到链接池
2)当Go 需要操作Redis时,直接从Redis 链接池取出链接即可。
3)这样可以节省临时获取Redis链接的时间,从而提高效率。
4)示意图
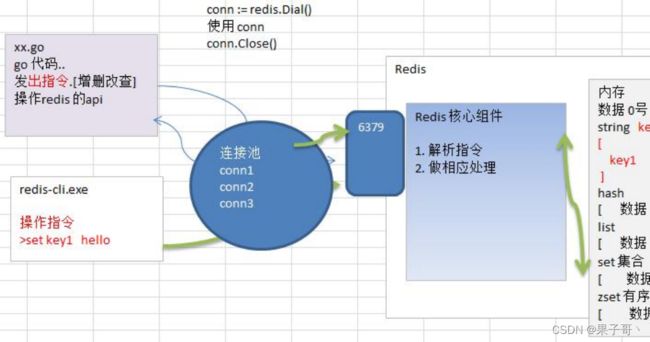
init函数 每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go运行框架调用,也就是说init会 在main函数前被调用
package main
import (
"fmt"
"github.com/garyburd/redigo/redis"
)
//定义一个全局的pool
var pool *redis.Pool
//当启动程序时,就初始化连接池
func init() {
pool = &redis.Pool{
MaxIdle: 8, //最大空闲链接数
MaxActive: 0, // 表示和数据库的最大链接数, 0 表示没有限制
IdleTimeout: 100, // 最大空闲时间
Dial: func() (redis.Conn, error) { // 初始化链接的代码, 链接哪个ip的redis
return redis.Dial("tcp", "localhost:6379")
},
}
}
func main() {
//先从pool 取出一个链接
conn := pool.Get() //从连接池中取出一个链接
defer conn.Close() //关闭连接池,一旦关闭链接池,就不能从链接池再取出链接
_, err := conn.Do("Set", "name", "汤姆猫~~")
if err != nil {
fmt.Println("conn.Do err=", err)
return
}
//取出
r, err := redis.String(conn.Do("Get", "name"))
if err != nil {
fmt.Println("conn.Do err=", err)
return
}
fmt.Println("r=", r)
//如果我们要从pool 取出链接,一定保证链接池是没有关闭
//pool.Close()
conn2 := pool.Get()
_, err = conn2.Do("Set", "name2", "汤姆猫~~2")
if err != nil {
fmt.Println("conn.Do err~~~~=", err)
return
}
//取出
r2, err := redis.String(conn2.Do("Get", "name2"))
if err != nil {
fmt.Println("conn.Do err=", err)
return
}
fmt.Println("r=", r2)
//fmt.Println("conn2=", conn2)
}
Go面试题
https://docs.qq.com/sheet/DQkRORVFKc2dTeXlB?_t=1662387680196&tab=BB08J2
goroutine和channel (275-283)
协程 goroutine
需求:要求统计1-20000的数字中,哪些是素数?
分析思路:
1)传统的方法,就是使用一个循环,循环的判断各个数是不是素数。
2)使用并发或者并行的方式,将统计素数的任务分配给多个goroutine去完成,这时就会使用到goroutine。
进程和线程说明
1)进程就是程序程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
2)线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位。
3)一个进程可以创建核销毁多个线程,同一个进程中的多个线程可以并发执行。
4)一个程序至少有一个进程,一个进程至少有一个线程
并发和并行
1)多线程程序在单核上运行,就是并发
2)多线程程序在多核上运行,就是并行
- 并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10个线程都在运行,但是从微观上看,在某一个时间点看,其实只有一个线程在执行,这就是并发。
- 并行:因为是在多个cpu上(比如有10个cpu),比如有10个线程,每个线程执行10毫秒(各自在不同cpu上执行),从人的角度看,这10个线程都在运行,但是从微观上看,在某一个时间点看,也同时有10个线程在执行,这就是并行
go协程和Go主线程
1)Go主线程(有程序员直接称为线程/也可以理解成进程):一个Go线程上,可以起多个协程,你可以这样理解,协程是轻量级的线程。
2)Go协程的特点
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程的线程-协程
案例说明
1)在主线程(可以理解成进程)中,开启一个goroutine,该协程每隔1秒输出“hello,world”
2)在主线程中也每隔一秒输出“hello,golang”,输出10次后,退出程序
3)要求主线程和goroutine同时执行
4)画出主线程和协程执行流程图
package main
import (
"fmt"
"strconv"
"time"
)
func test() {
for i:=1;i<=10; i++ {
fmt.Println("test () hello,world " + strconv.Itoa(1))
time.Sleep(time.Second)
}
}
func main() {
// test() 没开启协程
go test() // 开启协程
for i:=1;i<=10; i++ {
fmt.Println("main () hello,world " + strconv.Itoa(1))
time.Sleep(time.Second)
}
}
goroutine快速入门
1)主线程是一个物理线程,直接作用在cpu上的。是重量级的,非常耗费CPU资源。
2)协程是从主线程开启的,是轻量级的线程,是逻辑态,对资源消耗相对较小。
3)Golang协程机制是可以轻松开启上万个协程
goroutine的调度模型(MPG模式介绍)
- M:操作系统的主线程(是物理线程),真正干活的人(可以在一个CPU也可以在多个CPU)
- P:协程执行需要的上下文(理解为运行所需要的数据),可以把它看作一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。
- G:协程,代表一个goroutine,它有自己的栈

返回本地机器的逻辑CPU个数
package main
import (
"runtime"
"fmt"
)
func main() {
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
//可以自己设置使用多个CPU
runtime.GOMAXPROCS(cpuNum - 1)
fmt.Println("ok")
}
协程资源竞争问题
通过race参数可以知道是否有资源竞争问题
go build -race test.go
全局互斥锁解决资源竞争
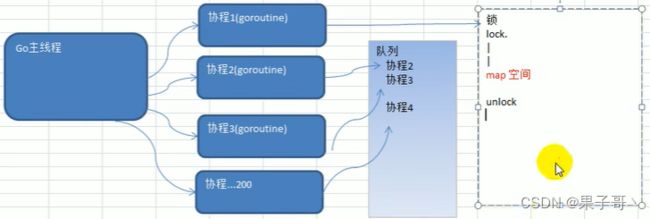
不同goroutine之间如何通讯
1)全局变量加锁同步
2)channel管道方式
(1)使用全局变量加锁同步改进程序
- 因为没有对全局变量m加锁,因此会出现资源争夺问题,代码会出现错误,提示concurrent map writes
- 解决方案:加入互斥锁
如何声明一个全局的互斥锁?var ( // synchronized同步,Mutex互斥 local sync.Mutex ) func test(n int) { lock.Lock() lock.Unlock } - 我们的数的阶乘很大,结果会越界,可以将求阶乘改成sum+=uint64(i)

主线程和协程同步进行,主线程读的时候不知道协程情况,所以依然会竞争。
解释:main遍历map的时候有可能协程没执行完,那遍历map的时候有可能和协程同时操作map
管道 channel
为什么需要channel?
前面使用全局变量加锁同步来解决goroutine的通讯,但不完美
1)主线程在等待所有goroutine全部完成的时间很难确定,我们这里设置10秒,仅仅是估算。
2)如果主线程休眠时间长了,会加长等待时间,如果等待时间断了,可能还有goroutine处于工作状态,这时也会随主线程的退出而销毁
3)通过全局变量加锁同步来实现通讯,也并不利用多个携程对全局变量的读写操作。 —— 新的通讯机制channel
channel的介绍
1)channel本质就是一个数据结构-队列。
2)数据是先进先出【FIFO】。
3)线程安全(自身机制,多个协程操作同一个管道时,不会发生资源竞争问题),多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的。
4)channel有类型的,一个string的channel只能存放string类型数据。
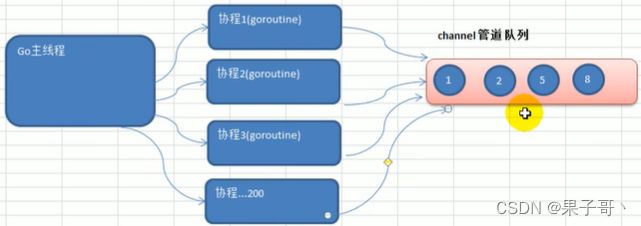
channel(管道)— 基本使用
定义/声明channel
var 变量名 chan 数据类型
举例:
var inChan chan int //(intChan用于存放int数据)
var mapChan chan map[int]string //(mapChan用于存放map[int]string类型)
var perChan chan Person
var perChan2 chan *Person
说明:
1)channel是引用类型
2)channel必须初始化才能写入数据,即make后才能使用
3)管道是有类型的,intChan只能写入整数int
channel初始化
说明:使用make进行初始化
var intChan chan int
intChan = make(chan int,10)
长度:len(intChan)
容量:cap(intChan)
向channel中写入(存放)与读取数据(不能超过其容量)
var intChan chan int
intChan = make(chan int,10)
num := 999
intChan <- 10
intChan <- num
//从管道中读取数据
var num2 int
num2 = <- intChan
<- intChan // 这样也可以,不接受,直接丢出去
在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告 deadlock
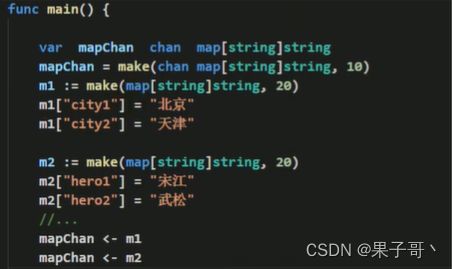
创建一个mapChan,演示写入和读取
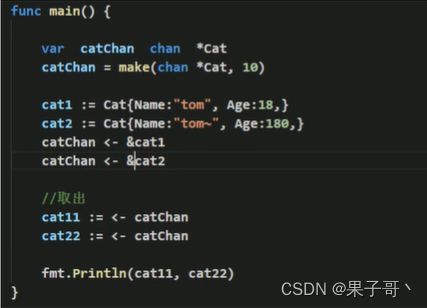
创建一个catChan,演示写入和读取
任何数据类型都实现了空接口
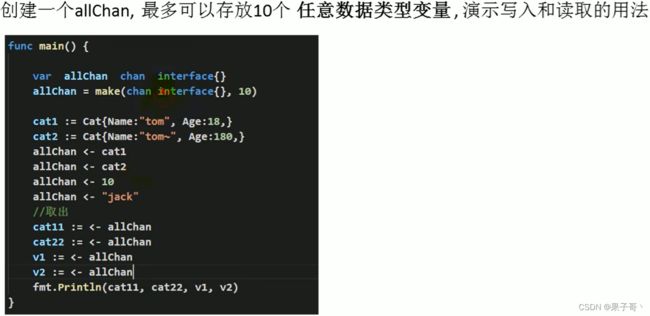
看下面代码:(通过类型断言)
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言
package main
import (
"fmt"
)
type Cat struct {
Name string
Age int
}
func main() {
//定义一个存放任意数据类型的管道 3个数据
//var allChan chan interface{}
// allChan = make(chan interface{},2)
allChan := make(chan interface{}, 3)
allChan<- 10
allChan<- "tom jack"
cat := Cat{"小花猫", 4}
allChan<- cat
//我们希望获得到管道中的第三个元素,则先将前2个推出
<-allChan
<-allChan
newCat := <-allChan //从管道中取出的Cat是什么?
fmt.Printf("newCat=%T , newCat=%v\n", newCat, newCat)
//下面的写法是错误的!编译不通过
//fmt.Printf("newCat.Name=%v", newCat.Name)
//使用类型断言 main.Cat
a := newCat.(Cat)
fmt.Printf("newCat.Name=%v", a.Name)
}


package main
import (
"fmt"
"math/rand"
)
type Person struct {
Name string
Age int
Adress string
}
func main() {
var perChan chan Person
perChan = make(chan Person,10)
for i := 0 ;i <10;i++ {
//var persons PerSlice
adress := "china"
person := Person {
Name : fmt.Sprintf("person|%d",rand.Intn(10)),
Age : rand.Intn(100),
Adress : adress,
}
perChan <- person
}
//channe需要关闭,要不会一直遍历下去
close(perChan)
for v:= range perChan {
fmt.Println("v=",v)
}
管道channel的关闭和遍历
(1)关闭
使用内置函数close可以关闭channel,当channel关闭后,就不能再向channel写数据了,但是仍然可以从该channel读取数据。
var intChan chan int
intChan = make(chan int, 100)
for i:=0; i < cap(intChan); i++ {
fmt.Println("i=", i)
intChan <- i+1
}
(2)遍历
channel支持for-range的方式进行遍历(通过range固定长度,遍历管道不能使用普通的 for 循环,因为长度会变小),请注意两个细节
- 在遍历时,如果channel没有关闭,则会出现deadlock的错误
- 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历。
package main
import (
"fmt"
)
func main() {
intChan := make(chan int, 3)
intChan<- 100
intChan<- 200
close(intChan) // close
//这是不能够再写入数到channel
//intChan<- 300 // panic: send on closed channel
fmt.Println("okook~")
//当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
//遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 100; i++ {
intChan2<- i * 2 //放入100个数据到管道
}
//遍历管道不能使用普通的 for 循环,因为长度会变小
// for i := 0; i < len(intChan2); i++ {
// }
//在遍历时,如果channel没有关闭,则会出现deadlock的错误
//在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
close(intChan2)
// 管道没下标的概念,必须按顺序取,不能特定取第三个
for v := range intChan2 {
fmt.Println("v=", v)
}
}
协程配合管道的综合案例

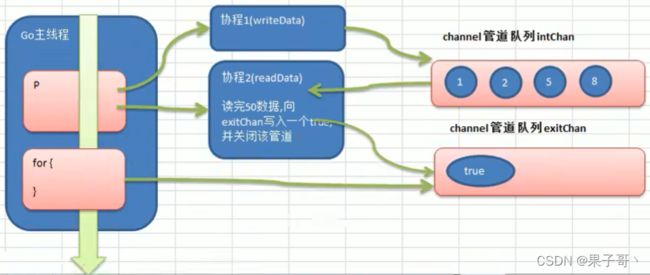
在使用协程的情况下,如果管道数据都读取完了,读取操作会挂起,当有新的数据写入时则唤醒读取,直到管道关闭并全部读取完后,再读取会返回 false,由此来判断任务是否结束。
package main
import (
"fmt"
"time"
)
//write Data
func writeData(intChan chan int) {
for i := 1; i <= 50; i++ {
//放入数据
intChan<- i //
fmt.Println("writeData ", i)
//time.Sleep(time.Second)
}
close(intChan) //关闭
}
//read data
func readData(intChan chan int, exitChan chan bool) {
for {
v, ok := <-intChan //ok代表是否成功,直到close后,会把ok变为false,然后break退出
if !ok {
break
}
time.Sleep(time.Second)
fmt.Printf("readData 读到数据=%v\n", v)
}
//readData 读取完数据后,即任务完成
exitChan<- true
close(exitChan)
}
func main() {
//创建两个管道
intChan := make(chan int, 10)
exitChan := make(chan bool, 1)
go writeData(intChan)
go readData(intChan, exitChan)
//time.Sleep(time.Second * 10),这种方法还是不知道会什么时候结束
for {
_, ok := <-exitChan
if !ok {
break
}
}
}
管道阻塞的机制
- 如果只是向管道写入数据,而没读取,就会出现阻塞而dead lock,原因是intChan容量是10,而代码writeData会写入50个数据,因此会阻塞在writeData的ch<-i。 (管道只有写而没有读,会阻塞)
- 如果写管道和读管道的频率不一致,无所谓。
管道的注意事项与细节
1、channel可以声明只读,或者只写性质
声明为只写: var chan2 chan<- int
声明为只读: var chan3 <-chan int
2、goroutine中使用recover捕获,解决协程中出现panic,导致程序崩溃问题
```go
package main
import (
“fmt”
“time”
)
func main() {
//使用select可以解决从管道取数据的阻塞问题
//1.定义一个管道 10个数据int
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan<- i
}
//2.定义一个管道 5个数据string
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
//传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock
//问题,在实际开发中,可能我们不好确定什么关闭该管道.
//可以使用select 方式可以解决
//label:
for {
select {
//注意: 这里,如果intChan一直没有关闭,不会一直阻塞而deadlock
//,会自动到下一个case匹配
case v := <-intChan :
fmt.Printf("从intChan读取的数据%d\n", v)
time.Sleep(time.Second)
case v := <-stringChan :
fmt.Printf("从stringChan读取的数据%s\n", v)
time.Sleep(time.Second)
default :
fmt.Printf("都取不到了,不玩了, 程序员可以加入逻辑\n")
time.Sleep(time.Second)
return
//break label
}
}
}
```
3、使用select可以解决从管道取数据的阻塞问题
协程求素数
需求:要求统计1-200000的数字中,哪些是素数?
分析思路:
- 传统的方法:使用一个循环判断各个数是不是素数
- 并发/并行的方式:将统计素数的任务分配给多个(4个)goroutine去完成,完成任务时间短
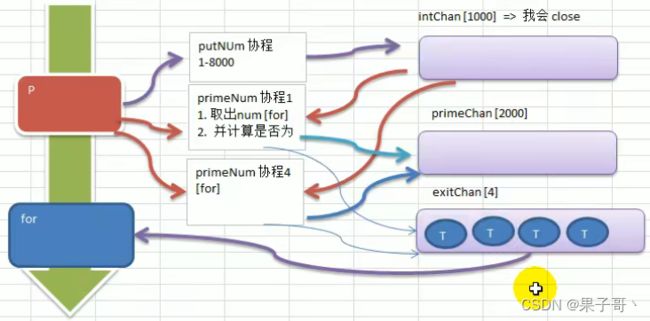
package main
import (
"fmt"
"time"
)
//向 intChan放入 1-8000个数
func putNum(intChan chan int) {
for i := 1; i <= 8000; i++ {
intChan<- i
}
//关闭intChan
close(intChan)
}
// 从 intChan取出数据,并判断是否为素数,如果是,就
// //放入到primeChan
func primeNum(intChan chan int, primeChan chan int, exitChan chan bool) {
//使用for 循环
// var num int
var flag bool //
for {
//time.Sleep(time.Millisecond * 10)
num, ok := <-intChan //intChan 取不到..
if !ok {
break
}
flag = true //假设是素数
//判断num是不是素数
for i := 2; i < num; i++ {
if num % i == 0 {//说明该num不是素数
flag = false
break
}
}
if flag {
//将这个数就放入到primeChan
primeChan<- num
}
}
fmt.Println("有一个primeNum 协程因为取不到数据,退出")
//这里我们还不能关闭 primeChan
//向 exitChan 写入true
exitChan<- true
}
func main() {
intChan := make(chan int , 1000)
primeChan := make(chan int, 20000)//放入结果
//标识退出的管道
exitChan := make(chan bool, 4) // 4个
start := time.Now().Unix()
//开启一个协程,向 intChan放入 1-8000个数
go putNum(intChan)
//开启4个协程,从 intChan取出数据,并判断是否为素数,如果是,就
//放入到primeChan
for i := 0; i < 4; i++ {
go primeNum(intChan, primeChan, exitChan)
}
//这里我们主线程,进行处理
//也通过一个协程
go func(){
for i := 0; i < 4; i++ {
<-exitChan
}
end := time.Now().Unix()
fmt.Println("使用协程耗时=", end - start)
//当我们从exitChan 取出了4个结果,就可以放心的关闭 prprimeChan
close(primeChan)
}()
//遍历我们的 primeChan ,把结果取出
for {
_, ok := <-primeChan
if !ok{
break
}
//将结果输出
//fmt.Printf("素数=%d\n", res)
}
fmt.Println("main线程退出")
}
Go语言如何执行Linux命令
package main
import (
"fmt"
"io/ioutil"
"os/exec"
)
func main() {
//需要执行的命令: free -mh
cmd := exec.Command("/bin/bash", "-c", `free -mh`)
// 获取管道输入
output, err := cmd.StdoutPipe()
if err != nil {
fmt.Println("无法获取命令的标准输出管道", err.Error())
return
}
// 执行Linux命令
if err := cmd.Start(); err != nil {
fmt.Println("Linux命令执行失败,请检查命令输入是否有误", err.Error())
return
}
// 读取所有输出
bytes, err := ioutil.ReadAll(output)
if err != nil {
fmt.Println("打印异常,请检查")
return
}
if err := cmd.Wait(); err != nil {
fm