linux下最全抓包命令使用方式学习和拓展
为什么要抓包?抓包有什么作用?
抓包的好处:
1,分析出当前服务器存在的漏洞,接口参数,防盗链,流量工具,ip伪造,参数篡改,钓鱼网站等。
抓包的作用:端到端联调,包括不限制语言的参数请求,只要走upd,http协议。万物皆可抓、
举个例子抓包的应用场景:网络传输,特殊协议,特殊场景,比如公安的视图库,国标,需要硬件交互的都必不可少(常见的:TCP,UDP,TLS,HTTP,QUIC,HTTP/2 Stream)。
我们来看看官网的介绍:(我还是那句话,不要上手就粘,万物皆可粘,这是没错,但是有这自己的理解更胜一筹)

官网使用详解:
tcpdump(1) man page | TCPDUMP & LIBPCAP
Tcpdump打印出网络接口上与布尔表达式匹配的数据包内容的描述( 有关表达式语法,请参见 pcap-filter (7) );描述前面有一个时间戳,默认情况下打印为小时、分钟、秒和自午夜以来的几分之一秒。它也可以与 -w 标志一起运行,这会导致它将数据包数据保存到文件中以供以后分析,和/或与 -r 标志一起运行,这会导致它从保存的数据包文件中读取而不是读取数据包从网络接口。它也可以与 -V一起运行 标志,这使它读取保存的数据包文件列表。在所有情况下,只有匹配 表达式的数据包 才会被 tcpdump处理。
如果Tcpdump 没有使用 -c 标志运行,它将继续捕获数据包,直到它被 SIGINT 信号(例如,通过键入中断字符,通常是 control-C 生成)或 SIGTERM 信号(通常使用 kill(1)指挥);如果使用 -c 标志运行,它将捕获数据包,直到它被 SIGINT 或 SIGTERM 信号中断或已处理指定数量的数据包。
当 tcpdump 完成捕获数据包时,它将报告以下计数:
数据包“捕获”(这是 tcpdump 已接收和处理的数据包数量);
数据包“由过滤器接收”(其含义取决于您运行 tcpdump的操作系统,并且可能取决于配置操作系统的方式 - 如果在命令行上指定了过滤器,则在某些操作系统上它很重要数据包,不管它们是否被过滤器表达式匹配,即使它们被过滤器表达式匹配,也不管 tcpdump是否 已经读取并处理了它们,在其他操作系统上,它只计算过滤器表达式匹配的数据包,而不管tcpdump是否 已读取并处理它们,并且在其他操作系统上,它仅计算与过滤器表达式匹配并由 tcpdump处理的数据包);
数据包``被内核丢弃''(这是由于缺乏缓冲区空间而被丢弃的数据包数量 ,如果操作系统向应用程序报告该信息,则运行tcpdump的操作系统中的数据包捕获机制;如果不是,则报告为0)。
在支持 SIGINFO 信号的平台上,例如大多数 BSD(包括 macOS)和 Digital/Tru64 UNIX,它会在收到 SIGINFO 信号时报告这些计数(例如,通过键入您的“状态”字符生成,通常control-T,虽然在某些平台上,比如 macOS,“status”字符默认是没有设置的,所以你必须用 stty (1) 设置它才能使用它)并且会继续抓包。在不支持 SIGINFO 信号的平台上,同样可以通过使用 SIGUSR1 信号来实现。
使用 SIGUSR2 信号和 -w 标志将强制将数据包缓冲区刷新到输出文件中。
从网络接口读取数据包可能需要您具有特殊权限;有关详细信息,请参见 pcap (3PCAP) 手册页。读取保存的数据包文件不需要特殊权限。
选项
-一个
以 ASCII 格式打印每个数据包(减去其链路级标头)。方便捕获网页。
-b
以 ASDOT 表示法而不是 ASPLAIN 表示法打印 BGP 数据包中的 AS 编号。
-B缓冲区大小
--buffer-size= buffer_size
将操作系统捕获缓冲区大小设置为buffer_size,以 KiB(1024 字节)为单位。
-c计数
收到count包后退出。
- 数数
读取捕获文件而不是解析/打印数据包时,仅在标准输出上打印数据包计数。如果在命令行上指定了过滤器,则tcpdump仅计算与过滤器表达式匹配的数据包。
-C文件大小
在将原始数据包写入保存文件之前,请检查文件当前是否大于file_size,如果是,则关闭当前保存文件并打开一个新文件。第一个保存文件之后的保存文件将具有使用 -w 标志指定的名称,其后有一个数字,从 1 开始并继续向上。file_size的默认单位是百万字节(1,000,000 字节,而不是 1,048,576 字节)。
通过在值中添加 k/K、m/M 或 g/G 后缀,可以将单位分别更改为 1,024 (KiB)、1,048,576 (MiB) 或 1,073,741,824 (GiB)。
-d
将编译后的数据包匹配代码以人类可读的形式转储到标准输出并停止。
请注意,尽管代码编译总是特定于 DLT,但通常不可能(也没有必要)指定将哪个 DLT 用于转储,因为tcpdump使用 -r指定的输入 pcap 文件的 DLT 或使用-i指定的网络接口 ,或分别使用-y 和 -i指定的网络接口的特定 DLT 。在这些情况下,转储显示的代码与不带-d的情况下过滤输入文件或网络接口的代码完全相同 。
但是,当既 没有指定-r 也没有 指定-i时 ,指定 -d会 阻止tcpdump猜测合适的网络接口(请参阅 -i)。在这种情况下,DLT 默认为 EN10MB,可以使用-y手动设置为另一个有效值 。
-dd
将数据包匹配代码转储为 C 程序片段。
-ddd
将数据包匹配代码转储为十进制数(以计数开头)。
-D
--list-interfaces
打印系统上可用的网络接口列表以及 tcpdump 可以捕获数据包的网络接口列表。对于每个网络接口,都会打印一个编号和一个接口名称,后面可能是接口的文本描述。可以将接口名称或编号提供给 -i 标志以指定要在其上捕获的接口。
这在没有列出它们的命令的系统上很有用(例如,Windows 系统或缺少 ifconfig -a的 UNIX 系统);该数字在 Windows 2000 和更高版本的系统上很有用,其中接口名称是一个有点复杂的字符串。
如果tcpdump 是用 缺少 pcap_findalldevs (3PCAP) 功能 的旧版本的libpcap构建 的 , 则不支持 -D标志。
-e
在每个转储行上打印链接级标题。例如,这可用于打印以太网和 IEEE 802.11 等协议的 MAC 层地址。
-E
使用spi@ipaddr algo:secret来解密以addr为地址并包含安全参数索引值 spi的 IPsec ESP 数据包。这种组合可以用逗号或换行符分隔重复。
请注意,此时支持为 IPv4 ESP 数据包设置密钥。
算法可以是 des-cbc、 3des-cbc、 blowfish-cbc、 rc3-cbc、 cast128-cbc或 none。默认值为des-cbc。仅当tcpdump在启用加密的情况下编译 时才存在解密数据包的能力。
secret是 ESP 密钥的 ASCII 文本。如果前面有 0x,则将读取一个十六进制值。
该选项假定 RFC 2406 ESP,而不是 RFC 1827 ESP。该选项仅用于调试目的,不鼓励将此选项与真正的“秘密”密钥一起使用。通过在命令行上显示 IPsec 密钥,您可以通过 ps (1) 和其他场合使其对其他人可见。
除了上述语法之外,语法文件名还可以用来让 tcpdump 读取提供的文件。该文件在收到第一个 ESP 数据包时打开,因此 tcpdump 可能已授予的任何特殊权限应该已经放弃.
-F
以数字方式而不是符号方式打印“外国”IPv4 地址(此选项旨在避免 Sun 的 NIS 服务器中的严重脑损伤 --- 通常它在翻译非本地互联网号码时会永远挂起)。
使用正在完成捕获的接口的 IPv4 地址和网络掩码对“外部”IPv4 地址进行测试。如果该地址或网络掩码不可用,要么是因为正在执行该捕获的接口没有地址或网络掩码,要么是因为它是 Linux 以及最新版本的 macOS 和 Solaris 中可用的“任何”伪接口,并且可以在多个接口上捕获,此选项将无法正常工作。
-F文件
使用文件作为过滤器表达式的输入。命令行上给出的附加表达式将被忽略。
-G旋转秒数
如果指定,则 每rotate_seconds秒轮换使用-w 选项指定的转储文件。保存文件将具有由 -w指定的名称,该名称应包括strftime (3) 定义的时间格式 。如果未指定时间格式,则每个新文件都将覆盖以前的文件。每当生成的文件名不唯一时,tcpdump 将覆盖预先存在的数据;因此,不建议提供比捕获周期更粗的时间规范。
如果与 -C 选项一起使用,文件名将采用 ` file
' 的形式。 -H
- 帮助
打印 tcpdump 和 libpcap 版本字符串,打印使用消息,然后退出。
- 版本
打印 tcpdump 和 libpcap 版本字符串并退出。
-H
尝试检测 802.11s 草稿网头。
-i接口
--interface=接口
监听,上报链路层类型列表,上报时间戳类型列表,或者上报 接口过滤器表达式编译结果。如果未指定 且未给出-d标志, tcpdump会在系统接口列表中搜索编号最小的配置好的接口(不包括环回),例如,它可能是“eth0”。
在具有 2.2 或更高版本内核的 Linux 系统以及最新版本的 macOS 和 Solaris 上,“any”的 接口 参数可用于从所有接口捕获数据包。请注意,“any”伪接口上的捕获不会在混杂模式下完成。
如果 支持-D 标志,则该标志打印的接口编号可以用作 接口 参数,如果系统上没有接口将该编号作为名称。
-我
--监控模式
将界面置于“监控模式”;这仅在 IEEE 802.11 Wi-Fi 接口上受支持,并且仅在某些操作系统上受支持。
请注意,在监控模式下,适配器可能会与与其关联的网络解除关联,因此您将无法使用该适配器使用任何无线网络。如果您在监视模式下捕获并且未使用另一个适配器连接到另一个网络,这可能会阻止访问网络服务器上的文件或解析主机名或网络地址。
此标志将影响 -L 标志的输出。如果 未指定-I ,则仅显示那些不在监控模式下可用的链路层类型;如果 指定了-I ,则仅显示在监视模式下可用的链路层类型。
--立即模式
以“立即模式”捕获。在这种模式下,数据包一到达就被传递到 tcpdump,而不是为了提高效率而进行缓冲。如果数据包被打印到终端而不是文件或管道,这是打印数据包而不是将数据包保存到“保存文件”时的默认设置。
-j tstamp_type
--time-stamp-type= tstamp_type
将捕获的时间戳类型设置为tstamp_type。用于时间戳类型的名称在 pcap-tstamp (7)中给出;并非所有列出的类型都对任何给定接口都有效。
-J
--list-time-stamp-types
列出接口支持的时间戳类型并退出。如果无法为接口设置时间戳类型,则不会列出时间戳类型。
--time-stamp-precision= tstamp_precision
捕获时,将捕获的时间戳精度设置为 tstamp_precision。请注意,高精度时间戳(纳秒)的可用性及其实际精度取决于平台和硬件。另请注意,在将纳秒精度的捕获写入保存文件时,时间戳以纳秒分辨率写入,文件以不同的幻数写入,以指示时间戳以秒和纳秒为单位;并非所有读取 pcap 保存文件的程序都能够读取这些捕获。
读取保存文件时,将时间戳转换为timestamp_precision指定的精度,并以该分辨率显示。如果指定的精度小于文件中时间戳的精度,则转换将失去精度。
timestamp_precision 支持的值是micro用于微秒分辨率和nano用于纳秒分辨率。默认为微秒分辨率。
- 微
--纳米
--time -stamp-precision=micro或 --time-stamp-precision=nano 的简写,相应地调整时间戳精度。从保存文件中读取数据包时,如果保存文件是以纳秒精度创建的,则使用 --micro 会截断时间戳。相反,当 使用--nano时,以微秒精度创建的保存文件将在时间戳中添加尾随零。
-K
--dont-verify-checksums
不要尝试验证 IP、TCP 或 UDP 校验和。这对于在硬件中执行部分或全部校验和计算的接口很有用;否则,所有传出的 TCP 校验和都将被标记为错误。
-l
使标准输出行缓冲。如果您想在捕获数据时查看数据,这很有用。例如,
tcpdump -l | 开球日期或者
tcpdump -l > dat & 尾 -f dat请注意,在 Windows 上,“行缓冲”表示“未缓冲”,因此如果 指定了-l ,WinDump 将单独写入每个字符 。
-U在其行为上与-l 类似 ,但它会导致输出被“包缓冲”,因此输出在每个包的末尾而不是每行的末尾被写入标准输出;这在包括 Windows 在内的所有平台上都有缓冲。
-L
--list-data-link-types
列出接口的已知数据链路类型,在指定的模式下,然后退出。已知数据链路类型的列表可能取决于指定的模式;例如,在某些平台上,Wi-Fi 接口在不处于监控模式时可能支持一组数据链路类型(例如,它可能仅支持虚假以太网标头,或者可能支持 802.11 标头但不支持带有无线电信息的 802.11 标头) 和另一组在监控模式下的数据链路类型(例如,它可能仅在监控模式下支持 802.11 标头或带有无线电信息的 802.11 标头)。
-m模块
从文件module 加载 SMI MIB 模块定义。可以多次使用此选项将多个 MIB 模块加载到tcpdump中。
-M秘密
使用秘密作为共享秘密,以使用 TCP-MD5 选项 (RFC 2385) 验证在 TCP 段中找到的摘要(如果存在)。
-n
不要将地址(即主机地址、端口号等)转换为名称。
-N
不要打印主机名的域名资格。例如,如果你给出这个标志,那么tcpdump将打印 ``nic'' 而不是 ``nic.ddn.mil''。
-#
- 数字
在行首打印可选的数据包编号。
-O
--无优化
不要运行数据包匹配代码优化器。仅当您怀疑优化器中存在错误时,这才有用。
-p
--no-promiscuous-mode
不要将界面置于混杂模式。请注意,由于某些其他原因,界面可能处于混杂模式;因此,“-p”不能用作“ether host {local-hw-addr} or ether broadcast”的缩写。
- 打印
打印解析的数据包输出,即使原始数据包正在保存到带有 -w 标志的文件中。
--print-sampling= nth
打印每第 n 个数据包。此选项启用--print标志。
未打印的数据包不被解析,这减少了处理时间。例如,将 nth设置 为100 ,将(从 1 开始计数)解析并打印第 100 个数据包、第 200 个数据包、第 300 个数据包等。
此选项还启用-S标志,因为不跟踪未打印数据包的相对 TCP 序列号。
-Q方向
--direction=方向
选择应捕获数据包的 发送/接收方向。可能的值是“in”、“out”和“inout”。并非在所有平台上都可用。
-q
快速(安静?)输出。打印更少的协议信息,因此输出行更短。
-r文件
从文件中 读取数据包(使用 -w 选项或其他编写 pcap 或 pcapng 文件的工具创建)。如果文件是“-”, 则使用标准输入。
-S
--absolute-tcp-sequence-numbers
打印绝对而非相对的 TCP 序列号。
-s snaplen
--snapshot-length= snaplen
从每个数据包中捕获 snaplen 字节的数据而不是默认的 262144 字节。由于快照受限而截断的数据包在输出中用 ``[| proto ]'',其中proto 是发生截断的协议级别的名称。
请注意,拍摄较大的快照既增加了处理数据包所需的时间,又有效地减少了数据包缓冲量。这可能会导致数据包丢失。另请注意,拍摄较小的快照会丢弃来自传输层以上协议的数据,这会丢失可能很重要的信息。例如,NFS 和 AFS 请求和回复非常大,如果选择了太短的快照长度,则大部分细节将不可用。
如果您需要将快照大小减小到默认值以下,则应将snaplen限制为将捕获您感兴趣的协议信息的最小数字。将 snaplen设置为 0 会将其设置为默认值 262144,以便与最近的旧版本向后兼容tcpdump的版本 。
-T型
强制由“表达式”选择的数据包被解释为指定的类型。目前已知的类型有 aodv (Ad-hoc On-demand Distance Vector protocol), carp (Common Address Redundancy Protocol), cnfp (Cisco NetFlow protocol), domain (Domain Name System), lmp (Link Management Protocol), pgm (Pragmatic General Multicast), pgm_zmtp1 (ZMTP/1.0 inside PGM/EPGM), ptp (Precision Time Protocol), quic (QUIC), radius (RADIUS), resp (REdis Serialization Protocol), rpc(Remote Procedure Call), rtcp (Real-Time Applications control protocol), rtp (Real-Time Applications protocol), snmp (Simple Network Management Protocol), someip (SOME/IP), tftp (Trivial File Transfer Protocol), vat ( Visual Audio Tool)、 vxlan(虚拟可扩展局域网)、 wb(分布式白板)和 zmtp1(ZeroMQ 消息传输协议 1.0)。
请注意,上面的pgm类型仅影响 UDP 解释,无论如何,本机 PGM 始终被识别为 IP 协议 113。UDP 封装的 PGM 通常称为“EPGM”或“PGM/UDP”。
请注意,上面的pgm_zmtp1类型会同时影响本机 PGM 和 UDP 的解释。在本地 PGM 解码期间,ODATA/RDATA 数据包的应用程序数据将被解码为带有 ZMTP/1.0 帧的 ZeroMQ 数据报。在 UDP 解码期间,除此之外,任何 UDP 数据包都将被视为封装的 PGM 数据包。
-t
不要在每个转储行上打印时间戳。
-tt
在每个转储行上打印时间戳,以自 1970 年 1 月 1 日 00:00:00 UTC 以来的秒数以及自该时间以来的几分之一秒。
-ttt
在每个转储行的当前行和上一行之间 打印一个增量(微秒或纳秒分辨率,具体取决于 --time-stamp-precision选项)。默认为微秒分辨率。
-tttt
在每个转储行上打印时间戳,如小时、分钟、秒和自午夜以来的秒的小数部分,前面是日期。
-tttt
在每个转储行的当前行和第一行之间 打印一个增量(微秒或纳秒分辨率,具体取决于 --time-stamp-precision选项)。默认为微秒分辨率。
-u
打印未解码的 NFS 句柄。
-U
--数据包缓冲
如果 没有指定-w 选项,或者如果指定了但同时指定了 --print 标志,则使打印的数据包输出 ``packet-buffered'';即,当每个数据包的内容描述被打印时,它将被写入标准输出,而不是在不写入终端时,仅在输出缓冲区填满时才写入。
如果指定了 -w 选项,则使保存的原始数据包输出 ``packet-buffered'';即,当每个数据包被保存时,它将被写入输出文件,而不是仅在输出缓冲区填满时才写入。
如果tcpdump 是用 缺少 pcap_dump_flush (3PCAP) 功能 的旧版本的libpcap构建 的 , 则不支持 -U标志。
-v
解析和打印时,产生(稍微多一点的)详细输出。例如,打印 IP 数据包中的生存时间、标识、总长度和选项。还启用额外的数据包完整性检查,例如验证 IP 和 ICMP 标头校验和。
当使用-w选项 写入文件, 同时不使用 -r 选项从文件读取时,每秒一次向 stderr 报告捕获的数据包数。在 Solaris、FreeBSD 和可能的其他操作系统中,此定期更新当前可能会导致捕获的数据包在从内核到 tcpdump 的途中丢失。
-vv
更详细的输出。例如,从 NFS 回复数据包中打印附加字段,并完全解码 SMB 数据包。
-vvv
更详细的输出。例如,telnet SB ... SE选项被完整打印。使用 -X Telnet 选项也以十六进制打印。
-V文件
从file 读取文件名列表。如果文件是“-”, 则使用标准输入。
-w文件
将原始数据包写入文件,而不是解析和打印出来。稍后可以使用 -r 选项打印它们。如果文件是“-”, 则使用标准输出。
如果写入文件或管道,此输出将被缓冲,因此从文件或管道读取的程序可能在收到数据包后的任意时间内看不到数据包。使用 -U 标志使数据包在收到后立即写入。
MIME 类型application/vnd.tcpdump.pcap已在 IANA 注册用于pcap文件。文件扩展名.pcap似乎与.cap和 .dmp 一起最常用。Tcpdump本身在读取捕获文件时不检查扩展名,并且在写入文件时不添加扩展名(它在文件头中使用幻数)。但是,如果存在扩展名,许多操作系统和应用程序将使用该扩展名,并且建议添加一个(例如 .pcap)。
有关文件格式的说明,请参见 pcap-savefile (5) 。
-W文件计数
与 -C 选项一起使用,这会将创建的文件数限制为指定的数量,并从头开始覆盖文件,从而创建一个“循环”缓冲区。此外,它会以足够多的前导 0 命名文件以支持最大文件数,从而使它们能够正确排序。
与 -G 选项一起使用,这将限制创建的旋转转储文件的数量,达到限制时以状态 0 退出。
如果与 -C 和 -G 一起使用,当前 将 忽略-W 选项,并且只会影响文件名。
-X
解析和打印时,除了打印每个数据包的标头外,还要以十六进制打印每个数据包的数据(减去其链路级标头)。 将打印整个数据包或 snaplen字节中较小的一个。请注意,这是整个链路层数据包,因此对于填充的链路层(例如以太网),当更高层数据包短于所需填充时,也会打印填充字节。 在当前实现中,如果数据包被截断, 此标志可能与-xx具有相同的效果 。
-xx
解析和打印时,除了打印每个数据包的头外,还打印每个数据包的数据, 包括 它的链路层头,以十六进制表示。
-X
解析和打印时,除了打印每个数据包的标头外,还以十六进制和 ASCII 格式打印每个数据包的数据(减去其链路级标头)。这对于分析新协议非常方便。 在当前实现中,如果数据包被截断, 此标志可能与-XX具有相同的效果 。
-XX
解析和打印时,除了打印每个数据包的 标头外,还以十六进制和 ASCII 格式 打印每个数据包的数据,包括其链路级标头。
-y数据链路类型
--linktype=数据链路类型
设置在捕获数据包时使用的数据链路类型(参见 -L)或只是编译和转储数据包匹配代码(参见 -d)到datalinktype。
-z postrotate 命令
与 -C 或 -G 选项一起使用,这将使 tcpdump 运行“ postrotate-command file ”,其中 file 是每次旋转后关闭的保存文件。例如,指定 -z gzip 或 -z bzip2 将使用 gzip 或 bzip2 压缩每个保存文件。
请注意,tcpdump 将与捕获并行运行命令,使用最低优先级,这样就不会干扰捕获过程。
如果你想使用一个本身带有标志或不同参数的命令,你总是可以编写一个 shell 脚本,它将保存文件名作为唯一的参数,安排标志和参数并执行你想要的命令。
-Z用户
--relinquish-privileges=用户
如果 tcpdump 以 root 身份运行,在打开捕获设备或输入保存文件之后,但在打开任何保存文件进行输出之前,将用户 ID 更改为 user 并将组 ID 更改为 user 的主要 组。
此行为也可以在编译时默认启用。
表达
选择要转储的数据包。如果没有给出表达式 ,则网络上的所有数据包都将被转储。否则,只会转储表达式为“真”的数据包。有关表达式语法,请参阅 pcap-filter (7)。
表达式参数可以作为单个 Shell 参数或多个 Shell 参数传递给 tcpdump ,以更方便者为准。通常,如果表达式包含 Shell 元字符,例如用于转义协议名称的反斜杠,则将其作为单个带引号的参数传递比转义 Shell 元字符更容易。多个参数在解析之前用空格连接。
例子
打印到达或离开sundown的所有数据包:
tcpdump 主机日落要打印helios与hot或ace之间的流量:
tcpdump 主机 helios 和 \( hot or ace \)打印ace和除helios之外的任何主机 之间的所有 IP 数据包:
tcpdump ip 主机 ace 而不是 helios打印本地主机和伯克利主机之间的所有流量:
tcpdump net ucb-ether要通过 Internet 网关snup 打印所有 ftp 流量:(请注意,引用表达式是为了防止 shell(错误)解释括号):
tcpdump '网关 snup 和(端口 ftp 或 ftp 数据)'打印既不是来自本地主机也不是发往本地主机的流量(如果您网关到另一个网络,这些东西永远不应该进入您的本地网络)。
tcpdump ip 而不是 net localnet打印涉及非本地主机的每个 TCP 会话的开始和结束数据包(SYN 和 FIN 数据包)。
tcpdump 'tcp[tcpflags] & (tcp-syn|tcp-fin) != 0 而不是 src 和 dst net localnet '打印设置了标志 RST 和 ACK 的 TCP 数据包。(即只选择flags字段中的RST和ACK标志,如果结果是“RST和ACK都设置”,则匹配)
tcpdump 'tcp[tcpflags] & (tcp-rst|tcp-ack) == (tcp-rst|tcp-ack)'打印进出端口 80 的所有 IPv4 HTTP 数据包,即仅打印包含数据的数据包,而不是,例如,SYN 和 FIN 数据包以及 ACK-only 数据包。(IPv6 留给读者作为练习。)
tcpdump 'tcp 端口 80 和 (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'要打印通过网关snup 发送的长度超过 576 字节的 IP 数据包:
tcpdump '网关 snup 和 ip[2:2] > 576'打印 不是 通过以太网广播或多播发送的 IP 广播或多播数据包:
tcpdump 'ether[0] & 1 = 0 和 ip[16] >= 224'打印所有不是回显请求/回复的 ICMP 数据包(即,不是 ping 数据包):
tcpdump 'icmp[icmptype] != icmp-echo 和 icmp[icmptype] != icmp-echoreply'输出格式
tcpdump 的输出取决于协议。下面给出了大多数格式的简要说明和示例。
时间戳
默认情况下,所有输出行前面都有一个时间戳。时间戳是表单中的当前时钟时间
hh:mm:ss.frac并且与内核的时钟一样准确。时间戳反映内核对数据包应用时间戳的时间。没有尝试考虑网络接口完成从网络接收数据包到内核对数据包应用时间戳之间的时间延迟;该时间延迟可能包括网络接口完成从网络接收数据包的时间与将中断传递给内核以使其读取数据包的时间之间的延迟,以及内核服务于“新数据包”中断和它对数据包应用时间戳的时间。链接级别标头
如果给出了 '-e' 选项,则打印出链接级标题。在以太网上,会打印源地址和目标地址、协议和数据包长度。
在 FDDI 网络上,“-e”选项使tcpdump打印“帧控制”字段、源地址和目标地址以及数据包长度。(“帧控制”字段控制对数据包其余部分的解释。普通数据包(例如包含 IP 数据报的数据包)是“异步”数据包,优先级值在 0 到 7 之间;例如,“ async4 ”。这样的假设数据包包含 802.2 逻辑链路控制 (LLC) 数据包;如果它不是ISO 数据报或所谓的 SNAP 数据包,则打印 LLC 报头。
在令牌环网络上,“-e”选项使tcpdump打印“访问控制”和“帧控制”字段、源地址和目标地址以及数据包长度。与 FDDI 网络一样,假设数据包包含 LLC 数据包。无论是否指定了“-e”选项,都会为源路由数据包打印源路由信息。
在 802.11 网络上,“-e”选项会导致tcpdump打印“帧控制”字段、802.11 标头中的所有地址以及数据包长度。与 FDDI 网络一样,假设数据包包含 LLC 数据包。
(注意:以下描述假定您熟悉 RFC 1144 中描述的 SLIP 压缩算法。)
在 SLIP 链路上,打印出方向指示符(“I”表示入站,“O”表示出站)、数据包类型和压缩信息。首先打印数据包类型。这三种类型是ip、utcp和ctcp。没有为ip数据包打印更多的链接信息。对于 TCP 数据包,连接标识符打印在类型之后。如果数据包被压缩,则打印出其编码的标头。特殊情况打印为 *S+ n和*SA+ n,其中n是序列号(或序列号和确认)已更改的量。如果不是特殊情况,则打印零个或多个更改。更改由 U(紧急指针)、W(窗口)、A(确认)、S(序列号)和 I(数据包 ID)指示,后跟 delta(+n 或 -n)或新值(=n)。最后,打印数据包中的数据量和压缩包头长度。
例如,以下行显示了一个出站压缩 TCP 数据包,带有一个隐式连接标识符;ack 变了 6,sequence number 变了 49,packet ID 变了 6;有 3 个字节的数据和 6 个字节的压缩头:
O ctcp * A+6 S+49 I+6 3 (6)ARP/RARP 数据包
ARP/RARP 输出显示请求的类型及其参数。该格式旨在自我解释。这是从主机rtsg到主机csam的“rlogin”开始时的一个简短示例:
arp 谁有 csam 告诉 rtsg arp 回复 csam is-at CSAM第一行表示 rtsg 发送了一个 ARP 数据包,询问 Internet 主机 csam 的以太网地址。Csam 用它的以太网地址回复(在这个例子中,以太网地址大写,互联网地址小写)。如果我们执行了tcpdump -n ,这看起来就不那么多余了:
arp 谁拥有 128.3.254.6 告诉 128.3.254.68 arp 回复 128.3.254.6 is-at 02:07:01:00:01:c4如果我们执行了tcpdump -e,那么第一个数据包是广播的,第二个是点对点的这一事实将是可见的:
RTSG 广播 0806 64:arp who-has csam tell rtsg CSAM RTSG 0806 64:arp 回复 csam is-at CSAM对于第一个数据包,它表示以太网源地址是 RTSG,目标是以太网广播地址,类型字段包含十六进制 0806(类型 ETHER_ARP),总长度为 64 个字节。IPv4 数据包
如果没有打印链路层报头,对于 IPv4 数据包, IP将在时间戳之后打印。
如果指定了 -v标志,来自 IPv4 标头的信息将显示在IP或链路层标头 之后的括号中。该信息的一般格式为:
tos tos , ttl ttl , id id , offset offset , flags [ flags ], proto proto , length长度, options ( options )tos是服务字段的类型;如果 ECN 位不为零,则报告为ECT(1)、ECT(0)或CE。 ttl是生存时间;如果为零,则不报告。 id是 IP 标识字段。 offset是片段偏移量字段;无论这是否是分段数据报的一部分,都会打印出来。 flags是 MF 和 DF 标志;如果设置了MF,则报告+ ,如果设置了F,则报告DF。如果两者都没有设置,. 被报道。 proto是协议 ID 字段。 length是总长度字段。 选项是 IP 选项(如果有)。接下来,对于 TCP 和 UDP 数据包,将打印源 IP 地址和目标 IP 地址以及 TCP 或 UDP 端口,每个 IP 地址与其对应的端口之间有一个点,将用 > 分隔源和目标。对于其他协议,将打印地址,并用 > 分隔源和目标。之后将打印更高级别的协议信息(如果有)。
对于分段的 IP 数据报,第一个分段包含更高级别的协议头;第一个之后的片段不包含更高级别的协议头。 如上所述, 分段信息将仅在 IP 标头信息中使用 -v标志打印。
TCP 数据包
(注意:以下描述假定您熟悉 RFC 793 中描述的 TCP 协议。如果您不熟悉该协议,则此描述对您没有多大用处。)
TCP 协议行的一般格式是:
src > dst : 标志 [ tcpflags ], seq data-seqno , ack ackno , win window , urg紧急, options [ opts ], length lensrc和dst是源 IP 地址和目标 IP 地址和端口。 Tcpflags是 S (SYN)、F (FIN)、P (PUSH)、R (RST)、U (URG)、W (ECN CWR)、E (ECN-Echo) 或 `.' 的某种组合。(ACK),如果没有设置标志,则为“无”。 Data-seqno描述了这个数据包中的数据所覆盖的序列空间部分(参见下面的示例)。 Ackno是此连接上另一个方向预期的下一个数据的序列号。 Window是此连接上另一个方向可用的接收缓冲区空间的字节数。 Urg表示数据包中有“紧急”数据。 选项是 TCP 选项(例如,mss 1024)。 伦是有效载荷数据的长度。Iptype、Src、dst和标志始终存在。其他字段取决于数据包的 TCP 协议标头的内容,并且仅在适当时才输出。
这是从主机rtsg到主机csam的 rlogin 的开头部分。
IP rtsg.1023 > csam.login: 标志 [S], seq 768512:768512, win 4096, opts [mss 1024] IP csam.login > rtsg.1023: 标志 [S.], seq, 947648:947648, ack 768513, win 4096, opts [mss 1024] IP rtsg.1023 > csam.login: 标志 [.], ack 1, win 4096 IP rtsg.1023 > csam.login: Flags [P.], seq 1:2, ack 1, win 4096, length 1 IP csam.login > rtsg.1023: 标志 [.], ack 2, win 4096 IP rtsg.1023 > csam.login:标志 [P.],seq 2:21,ack 1,win 4096,长度 19 IP csam.login > rtsg.1023:标志 [P.],seq 1:2,ack 21,win 4077,长度 1 IP csam.login > rtsg.1023:标志 [P.],seq 2:3,ack 21,win 4077,urg 1,长度 1 IP csam.login > rtsg.1023:标志 [P.],seq 3:4,ack 21,win 4077,urg 1,长度 1第一行表示 rtsg 上的 TCP 端口 1023 向 csam 上的登录端口发送了一个数据包 。S表示设置了SYN标志。数据包序列号是 768512,它不包含任何数据。(符号是 `first:last',意思是 `sequence numbers first up to but not include last '。)没有捎带 ACK,可用的接收窗口是 4096 字节,并且有一个 max-segment-size 选项请求1024 字节的 MSS。Csam 回复了一个类似的数据包,除了它包含一个用于 rtsg 的 SYN 的捎带 ACK。然后 Rtsg 确认 csam 的 SYN。'.' 表示设置了 ACK 标志。数据包不包含数据,因此没有数据序列号或长度。请注意,ACK 序列号是一个小整数 (1)。当tcpdump第一次看到 TCP 'conversation' 时,它会打印数据包的序列号。在会话的后续数据包中,将打印当前数据包的序列号与此初始序列号之间的差异。这意味着第一个之后的序列号可以解释为会话数据流中的相对字节位置(每个方向的第一个数据字节为“1”)。`-S' 将覆盖此功能,导致输出原始序列号。
在第 6 行,rtsg 发送 csam 19 个字节的数据(对话的 rtsg → csam 侧的字节 2 到 20)。PUSH 标志在数据包中设置。在第 7 行,csam 说它已接收到 rtsg 发送的数据,但不包括字节 21。由于 csam 的接收窗口变小了 19 个字节,因此大部分数据显然位于套接字缓冲区中。Csam 也在这个数据包中向 rtsg 发送一个字节的数据。在第 8 行和第 9 行,csam 将两个字节的紧急推送数据发送到 rtsg。
如果快照足够小以至于tcpdump没有捕获完整的 TCP 标头,它会尽可能多地解释标头,然后报告 ``[| tcp ]'' 表示无法解释余数。如果标头包含一个虚假选项(一个长度太小或超出标头末尾的选项),tcpdump 会将其报告为 ``[ bad opt ]'' 并且不会解释任何进一步的选项(因为无法分辨他们从哪里开始)。如果标头长度表明存在选项,但 IP 数据报长度不足以使选项实际存在,则tcpdump将其报告为 ``[ bad hdr length ]''。
捕获具有特定标志组合(SYN-ACK、URG-ACK 等)的 TCP 数据包
TCP头的控制位部分有8位:
CWR | 欧洲经委会 | 急需 | 确认 | PSH | RST | 同步 | 鳍
假设我们要查看用于建立 TCP 连接的数据包。回想一下,TCP 在初始化新连接时使用 3 次握手协议;关于 TCP 控制位的连接顺序是
1) 调用者发送 SYN
2) 接收方用 SYN、ACK 响应
3) 调用者发送 ACK
现在我们感兴趣的是捕获仅设置了 SYN 位的数据包(步骤 1)。请注意,我们不需要来自第 2 步(SYN-ACK)的数据包,只需要一个简单的初始 SYN。我们需要的是tcpdump的正确过滤器表达式。
回想一下没有选项的 TCP 标头的结构:
0 15 31 -------------------------------------------------- --------------- | 源港 | 目的港| -------------------------------------------------- --------------- | 序号 | -------------------------------------------------- --------------- | 确认号码 | -------------------------------------------------- --------------- | HL | rsvd |C|E|U|A|P|R|S|F| 窗口大小 | -------------------------------------------------- --------------- | TCP 校验和 | 紧急指针 | -------------------------------------------------- ---------------除非存在选项,否则 TCP 标头通常包含 20 个八位字节的数据。该图的第一行包含八位字节 0 - 3,第二行显示八位字节 4 - 7 等。
从 0 开始计数,相关的 TCP 控制位包含在 octet 13 中:
0 7| 15| 23| 31 ----------------|---------------|----------------|- --------------- | HL | rsvd |C|E|U|A|P|R|S|F| 窗口大小 | ----------------|---------------|----------------|- --------------- | | 第 13 个八位字节 | | |让我们仔细看看八位字节。13:
| | |---------------| |C|E|U|A|P|R|S|F| |---------------| |7 5 3 0|这些是我们感兴趣的 TCP 控制位。我们将这个八位字节中的位从右到左从 0 到 7 编号,所以 PSH 位是位号 3,而 URG 位是位号 5。
回想一下,我们想要捕获仅设置了 SYN 的数据包。让我们看看如果 TCP 数据报到达时在其标头中设置了 SYN 位,八位字节 13 会发生什么情况:
|C|E|U|A|P|R|S|F| |---------------| |0 0 0 0 0 0 1 0| |---------------| |7 6 5 4 3 2 1 0|查看控制位部分,我们看到仅设置了位号 1 (SYN)。
假设字节数 13 是网络字节序中的 8 位无符号整数,则该字节的二进制值为
00000010
它的十进制表示是
7 6 5 4 3 2 1 0 0*2 + 0*2 + 0*2 + 0*2 + 0*2 + 0*2 + 1*2 + 0*2 = 2我们几乎完成了,因为现在我们知道,如果只设置 SYN,则 TCP 报头中第 13 个八位字节的值,当解释为网络字节顺序的 8 位无符号整数时,必须正好是 2。
这种关系可以表示为
tcp[13] == 2
我们可以使用此表达式作为tcpdump的过滤器,以查看仅设置了 SYN 的数据包:
tcpdump -i xl0 tcp[13] == 2
表达式说“让 TCP 数据报的第 13 个八位字节具有十进制值 2”,这正是我们想要的。
现在,假设我们需要捕获 SYN 数据包,但我们不关心是否同时设置了 ACK 或任何其他 TCP 控制位。让我们看看当带有 SYN-ACK 集的 TCP 数据报到达时,八位字节 13 会发生什么:
|C|E|U|A|P|R|S|F| |---------------| |0 0 0 1 0 0 1 0| |---------------| |7 6 5 4 3 2 1 0|现在位 1 和 4 在第 13 个八位字节中设置。八位字节 13 的二进制值为
00010010转换为十进制
7 6 5 4 3 2 1 0 0*2 + 0*2 + 0*2 + 1*2 + 0*2 + 0*2 + 1*2 + 0*2 = 18现在我们不能只在tcpdump过滤器表达式中使用 'tcp[13] == 18',因为这只会选择那些设置了 SYN-ACK 的数据包,而不是那些只设置了 SYN 的数据包。请记住,只要设置了 SYN,我们就不会关心是否设置了 ACK 或任何其他控制位。
为了实现我们的目标,我们需要将八位字节 13 的二进制值与其他值进行逻辑与以保留 SYN 位。我们知道我们希望在任何情况下都设置 SYN,因此我们将第 13 个八位字节中的值与 SYN 的二进制值进行逻辑与:
00010010 SYN-ACK 00000010 SYN AND 00000010(我们想要 SYN)和 00000010(我们想要 SYN) -------- -------- = 00000010 = 00000010我们看到无论是否设置了 ACK 或另一个 TCP 控制位,此 AND 操作都会提供相同的结果。AND 值的十进制表示以及此操作的结果是 2(二进制 00000010),因此我们知道对于设置了 SYN 的数据包,以下关系必须成立:
( ( 八位字节 13 的值 ) AND ( 2 ) ) == ( 2 )
这将我们指向tcpdump过滤器表达式
tcpdump -i xl0 'tcp[13] & 2 == 2'一些偏移量和字段值可能表示为名称而不是数值。例如 tcp[13] 可以替换为 tcp[tcpflags]。以下 TCP 标志字段值也可用:tcp-fin、tcp-syn、tcp-rst、tcp-push、tcp-ack、tcp-urg。
这可以证明为:
tcpdump -i xl0 'tcp[tcpflags] & tcp-push != 0'请注意,您应该在表达式中使用单引号或反斜杠来隐藏 shell 中的 AND ('&') 特殊字符。
UDP 数据包
这个 rwho 数据包说明了 UDP 格式:
actinide.who > 广播.who: udp 84这表示主机actinide上的端口向主机广播的端口发送了 UDP 数据报,即 Internet 广播地址。该数据包包含 84 字节的用户数据。某些 UDP 服务被识别(从源或目标端口号)并打印更高级别的协议信息。特别是对 NFS 的域名服务请求 (RFC 1034/1035) 和 Sun RPC 调用 (RFC 1050)。
TCP 或 UDP 名称服务器请求
(注意:以下描述假定您熟悉 RFC 1035 中描述的域服务协议。如果您不熟悉该协议,则以下描述似乎是用希腊语编写的。)
名称服务器请求的格式为
src > dst: id op? 标志 qtype qclass 名称 (len) h2opolo.1538 > helios.domain: 3+ A? ucbvax.berkeley.edu。(37)主机h2opolo向helios上的域服务器询问与名称ucbvax.berkeley.edu关联的地址记录 (qtype=A) 。 查询 ID 为“3”。`+' 表示设置了递归所需的标志。查询长度为 37 个字节,不包括 TCP 或 UDP 和 IP 协议标头。查询操作是正常的Query,因此省略了 op 字段。如果 op 是其他东西,它会被打印在 '3' 和 '+' 之间。同样, qclass 是正常的 C_IN,因此被省略。任何其他 qclass 都将在“A”之后立即打印。检查了一些异常情况,并可能导致方括号中包含额外字段:如果查询包含答案、规范记录或附加记录部分, 则 ancount、 nscount或 arcount 打印为 `[ n a]'、`[ n n ]' 或 `[ n au]' 其中n 是适当的计数。如果设置了任何响应位(AA、RA 或 rcode)或在字节 2 和 3 中设置了任何“必须为零”位,则打印“[b2&3= x ]”,其中x是头字节二和三。
TCP 或 UDP 名称服务器响应
名称服务器响应的格式为
src > dst: id op rcode flags a/n/au type class data (len) helios.domain > h2opolo.1538: 3 3/3/7 A 128.32.137.3 (273) helios.domain > h2opolo.1537: 2 NXDomain* 0/1/0 (97)在第一个示例中,helios 使用 3 条答案记录、3 条名称服务器记录和 7 条附加记录来响应来自h2opolo的查询 id 3 。第一个答复记录是类型 A(地址),其数据是 Internet 地址 128.32.137.3。响应的总大小为 273 字节,不包括 TCP 或 UDP 和 IP 标头。操作(查询)和响应代码(NoError)被省略,A 记录的类(C_IN)也是如此。在第二个示例中,helios使用不存在域 (NXDomain) 的响应代码响应查询 2,没有答案、一个名称服务器和没有权限记录。`*' 表示已设置权威答案位。由于没有答案,因此没有打印任何类型、类别或数据。
其他可能出现的标志字符是“-”(递归可用,RA,未设置)和“|” (截断消息,TC,设置)。如果“问题”部分不包含一个条目,则打印“[ n q]”。
SMB/CIFS 解码
tcpdump现在包括相当广泛的 SMB/CIFS/NBT 解码,用于 UDP/137、UDP/138 和 TCP/139 上的数据。还完成了 IPX 和 NetBEUI SMB 数据的一些原始解码。
默认情况下,会进行相当少的解码,如果使用 -v,则会进行更详细的解码。请注意,使用 -va 单个 SMB 数据包可能会占用一页或更多页面,因此如果您真的想要所有血腥细节,请仅使用 -v。
有关 SMB 数据包格式的信息以及所有字段的含义,请参阅 Index of /pub/samba/specs和其他在线资源。SMB 补丁由 Andrew Tridgell ( [email protected] ) 编写。
NFS 请求和回复
Sun NFS(网络文件系统)请求和回复打印为:
src.sport > dst.nfs:NFS 请求 xid xid len op args src.nfs > dst.dport:NFS 回复 xid xid 回复 stat len op 结果 sushi.1023 > wrl.nfs: NFS 请求 xid 26377 112 读取链接 fh 21,24/10.73165 wrl.nfs > sushi.1023:NFS 回复 xid 26377 回复 ok 40 读取链接“../var” sushi.1022 > wrl.nfs: NFS 请求 xid 8219 144 查找 fh 9,74/4096.6878 “xcolors” wrl.nfs > sushi.1022:NFS 回复 xid 8219 回复 ok 128 查找 fh 9,74/4134.3150在第一行中,主机sushi 向wrl发送一个 id为26377的事务。请求为 112 字节,不包括 UDP 和 IP 标头。该操作是文件句柄 ( fh ) 21,24/10.731657119上的 读取链接(读取符号链接) 。(如果幸运的话,在这种情况下,文件句柄可以解释为主要、次要设备号对,后跟索引节点号和世代号。)在第二行,wrl用相同的事务回复“ok” id 和链接的内容。在第三行中,sushi要求(使用新的事务 id)wrl在目录文件 9,74/4096.6878 中查找名称“ xcolors ”。在第四行,wrl发送一个带有相应事务 id 的回复。
请注意,打印的数据取决于操作类型。如果与 NFS 协议规范一起阅读,则该格式旨在自我解释。另请注意,旧版本的 tcpdump 以稍微不同的格式打印 NFS 数据包:将打印事务 id (xid) 而不是数据包的非 NFS 端口号。
如果给出 -v(详细)标志,则打印附加信息。例如:
sushi.1023 > wrl.nfs: NFS 请求 xid 79658 148 读取 fh 21,11/12.195 8192 字节 @ 24576 wrl.nfs > sushi.1023:NFS 回复 xid 79658 回复 ok 1472 读取 REG 100664 ids 417/0 sz 29388(-v 还打印 IP 标头 TTL、ID、长度和分段字段,这些字段已在本示例中省略。)在第一行中, sushi要求wrl从文件 21,11/12.195 中读取 8192 个字节,位于字节偏移处24576. Wrl回复‘ok’;第二行显示的数据包是回复的第一个片段,因此只有 1472 字节长(其他字节将在后续片段中跟随,但这些片段没有 NFS 甚至 UDP 标头,因此可能不会打印,取决于使用的过滤器表达式)。因为给出了 -v 标志,所以打印了一些文件属性(除了文件数据之外还返回):文件类型(``REG'',用于常规文件),文件模式(八进制), UID 和 GID 以及文件大小。如果多次给出 -v 标志,则会打印更多详细信息。
NFS 回复数据包不明确标识 RPC 操作。相反, tcpdump跟踪“最近的”请求,并使用事务 ID 将它们与回复进行匹配。如果回复没有紧跟相应的请求,则它可能无法解析。
AFS 请求和回复
Transarc AFS(安德鲁文件系统)请求和回复打印为:
src.sport > dst.dport: rx 数据包类型 src.sport > dst.dport: rx 数据包类型服务调用名称参数 src.sport > dst.dport: rx 数据包类型服务回复调用名称参数 elvis.7001 > pike.afsfs: rx data fs call rename old fid 536876964/1/1 ".newsrc.new" 新的 fid 536876964/1/1 “.newsrc” pike.afsfs > elvis.7001:rx 数据 fs 回复重命名在第一行中,主机 elvis 向 pike 发送一个 RX 数据包。这是到 fs(文件服务器)服务的 RX 数据包,并且是 RPC 调用的开始。RPC 调用是重命名,旧目录文件 id 为 536876964/1/1,旧文件名 `.newsrc.new',新目录文件 id 536876964/1/1 和新文件名`。新闻频道”。主机 pike 以 RPC 回复来响应重命名调用(这是成功的,因为它是一个数据包而不是一个中止包)。通常,所有 AFS RPC 至少通过 RPC 调用名称进行解码。大多数 AFS RPC 至少有一些参数被解码(通常只有“有趣”的参数,用于一些有趣的定义)。
该格式旨在进行自我描述,但对于不熟悉 AFS 和 RX 工作原理的人可能没有用处。
如果两次给出 -v(详细)标志,则会打印确认数据包和附加标头信息,例如 RX 呼叫 ID、呼叫号、序列号、序列号和 RX 数据包标志。
如果两次给出 -v 标志,则会打印附加信息,例如 RX 调用 ID、序列号和 RX 数据包标志。MTU 协商信息也从 RX ack 数据包中打印出来。
如果给出了 3 次 -v 标志,则打印安全索引和服务 ID。
除了 Ubik 信标数据包(因为中止数据包用于表示对 Ubik 协议投赞成票),为中止数据包打印错误代码。
AFS 回复数据包不明确标识 RPC 操作。相反, tcpdump跟踪“最近的”请求,并使用呼叫号码和服务 ID 将它们与回复相匹配。如果回复没有紧跟相应的请求,则它可能无法解析。
KIP AppleTalk(UDP 中的 DDP)
封装在 UDP 数据报中的 AppleTalk DDP 数据包被解封装并作为 DDP 数据包转储(即,所有 UDP 报头信息都被丢弃)。文件 /etc/atalk.names 用于将 AppleTalk 网络和节点号转换为名称。此文件中的行具有以下形式
号码名称 1.254 以太币 16.1 ICSD 网 1.254.110 王牌前两行给出了 AppleTalk 网络的名称。第三行给出特定主机的名称(主机与网络的区别在于数字中的第 3 个八位位组 - 网络号必须有两个八位位组,主机号必须 有三个八位位组。)数字和名称应该分开通过空格(空格或制表符)。/etc/atalk.names 文件可能包含空行或注释行(以“#”开头的行) 。AppleTalk 地址以表格形式打印
网络主机端口 144.1.209.2 > ICSD-net.112.220 office.2 > icsd-net.112.220 jssmag.149.235 > icsd-net.2(如果 /etc/atalk.names 不存在或不包含某些 AppleTalk 主机/网络号的条目,则地址以数字形式打印。)在第一个示例中,网络 144.1 上的 NBP(DDP 端口 2)节点 209 正在向网络 icsd 节点 112 的端口 220 上侦听的任何内容发送数据。第二行是相同的,只是源节点的全名是已知的(“办公室”)。第三行是从网络 jssmag 节点 149 上的端口 235 发送到 icsd-net NBP 端口上的广播(请注意,广播地址 (255) 由没有主机号的网络名称指示 - 因此这是一个好主意在 /etc/atalk.names 中保持节点名称和网络名称不同)。NBP(名称绑定协议)和 ATP(AppleTalk 事务协议)数据包对其内容进行解释。其他协议只是转储协议名称(或数字,如果没有为协议注册名称)和数据包大小。
NBP 数据包的格式类似于以下示例:
icsd-net.112.220 > jssmag.2:nbp-lkup 190:“=:LaserWriter@*” jssmag.209.2 > icsd-net.112.220:nbp 回复 190:“RM1140:LaserWriter@*”250 techpit.2 > icsd-net.112.220:nbp 回复 190:“techpit:LaserWriter@*”186第一行是由 net icsd 主机 112 发送并在 net jssmag 上广播的激光写入器的名称查找请求。查找的 nbp id 是 190。第二行显示来自主机 jssmag.209 的对该请求的回复(注意它具有相同的 id),说明它在端口 250 上注册了一个名为“RM1140”的激光写入器资源。第三该行是对同一请求的另一个回复,称主机 techpit 已在端口 186 上注册了激光写入器“techpit”。以下示例演示了ATP 数据包格式:
jssmag.209.165 > helios.132: atp-req 12266<0-7> 0xae030001 helios.132 > jssmag.209.165: atp-resp 12266:0 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:1 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:2 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:3 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:4 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:5 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:6 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp*12266:7 (512) 0xae040000 jssmag.209.165 > helios.132: atp-req 12266<3,5> 0xae030001 helios.132 > jssmag.209.165: atp-resp 12266:3 (512) 0xae040000 helios.132 > jssmag.209.165: atp-resp 12266:5 (512) 0xae040000 jssmag.209.165 > helios.132: atp-rel 12266<0-7> 0xae030001 jssmag.209.133 > helios.132: atp-req* 12267<0-7> 0xae030002Jssmag.209 通过请求最多 8 个数据包(“<0-7>”)向主机 helios 发起事务 id 12266。行尾的十六进制数是请求中“userdata”字段的值。Helios 以 8 512 字节的数据包响应。事务 id 后面的 `:digit' 给出了事务中的数据包序列号,括号中的数字是数据包中的数据量,不包括 ATP 标头。数据包 7 上的“*”表示 EOM 位已设置。
Jssmag.209 然后请求重新传输数据包 3 和 5。Helios 重新发送它们,然后 jssmag.209 释放交易。最后,jssmag.209 发起下一个请求。请求中的“*”表示未设置 XO(“恰好一次”)。
也可以看看
stty (1), pcap (3PCAP), bpf (4), nit (4P), pcap-savefile (5) , pcap-filter (7) , pcap-tstamp (7)https://www.iana.org/assignments/media-types/application/vnd.tcpdump.pcap
作者
原作者是:Van Jacobson、Craig Leres 和 Steven McCanne,来自加州大学伯克利分校劳伦斯伯克利国家实验室。
它目前由 Tcpdump Group 维护。
当前版本可通过 HTTPS 获得:
Home | TCPDUMP & LIBPCAP
原始发行版可通过匿名 ftp 获得:
ftp://ftp.ee.lbl.gov/old/tcpdump.tar.Z
IPv6/IPsec 支持由 WIDE/KAME 项目添加。该程序在特定配置下使用 OpenSSL/LibreSSL。
错误
要报告安全问题,请发送电子邮件至[email protected]。要报告错误和其他问题、贡献补丁、请求功能、提供一般反馈等,请参阅 tcpdump 源树根目录中 的文件CONTRIBUTING.md 。
NIT 不会让您查看自己的出站流量,BPF 会。我们建议您使用后者。
在具有 2.0[.x] 内核的 Linux 系统上:
环回设备上的数据包将被看到两次;
包过滤不能在内核中完成,因此必须从内核中复制所有包才能在用户模式下进行过滤;
所有数据包,不仅仅是快照长度内的部分,将从内核复制(2.0 [.x]数据包捕获机制,如果要求仅将数据包的一部分复制到用户空间,则不会报告真实长度数据包;这将导致大多数 IP 数据包从tcpdump得到错误 );
在某些 PPP 设备上捕获将无法正常工作。
我们建议您升级到 2.2 或更高版本的内核。
应该尝试重新组装 IP 片段,或者至少为更高级别的协议计算正确的长度。
名称服务器反向查询未正确转储:打印(空)问题部分而不是答案部分中的实际查询。有些人认为反向查询本身就是一个错误,并且更愿意修复生成它们的程序而不是tcpdump。
跨越夏令时更改的数据包跟踪将提供倾斜的时间戳(忽略时间更改)。
除令牌环标头中的字段之外的字段上的过滤器表达式将无法正确处理源路由令牌环数据包。
802.11 标头以外的字段上的过滤器表达式将无法正确处理设置了 To DS 和 From DS 的 802.11 数据包。
ip6 proto 应该追逐标头链,但此时它没有。 为这种行为提供了 ip6 protochain 。
针对传输层标头的算术表达式,例如tcp[0],不适用于 IPv6 数据包。它只查看 IPv4 数据包
实战抓包,对于我们开发来说,抓包抓的是ip,指定端口,指定网卡,指定请求方式和协议
常用用法:(通过抓包命令抓取数据,通过web工具查看)

通过分析我们可以看到抓取的参数,我们的接口比较简单
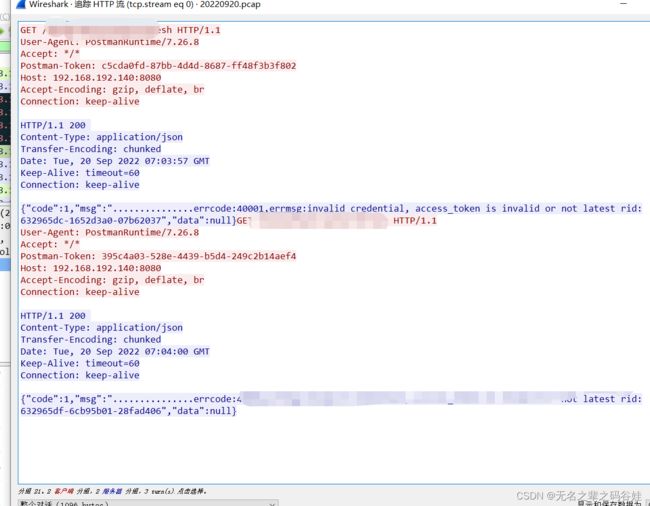
抓ip
tcpdump -i any host ip -w 20220919.cap
![]()
抓端口:
tcpdump -i ens33 port 8080 -s 0 -l -A -w /opt/20220920.pcap

抓网卡:不加-w 是直接控制台打印
tcpdump -i ens33 -w 1.pcap

指定ip和端口,网卡抓包:
tcpdump -i ens33 host 192.168.192.140 and port 8080 -e -vv -c 10 -w 20220920.pcap

这里可以配置抓包分析工具分析抓包的数据,如果你还需要调试其他的参数命令抓包,可以通过-h方式去看命令文档。
————没有与生俱来的天赋,都是后天的努力拼搏(我是小杨,谢谢你的关注和支持)