Python语言:散修笔记
文章目录
- 前言
- 转义字符的使用
-
- 原字符
- 变量的定义
- 类型转换
- 注释
- 接收用户信息
- 运算规则
-
- 整除运算
- 幂运算
- 比较运算符
- 布尔运算
- 运算优先级
- 对象的布尔值
- if else elif分支结构
- 条件表达式
- 试错pass语句
- range内置函数用法
- for in循环
- else与循环的搭配用法
- 列表
-
- 添加元素
- 切片的理解
- 修改元素
- 元素排序
- 列表生成式
- 字典
-
- 创建字典
- 通过键获取值
- 通过键名修改值
- 增加键值对
- 删除操作
- 获取字典视图
- 列表作为键值压缩成字典
- 元组
-
- 创建元组
- 元组不可变性
- 集合
-
- 集合的创建
- 集合的增删改
- 集合之间的关系判断
- 四种数据结构总结
- 字符串
-
- 字符串的驻留机制
- 字符串的查询操作
- 字符串大小写转换
- 字符串的内容对齐排版
- 字符串的劈分
- 字符串的判断
- 字符串的替换与合并
- 字符串的比较
- 字符串的切片
- 格式化字符串输出
- 字符串的编码与解码
- 函数
-
- 函数的定义与框架
- 形参与实参
- 默认参数值
- 可变参数
- 可变关键字参数
- 两者区别
- 递归函数(函数结束篇)
- 错误捕获
-
- 第一种
- 第二种
- 第三种
- 面向对象
-
- 类的定义
- 动态绑定对象属性和方法
- 继承类
- 多态的实现
- dir()
- 模块
-
- 导入模块
- 模块之间以主程序进行运行
- 包
- 文件操作
-
- 文件的读写操作
- 几种常见的打开方式
- 文件对象的常用方法
- with自动退出语句
- os重要模块
-
- os.path模块常用函数
- 结束语
前言
Python是一门非常方便省时间的语言
由我自己学过C语言的基础上来学习的时候,Python省略了很多很多的条条框框,同时又是一门面向对象的语言,所以在学习的过程中与C#非常相似。
因此,本篇文章适用于什么基础都没有的同学,但即使是这样,我还是希望各位学习一下C或Java,先难后易,Python相比于这几门确实是简单的,所以先难后易,先苦后甜会更甜。
转义字符的使用
- \ 反斜杠是最常用的,与其他语言一样的作用
- 1:\t 相当于Tab键
- 2:\n 换行
- 3:\r 回车
这个回车产生的效果是:当你在print一个字符串中间插入了一个\r,他会用\r后面的字符串将\r前面的字符进行覆盖掉。
比如:print(‘hello\rword’),输出:word - 4:\b 退格键,相当于键盘的Backspace
比如:print(‘hello\b word’) 输出:hell word
原字符
在print的引号前加一个r/R后,不管引号后面的字符串里面是否有转义字符都会将其看做一个字符,也就是完整的输出,\r就给你输出\r,没有回车的效果了
- 注意事项:不能在使用了原字符r后,在字符串后面加反斜杠\,
比如:print(r’hellossss\‘)------这样是错误的
正确写法: print(r’hellossss’)这样就是正确的,输出的结果:hellossss
我的理解是:可能使用r/R是为了直接将转义字符输出,那么你在引号前面加了一个反斜杠,电脑会自动认为那个引号也是你想要输出的,所以会编译不通过。
变量的定义
Python的变量名与其他语言差不多,都是for ,if 等等这些关键词是不能作为变量名。
- Python十分的方便,因为定义变量不需要在变量名前面加上类型名,因为在python中会自动帮你识别出来是什么类型,然后该变量名就对应了你赋值的类型。比如:name = ‘皇帝’ 该语法是正确的,没有错误,然后name就变成了字符串类型变量。
- 单引号与双引号
本质上你可以完全按照C的语法来编写Python,因为Python底层就是用C来写的。 - 三个单引号与三个双引号
该用法就是你可以在引号之间换行,在你的代码里面可以书写进行换行操作,输出的时候也会同样给你换行。
比如:‘’‘Hello
666’‘’
输出:‘’‘Hello
666’‘’
就是把你在代码里面敲的回车也进行输出。
这个功能再一个引号中是不能实现的
总结:单双引号没有区别,但是Python中与C有区别的是使用多少个引号一次性使用三次引号的能够在引号间进行换行书写内容。
类型转换
-
任何类型都能将其转换为str字符串类型
str(其他类型),然后就能直接把整个str(类型)输出 -
注意事项:在Python中使用print输出的只能为str类型,所以当你想直接输出变量名的时候要确保该变量名是str 类型否则
age = 20 print(str+age)这样是不成立的
只有将age转化为str类型才能将其输出,print(str(age))这样就能进行输出了。 -
但是当你单独直接输出print(age)是可以的,也就是说两个不同类型的不能用+连起来。
-
如果都是int类型用+号连接起来就变成了将两个数进行加法运算
-
转为int类型变量
当想要把str转化为int类型之前要检查一下str里面的内容是否是全数字,否则将不能转换。
注意:由于bool 类型是由01构成的,所以bool类型是能够直接转化为int类型的。 -
转换为float类型变量
同int类型一样,bool和字符串全为数字的时候能转为float。
int类型转为float的话就是在整数后面加上.0小数点,同理bool类型是由01构成,所以也是在01后面加上小数点。
总结:在Python中的类型转换与C语言是有着异曲同工之妙处,因为在C中将类型转换是在变量名前面加括号和类型名,如:(double)age,这样就能将age强制转换为double类型,而Python中则是直接使用类型名加括号,直接把变量放在括号里面就完成了转换。这样的转换方式在后面我相信会看到更多,比如想要看该变量是什么类型的就用type(变量名),Python中常见的方式都是用这种很直观的方式进行代码编写。
可能这也是Python创始人为什么说:“人生苦短,我要用Python”的原因了。
注释
-
使用 #
#代表在他后面的并且在同一行的内容都是注释,计算机在运行的时候会忽略里面的内容进行执行代码。 -
使用三个单引号
该方法解决了#只能进行单行注释的缺点,在同时上面讲到三个单引号在print进行输出字符串的时候使用三个单引号或者三个双引号能在里面进行换行输出。
注释中也能使用三个单引号,这时候直接使用三个单引号,里面的内容也能进行多行注释,并且计算机不会执行这些语句。 -
注意事项
多行注释不能使用三个双引号,这是不符合语法规则的,具体我这个菜逼还不知道,但是想想也有道理,人家Python都创造出来为了方便我们不用再按Shift进行双引号才能删输出字符串了,当然为了更方便点直接裸用三个单引号进行多行注释也不为奇怪。 -
#的另一种用法
在整个代码的第一行写#coding : utf-8或者其他编码方式
该意思就是当你用记事本打开你写的Python代码的时候是用什么编码方式打开的,在 第一行写上
#coding : 编码方式,
从一开始就决定了你写的代码在用记事本打开的时候是用什么编码房室结进行打开查看的。
(目前还不知道这个功能有什么用ing……)
接收用户信息
- present = input(‘皇帝你想要什么礼物?’)
input函数就是接收用户输入的一个函数方法 ,使用了该方法后会在输出端让你在键盘上任意输入,然后回车就会将你输出的内容赋值给present变量。
运算规则
print(1+1) #加法运算
print(2-1) #减法运算
print(11/2) #除法运算
print(11//2) #整除运算
print(2**5) #幂运算
运行结果:

在Python中新知识点如下:
整除运算
填写两个除号就是进行整除运算,把小数点去掉(不进行四舍五入)
但是在一正一负中,所得的结果要向下取整
解释:当在进行整除运算的时候如果出现一正一负的情况,所得的结果肯定是负数,向下取整的意思就是有小数点的话就要往更小的值去取。
比如正常除法得到的结果为-2.2:那么结果整除结果就是-3(比-2.2更小,即向下取整)
特别提醒:
!当我们用float类型进行整除的时候,出来的结果是要带小数点的,我们只是把小数点那些数给扔掉,但是我们没有把该类型的精度给扔掉,这点是很重要的。
幂运算
前面的数是底数,两个乘号后面是指数
2**5 :2的5次方 == 32
- 取模
#运算方式: 余数= 被除数 - (除数 * 商)
print(9%-4)
print(-9%4)
结果:
-3
3
这个是一个细节,因为我们都知道运算方式,但是我们在写的时候通常会忽略这个点,所以常常以为结果都是3,但其实不然。
#赋值运算符
在Python中与其他语言的赋值没什么区别,
但是多了一个就是Python能进行按系列解包赋值,说人话就是按顺序一个一个对应赋值
#按照顺序进行赋值
a,b,c = 1,2,3
print(a,b,c)
结果就是abc分别对应123三个数
- 一定要一一对应,不然值多了或者变量多了都是会报错误信息的。
- 交换两个变量的值
这个是比较震惊我的世界观的,原来Python是那么的爱惜我们的生命时间。
在通常的C语言中我们需要加入一个临时变量进行中间介才能完成交换两个变量之间的值
But在Python中,因为有了这个按系列解包赋值,能够一次性的将两个变量进行交换(不会有人不知道Python是一个语句一个语句的解释的吧)
a,b = b,a
Python直接把这条语句进行解释,就是直接将两个数进行交换了。不再需要繁琐的临时变量进行交换空间才能交换数值。十分的方便。
比较运算符
Python中与其他语言不太一样的是有一个能对ID地址进行比较的运算
- is比较运算
a = 10
b = 10
print(a==b)
print(a is b)
结果截屏:

解释:
is是通过比较两个变量的ID地址
然后如果是变量类型的数值,如果值相同但赋值给不同变量名,
在你第二个变量名赋值之前,会在计算机中寻找有没有开辟过该空间的值,
有的话就把该ID地址也给第二个变量
所以在比较ID地址的时候,如果值相同的话,ID地址也会相同
注意:当你给不同的数组或者集合赋相同的值的时候,用is将两个变量进行比较的结果是false,也就是这两个变量是不一样的,因为数组你每次开辟一个空间都会另外开一块地方给你,而不是再次在同一块地方给你进行使用,这样就是解释了每次开辟数组空间都要谨慎考虑你需要的空间是多大,而不能盲目的开辟空间。
- is not
一样的,有is就有is not 也就是比较不同,如果地址不同就返回true,与is的返回值相反,这很容易理解。
布尔运算
Python中的布尔运算与C不一样,C中是使用&&,|| 与或运算
但是在Python中与运算变成了and,或运算变成了or其实也就是更容易让人看懂,这也就是Python的魅力所在。
- and
即是C语言的&&,可以作为条件判断,同时True该条件才是正确的,但只要有一边是False就为错 - or
即是C语言的||,可以作为条件判断,只需有一边True条件便成立了,需要两边都为False才能为False - not
Python中特有的运算符,该运算符单纯是用在bool类型的运算
用来判断bool类型变量,假设该变量为False,那么not 变量判断后,该语句便是True - in与not in
见字如面,in就是里面,可以用来判断一个字符串中是否包含某些字符串或者字符 - 细说not
在Python中没有!非的说法,在C语言中我们通常你都是加一个叹号作为该条件判断的否定,但是在Python中是用not作为条件的非。因此这是与其他语言的不同之处。
ch = 'hello word'
print('hello' in ch)
#结果为True,也就是该字符串hello包含在ch字符串变量里面
- 位运算
位运算 都是使用二进制进行运算
&按位与运算:
当两个二进制数进行与运算的时候,当且仅当对应位置上都为1时,结果才为1,其他情况都为0。
下面例子是两个十进制数转为二进制数进行与运算(4和8转为二进制数)

|按位或运算:
当两个二进制数进行或运算的时候,当且仅当对应位置上都为0时,结果才为0,其他情况都为1。

<<左移:
将二级制数左移一位的时候,高位溢出舍去,低位补0,左移一位就相当于该二进制数对应的十进制数乘以2。

>>右移:
将二级制数右移一位的时候,高位补0,低位截断,右移一位就相当于该二进制数对应的十进制数除以2。

- 总结
正所谓前有高中学的左加右减,后有现在学的左乘右除
很多东西我发现都是相通的。
口诀:左乘右除
运算优先级
算术运算符 > 位运算符 > 比较运算符
对象的布尔值
在Python中万物皆可对象,因此都有对应的True或者False值,所以Python中内置了一个函数bool(对象),用来判断是否为真值或者假值。
- 所有0、None、空的集合字符串或者空元组都为False值。
- 其余的都为True值
if else elif分支结构
在Python中的循环结构和函数结构都没有大括号的。
例如在if结构中:
- if(条件) :
(Tab缩进)
在Python的结构就是使用冒号然后结构体就是使用一个缩进来区分该部分是属于if语句的结构。 - if else结构
同理,在if后需要加冒号,然后属于if的代码就用缩进来区分,
这样在else也是一样,else另起一行,然后属于他的部分也要用缩进进行区分。 - elif
在Python中的elif的意思是和C语言中的if() else if()的意思是一样的,Python中只是更加简化方便了,同样需要加中=括号条件和冒号,代码中属于哪一部分的同样需要 缩进。
#提问成绩
grade = int(input('请输入你的成绩:'))
if(90<=grade<=100):
print('你的等级为A')
elif(grade >= 80 and grade <= 89):
print('你的等级为B')
elif(grade >= 70 and grade <= 79):
print('你的等级为C')
elif(grade >= 60 and grade <= 69):
print('你的等级为D')
elif(grade >= 0 and grade <= 59):
print('你在学什么?')
else:
print('你输的是哪门子的成绩?')
细节小知识点
- 这里需要提一个点,在Python中的范围能和我们平时学的数学区间一样写,只有Python能这样,其他都不行。
例如上面的例子:if(90<=grade<=100):该语句是成立的。也只有Python能这样写
条件表达式
Python中的条件表达式有点类似于C语言中的三目运算符
- 结构如下:
语句1 if(条件判断) else 语句2
解释:如果IF条件满足,那就执行语句1,否则执行语句2
条件判断可以不用加括号也符合语法规则
#条件表达式
num1 = int(input('请输入第一个数字:'))
num2 = int(input('请输入第二个数字:'))
print(str(num1)+'>'+str(num2) if (num1 > num2) else str(num1)+'<'+str(num2))
试错pass语句
该语句是纯纯的一个万能不报错占位符,也就是说该pass部分我还没想好怎么写的时候我可以先用pass占个位置,等我运行的时候也不会报错,让我想好了怎么写了再把pass去掉,填上自己要写的代码。
这通常用的一个结构语句中,例如if else ,if之后的执行的代码我还没想好我就可以填一个pass进去充当占位符,如果不填就会报错。
n1 = 5
n2 = 6
if(n1 > n2):
pass
else:
pass
这样就是pass的作用,目的很简单,给你占个位置,啥也不执行,但就是不会给你报错,这就极大地利于我们在写一个项目的时候,搭建框架的时候非常有用。
range内置函数用法
- 包含一个参数
range(结束范围)
解释:只给一个参数的range函数就是默认从0开始创建,两个数之间的步长(距离)也默认为1。
即从0一直创建一组数到结束范围 - 包含两个参数
range(start, end)
很明显了,明白了包含一个参数的,这个就很容易理解了
很显然就是给了一个开始和结束的范围,但同样默认的步长为1 - 包含三个参数
range(start, end, SupportsIndex)
前面都提到了步长,但是都没有能修改默认值,因此第三个参数就是为了修改步长的
#range内置函数
#只给一个参数,即一个结束范围,不包含该参数,默认从0的闭区间开始,10为开区间
r1 = range(10)
print(r1)
print(list(r1)) #list是一个列表,将r1中的数字都列出来
#给两个参数,即一个区间范围
r1 = range(1,10)
print(r1)
print(list(r1))
#给三个参数,前面两个为区间范围,第三个参数为步长,前面两个的步长都为1,也就是两个数字之间的间隔是1
r1 = range(1,10,2)
print(r1)
print(list(r1))
- 需要说明的细节
使用range的时候无论你创建多大的数,即使你给一个10000与你只给一个10的范围,这两个使用range的函数在计算机中存储的空间是一样的,因为range只是给了三个参数而已,当你真正用到的时候才会占不一样的内存。
for in循环
该循环有点像C#中的foreach
在C#中foreach : 循环参数(var item in 对应的集合)
然而在Python中的for in里面他是这样操作的
for item in 集合
该集合可以是一串字符串,那么item提取出来的便是一个个字符
例如:
for item in 'Python'
print(item)
#该操作就是从Python中一个一个字符提取出来然后赋值给item将其输出。
可以结合前面学习到的range函数,将其中所创建的数字都按照顺序一个个输出出来
for i in range(10)
print(i)
#该代码执行的操作就是将range作为一个集合,然后把集合中的元素将其输出打印
- 常用的for in用法
for _ in range(5):
print('皇上驾到!')
结果:
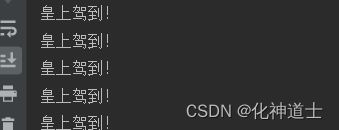
#当我们不需要有一个变量进行输出的时候我们就用下划线代替变量名,然后用range作为循环体执行次数,因为在range中他是左闭右开区间,所以5是不包含的,但是又因为是从0开始,所以他还是会执行5次,这也是为什么在C语言中,经常有大佬提倡在for循环的执行次数中秉持着从0开始的执念。
else与循环的搭配用法
-
当我们使用for in 和while 的时候,在循环结束不是用break退出的时候就能进入到else的语句执行代码。
解释:
for in:
…
…
else
假入你的for in循环中,退出循环的是集合中的元素都扫描过了,也就是正常条件退出的时候就不会执行else语句里面的代码。
但是如果在循环中退出是因为进入了break语句才强行退出的话,那么在退出循环后就会进入else语句里面执行代码体。
打个比喻:当你正常在考试中按照时间交卷退出考场的话就没人会理你,也没人会找你,但是当你还没到考试结束时间你就退出了,那么肯定会有监考老师来问你,那么这个else干的就是监考老师这个事情。 -
同理在使用while循环体与else搭配也一样的效果
代码如下:
#else与循环搭配使用
#与for in搭配
for item in range(3):
if(input('请输入密码:') == '8888'):
print('密码正确!')
break
else:
print('密码错误')
else:
print('三次密码均错误!五分钟后再次操作')
#与while搭配使用
time = 3
while time > 0:
pws = input('请输入密码')
if(pws == '8888'):
print('密码正确')
break
else:
print('密码错误')
time-=1
else:
print('三次密码均错误!五分钟后再次操作')
列表
创建列表的两种方式
- 直接用 [填写元素,元素之间用逗号隔开]
- list([填写元素,元素之间用逗号隔开])
- 以上就是创建列表的方式,但创建完了需要用一个变量名来接收该列表的ID地址。
解释:该列表本身有一个ID地址,然后里面的元素存的都是每一个元素对应的地址,也就是可以说该列表是一个存放各种ID地址的列表,所以他能包罗万象,你想放什么元素类型都可以。
列表切片
定义了一个列表变量名后就可以使用列表切片
lst = [10,20,30…]
- lst [ startindex : endindex : step ]
- 冒号必须要写山去,三个参数按照自己的需求写上去,可以不写
- 默认参数通常都是以你的列表收尾元素下标
A: 当你的step步长是正数的时候
start就是0,end就是列表最后一个元素下标
B: 当你的step步长是负数的时候
start就是列表最后一个元素下标,end就是0
#列表的步长
lst = [10,20,30,40,50,60,70,80]
print(len(lst))
print(lst.index(50))
#切片,步长均为正的情况下
print(lst[1:5:1])
print(lst[:5:1])#默认start下标0
print(lst[1::1])#默认end下标7-即结束的下标
print(lst[::2])#开始和结束下标均默认
print(lst[2:5:])#默认步长为1
#切片,步长为负的情况下
print('--------步长为负-----------')
print(lst[::-1])
#当步长为负数的时候,你就要把start和end下标两个对换一下,因为步长负数需要从start开始减
#因此步长为负数的时候就默认start从末尾开始,end下标从0开始
添加元素
- .remove
在列表这个对象中使用一个列表类带的方法.remove就可以使用,
该功能是将你输入的元素进行删除 - .pop
在列表对象中使用pop函数,该功能是按照你输入的下标进行删除,只能删除单个,如果不输入下标的话会默认删除最后一个元素,因为这是数据结构中的栈的用法,所以pop会把后来的元素先出栈。 - 使用切片
list列表变量名使用中括号然后像上面的切片操作一样,把两个必须要写的冒号打出来,两个参数表示的是你要切的范围大小,还有step步长。 - 删除还有另外一种切片方法
不是说切片是切出来一块进行操作吗,那我就把切出来那一块进行赋值,全都给[]空列表,这切出来的就相当于被删除了,因为是空的,然后进行打印的时候不会把空列表打印出来。 - del删除列表对象
del lst 就是直接把你改列表对象变量给删除掉了,后面就不能继续使用了。
代码如下:
lst = [1,5,6,9,8,4]
lst.remove(5)
#lst.pop()#如果不给pop的要删除的下标的话默认会自动删除掉最后一个元素
#lst.pop(3)#表示要删除的元素为下标为3的元素
#使用切片进行切块删除
#切片是按照一块一块的切,把你需要留下的切下来
#比如我需要把下标为0~3的元素留下,把剩下的删除掉
print(lst[0:4])
lst2 = [20,30,40,50,60]
lst2[1:3] = []#将空列表赋值给切出来的这一块元素,就变成了删除这几个元素的操作了
print(lst2)
切片的理解
切片这个词语不仅在代码中出现,在PS中我也是有用,其功能是一样的,都是把一个对象切块。
比如在Python中切片就是在给出的范围内进行切片,将该范围的元素切出来,所以切片操作就能够当作是添加元素也能用来删除元素。
添加元素则需要两个列表,就是在另一个列表上切出一块来,然后补到你想要加入元素的列表中。
总而言之:切片就是将列表一块地方切出来,怎么操作还是取决于你的怎么写。
修改元素
也是使用切片,也可以不用,直接用下标找到你要修改的元素直接修改就好了。
lst = [1,6,59,614,6664,94,8]
#使用切片切出来,然后对着块地方进行修改
lst[2:5] = [55,555,5555]
print(lst)
元素排序
Python中非常方便,这些排序方法根本不用我们自己写,只需要记住有这个方法就行,英语稍微好点的一看就知道是干嘛用的了。
- 列表类自带的方法 sort
能进行两种方式,一种是正序另一种是逆序 - Python中内置的函数 sorted
同样能进行两种方式,正序逆序排序
如果不特殊说明是reverse = True的话,默认为正序排序。
#列表排序
#lst.sort()#直接使用列表中带的方法,从小到大排序,排正序
#lst.sort(reverse=True)#排序将变成逆序排序,同样如果不写False就会默认为True
#new_lst = sorted(lst) #使用内置函数进行排序,该排序是正排序,从小到大
new_lst = sorted(lst,reverse=True) #逆序排序,从大到小
print(new_lst)
列表生成式
结合着for循环和range内置函数搭配使用就是列表生成式
就是在中括号中使用range函数生成一个元素范围,然后使用for循环用一个i变量把range中的元素提取出来,然后再把那个变量放在中括号第一个位置就是相当于把该变量放在了列表中。
看下面实战代码:
l = [i for i in range(1,6)]
print(l)
l2 = [i*2 for i in range(1,6)]
print(l2)
字典
创建字典
该字典其实就相当于hashtable,在C#中有用到过,其实说白了也是通过键值对查找相应的值。
在Python中我发现键的定义必须是字符串(第二种创建方式有小小出入),然后键对应的值就可以是任意类型的。
需要注意的是,键值对是用冒号隔开的,左键右值
- 第一种创建字典方式
直接使用大花括号创建,和创建列表的形式也一样,直接给出一个变量名来接收该字典。键必须是字符串形式。 - 第二种创建字典方式
通过内置函数dict()进行创建。
重点:括号内虽然不需要花括号和冒号,但是他需要用赋值号将键和值对应起来,在第二种方式中键名必须是变量名,但是在print输出字典的时候还是会转换为字符串形式,因为刚刚说了键必须是字符串形式,在用键寻找相应值的时候,也要把该变量名作为字符串来找对应的值。
解释:首先必须接受的事实就是键的类型必须是字符串,在第一种直接创建方式中就很直接明了,字符串键对应一个值。
其次,在第二种方式中,键类型不能直接是字符串形式,而是通过变量名形式加一个等号表示该变量名对应该值,为什么说第二种方式键也是字符串呢,因为我在将整个字典输出的时候发现是以字符串形式输出的,并且在寻找值的时候,用的也是键的字符串形式。
通过键获取值
- 第一种方式:字典变量 [ ‘字符串键名’ ]
直接使用中括号,里面填写相应的键,就能获得该键对应的值 - 第二种方式:使用字典对象的方法 . get(键名),其中有两种重载方法
比如:字典名为dit
一个参数:
那么dit.get(填写键名)
这样就能直接获得字典里对应的值了
两个参数:
dit.get(键名,值)
填写两个参数原因是因为假如你填的键名根本就没有的时候不让他报错,假设你给的键名为空,那么你填一个参数,只填一个键名就会报错。
所以有时候不知道具体有没有该键名时候为了严谨一点,会选择再填写多一个键值以防报错。
代码如下:
#创建字典的第一种方式
#键的命名必须是字符串形式
dit = {'张飞': '646', '关羽': 20, '刘备':60,'李白':99}
print(dit)
#第一种通过中括号输入键找到值,就像列表通过下标找数值一样
print(dit['张飞'])
#当你输入的键是不存在的,那么就可以输入第二个参数作为该不存在的键的值
print(dit.get('皇帝', '万众瞩目'))
#创建字典的第二种方式
#键的命名必须是变量名形式,但是输出的时候会自动变为字符形输出,因此在用键查找的时候依旧是用字符串形式进行查找
dit2 = dict(age=20,name='汤姆',s = 20)
print(dit2)
print(dit2['name'])
- 如何遍历字典
使用for循环遍历的是字典的键名,通过键名我们使用获取键值的方法获取元素,也就是上述所说的获取值的两种方法都可使用。
for item in dit:
print(item,dit.get(item))
通过键名修改值
- dit[键名] = 修改值
该方法就是上面的获取谋个键值方法,现在修改也就是获取到相应键后,通过键来直接修改键值。
增加键值对
- 注意:上面这种修改方法包含了键名不存在情况,也就是说假如键名不存在,就会给你创建一个,然后在字典尾部给你加上去。这也是一种增加键值的方式。
删除操作
- del dit[填入相应的键名]
该方法就是删除单个键值对 - dit.clear()使用字典自带的方法
将字典里面所有元素清除掉
修改,增肌,删除操作代码如下:
dit = {'张飞': '646', '关羽': 20, '刘备':60,'李白':99}
print(dit)
#通过找到键名修改键值
dit['张飞'] = 65
print(dit)
#如果没有找到该键名就会自动创建该键名,然后把该键值赋值进去
dit['皇帝'] = 520
print(dit)
#删除
del dit['张飞'] #删除单个键值对,通过填入键名,将其键值对都删除掉
#dit.clear() #该方法是清除字典里面所有键值对
print(dit)
获取字典视图
-
获取键组,dit.keys()
-
获取值组,dit.value()
-
获取键值组,也成元组,dit.items()
代码如下:
dit = {'张飞': '646', '关羽': 20, '刘备':60,'李白':99}
print(dit)
#获取键组
key = dit.keys()
print(key,type(key))
#获取值组
value = dit.values()
print(value,type(value))
#获取键值组,也成元组
item = dit.items()
print(item,type(item))
运行结果截图:

列表作为键值压缩成字典
- 键列表类型必须是字符串
- 值列表类型可以随意
假设:键的数量与值的数量不一致,那么计算机会自动以最少个数的作为基准,把多出来的丢掉,剩下能匹配的就组成字典。
#键
item = ['张飞','皇帝','李白']
#值
value = [5,999,999,123456]
#使用列表,将两个列表压缩为一个字典。一个作为键,另一个作为值
dit = {item : value for item,value in zip(item,value)}
print(dit)
假如你的键item为字母,但是你想全部变为大写形式,只需要修改一个地方即可,其他地方不用修改。(因为我的键全是中文,所以我没用.upper)
修改地方:dit = { item : value for item,value in zip(item,value)}
将 item 改成 item.upper() ,那么就变成了
dit = { item.upper() : value for item,value in zip(item,value)}
元组
创建元组
- 第一种方式,直接在小括号内创建
前面的列表和字典创建方式都有直接加中括号和花括号,在括号内填写元素就创建好了,那么在元组中也是一样,只不过元组创建的括号是用小括号。 - 使用第一种方式的时候,也可以不用加小括号,但是前提是元素之间要用逗号隔开,然后计算机会自动识别你正在创建元组。
当你只有一个元素的时候,不管你是否有小括号,都要在第一个元素后加一个逗号区分,让电脑知道你不是在赋值而是在创建元组。 - 第二种方式,使用内置函数tuple
就是直接使用就好,但是在tuple()的括号内还要再加一个小括号才能进行创建元组。我的理解是:因为在tuple中本身是一个函数,传参创建元组那必须是传一个元组才算是传元组参,不然不加小括号就以为你传的是多个参数。其实就是传一个元组进去,我们创建元组就是用小括号的。那么其实就是相当于该内置函数可以传一个数据结构堆进去,即我们可以传一个列表,传一个字典进去。
#创建元组方式
#第一种方式
#元素使用小括号
t = (5,4,9,3)
print(t, type(t))
#假如只有一个元素,需要加一个逗号加以区分你创建的是一个元组,不然会自动认为你该一个元素为一个类型变量值
t1 = (5,)
print(t1,type(t1))
#也可以省略小括号的方式创建元组
t2 = 5,
print(t2,type(t2))
#第二种方式
#使用内置函数tuple,但是记得要在括号内创建元组时候也要加小括号,否则会报错
t3= tuple((5,8,96,'皇帝'))
print(t3,type(t3))
#传列表进去创建一个元组元素为列表的元组
t4 = tuple([1,2,3,4])
print(t4)
元组不可变性
- 元组是不可变的,只要想通过下标或者想要操作增删改操作都是行不通的。
- 我们的元组不可变,但是我们元组中的元组假如是可变的,那么我们能间接的修改元组。
比如:我的元组一个元素是列表,由于列表是可变的,所以通过下标找到列表元素,可以在列表中进行增删改。
#元组是不可变的
t = (6531,[13,65,1],'皇帝',1.2)
print(t)
#我们不能直接修改元组中的元素
print(t[2])#通过下标元素访问元组中的元素,但是不能通过获取元素方式修改元素值
#元组不可变,但是我的元组元素是列表,我的列表可变
t[1].append('新来的')
print(t)
集合
- 什么是集合
集合即元素的总汇,可以是不同类型的元素汇聚在一起为集合。
所以在创建集合的时候可以由不同数据类型放在一个集合中。 - 上述学过的列表,元组,字典都属于数据的集合,同样他们可以转换为集合。这时候要使用内置函数set
集合的创建
- 直接创建
与上面的数据结构直接创建方式一样。直接使用花括号,填充元素即可。 - 与字典的区分
首先字典是键值对,需要手动把键和值对应上,同样也是花括号。
二者区分就是看有没有键值对。 - 使用内置函数set
注意事项: 使用set内置函数时不能够传多个参数,只能是传一种集合,比如你传列表、字典、元组,并且只能传一个,不能传两个或多个列表、字典、元组。 - 字典作为元素集合传进set内置函数会发生什么
使用内置函数set把字典传进去的时候,输出该集合的时候,会把字典中的键输出出来,
这就解释了为什么集合也用花括号,因为在创建集合的时候,这些元素可以认为是键,但是没有值,所以当我们把字典传进去的时候会把键筛选出来作为集合元素,然后把值丢掉。 - 集合与字典一样,字典中是键不能重复,那么集合中的元素又是键组成的,自然是不能重复,计算机会自动帮你把重复的覆盖掉,只留下一个进行输出。
#集合的创建
t1 = {1,5,'jackson',4.0}
print(t1)
#输出后发现顺序乱的,说明了集合是无序的,每次输出都有不一样的结果
#使用set内置函数传参只能传一种数据结构,或者传一组不含数据结构的元组
t2 = set([1,5,8,'我是列表'])
print(t2)
t3 = set({5,8,9,6,'我是字典'})
print(t3)
#不允许多个参数,只允许传数据结构进去并且只能有一个数据结构
#将字符串变成一个一个字符,然后存到集合中,因为字符串本身就是一个字符的集合
t4 = set('python')
print(t4)
#使用set用元组创建集合
t5 = set((4,5,6,'我是元组'))
print(t5)
#空集合
#t = {} #这样不是空集合,因为空字典已经这样定义了,所以我们要用内置函数set来定义空集合
t6 = set()#什么都不写就是空集合
print(t6,type(t6))
t7 = set({'张飞': '646', '关羽': 20})
print(t7)
#把键作为集合元素输出,值丢掉
集合的增删改
元素的增加:
- 由于集合可变,所以可以进行增删改操作
- 增加元素,集合名. add()
该方法只能一个一个的添加,不能一次性添加多个,所以也不能添加数据结构 - 集合名. update()
该方法解决了前面add只能添加一个的弊端,该方法可以添加多个元素,也可以添加一个元素,但是前提是你要给定一个数据结构传进去,该数据结构可以是多个元素也可以是一个元素,这样就实现了自由添加元素个数了。 - 两个方法都是只能传一个参数,第一个是只能传一个元素,第二个是只能传一个数据结构。
#集合的创建
t = {1,5,'jackson',4.0}
print(t)
#集合的添加
#使用集合自带方法add,添加一个元素,不能添加多个或者数据结构,因为数据结构里面可能包含不止一个
t.add(999)
print(t)
#使用update方法,可以添加一个数据结构,但是不能把多个元素拆开传进去,因为
t.update({1,5,8,9})
print(t)
元素的删除:
- 集合名. remove()
移除集合中特定元素,只能删除一个。
假如集合中没有该元素则会报错。 - 集合名.discard()
移除集合中特定元素,只能删除一个。
假如集合中没有该元素,不会报错。 - 集合名.pop()
随机弹出一个元素,也相当于删除一个元素,这与C语言中栈的弹出一样,能知道弹出的元素是什么,返回值就是弹出的元素。
不允许写入参数,.pop()方法因为集合的元素是随机排序的,每一次运行都不一样,所以在弹出中也是随机的,每次运行之后谁排在后面就谁被pop出来。 - 集合名.clear()
清除集合中所有元素
#集合的创建
t = {1,5,'jackson',4.0}
print(t)
#集合的删除
#删除特定的元素,假如没有该元素则会报错
t.remove(1)
print(t)
#删除特定元素,假如没有该元素不会报错
t.discard('元素不存在')
print(t)
#随机弹出一个元素,也就是删除
print(t.pop())
print('弹出随机一个元素后的集合是:',end='')
print(t)
#删除所有元素
t.clear()
print(t)
集合之间的关系判断
- 集合之间是否为子集关系,集合名1.issubset(集合2)
解释sub:我在C#中学习字符串函数的时候,有一个函数名也有该关键词,就意思是把字符串截取你想要的那部分。
因此在这里同样也是,假如集合1是集合2的截取部分,那么也就是说明集合1是集合2的子集。 - 集合之间的关系是否为超集,集合名2.issuperset(集合1)
解释:判断子集关系是用小的判断,可能开发者为了方便能使用大的来判断就写了这么一个函数,就是判断大的是不是小的超集,也就是和判断子集关系反过来了,假如像集合1是集合2的子集,那么反过来集合2就是集合1的超集,所以反过来使用issuperset的时候就会返回true。 - 集合之间的关系是否有交集,集合名3.isdisjoint(集合4)
很容易理解,就是纯纯判断两个集合之间有没有相同的元素,但是需要注意的是该函数判断的是两个集合之间是没有交集关系,如果没有交集就返回True,如果有就返回False。
解释:因为函数名很简明的说了 is dis 就是表示判断不是,dis就是否定的意思。
示例代码如下:
s1 = {1,2,3,4,5,9,55,7,6}
s2 = {1,3,4,2}
s3 = {5,6,9,7,1}
s4 = {5,6,9}
#判断是否为子集,只要元素相同就行,小的是大的子集,否则不能
print(s1.issubset(s2)) #s1是否为s2的子集
print(s2.issubset(s1)) #s2是否为s1的子集
#sub这个词在C#中出现过,是截取字符串的函数名中出现,所以我的理解是is sub意思是:s1是截取在s2中,是就返回true否就false
#判断是否为超集,超集就是和判断是否为子集相反,大的就是小的超集,小的是大的子集
print(s1.issuperset(s2))
print(s2.issuperset(s1))
#判断是否 没有 交集,判断的是没有交集,如果没有就返回true,有就返回false
print(s3.isdisjoint(s4))
print(s2.isdisjoint(s4))
四种数据结构总结
- 列表list、字典dict、元组tuple、集合set
- 列表list 使用中括号[ ]
列表的创建、增加、修改、删除
内置函数list[ ] - 字典dict 使用花括号{ }
字典是一种键值对数据结构,一个键对应一个值,
存储的时候就是一对一对的存。
字典的创建、增加、修改、删除
内置函数dict{ } - 元组tuple 使用小括号( )
元组的创建,但是元组是不可变序列,所以不能进行增删改操作
但是可以对元组中列表元素或者字典元组进行增删改,这相当于是间接修改元组,但实质上元组是不能进行修改操作。 - 集合set 使用花括号{ }
集合的创建、增加、修改、删除
集合之间的数学关系
内置函数set { }
与字典区分:字典是键值对,但是集合只有键没有值,集合存下来的元素其实就是键。 - 我的总结:
1:首先是我认为列表、字典是比较细分的数据结构,为什么这么说呢:是因为在元组中能使用内置函数tuple传参传一个列表进去或者传一个字典进去,就相当于是一个元素为列表或字典的元组,而这些列表和字典中又不止一个值(字典中不会把值传进去,只会把键传进去)。
2:其次,在实验过程中摸索到,在列表创建的时候可以把列表作为列表元素放进另一个列表中,实现套娃功能。在字典中就不可以,因为字典需要的是键值对,一个字典传进去之后就不是键值对了,字典创建中必须严格遵守-----键:值-----,所以如果你传一个字典就去就毁掉了该创建方式。
3:比元素还大的我认为是集合,这几种数据结构都是能用在创建集合里面。
比如在创建一个集合的时候我可以使用内置函数将一个元组或者字典又或者是列表作为一个参数传进去,记住使用内置函数的时候只能传一个参数。元组可以作为一个参数,列表也可以作为一个参数,同样字典也可以作为一个参数。 - 注意事项,假如你把字典作为参数传进集合中,集合会单单把字典的键作为集合的值,而不会把字典的值放进集合里面。
补充:
集合生成式
与列表生成式一模一样,只是把中括号[ ]改成花括号而已。
s = {i for i in range(5)}
print(s,type(s))
字符串
- 字符串是一个不可变序列
字符串的驻留机制
- 字符串驻留机制解释
当一个字符串被创建出来后,在计算机一个存储池中留着,当你再次创建的字符串如果与该存储池中的某个字符串相同的话就不会继续给你开一个空间让你创建一个一模一样的字符串,继续给该字符串的ID地址,该机制大大减少了空间浪费。 - 需要说明的几点
1:在交互式中字符串驻留机制就显现的特别明显,然而在Pycharm中因为被优化过,所以有些是在交互式中不能是同一个字符串的,在Pycharm中也算是发生了驻留机制。
2:下面我将使用交互式来演示驻留机制如何发生的,哪些情况是不发生的。
发生驻留机制的几种情况:
-
符号标识符的字符串
当你赋予两个变量不符合标识符的字符串,即使两个变量字符串相同,也不会产生驻留机制,也就是说浪费空间,你用两个不同的空间存了两个相同的字符串。
举个栗子:
当你比较二者地址的时候明显是返回一个False,表示不一样的空间。
(因为我这里的减号为不符合标识符的字符串。)

-
字符串长度为0或者1的时候
该条件适用于当你输入了不符合标识符的字符的时候用,因为有些时候就是想存一个标识符作为字符串,比如存一个减号加号之类的,这时候字符串长度为1,即使是不符合标识符的也能发生驻留机制,将相同的字符串保留一份,无须再创建多一份。

字符串的查询操作
- 主字符串A变量名.index(‘要查找的字符串B’)
该方法是在主字符串A里面寻找B字符串首字符的下标位置。
返回下标位置 - 主字符串A变量名.find(‘要查找的字符串B’)
该方法是在主字符串A里面寻找B字符串首字符的下标位置。
返回下标位置 - 主字符串A变量名.rindex(‘要查找的字符串B’)
该方法是在主字符串A中从尾部开始寻找B字符串首字母下标位置。
返回下标位置 - 主字符串A变量名.rfind(‘要查找的字符串B’)
该方法是在主字符串A中从尾部开始寻找B字符串首字母下标位置。
返回下标位置。 - index与find的区别
如果寻找的字符不存在,那么这时候就会有差别了。
假如使用index寻找一个不存在的字符,就会报错,然而使用find就不会
所以我们一般会使用find比较多。
同理加上r也一样,就是rindex与rfind的区别也是一样的。
字符串大小写转换
为了方便解释,设a为字符串
-
a.upper()
把字符串中的所有字母转换为大写 -
a.lower()
把字符串中的所有字母转换为小写 -
a.swapcase()
把字符串中的小写转为大写,大写转为小写。
(就是反转一下) -
a.capitalize()
把字符串中的首个字符转为大写,剩余的就转为小写 -
a.title()
把字符串中的每个单词的首字母都变为大写,然后单词首字母后的都转为小写 -
需要说明的细节
当我们转换后的字符串是会产生一个新的字符串对象,也就是说不再是原本的那个字符串指向的地址,即不是原字符串了,而是给你开辟了一个新的空间地址存放该转换后的字符串。
上面的转换都会产生这样的效果。
实验代码如下:
s = 'Hello,Python'
#字母的大小写转换
#全部字母转换为大写字母
s2 = s.upper() # 转换后会产生新的字符串空间地址存放
print(s,id(s))
print(s2,id(s2))
#全部字母转换为小写字母
s2 = s.lower();
print(s,id(s)) # 转换后会产生新的字符串空间地址存放
print(s2, id(s2))
#大小写字母相互转换,即在字符串中小写变大写,大写变小写
s2 = s.swapcase()
print(s2,id(s2))
print(s,id(s))
#字符串中首字母转为大写后,后面的不管怎样其他都为小写
s2 = s.capitalize()
print(s2,id(s2))
print(s, id(s))
#字符串中每个单词的首字母转换为大写,单词首字母后均为小写(区别于capitalize)
s2 = s.title()
print(s2,id(s2))
print(s,id(s))
字符串的内容对齐排版
为了方便我们设字符串为a
- 食用提醒
如何对齐,就是按照你第一个参数给出的长度范围。
假如给的参数长度小于字符串长度就直接返回原字符串,没得对齐了。
第二个参数是填充符号,就是把字符串放进去后剩下来的长度就用第二个参数进行填充,假如不填,就默认为空格。
下面所有的函数都是一样的,都按照参数一给出的范围对齐。
长度不够也是直接返回原字符串。
第二个参数特性也是一样的,只有一个函数是不允许填第二个参数。具体下面会说明。
下面我就不再赘述了。记住都有这些特性就就行。 - a.center(参数一,参数二可填可不填)
见字如面,center就是字符串居中对齐。 - a.ljust(参数一,参数二可填可不填)
left左对齐 - a.rjust(参数一,参数二可填可不填)
right右对齐 - a.zfill(参数一)
用0填充,进行右对齐。
该方法不用填写第二个参数,因为该方法就是用0来填充进行右对齐。 - 有关a.zfill()方法的细节说明
该方法有一点很神奇,就是假设你的字符串首个字符是加减号的话,你进行a.zfill()方法的时候,那些0会在加减号后面进行填充。
我目前为止实验的符号只有加减号会发生这种情况。
实验代码如下,里面我写了关于zfill对于加减号的特殊情况发生的代码,可以试着多次换符号进行实验。(如有发现除了加减符号也能产生该情况的话务必私信我,感谢大佬们)
#输出格式排版
s = 'hello,python'
#居中对齐
#第一个参数必填:表示该字符串按照多少个位置居中对齐
#第二个参数非必填:表示填充的符号,不填写就是默认为空格
#假如第一个参数小于字符串长度则直接返回原字符串
print(s.center(20,'*'))
#左对齐
#第一个参数必填:表示该字符串按照多少个位置左对齐
#第二个参数非必填:表示填充的符号,不填写就是默认为空格
#假如第一个参数小于字符串长度则直接返回原字符串
print(s.ljust(20,'&'))
#右对齐
#第一个参数必填:表示该字符串按照多少个位置右对齐
#第二个参数非必填:表示填充的符号,不填写就是默认为空格
#假如第一个参数小于字符串长度则直接返回原字符串
print(s.rjust(20,'$'))
#右对齐,用0填充
#如果加减号在字符串第一个位置,则0会填充到加减号后面
#只能填一个参数,因为填充符号固定了
s2 = '+jj'
print(s2.zfill(20))
字符串的劈分
为了方便设a为字符串变量
-
食用提醒
下面的函数参数有最多有两个。
首先第一个参数为分隔符,即一个字符串中,你按照哪个分隔符进行分割
分割完成后就返回一个列表,把你分割好的做成一个列表形式返回。
分隔符参数名为:sep
分割个数参数名为:maxsplit
所以在写参数的时候可以用sep=‘’的形式来写,也可以不写出参数名,直接填写分隔符和分割个数,二者一样。(代码中我都写出了几种情况) -
a.split(参数1,参数2可写可不写)
表示从字符串开始分割,遇到参数一填写的字符串分割符就分割开,直至字符串结束,把分割好的几部分以列表的形式返回。 -
a.rsplit(参数1,参数2可写可不写)
表示从字符串尾部开始分割,遇到参数一填写的字符串分割符就分割开,直至字符串的头部结束,把分割好的几部分以列表形式返回。 -
两个方法的区别
显而易见的区别就是分割的顺序不一样,split一个是从左到右分,rsplit另一个是从右到左分
最本质的区别就是当你规定了分割个数之后,区别就非常大,可以运行下我下面的代码。两个字符串明显分割的部分不一样了。
试验代码如下:
# 字符串的劈分
#使用split,分割字符串内容,返回的是列表。
#参数是分割字符串的标识符,就是按照你传参的该字符进行分割,字符串中遇到该字符就分割,然后该字符不列在元素当中,仅当为分割符
s = 'hello|word|python'
print(s.split('|'))
print(s.split('|',1))
print(s.split(sep='|'))
print(s.split(sep='|',maxsplit=1))#写出sep参数等于多少(即分隔符是什么),与不写是一样的。同理maxsplit写不写也是一样的效果。
#使用rsplit从尾部开始分割
s1 = 'hello|love|me'
print(s1.rsplit('|'))
print(s1.rsplit('|',1))
print(s1.rsplit(sep='|',maxsplit=1))
字符串的判断
为了方便就设字符串变量为a
- a.isidentifier()
判断该字符串是否为合法标识符
identify就是鉴别的意思,在代码中鉴别标识符 - a.isspace()
判断字符串是否全部都由空白字符组成
(如:回车、换行、水平制表符) - a.isalpha()
判断该字符串是否全为字母组成 - a.isdecimal()
判断该字符串是否全部由十进制数字组成 - a.isnumeric()
判断该字符串是否全部由数字组成 - 补充说明.isdecimal()与.isnumeric()
因为Python中一般是由Unicode编码的,区别就在这里,有些别国数字分别用这两个判断数字的话就会产生不一样的结果 - a.isalnum()
判断该字符串是否全部由字母和数字组成
看该方法的命名就知道了,al表示前面判断字母的isalpaha,num表示前面判断数字的isnumeric,组合起来就是alnum,既判断字母又判断数字。
该模块很难简单,基本面向对象语言都有该功能函数,就不进行代码实验了。
字符串的替换与合并
为了方便设字符串变量为a
- a.replace(参数1,参数2,参数3可填可不填)
参数1是从a字符串中找到该字符串,然后用参数2字符串进行替换。
特别说明,参数3是表示替换的次数,假如说你a字符串中有多个参数1的字符串,那么参数3就可以控制替换的次数。(从左到右开始替换)
假如a中没有参数1的字符串进行替换的话就a的原字符串保持变。 - 分割字符串.join(参数为列表、元组)
实质是把一串元素进行合并
该方法是为你传进来的参数服务的,使用分割字符串点出来一个函数方法join然后用该分割符把传进来的列表、元组中的元素进行衔接起来。
==注意事项:==该方法除了列表和元组,集合和字典都不能将其用该方法衔接起来。字典很明显不能用该方法,因为是键值对,而集合的话我目前还未弄清楚原因,有知道的大佬可以私信给我,我也很想知道。
试验代码如下:
s = 'hello python java python'
#replace表示字符串中所有的指定在主字符串中,把方法参数一字符串,替换成参数二的字符串
print(s.replace('k','java'))
# 假设传入第三个参数,表示你在主字符串中替换的次数
print(s.replace('python', 'java',1))
# join
lst = ['hello','python','java','C#']
print(' '.join(lst))
t = ('666','python','C#')
print('|'.join(t))
'''
集合不能被衔接,具体原因目前还不知道
se = {1,5,'hello',666}
print('&'.join(se))
'''
字符串的比较
a = 'apple'
b = 'banana'
print(a>b)
- 按找ASCII码表进行比较。一个一个字符进行比较,如果相同就往下继续比较,一定能比较出结果,所以字符串能直接使用 > < == 这些符号进行比较。返回的值是True或者False。因为前面说过所有对象皆有Bool值。
字符串的切片
我个人感觉字符串切片没什么好说的,就是把字符串看成列表一样,写法也和当时列表切片一模一样,
就是三个参数,start: end: step。
- 需要说明的是字符串中每个字符的下标也有负数,从尾部开始数就是从-1开始一直到字符首字母都是越来越小,减1的步长。
该下标表示也是和列表一样的。
s = 'hello python'
print(s[-6::1])
print(s[6::1])
print(s[4:])
print(s[:3])
格式化字符串输出
在这个模块解决了我对print输出的所有疑惑和小细节
- 用%作为占位符
这与C语言中的占位符一样,就是用%的形式作为一个可变字符,然后在引号后面使用变量进行输出。
name = ‘python’
age = 11
如:print(‘输出:%s、%d’ % (name, age))
解释:
%s对应字符串输出
%d对应int输出
%f 对应float输出
%lf 对应double输出
基本常用的就这几个
使用%d - 用{}作为占位符进行输出
如:print(‘输出:{0} {1}’.format(name, age))
占位符里面的数字可以不写,但是一般来说我们程序员都会写上0123这样子排序下去,方便分辨对应的变量。
即:print(‘输出:{} {}’.format(name, age))这样也是能运行通过的,但是不提倡该写法。
#格式化输出
name = 'LOVE'
num = 220901
#使用%占位符输出
print('时间:%d 姓名:%s'% (num,name))
#使用{}占位符输出
#占位符中的数字可以不填,但是一般规范点要填
print('时间:{}'.format(num))
print('时间:{0} 姓名:{1}'.format(num,name))
字符串的编码与解码
- 字符串的编码
设字符串为a
a.encode(encoding= ‘编码格式’)
接收a字符串编码后的字节需要用byte类型变量接收在这里我们设该变量名为B。
但是在Python中只需要一个变量就行,因为会自动帮你转换为对应的变量类型。 - 我字符串的解码
a.decode(encoding= ‘解码格式’)
使用在接收字符串编码后的变量B.decode(encoding=‘解码形式’)
然后用一个字符串变量接收该解码后的字符串 - 总结
编码用字符串来把方法 . 出来。
解码用接收编码后的字节变量 . 出来。
函数
函数的定义与框架
- 书写函数的格式
def 函数名(参数…) :
Tab空格 …函数体
Tab空格 return(没有返回值的时候可以不写)
形参与实参
- 形参
即形式参数,在定义函数中,参数值就是形式参数,该参数就是把你在调用函数传进来的参数复制一遍,在函数内部进行调用。 - 实参
调用函数传进来的参数即实际参数,便是实参,该参数是用于被函数的形参进行复制,复制完成后就能为函数内部进行使用。
默认参数值
在定义一个函数的时候我们直接写参数个数时,也可以直接给形参赋初值,这就是所谓的默认值,当我们调用函数的时候,有默认值的参数是可以选择不填,因为有默认值了。假设你要传进来也可以,同时会改变该函数的默认值。
#函数参数默认值
def calt(a,b=10):
print(a)
print(b)
return
calt(1,55)
calt(5)
可变参数
假定一个函数名为Fun(可变参数)
- 在定义一个可变参数函数的时候在函数形参括号里面的参数名要加一个*
如: def Fun(* args):
形参加星号表示该函数的参数为可变参数
在调用函数的时候,实参写多少个就把该参数全部压进args该形参变量中,变成一个元组不可变序列进行操作,然后返回该参数args的时候也是以元组形式返回。 - 传参的几种形式
1:直接传列表、元组、字典、集合。这些都会作为只有一个元组的元组传进去。
2:使用多个参数即:fun2(1,4,5,8)这样就是一个可变参数最直观的写法,就是可以写多个,想写几个就写几个,最后把这一坨作为函数形参压进函数形参名字args(改名字是你定义函数时候写的,随便什么名字都可以,无所谓),然后args就是一个元组。
3:当你把列表、元组、字典、集合传进来,可以在实参中加一个星号,使之拆开所有元素,放进形参args中作为元组一个一个的元素,而不是直接把一整个作为元组元素。同时如果你在一个总汇中加一个星号都能将其拆开成一个个元素作为参数传进去,总汇的概念就是数据结构这些,字符串也可以是一个总汇… 如果能get到什么是总汇那应该好办了,该可变参数就很容易理清楚哪些能拆哪些不能拆。
lst = [1,4,5,2]
t = (8,8,9,9,5)
s = {888,999,777,666}
dit = {'人':9,'Jackson':66}
def fun2(*args):
print(args)
return
fun2(lst)#该传参形式是以一个列表形式传进去
fun2(lst,t,dit,s)# 把各个数据结构作为元组元素传进去
fun2(*lst)#该传参形式是把列表分解开来传进去
fun2(*t)
fun2(*s)
fun2(*dit)#字典也可以实现拆开成一个个元素传进去,拆开的是字典的键,键作为元组的元素放进去
fun2(*'helloword')
fun2(1,4,5,8)
可变关键字参数
- 在定义该函数的时候,参数需要加两个**
如: def Fun(* args):
形参加两个星号表示该参数是关键字参数
即,我们在传实参进来的时候的格式是:a = 1,b = 2…
该关键字参数的函数传进来的时候,全部压进args里面,变成一个字典的形式,参数变量名a 和 b是键,然后等号后面是值,这样就构成了一个字典,具备了字典的元素。
所以使用可变关键字参数的时候,我们该形参args就是一个字典。 - 传参方式
1:首先是直接使用创建字典的方式进行传参,也就是在函数括号中填写,像使用内置函数dict创建字典一样的方式传参进去。
2:直接传一个字典进去,这时候需要用两个星号将其拆开,进去之后形参依旧是字典形式,然后形参返回形式也是字典形式。
# 关键字参数,即键值对,将参数返回的时候为字典类型
def fun3(**args):
print(args)
args.clear()
return args
dit2 = fun3(a=2,b=9)
print(dit2,type(dit2))
#不能直接传一个字典进去 fun3(dit)
#所以要用一个**放进去解开字典所有元素传进去
fun3(**dit)
两者区别
- 首先是只有一个星号的函数参数,如果使用了一个星号作为该函数的参数的话,那么该参数就是可变参数序列,但是在函数里面,该参数是元组,是一个不可变序列,返回该参数也是以元组形式返回。
- 其次第二个是可变关键字参数,如果使用两个星号作为该函数的参数的话,那么该参数就是可变关键字参数序列,但是在函数里面,该参数是字典,(这时候我们知道字典是可变的)因为是以关键字形式传进来,所以返回该参数的时候也是以字典形式返回。
- 补充细节
当你即使用可变参数,又使用可变关键字参数的时候就需要记住一个细节点:
必须把一个星号的可变参数放在两个星号的可变关键字参数的前面。
一个星号才轮到两个星号(很容易理解)
ss = 'hello,python'
def fun4(*args1,**args2):
print(args1,args2)
return
fun4(1,4,5,2,a=8,c=8)
fun4(ss) #表明在可变参数中,尽管有一个可变序列和一个关键字可变参数,都不填或者填一个都行,什么叫可变参数,即想填多少就填多少,不填也行
递归函数(函数结束篇)
斐波那契数列:
1 1 2 3 5 8…
就是从第三个数字开始,前两个数字的和作为该数字的值1+1=2第三个数为2
1+2=3,第四个数为3,以此类推。
- 首先第一二两个数不在规律范围内,就是不符合前两个数加起来等于他自己,所以在代码中要单独判断。
- 然后使用递归函数进行调用,学过C语言的就很容易理解了,就是在函数内部自己调用自己。
- 递归函数必须设置一个终止条件,否则递归函数会无穷无尽的递归下去。
#斐波那契
def fib(n):
if(n==1):
return 1
elif(n==2):
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(6))
#使用循环把前6个斐波那契数打印出来
for i in range(1,7):
print(fib(i),end='\t')
错误捕获
下面的try部分接的都是执行代码,试错代码部分,假设代码出错就会执行execpt的捕获错误部分的代码。
第一种
当我们明确是哪种错误类型之后就可以对应好下面的错误捕获来使用:
- try ------ execpt ZeroDivisionError :
分母不能为0,如果为0就捕获异常,除或模0出现异常的时候就会执行错误捕获代码 - try-------execpt ValueError :
用户输入的类型与try中代码执行的数据类型不一致,比如:代码需要用int类型,但是用户输入的字符串没有进行转换,仍然用输入的字符串进行执行,这时候就会捕获异常。
简而言之:就是传入无效参数 - try-------except BaseException as E:
该捕获异常类型就包含了所有错误,在你不知道会发生什么异常的时候就用这,as E表示将错误信息给E,E是一个变量名,只要符合标识符就行,所以我们一般会在捕获异常后直接用print输出E该错误信息。
代码如下:
try:
n1 = int(input(':'))
n2 = int(input(':'))
reslut = n1/n2
print(reslut)
except ZeroDivisionError:
print('除数不能为0')
except ValueError:
print('值输入错误')
except BaseException as E:
print(E)
继续补充几个常见的错误捕获,但不进行代码演示了,因为都一样的写法
- IndexError :
在序列中没有此索引 - KeyError :
映射中没有这个键 - NameError :
没有声明或者初始化对象(没有属性) - SyntaxError :
Python语法错误
第二种
- try ----- except BaseException as E: ------ else :
意思是try中出现异常了,将在异常捕获中执行except的代码,否则如果没有抛异常的话,当执行完try的代码后继续执行else的代码,换句话说else是跟着except的,所以就当except没有执行的时候就else。
try:
n1 = int(input(':'))
n2 = int(input(':'))
reslut = n1 / n2
print(reslut)
except BaseException as E:
print(E)
else:
print('try完了就继续执行我这个语句')
第三种
- try ----- except BaseException as E: ------ else : --------finally:
该方法就是不管你是否有错误,最后的finally都会执行里面的代码体
try:
n1 = int(input(':'))
n2 = int(input(':'))
reslut = n1 / n2
print(reslut)
except BaseException as E:
print(E)
else:
print('try完了就继续执行我这个语句')
finally:
print('管你错没错误,我就执行')
面向对象
在Python中万物皆对象
类的定义
- 类是一些物体的总汇,他们具有相同的特征,这时候我们可以归结为一种类,我们可以在该类的基础上创建一种对象,该对象拥有类中所有的属性和功能。
- 如何定义一个类
class 类名:
上面这种格式即为一个类,在类中书写属性和方法体即可 - 类里面的方法又分为几种
1:def init(self): 初始化方法(我称之为构造函数)
在该函数中是初始化的方法,具体是当你在创建对象的时候,该方法就是一个传参的函数,
比如:def init(self,name,age = 2): 这时候我们就需要在创建对象的时候传入两个参数
注意:这里我的age赋了一个值,就跟前面的函数一样,可以赋予默认值,然后在使用该方法的时候就可以选择不填,自动给你默认值。
对于self的解释:在初始化方法里面会自动给你打上self该参数在里面,其实该参数就相当于是一个对象,因为类是为对象服务的,一般用方法都是基于对象然后使用类中的方法,所以该self就是一个占位符一样,告诉你这个东西是对象,同时可以通过对象来修改值等操作。
总结:简而言之该初始化就是相当于在你创建对象的时候传一些需要用的参数,就是初始化属性而已 。比如:现在有一个Student类,stu = Student(‘张三’,20)这是时候在创建对象的时候因为是初始化函树数需要传参,我们在创建的时候同样需要传参。
2:类中定义的普通方法 称他为实例方法
如:def eat ( self ) 同样的括号内需要有self ,因为都是为了表明在使用的是你当前创建对象的属性。
在类中直接写一个函数方法,没什么特别的,就跟平时创建方法体一样,使用的时候可以用对象使用该方法功能。
3:@classmethod
def cm(cls): 定义类方法,表示可以用类名调用的方法,用对象也可以调用。
cls就是在你写类方法的时候自动给你补充上的,具体原因我目前还未得知,有知道的大佬可以私信告诉我~
在定义类方法之前@classmethod 是必须写上的
4:@staticmethod
def stfun(): 定义静态方法,表示可以用类型调用的方法,用对象也可以调用
在该静态方法中不需要加什么特定的参数。只是说没有特定要加的参数而已,不是说不可以写一个要传参的函数。
5:类属性
类中方法外的变量称为类属性,被该类的所有对象可共享。
6:假设你不想我的类属性被外部对象访问到,只想在对象创建完成后,仅仅在内部使用。
这时候需要把self.age变成self._ _age就是在属性前面加两个下划线,表示该属性属于内部的,外部不能访问到
若我真的想用对象直接访问那怎么办?
那就:对象名 . _类名_ _属性 这样就可以访问到, 不过都不让你访问了还强制性访问就不太好了,因为咱程序员写代码是有原则的嘛。 - 总结一下
类方法:使用@classmethod 修饰的方法,可以使用类名直接访问的方法
静态方法:使用@staticmethod 修饰的方法,可以使用类名直接访问的方法
class Student:
locate = '广东'
#初始化属性,创建对象时的参数,可以自己在参数中赋值使之拥有默认值,防止报错
def __init__(self,name,age = 2):
self.name = name
self.agess = age
def sayhello(self):
print("你好我是:%s, 今年%d岁"% (self.name,self.agess))
@classmethod
def cm(cls):
print('我是类方法,可以使用类名使用我,也可以用对象使用我')
@staticmethod
def stfun():
print('我是静态方法,可以使用类名使用我,也可以用对象使用我')
stu = Student('孙悟空',2000)
stu.sayhello()
stu.cm()
Student.cm()
stu.stfun()
Student.stfun()
Student.sayhello(stu)#这样调用对象方法也可以
动态绑定对象属性和方法
-
首先创建一个Student类,然后使用def _ _ init _ _(self,name,age = 2) : 初始化属性。
-
动态的解释
我们创建一个类之后就会创建一个对象,该对象拥有类的所有功能和属性,当我们发现创建的类已经不满足对象的需求时,即属性和功能不够对象用了,这时候就需要动态的为对象添加他所需的属性和功能。 -
动态绑定属性
假设对象名为 stu1
现在需要加多一个性别属性给stu1该对象,我们直接添加就好
如:stu1 . gerder = ‘男’
gerder是前面不存在的属性,我们直接在这创建出来给他赋值就是一种动态绑定属性。
也就是说gender该属性名是随意起的,现在要做的工作就是添加一个在类中不存在的属性。 -
动态绑定方法
假设对象名为stu2
现在需要加多一个方法给stu2该对象,我们同样可以直接添加,
如:stu2 . show = show
注意:show是我们在程序中定义的函数方法体,show可以和你要在对象中添加的方法名一样,只要你把show函数定义了就行。
然后就可以使用stu2 . show()了,功能和你在程序中定义的show方法功能一样。
#动态绑定属性和方法
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def eat(self):
print(self.name+'在吃饭')
stu1 = Student('张三',20)
stu2 = Student('李四',25)
stu1.eat()
#动态添加一个性别属性
stu1.gender = '男'
print(stu1.gender,stu1.name)
#stu2没有添加该属性就不能够使用,因为这是专属于张三的属性,不是class类中共同的属性
#动态添加一个方法
def sayhello():
print('你好,我是学生')
stu2.sayhello = sayhello
stu2.sayhello()
继承类
- 什么是继承
现实生活中的继承很类似,就是继承家产这些差不多。
在类与类之间也有继承关系,父类与子类,子类继承了父类,就能拥有父类的功能与属性,而子类也能在此基础上添加属于自己的属性或者方法。
一个子类可以继承多个方法,但是该属性就不适用与现实生活了,一个人可不兴有多个父亲。 - 如何实现继承关系
每一个类如果没有写明继承哪个类的话全部类都是默认继承object类。
假设有一个:Person类,然后Student类想要继承Person类,那么在创建Student的时候
class Student (Person):
黄色部分就是写出你该类要继承的父类是哪个,继承多个就用逗号隔开。 - 继承了之后如何在子类中重写父类方法
重写父类方法我觉得不应说是重写,应该属于调用父类。
因为在子类Student定义自己的方法的时候,
在方法内部使用super() . 父类方法()
在方法内部填充属于Student所需的其他功能,或者不填,就是想调用该方法而已。 - 解释下重写方法的原因与作用
如果对子类继承的父类方法 或者 属性不满意,可以在子类中对方法体进行重写
通过super().xxx()调用父类中重写的方法 - def _ _ str _ _ (self): return XXXX
一般类中都会重写该方法,因为方便查看该类是什么
就是说该方法是Python中自带的,在类中放进该函数的话,当你print(对象)的时候就会打印出你在该方法里面写的内容,因为我们是return XXX,所以print的东西肯定是XXX - super().XXX()
这个东西表示你在使用父类中的方法或者属性。
先super()表示父类,然后后面就可以 . 出来你想要调用父类的东西就可以了。
语言不如代码来的实际
继承示例代码如下:
#实现继承类
class Person(object):
def __init__(self,name,age):
self.name = name
self.age = age
def show(self):
print('我是学生,名字是:{0}、 年龄:{1}'.format(self.name,self.age))
#一般类中都会重写该方法,因为方便查看该类是什么
def __str__(self):
return '我是人类父类'
class Student(Person):
def __init__(self,name,age,score):
super().__init__(name,age)
self.score = score
def show(self):
super(Student, self).show()
print('学生需要学号:',self.score)
def __str__(self):
return '我是学生类,继承于人类'
stu = Student('jackson',20,'1001')
stu.show()
print(stu)
print(type(stu))
多态的实现
- 首先多态是每一个面向对象的语言必备的编程思想。
我对多态的理解是:一个功能,根据对象不同表现出来的效果是不同的,比如吃东西这一说,人和鸟吃的东西不一样,那么在吃这一块就能表现出多态。 - 多态的实现
语言上描述:
首先多态我们照样要用一个父类,然后在不同对象中实现吃的动作,每一个继承父类对象都有一个吃的动作,即继承了父类的方法,通过重写方法表现出不一样的效果。那么这时候我们在外部声明一个函数方法,参数要传入一个父类对象,然后调用父类对象中的函数方法 ‘吃‘ 。
然后声明完成该函数后,我们真正要传的对象是根据自己想要表现出哪位子类的态度动作,即多态,传入鸟的对象就 会告诉你鸟在吃的动作是怎么完成的。 - 总结概括一下:多态是具有多种形态,即便你不晓得哪一个变量传进来的,但是你仍然可以让该变量表现出该方法功能来,动态的决定调用哪一个对象就是多态。
代码如下:
#实现多态
class Animal(object):
def eat(self):
print('动物吃东西')
class Student(Animal):
def eat(self):
print('学生正在吃饭')
class Dog(Animal):
def eat(self):
print('狗正在吃骨头')
class Cat(Animal):
def eat(self):
print('猫在吃鱼')
class Bird(Animal):
def eat(self):
print('鸟在吃虫')
def funeat(Animal):
Animal.eat()
funeat(Dog())
funeat(Cat())
funeat(Student())
funeat(Bird())
dir()
特别说明一下该函数的用处,该函数能够显示出一个对象中有什么属性,有什么方法函数等等,只要碰到不会的或者不知道这个类里面有什么东西。
- 直接打印出来即可:print(dir(对象名))
模块
什么是模块
模块就是一个 .py文件,一个程序可以包含很多个模块,每个模块里面又包含很多的函数语句等,就是我们所写的代码,都是放在一个模块当中。
导入模块
有两种方法导入
- import 模块名
这种导入方式就是直接把模块中所有包含的函数和类全部都导进来了。 - from 模块名 import 函数\变量\类
这种导入方式就是比较细致,在一个模块中拥有什么东西都可以单独拎出来只单单导入一个,而不是将一个模块中所有东西都导入。
这种方式就是只能使用你导入的东西,而真个模块其他的是不能使用的。 - 如何能够自己导入自己写的模块
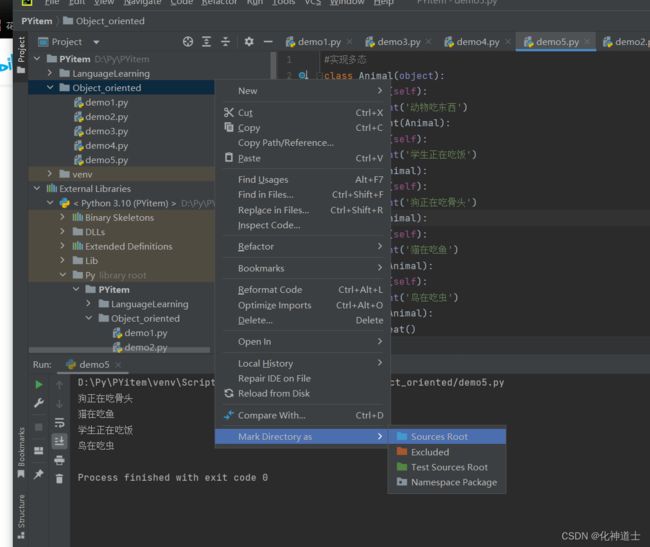
看图步骤说话:
①把想要用的模块放在一个文件夹中

②右键文件夹->Mark Directory as-> Sources Root
然后你的文件夹就会变成蓝色的了,这样子你在该文件夹里面的模块都可以进行导入调用了。
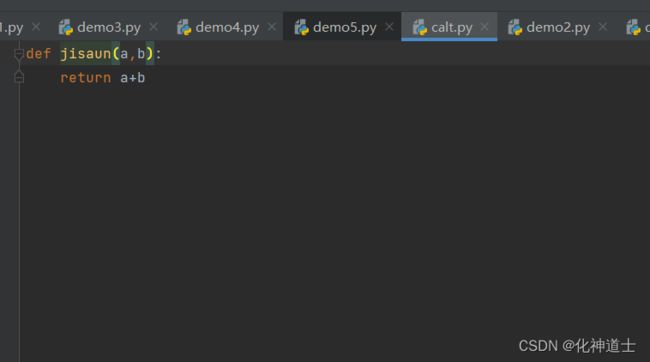
③然后我在文件夹中新写一个加法模块,名字叫calt
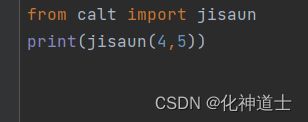
④然后我在同一文件夹中导入该模块,然后使用该模块的jisuan函数

- 注意细节:使用另一个模块的函数的时候,需要使用模块名点出来模块里面的函数方法。
- 假使你是直接用from calt import jisaun就可以直接使用jisuan函数方法。
如图:
模块之间以主程序进行运行
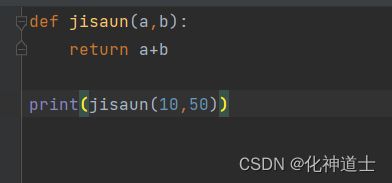
- 假使你需要引入另一个模块中的函数进行调用的时候,函数里面有一个你并不想执行的代码,这时候你就可以把该代码进行一个以主程序运行的代码模块标注
比如下面的图片:
假设我们只想用jisuan该函数,当我们另一个模块调用jisuan函数的时候,洗面的print这行代码也会在另一个模块输出。
解释一下为什么会执行print语句:
因为在Python中运行程序的时候定义的函数不会优先运行,因为你没有调用,也就是说程序会优先运行print语句然后把jisaun这个函数运行出来10+50,然后再找到函数jisuan这个定义进行调用给另一个模块。
这里也引出了另一个问题,就是在被调用模块中只写函数或者类的定义就可以了,被调用的时候找的都是函数定义和类定义,而不是在全局变量中找到其他print之类的语句先运行完了再给你去找函数方法。
包
- 什么是包
每一个包中包含着多个模块。
包与包之间里面的模块名可以一样,只要不同包就可以
目的:代码规范、避免模块名冲突 - 包与文件目录的区别
包中比目录多含有一个模块:_ _init_ _.py
目录中 一般不含有该 _ _init_ _.py 模块名文件 - 包的导入
import 包名 . 模块名
包的导入方式有很多,理解了前面的import和from…怎么导入的就基本懂了。
就是一个层层递进一层剥一层的感觉。
示例代码如下:仅仅代表一小部分
#表示导入了包中的一个模块
import package1.packmd1
#表示导入了整个包
import package1
#可以通过包名直接调用一个模块中的pr1函数
package1.packmd1.pr1()
#可以先导入包中的函数
from package1 import packmf2
#然后就不用老是写包名才能调用到模块函数
packmf2.pr2()
文件操作
文件的读写操作
- 使用内置函数open()创建文件对象
语法规则:
标注:readline表示读取的是每一个字符,包括回车也会将其\n读取,然后输出到print上面
#表示打开文件名问a的txt文件,打开方式为r只读
file = open('a.txt','r')
print(file.readline())
#打开了文件流就关闭文件流
file.close()
几种常见的打开方式
我们下面都已txt文件作为文件打开
- ‘r’ 只读,即只允许读取文件内容不允许修改
- ‘w’ 写,每次打开文件都会将文件内容清空然后进行书写。如果该文件不存在就会创建该文件
- ‘a’ 追加,即在文件原有的内容上进行追加内容。如果文件不存在就创建该文件
- b
这个需要好好说一下
这个打开方式表示除了txt文件内容外,其他的文件打开方式,比如mp3,视频等文件都是属于二进制文件的都要用该读取方式。
如果使用呢:
首先打开方式不是b,而是rb wb,即rb是读取,wb是写入
代码如下:
src=open('xxx.jpg','rb')
target=open('jpgcopy.jpg','wb')
#这一条语句是边读边写的意思
target.write(src.read())
src.close()#记得关闭文件流
文件对象的常用方法
- read([size])
从文件中读取,size表示读取的字节大小,如果不写就是把你整个文件读取完成。 - readline()
文本内容里面所有内容都读取出来,比如换行符\n也给你的确出来。 - wirte(str)
将字符串写入文件中 - writelines(s_list)
将一个字符串列表写入文本中,不写入换行符 - seek(offset[,whence])
offset表示相对于whence的位置
offset表示开始扫描的位置,正数表示往前扫描,负数为倒退扫描。
whence代表值:
0=从文件头开始算
1=从当前位置开始算
2=从文件尾部开始算 - tell()
返回文件指针的当前位置 - flush()
把缓冲区的内容写入文件,但是不关闭文件 - close()
把缓冲区的内容写入文件,同时关闭文件,释放文件对象相关资源 - 缓冲区解释
在文件流中,缓冲区是一个我认为需要理解的点。
在文件流中的缓冲区是表示在扫描中,扫描到的东西不会先写入文本文件或者目标文件,先存在缓冲区先。假设你现在有一个需求是想把在文件流流到某个程度的时候将其缓冲区的内容先输出到目标文件中先,这时候就需要上面所说的两个缓冲区函数。
close是我们打开文件后必须要使用它来关闭的。
而flush就是能够将内容优先输入到目标文件,但是不关闭。
with自动退出语句
- 语法规则: with 调用类或打开某个文件流 as 变量名
with open('66.txt','r') as file:
print(file.read())
#就是说有了该语句就不用手动关闭文件流了
-
执行过程
该语句意思是:首先进入打开文件流,然后执行读取或者写入操作等,然后不用手动使用close进行关闭文件流。 -
更深的理解
就是当我创建一个类对象的时候,并且使用对象调用方法的时候是先进入类,然后调用方法,然后退出类。
类中有两个进入和退出函数方法,我们通过重写他们可以得到一些信息
代码如下:
class SL(object):
def __enter__(self):
print('我进来啦!')
return self
def show(self):
print('我真在执行嚯~')
return
def __exit__(self, exc_type, exc_val, exc_tb):
print('我走咯~')
return
with SL() as s:
s.show()
运行结果:

os重要模块
为什么说重要呢,因为这与我们电脑操作系统直接相关联。
该模块中的函数能直接执行我们的可执行文件和系统中自带的系统
- os.system(‘填写系统中的软件如记事本这类的名字,后缀加上.exe’)
在Python中有该语句既可以直接执行该软件。
其他常见的函数如下: - getcwd()
返回当前工作目录,如果你在Python中运行程序,就会返回你该程序所在的文件目录 - listdir(path)
返回指定路径下的文件和目录信息
例子:就是把你访问的目录里面所有文件进行输出 - mkdir(path[,mode])
创建目录 - makedirs(path1/path2/…[,mode])
创建多级目录,就是嵌套目录
如:makedirs(A/B/C)
表示在当前目录下面创建A目录,然后A目录里面含有一个B目录,然后B目录里面含有一个C目录。 - rmdir(path)
删除目录 - removedirs(path1/path2/…)
删除多级目录 - chdir(path)
将path设置为当前工作目录
os.path模块常用函数
- abspath(path)
用户获取文件或目录的绝对路径 - exists(path)
用户判断文件或者目录是否存在,返回值为True或者False - join(path,name)
将目录与目录或者文件名拼接起来
就是将连个字符串拼接而已 - split()
分离目录和文件名
就是该函数会自动识别哪个是目录哪个是文件名这样 - splitext()
分离文件名和扩展名 - basename(path)
从一个目录中提取文件名
注意:是你传进来一个路径,然后在这个路径path中给你提取文件名出来 - dirname(path)
从一个路径中提取文件路径,不包括文件名
从path中,你填进去的路径中提取除了文件名以外的路径,就这么简单 - isdir(path)
用于判断是否为路径
结束语
能写到这,让我明白了,时代在与时俱进,计算机科学更是如此,甚至更快,对于Python这门语言,我的感受是:它是C的儿子,是C#的偷懒兄弟,没有什么语言框架约束,拿来就能用。手持Pycharm,懂点英文就可以写代码了。
散功完毕~
愿各位道友日后注意身体健康,有了健康方能走得更远,修为方能更进一步。