04强化学习——Actor-Critic(AC)进阶篇(minibatch-MC-AC)
一、问题描述
上一篇文中讲到了AC的基本框架和问题,在TD-AC的实验结果可以看出很不稳定,下面做出两点改变
1、使用MC方法来计算置换上述作为评估器,值函数计算采用从前状态开始进行折扣累加方式:
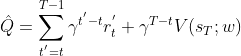
2、采用mini-batch的方式来代替一整条episodes的训练
二、代码实现
import tensorflow as tf
import numpy as np
import gym
import matplotlib.pyplot as plt
RENDER = False
#利用当前策略进行采样,产生数据
class Sample():
def __init__(self,env, policy_net):
self.env = env
self.brain=policy_net
self.gamma = 0.90
def sample_episodes(self, num_episodes):
#产生num_episodes条轨迹
batch_obs=[]
batch_actions=[]
batch_rs =[]
#一次episode的水平
batch = 200
mini_batch = 32
for i in range(num_episodes):
observation = self.env.reset()
#将一个episode的回报存储起来
reward_episode = []
j = 0
k = 0
minibatch_obs = []
minibatch_actions = []
minibatch_rs = []
while j < batch:
#采集数据
flag =1
state = np.reshape(observation,[1,3])
action = self.brain.choose_action(state) # 使用策略网络来选择动作
observation_, reward, done, info = self.env.step(action)
#存储当前观测
minibatch_obs.append(np.reshape(observation,[1,3])[0,:])
#存储当前动作
minibatch_actions.append(action)
#存储立即回报
minibatch_rs.append((reward+8)/8)
k = k+1
j = j+1
if k==mini_batch or j==batch:
# 处理回报
reward_sum = self.brain.get_v(np.reshape(observation_, [1, 3]))[0, 0]
discouted_sum_reward = np.zeros_like(minibatch_rs)
for t in reversed(range(0, len(minibatch_rs))):
reward_sum = reward_sum * self.gamma + minibatch_rs[t]
discouted_sum_reward[t] = reward_sum
# 将mini批的数据存储到批回报中
for t in range(len(minibatch_rs)):
batch_rs.append(discouted_sum_reward[t])
batch_obs.append(minibatch_obs[t])
batch_actions.append(minibatch_actions[t])
k=0
minibatch_obs = []
minibatch_actions = []
minibatch_rs = []
#智能体往前推进一步
observation = observation_
#reshape 观测和回报
batch_obs = np.reshape(batch_obs, [len(batch_obs), self.brain.n_features])
batch_actions = np.reshape(batch_actions,[len(batch_actions),1])
batch_rs = np.reshape(batch_rs,[len(batch_rs),1])
# print("batch_rs", batch_rs)
return batch_obs,batch_actions,batch_rs
#定义策略网络
class Policy_Net():
def __init__(self, env, action_bound, lr = 0.0001, model_file=None):
self.learning_rate = lr
#输入特征的维数
self.n_features = env.observation_space.shape[0]
#输出动作空间的维数
self.n_actions = 1
#1.1 输入层
self.obs = tf.placeholder(tf.float32, shape=[None, self.n_features])
#1.2.策略网络第一层隐含层
self.a_f1 = tf.layers.dense(inputs=self.obs, units=200, activation=tf.nn.relu, kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
#1.3 第二层,均值
a_mu = tf.layers.dense(inputs=self.a_f1, units=self.n_actions, activation=tf.nn.tanh, kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
#1.3 第二层,标准差
a_sigma = tf.layers.dense(inputs=self.a_f1, units=self.n_actions, activation=tf.nn.softplus, kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
#
self.a_mu = 2*a_mu
self.a_sigma =a_sigma
# 定义带参数的正态分布
self.normal_dist = tf.contrib.distributions.Normal(self.a_mu, self.a_sigma)
#根据正态分布采样一个动作
self.action = tf.clip_by_value(self.normal_dist.sample(1), action_bound[0],action_bound[1])
#1.5 当前动作,输入为当前动作,delta,
self.current_act = tf.placeholder(tf.float32, [None,1])
self.delta = tf.placeholder(tf.float32, [None,1])
#2. 构建损失函数
log_prob = self.normal_dist.log_prob(self.current_act)
self.a_loss = tf.reduce_mean(log_prob*self.delta)+0.01*self.normal_dist.entropy()
# self.loss += 0.01*self.normal_dist.entropy()
#3. 定义一个动作优化器
self.a_train_op = tf.train.AdamOptimizer(self.learning_rate).minimize(-self.a_loss)
#4.定义critic网络
self.c_f1 = tf.layers.dense(inputs=self.obs, units=100, activation=tf.nn.relu, kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
self.v = tf.layers.dense(inputs=self.c_f1, units=1, activation=tf.nn.relu, kernel_initializer=tf.random_normal_initializer(mean=0, stddev=0.1),\
bias_initializer=tf.constant_initializer(0.1))
#定义critic网络的损失函数,输入为td目标
self.td_target = tf.placeholder(tf.float32, [None,1])
self.c_loss = tf.losses.mean_squared_error(self.td_target,self.v)
self.c_train_op = tf.train.AdamOptimizer(0.0002).minimize(self.c_loss)
#5. tf工程
self.sess = tf.Session()
#6. 初始化图中的变量
self.sess.run(tf.global_variables_initializer())
#7.定义保存和恢复模型
self.saver = tf.train.Saver()
if model_file is not None:
self.restore_model(model_file)
#依概率选择动作
def choose_action(self, state):
action = self.sess.run(self.action, {self.obs:state})
# print("greedy action",action)
return action[0]
#定义训练
def train_step(self, state, label, reward):
td_target = reward
delta = td_target - self.sess.run(self.v, feed_dict={self.obs:state})
delta = np.reshape(delta,[len(reward),1])
for i in range(10):
c_loss, _ = self.sess.run([self.c_loss, self.c_train_op],feed_dict={self.obs: state, self.td_target: td_target})
for j in range(10):
a_loss, _ =self.sess.run([self.a_loss, self.a_train_op], feed_dict={self.obs:state, self.current_act:label, self.delta:delta})
return a_loss, c_loss
#定义存储模型函数
def save_model(self, model_path):
self.saver.save(self.sess, model_path)
def get_v(self, state):
v = self.sess.run(self.v, {self.obs:state})
return v
#定义恢复模型函数
def restore_model(self, model_path):
self.saver.restore(self.sess, model_path)
def policy_train(env, brain, sample, training_num):
reward_sum = 0
average_reward_line = []
training_time = []
average_reward = 0
current_total_reward = 0
for i in range(training_num):
current_state,current_action, current_r = sample.sample_episodes(1)
brain.train_step(current_state, current_action,current_r)
current_total_reward = policy_test(env, brain,False,1)
if i == 0:
average_reward = current_total_reward
else:
average_reward = 0.95*average_reward + 0.05*current_total_reward
average_reward_line.append(average_reward)
training_time.append(i)
if average_reward > -300:
break
print("current experiments%d,current average reward is %f"%(i, average_reward))
brain.save_model('./current_bset_pg_pendulum')
plt.plot(training_time, average_reward_line)
plt.xlabel("training number")
plt.ylabel("score")
plt.show()
def policy_test(env, policy,RENDER, test_number):
for i in range(test_number):
observation = env.reset()
if RENDER:
print("第%d次测试,初始状态:%f,%f,%f" % (i, observation[0], observation[1], observation[2]))
reward_sum = 0
# 将一个episode的回报存储起来
while True:
if RENDER:
env.render()
# 根据策略网络产生一个动作
state = np.reshape(observation, [1, 3])
action = policy.choose_action(state)
observation_, reward, done, info = env.step(action)
reward_sum+=reward
# reward_sum += (reward+8)/8
if done:
if RENDER:
print("第%d次测试总回报%f" % (i, reward_sum))
break
observation = observation_
return reward_sum
if __name__=='__main__':
#创建仿真环境
env_name = 'Pendulum-v0'
env = gym.make(env_name)
env.unwrapped
env.seed(1)
#动作边界
action_bound = [-env.action_space.high, env.action_space.high]
#实例化策略网络
brain = Policy_Net(env,action_bound)
#实例化采样
sampler = Sample(env, brain)
#训练时间最大为5000
training_num = 500
#测试随机初始化的个数
test_number = 10
#利用Minibatch-MC-AC算法训练神经网络
policy_train(env, brain, sampler, training_num)
#测试训练好的神经网络
reward_sum = policy_test(env, brain,True,test_number)