Flink电商数仓项目复盘笔记-01
Flink电商数仓项目笔记
电商实时数仓分层介绍
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时需求的时候,计算的复用性较差,开发成本随着需求增加直线上升。
实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性。
例如下图:

- 例如:我们在普通实时SparkStreaming项目中,直接从数据源获取后通过过滤然后获取新增数据和变化数据,之后进行GMV的计算,但是弊端就是假设我后续的销售明细或者其他需求需要使用到新增数据和变化数据,则需要重新从数据源再次过滤进行数据处理;这样数据的复用性就会很差!
离线计算:
就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是 Hadoop 的 MapReduce 方式;
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算。
实时计算:
输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。
实时电商数仓项目分层
- ODS: 原始数据,日志和业务数据—>放到kafka中
- DWD: 根据数据对象为单位进行分流,比如订单、页面访问等等。—>从kafka中读取数据进行分流处理
- 使用侧输出流进行分流
- 日志数据和业务数据的事实表,我们都放到dwd层的
- 日志数据和业务数据的事实表放在kafka中的
- DIM: 维度数据—>维度表放到dim层
- 维表放到Hbase
- 为什么事实表放到kafka,而维表放到Hbase呢?
-
- 事实表和维表需要关联进行数据的统计操作,join实际上就是从维表中通过主键id查询相关维度信息然后放入事实表中。
-
- 由于kafka中的数据默认保存7天,不能永久保存数据;而比如用户维度信息表,它保存了用户的信息,需要长期使用。
- 另外一点kafka属于数据传输的消息中间件,仅是作为数据的缓存和订阅消费;无法根据用户id去查询某个数据表的信息。而HBase却可以实现快速的查询,结合Phoenix使用
-
- DWM: 对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据。
- dwd层和dws层中间部分,将共用的数据抽取放到了dwm层 —>放入到kafka中,需要接着被消费,被加工
- DWS: 根据某个主题将多个事实数据轻度聚合,形成主题宽表。—>放到ClickHouse中,供查询使用
- ADS: 把ClickHouse中的数据根据可视化需进行筛选聚合—>不落盘,不存储,直接对接SpringBoot接口进行数据展示;离线数仓解决了对历史数据的分析需求;实时计算解决的是时效性的数据分析。
实时需求概览
- 离线数据在计算前已经知道所有的数据,而实时数据在计算时正在获取数据,边获取,边计算。
- 实时计算和离线计算以及即席查询的区别:
- 实时需求是7*24小时去运行的,离线需求固定性,每天有定时任务。而即席查询是暂时的需求。
- 即席查询的框架presto(基于内存当场计算)、kylin(预计算)多维分析–>(hive中有个with cube)
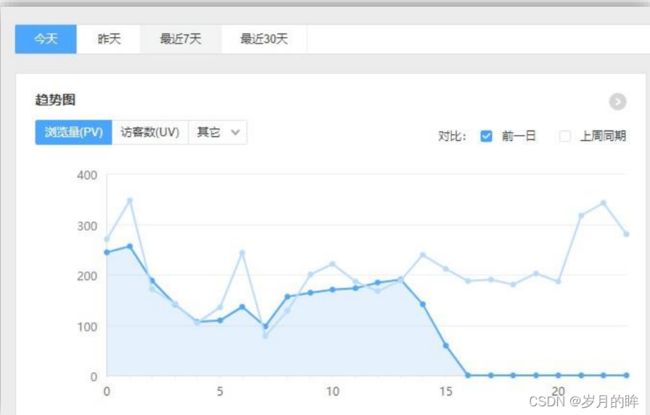
日常统计报表或分析图中需要包含当日部分
对于日常企业、网站的运营管理如果仅仅依靠离线计算,数据的时效性往往无法满足。
通过实时计算获得当日、分钟级、秒级甚至亚秒的数据更加便于企业对业务进行快速反应与调整。所以实时计算结果往往要与离线数据进行合并或者对比展示在 BI 或者统计平台中。
实时数据大屏监控需求
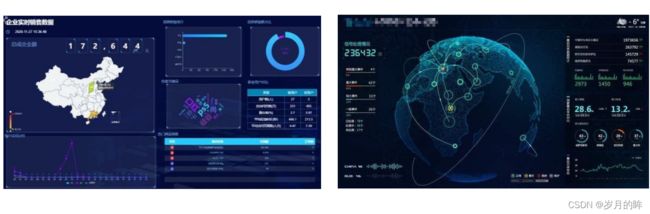
数据大屏,相对于 BI 工具或者数据分析平台是更加直观的数据可视化方式。尤其是一些大促活动,已经成为必备的一种营销手段。
另外还有一些特殊行业,比如交通、电信的行业,那么大屏监控几乎是必备的监控手段。
数据预警或提示
经过大数据实时计算得到的一些风控预警、营销信息提示,能够快速让风控或营销部分得到信息,以便采取各种应对。
比如,用户在电商、金融平台中正在进行一些非法或欺诈类操作,那么大数据实时计算可以快速的将情况筛选出来发送风控部门进行处理,甚至自动屏蔽。 或者检测到用户的行为对于某些商品具有较强的购买意愿,那么可以把这些“商机”推送给客服部门,让客服进
行主动的跟进。
实时推荐系统
实时推荐就是根据用户的自身属性结合当前的访问行为,经过实时的推荐算法计算,从而将用户可能喜欢的商品、新闻、视频等推送给用户。这种系统一般是由一个用户画像批处理加一个用户行为分析的流处理组合而成。
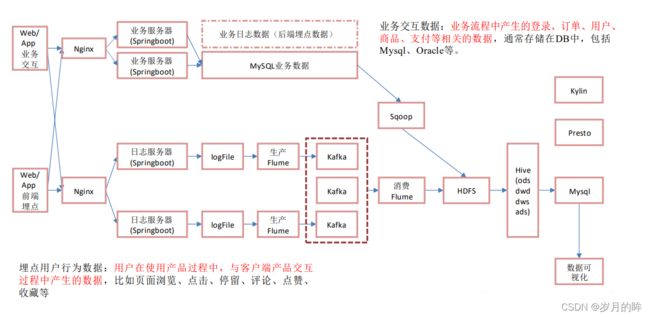
离线和实时架构对比
离线架构
-
sqoop同步数据的方式:
- 增量、全量、新增及变化,特殊。
- 新增:在SQL中有判断日期,where dt=‘今天’ ;创建时间等于当日。
- 全量:where 1=1;
- 新增及变化:在SQl中创建时间或修改时间等于今天;使用or做时间过滤
- 特殊就导一次
- 增量、全量、新增及变化,特殊。
-
Flume:
- source—>taildir source,channel—>kafka channel ; 没有sink
- TailDirsource:
优点: 断点续传,监控多目录多文件,实时监控
缺点: 当文件更名之后会重新读取该文件造成重复。- 出现重复的原因:taildirsource它是iNode+全路径表示一个文件,当文件名变化了,它会认为一个新文件。
- 解决的办法:
-
- 就是使用不更名的打印日志框架(logback)
-
- 修改源码,让TailDirSource判断文件时只看iNode值
-
KafkaChannel:
优点: 将数据写入Kafka, 省了一层sink组件。 这个组件在kafka中:既是生产者又是消费者
用法:
-
- Source-kafkaChannel-Sink
-
- Source-kafkaChannel
-
- kafkaChannel-Sink
-
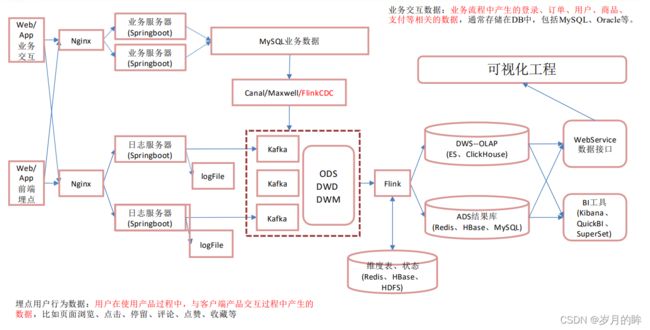
实时架构
kafka框架的回顾:
producer:
-
如何保证生产者的数据不丢失?数据的可靠性方面采用ACk应答机制,参数0,1,-1
-
拦截器,序列化器,分区器
-
发送流程 sender main
-
幂等性,事务
-
分区规则—>
有指定分区则发往指定分区,没有指定分区则根据key值Hash;没有指定分区也没有key的时候,轮询(粘性)
Brock:
Topic:
副本:高可用
分区:高并发、负载均衡(防止热点数据)、避免忙闲不均
ISR、OSR、LEO、HW
Consumer:
分区分配规则、offset偏移量的保存(默认保存在__consumer_offsets)
其他:手动维护offset(mysql)
保存数据&保存offset写入一个事务,精准一次消费。
NO1. 业务数据:
实时架构中,业务数据使用Canal/Maxwell/FlinkCDC来检测mysql数据库的binlog日志,动态监测数据库中数据的变化;然后使用 Canal将变化的数据读写到kafka中。
binlog:开启为行级别
NO2. 日志数据:
在离线数仓的架构中使用Flume读取落盘的日志文件,而实时则直接将日志写入到kafka。
优点是:速度快,时效性高,减少了磁盘IO;缺点:耦合性高。
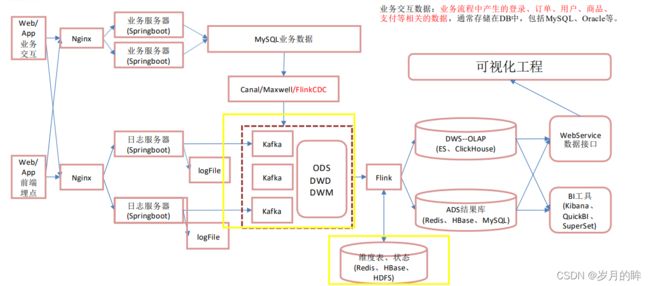
ODS: 将日志数据和业务数据写入ods层的kafka后,分为两个主题:1.行为日志主题 2.业务数据主题
DWD层:使用Flink连接kafka进行数据的消费,使用侧输出流分流到不同的主题中。
-
**日志数据:**会按照 页面数据、事件数据、曝光数据、启动数据和错误数据,因此要拆分为五个主题。
-
**业务数据:**除了一部分事实表需要存放到kafka中,另外的维表需要存放到HBase上。
DWM层:我们使用Flink消费dwd的主题数据,中间可能需要关联维表;dwd层事实表关联HBase上的维表然后形成dwm层的主题。
DWS层:使用Flink消费DWD层的数据和DWM的数据,然后将结果写出到ClickHouse,对接数据接口形成可视化页面。
ADS层:最终的指标存入Mysql或Redis
整体采用Lambda架构,将实时数仓和离线数仓整合到一起,复用kafka组件。
离线架构
- 优点: 耦合性低,稳定性高
- 缺点: 时效性差一点
- 说明:
-
- 项目经理(架构师)是大公司出来的,追求系统的稳定性
-
- 耦合性低,稳定性高
-
- 考虑到公司未来的发展,数据量一定会变得很大
-
- 早期的时候实时业务使用Sparkstreaming(微批次)
-
实时架构
- 优点: 时效性好
- 缺点: 耦合性高,稳定性低
- 说明:
- 1.突出优点,时效性好
- 2.Kafka集群高可用,挂一台两台是没有问题
-
- 数据量小,所有机器存在于同一个机房,传输没有问题4.架构还是公司项目经理(架构师)定的
日志数据采集
模拟日志生成器的使用
这里提供了一个模拟生成数据的 jar 包,可以将日志发送给某一个指定的端口,需要大数据程序员了解如何从指定端口接收数据并对数据进行处理的流程。
- 开发需求:
-
- 使用Mock数据代替App/Web埋点数据,然后写SpringBoot程序接收日志数据进行处理(落盘或者send给kafka的Producer),本地使用idea启动SpringBoot程序,测试启动Mock数据的jar后,数据能否写入到磁盘文件中。启动zk、hadoop、kafka的服务,看数据能否发送到kafka的Topic中。
-
- 测试通过后将SpringBoot程序打成jar包上传到节点服务器;接着搭建Nginx负载均衡。
-
日志数据采集
SpringBoot: 分层可以提高代码复用性,解耦
Controller: 拦截用户请求,调用service, 响应请求
Service: 调用DAO,数据处理
DAO (Mapper): 获取数据
持久化层: 存储数据
(1)数据生成脚本存放于/opt/module/applog目录下—>日志数据生成脚本gmall-mock-log.jar,启动脚本时的配置文件application.yml
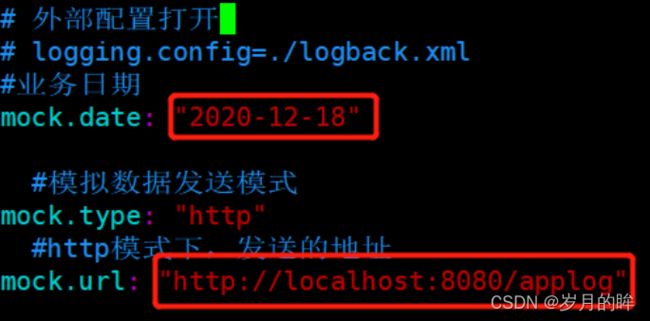
(2) 根据实际需要修改application.yml
(3) 使用模拟日志生成器的jar 运行
java -jar gmall-mock-log.jar
(4) 目前还没有地址接收日志,所以程序运行后的结果会报错
- 注意:ZooKeeper 从 3.5 开始,AdminServer 的端口也是 8080,如果在本机启动了zk,那么可能看到 404、405 错误,意思是找到请求地址了,但是接收的方式不对。
日志采集模块-本地测试
创建SpringBoot工程
(1)创建Springboot工程
SpringBoot 整合 Kafka
1) 修改 SpringBoot 核心配置文件 application.propeties
# 应用名称
spring.application.name=gmall-logger
# 应用服务 WEB 访问端口
server.port=8081
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=flink:9092
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
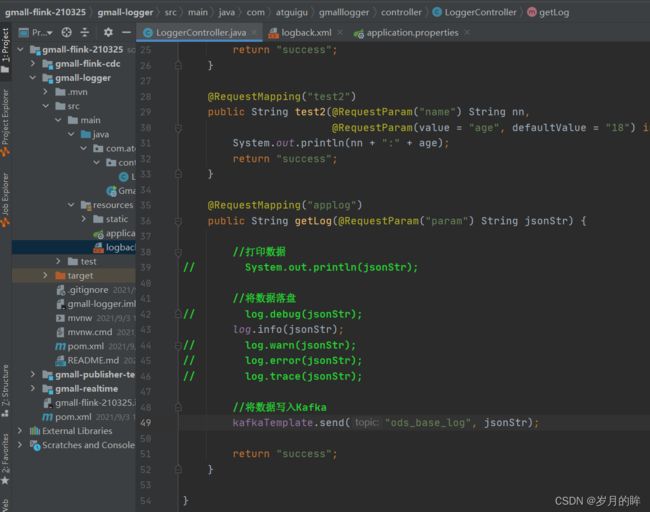
2) 在 LoggerController 中添加方法, 将日志落盘并发送到 Kafka 主题中
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
//@Controller
@RestController //@Controller + @ResponseBody
@Slf4j
public class LoggerController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("test")
// @ResponseBody
public String test1() {
System.out.println("success");
return "success";
}
@RequestMapping("test2")
public String test2(@RequestParam("name") String nn,
@RequestParam(value = "age", defaultValue = "18") int age) {
System.out.println(nn + ":" + age);
return "success";
}
@RequestMapping("applog")
public String getLog(@RequestParam("param") String jsonStr) {
//打印数据
// System.out.println(jsonStr);
//将数据落盘
// log.debug(jsonStr);
log.info(jsonStr);
// log.warn(jsonStr);
// log.error(jsonStr);
// log.trace(jsonStr);
//将数据写入Kafka
kafkaTemplate.send("ods_base_log", jsonStr);
return "success";
}
}
3) 在 Resources 中添加 logback.xml 配置文件
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/data"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%npattern>
encoder>
appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.logfile>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.logfileNamePattern>
rollingPolicy>
<encoder>
<pattern>%msg%npattern>
encoder>
appender>
<logger name="com.atguigu.gmalllogger.controller.LoggerController"
level="INFO" additivity="false">
<appender-ref ref="rollingFile"/>
<appender-ref ref="console"/>
logger>
<root level="error" additivity="false">
<appender-ref ref="console"/>
root>
configuration>
4) 修改 hadoop102 上的 applog 目录下的 application.yml 配置文件
注意:mock.url 设置为自身 Windows 的 IP 地址
5) 测试
-
运行Windows 上的 Idea 程序 LoggerApplication
-
运行applog 下的jar 包
-
java -jar gmall-mock-log.jar
-
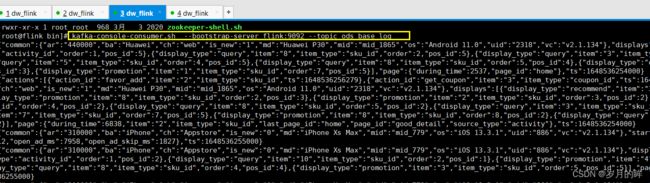
启动 kafka 消费者进行测试
bin/kafka-console-consumer.sh --bootstrap-server flink:9092 --topic ods_base_log -
查看数据消费情况
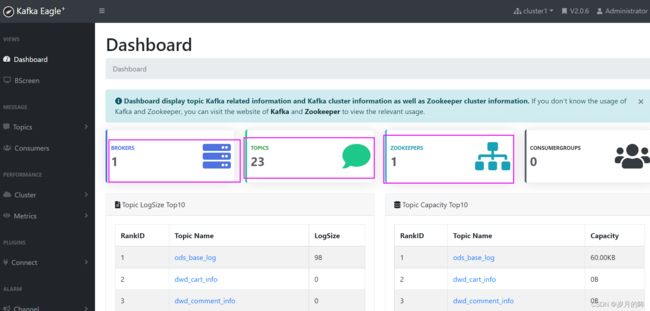
安装kafka可视化监测工具
1. kafka-Eagle客户端监测工具官网:
- 官网地址
源码: https://github.com/smartloli/kafka-eagle/
官网:https://www.kafka-eagle.org/
下载: http://download.kafka-eagle.org/
安装文档: https://docs.kafka-eagle.org/2.env-and-install
2. 软件安装
-
上传解压
-
tar -zxvf kafka-eagle-bin-2.0.6.tar.gz -
cd kafka-eagle-bin-2.0.6
-
tar -zxvf kafka-eagle-web-2.0.6-bin.tar.gz
-
mv kafka-eagle-web-2.0.6 /opt/module/
-
删除kafka-eagle-web-2.0.6-bin空文件夹
-
-
修改配置
-
cd /opt/module/kafka-eagle-web-2.0.6/
-
cd conf—>vim system-config.properties
-
## 可以配置多个集群,但是我们只有一个所以删除cluster2 4 kafka.eagle.zk.cluster.alias=cluster1 #根据自己的情况修改 5 cluster1.zk.list=flink:2181/kafka ## 配置一个不冲突的端口即可 28 kafka.eagle.webui.port=18048 ## 删除cluster2的信息,然后将cluster1的存储设置为kafka 43 cluster1.kafka.eagle.offset.storage=kafka ## 将sqllite的配置全部注释 103 # kafka sqlite jdbc driver address ## 配置Mysql数据库信息 111 # kafka mysql jdbc driver address 113 kafka.eagle.driver=com.mysql.jdbc.Driver 114 kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull 115 kafka.eagle.username=root 116 kafka.eagle.password=000000
-
-
配置Kafka的Jmx
-
修改Kafka启动脚本 vim /opt/module/kafka_2.12-0.11.0.3/bin/kafka-server-start.sh
-
添加JMX的端口
29 export JMX_PORT="19092" -
配置环境变量
-
vim /etc/profile
-
export KE_HOME=/opt/module/kafka-eagle-web-2.0.6 export PATH=$KE_HOME/bin:$PATH -
source /etc/profile
-
启动集群
-
然后启动eagle
-
-
-
启动成功访问页面:http://192.168.191.115:18048
- 用户名【admin】密码【123456】
日志采集模块-打包单机部署
-
将gmall-logger达成jar包上传至/opt/module/applog,并将名字改为gmall-logger-new.jar
-
注意application.yml 中的端口一定要和java程序中配置的端口对应上
-
数据保存到/opt/module/applog/data目录下,运行gmall-logger-new.jar程序和gmall-mock-log.jar 程序,并启动kafka服务和消费者
-
最终数据打印到控制台,显示正常,数据写入log文件正常
控制台打印的数据和kafka接收到的数据打印至控制台:
至此证明单节点的日志采集和对接kafka完成
日志采集-Nginx负载均衡
负载均衡配置
模拟数据以后应该发给 nginx,然后 nginx 再转发给我们的日志服务器.
日志服务器由于我们是单节点,因此配置一台即可;如果是集群需要配置多台
-
- 打开 nginx 配置文件
- cd /opt/module/nginx/conf
vim nginx.conf 修改如下配置
http {
# 启动省略
upstream logcluster{
server flink:8081 weight=1;
#server hadoop102:8081 weight=1;
#server hadoop103:8081 weight=1;
#server hadoop104:8081 weight=1;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
#root html;
#index index.html index.htm;
# 代理的服务器集群 命名随意, 但是不能出现下划线
proxy_pass http://logcluster;
proxy_connect_timeout 10;
}
# 其他省略
}
- 测试,先启动日志服务器的日志处理程序;—>然后启动kafka消费者
- kafka消费者:kafka-console-consumer.sh --bootstrap-server flink:9092 --topic ods_base_log
- 最后启动日志mock程序
- 注意:不要忘了修改mock数据jar程序的对应配置文件application.yml文件中的端口为80
业务数据的采集
MySQL 的 binlog
(1) 什么是 binlog
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的 DDL 和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
- 其一:MySQL Replication 在 Master 端开启 binlog,Master 把它的二进制日志传递给 slaves 来达到 master- slave 数据一致的目的。
- 其二:自然就是数据恢复了,通过使用 mysqlbinlog 工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
(2) binlog 的开启
-
开启Mysql的binlog日志检测—> vim /etc/my.cnf
-
-开启对那个数据库监测 -设置为行级读取
-
-
测试向数据库中的某张表添加一条数据,看binlog能否监测到
(3) Binlog 的分类设置
mysql binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW
在配置文件中可以选择配置 binlog_format= statement|mixed|row
三种格式的区别:
- statement
语句级,binlog 会记录每次一执行写操作的语句。
相对 row 模式节省空间,但是可能产生不一致性,比如update tt set create_date=now();如果用 binlog 日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
- row
行级, binlog 会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql 是什么,引用了什么函数,他只记录执行后的效果。 缺点:占用较大空间。
- mixed
statement 的升级版,一定程度上解决了,因为一些情况而造成的statement 模式不一致问题;默认还是statement,在某些情况下譬如:
当函数中包含 UUID() 时;包含 AUTO_INCREMENT 字段的表被更新时;执行 INSERT DELAYED 语句时;用 UDF 时;会按照 ROW 的方式进行处理。
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外 statement 和 mixed 对于需要
对 binlog 的监控的情况都不方便。
综合上面对比,Cannel 想做监控分析,选择 row 格式比较合适
Flink-CDC
1 . 什么是 CDC
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
2. CDC 的种类
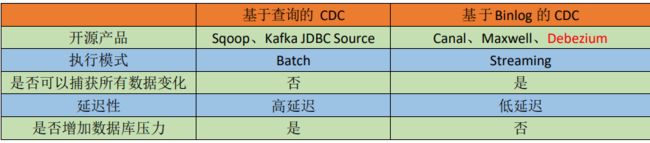
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:
3.Flink-CDC
Flink -CDC是内置了Debezium,然后可以直接获取业务数据库的数据变化,然后将数据直接写入到flink框架中,无需Canal–> kafka–>flink;因此效率比较高。
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:
https://github.com/ververica/flink-cdc-connectors
FlinkCDC 案例实操
DataStream 方式的应用
pom依赖
org.apache.flink
flink-java
1.12.0
org.apache.flink
flink-streaming-java_2.12
1.12.0
org.apache.flink
flink-clients_2.12
1.12.0
org.apache.hadoop
hadoop-client
3.1.3
mysql
mysql-connector-java
5.1.49
com.alibaba.ververica
flink-connector-mysql-cdc
1.2.0
com.alibaba
fastjson
1.2.75
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
代码案例
DataStream API官网案例
官方文档

案例demo
-
- 获取执行环境
-
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- 通过FLinkCDC构建SourceFunction并读取数据
-
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder() .hostname("hadoop102") .port(3306) .username("root") .password("000000") .databaseList("gmall--flink") .tableList("gmall-flink.z_user_info") //如果不添加该参数,则消费指定数据库中所有表的数据.如果指定,指定方式为db.table .deserializer(new StringDebeziumDeserializationSchema()) .startupOptions(StartupOptions.initial()) .build(); DataStreamSource<String> streamSource = env.addSource(sourceFunction);
-
- 打印数据
-
streamSource.print();
-
- 启动任务
-
env.execute("FlinkCDC");
最终代码案例
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 开启CK并指定状态后端为FS memory fs rocksdb
env.setStateBackend(new FsStateBackend("hdfs://flink:8020/gmall-flink/ck"));
env.enableCheckpointing(5000L);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(10000L);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//2.通过FlinkCDC构建SourceFunction并读取数据
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("flink") //主机名
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall--flink")//读取那个数据库
.tableList("gmall-flink.z_user_info")//如果不添加该参数,则消费指定数据库中所有表的数据.如果指定,指定方式为db.table
.deserializer(new StringDebeziumDeserializationSchema())
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3.打印数据
streamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
案例测试
1) 打包并上传至 Linux
2) 开启 MySQL Binlog 并重启 MySQL
3)启动 Flink 集群
4) 启动 HDFS 集群
5) 启动程序
6) 在 MySQL 的 gmall-flink.z_user_info 表中添加、修改或者删除数据
7) 给当前的Flink 程序创建 Savepoint
bin/flink savepoint JobId
hdfs://hadoop102:8020/flink/save
8) 关闭程序以后从 Savepoint 重启程序
bin/flink run -s hdfs://hadoop102:8020/flink/save/... -c
com.xxx.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar
FlinkSQL 方式的应用
pom依赖
org.apache.flink
flink-table-planner-blink_2.12
1.12.0
代码实现
public class FlinkSQL_CDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info (" +
"
id INT," +
" name STRING," +
" phone_num STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'hadoop102'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '000000'," +
" 'database-name' = 'gmall-flink'," +
" 'table-name' = 'z_user_info'" +
")");
tableEnv.executeSql("select * from user_info").print();
env.execute();
}
}
Flink-CDC可以做到断点续传,但是需要设置checkpoint,从保存点读取。
自定义反序列化器
代码实现
public class Flink_CDCWithCustomerSchema {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.创建 Flink-MySQL-CDC 的 Source
Properties properties = new Properties();
//initial (default): Performs an initial snapshot on the monitored database tables upon
first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first
startup, just read from the end of the binlog which means only have the changes since the
connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first
startup, and directly read binlog from the specified timestamp. The consumer will traverse the
binlog from the beginning and ignore change events whose timestamp is smaller than the
specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon
first startup, and directly read binlog from the specified offset.
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-flink")
.tableList("gmall-flink.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
.deserializer(new DebeziumDeserializationSchema<String>() { //自定义数据解析器
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String>
collector) throws Exception {
//获取主题信息,包含着数据库和表名
mysql_binlog_source.gmall-flink.z_user_info
String topic = sourceRecord.topic();
String[] arr = topic.split("\\.");
String db = arr[1];
String tableName = arr[2];
//获取操作类型 READ DELETE UPDATE CREATE
Envelope.Operation operation =
Envelope.operationFor(sourceRecord);
//获取值信息并转换为 Struct 类型
Struct value = (Struct)sourceRecord.value();
//获取变化后的数据
Struct after = value.getStruct("after");
//创建 JSON 对象用于存储数据信息
JSONObject data = new JSONObject();
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
//创建 JSON 对象用于封装最终返回值数据信息
JSONObject result = new JSONObject();
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
//发送数据至下游
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
//3.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//4.打印数据
mysqlDS.print();
//5.执行任务
env.execute();
}
}
原始的反序列化器仅是调用了内置的toString方法,对后期的数据处理不方便。因此需要自定义反序列化器。
自定义反序列化器代码
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//1.创建JSON对象用于存储最终数据
JSONObject result = new JSONObject();
//2.获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct value = (Struct) sourceRecord.value();
//3.获取"before"数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4.获取"after"数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5.获取操作类型 CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
//6.将字段写入JSON对象
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
//7.输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
- FlinkCDC:
Datastream:
优点: 多库多表
缺点: 需要自定义反序列化器(灵活) - FlinkSQL:
优点: 不需要自定义反序列化器
缺点: 单表查询
| FlinkCDC | Maxwell | Canal | |
|---|---|---|---|
| 断点续传 | checkpoint | Mysql | 本地磁盘 |
| SQL–>数据 | 无 | 无 | 一对一(炸开) |
| 初始化功能 | 有(多库多表) | 有(单表) | 无(单独查询) |
| 封装格式 | 自定义 | JSON | JSON (c/s自定义) |
| 高可用 | 运行集群高可用 | 无 | 集群(ZK) |
Maxwell
安装Maxwell
将下载好的压缩包解压
解压 maxwell-1.25.0.tar.gz 到/opt/module 目录
tar -zxvf /opt/software/maxwell-1.25.0.tar.gz -C /opt/module/
初始化 Maxwell 元数据库
1) 在 MySQL 中建立一个 maxwell 库用于存储 Maxwell 的元数据
[root@flink module]$ mysql -uroot -p000000
mysql> CREATE DATABASE maxwell;
2) 设置安全级别
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
3) 分配一个账号可以操作该数据库
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%' IDENTIFIED BY '000000';
4) 分配这个账号可以监控其他数据库的权限
mysql> GRANT SELECT ,REPLICATION SLAVE , REPLICATION CLIENT ON *.* TO maxwell@'%';
使用 Maxwell 监控抓取 MySQL 数据
-
拷贝配置文件
-
[root@flink maxwell-1.25.0]$ cp config.properties.example config.properties
-
-
修改配置文件
producer=kafka
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#需要添加
kafka_topic=ods_base_db_m
# mysql login info
host=hadoop102
user=maxwell
password=000000
#需要添加 初始化会用
client_id=maxwell_1
注意:
默认还是输出到指定 Kafka 主题的一个 kafka 分区,因为多个分区并行可能会打乱binlog 的顺序。如果要提高并行度,首先设置 kafka 的分区数>1,然后设置 producer_partition_by 属性可选值 producer_partition_by=database|table|primary_key|random| column
- 在/home/bin 目录下编写 maxwell.sh 启动脚本
vim /home/atguigu/bin/maxwell.sh /opt/module/maxwell-1.25.0/bin/maxwell --config
/opt/module/maxwell-1.25.0/config.properties >/dev/null 2>&1 &
- 授予执行权限
chmod +x /home/atguigu/bin/maxwell.sh
- 运行启动程序
[root@flink maxwell-1.25.0]$ maxwell.sh
- 启动Kafka 消费客户端,观察结果
bin/kafka-console-consumer.sh --bootstrap-server flink:9092 --topic ods_base_db_m
为数据库gmall-flink下的base_trademark表中添加一条数据看maxwell能否监测到
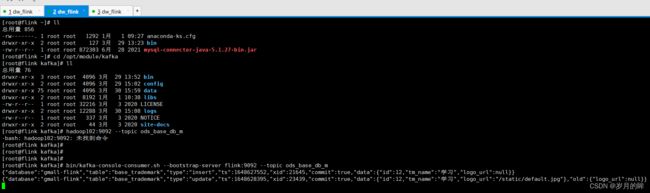
Maxwell监测到表的变化,并将这个变化的数据信息写入到kafka,并打印到控制台
执行/opt/module/dblog 下的 jar 生成模拟数据
java -jar gmall2020-mock-db-2020-11-27.jar
Canal 搭建使用教程
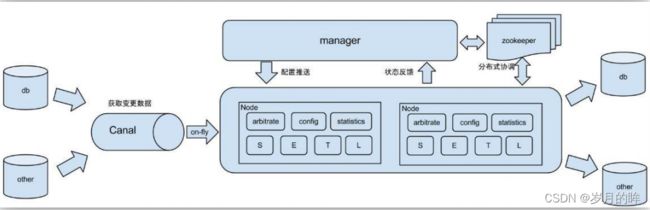
什么是 Canal
阿里巴巴 B2B 公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外, 所以衍生出了同步杭州和美国异地机房的需求,从 2010 年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。
Canal 是用java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,Canal 主要支持了 MySQL 的 Binlog 解析,解析完成后才利用Canal Client 来处理获得的相关数据。(数据库同步需要阿里的Otter 中间件,基于Canal)。
使用场景
(1) 原始场景: 阿里 Otter 中间件的一部分
Otter 是阿里用于进行异地数据库之间的同步框架,Canal 是其中一部分。
(2) 常见场景1:更新缓存
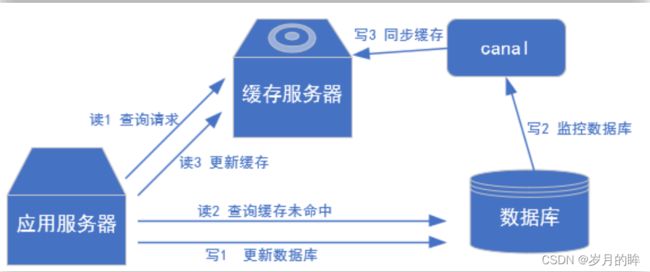
(3) 常见场景2:抓取业务数据新增变化表,用于制作拉链表。
(4) 常见场景3:抓取业务表的新增变化数据,用于制作实时统计(我们就是这种场景)
Canal 的工作原理
(1) MySQL 主从复制过程
- Master 主库将改变记录,写到二进制日志(Binary log)中
- Slave 从库向 mysql master 发送 dump 协议,将master 主库的 binary log events拷贝到它的中继日志(relay log);
- Slave 从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
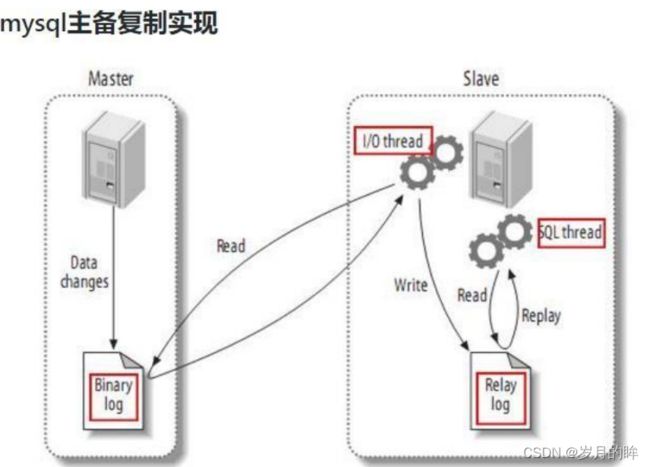
(2) Canal 的工作原理
很简单,就是把自己伪装成 Slave,假装从Master 复制数据
Canal安装
下载安装包
- https://github.com/alibaba/canal/releases
解压安装
[root@flink software]$ tar -zxvf canal.deployer-1.1.4.tar.gz -C /opt/module/canal
canal 单机版
- 修改/opt/module/canal/conf/canal.properties 的配置 vim canal.properties
- 这个文件是 canal 的基本通用配置,canal 端口号默认就是 11111
- 修改 canal 的输出 model,默认 tcp,改为输出到 kafka

-
tcp 就是输出到 canal 客户端,通过编写 Java 代码处理
-
修改Kafka 集群的地址

-
如果创建多个实例通过前面 canal 架构,我们可以知道,一个 canal 服务中可以有多个 instance,conf/下的每一个example 即是一个实例,每个实例下面都有独立的配置文件。默认只有一个实例 example,如果需要多个实例处理不同的 MySQL 数据的话,直接拷贝出多个 example,并对其重新命名,命名和配置文件中指定的名称一致,然后修改 canal.properties 中的
canal.destinations=实例 1,实例 2,实例 3。 -
修改 instance.properties
-
我们这里只读取一个 MySQL 数据,所以只有一个实例,这个实例的配置文件在conf/example 目录下
-
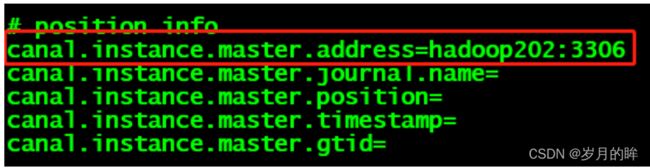
配置 MySQL 服务器地址
-
配置连接 MySQL 的用户名和密码,默认就是我们前面授权的 canal

-
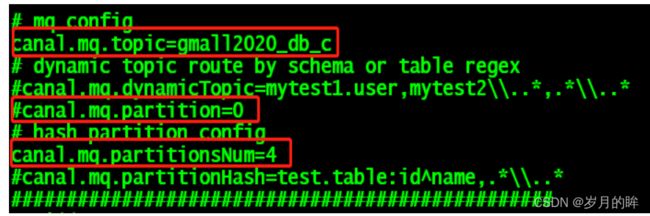
修改输出到 Kafka 的主题以及分区数
-
-
注意:
默认还是输出到指定 Kafka 主题的一个 kafka 分区,因为多个分区并行可能会打乱binlog 的顺序;如果要提高并行度,首先设置 kafka 的分区数>1,然后设置 canal.mq.partitionHash 属性.
单机 canal 测试
-
启动 canal
- cd /opt/module/canal/
- bin/startup.sh
-
看到CanalLauncher 你表示启动成功,同时会创建gmall2022_db_c 主题
-
启动Kafka 消费客户端测试,查看消费情况
- bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic gmall2020_db_c
-
运行/opt/module/dblog 中生成模拟数据
业务数据库采集
创建实时业务数据库—>gmall-flink
导入sql脚本,修改/etc/my.cnf 文件
[root@flink module]$ vim /etc/my.cnf
server-id= 1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=gmall-flink
重启 MySQL 使配置生效–>systemctl restart mysqld
使用脚本将业务数据和日志数据采集到kafka的对应topic中
DWD-DIM 层数据准备
复习Flink中的状态state
状态概念
流式计算分为无状态和有状态两种情况:
1.无状态:无状态的计算观察每个独立事件,并根据最后一个事件输出结果
2.有状态:有状态的计算则会基于多个事件输出结果(需要多个事件结果进行聚合操作)。
3.有状态的部分场景:
(1).所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算。
(2).所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差 20 度以上的温度读数,则发出警告,这是有状态的计算。
(3).流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算
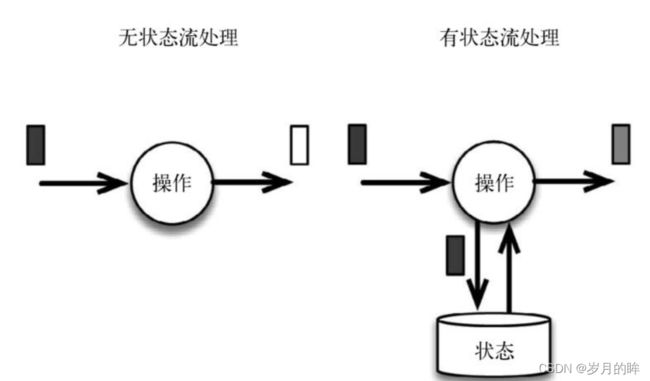
状态区别
无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条)。
有状态流处理会维护状态(根据每条输入记录进行更新),并基于最新输入的记录和当前的状态值生成输出记录(灰条)。
即:有状态的输出中,会将状态值也输出
图示:
flink中的状态
1.由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态
2.可以认为状态就是一个本地变量,可以被业务逻辑访问
3.flink会进行状态管理,包括一致性、故障处理、以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑
4.在flink中,状态始终是与特定的算子相关联
5.为了使运行时的flink算子了解算子的状态,算子需要预先注册其状态
6.总的分两种:
算子状态(Operator state):算子状态的作用范围限定为算子任务
键控状态(keyed State) :根据输入数据流中定义的键来维护和访问,处理keyby之后的数据流,即keyedStream流
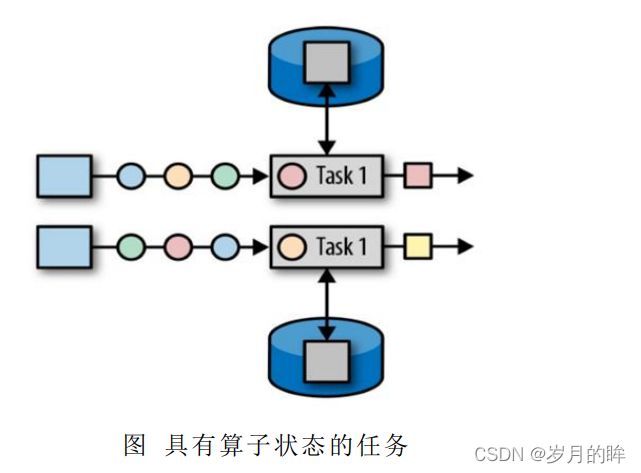
7.算子状态:
作为范围限定为算子任务,由同一并行任务所处理的数据都可以访问到相同的状态
状态对同一任务而言是共享的
算子状态不能由相同或不同算子的另一个任务访问
引入状态编程
Flink 内置的很多算子,数据源 source,数据存储 sink、transform算子 都是有状态的。
1.原因:
如果一个task在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义上(at least once, exactly once),Flink引入了state和checkpoint。
2.state:状态
指一个具体的task/operator(基于算子的状态)的状态【state数据默认保存在java的堆内存中】
分类:
算子状态(operator state) :算子之后的数据流
键控状态(keyed state):keyby之后的数据流即 keyedStream
Keyed State和Operator State,可以以两种形式存在:
原始状态(raw state)
托管状态(managed state)
托管状态:由Flink框架管理的状态
原始状态:由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。
通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。
flink状态的分类和基本数据结构
总结为2大类8种基本数据结构
- flink中的状态state分两大类:算子状态和键控状态
算子状态的使用
(1) 算子状态operator state
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
(2)Flink 为算子状态提供三种基本数据结构:
- 列表状态(List state)
将状态表示为一组数据的列表。 - 联合列表状态(Union list state)
也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。 - 广播状态(Broadcast state)
如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
(3)operator state代码示例
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问;
- 总结:算子状态作用范围限定为算子任务,是在一个任务中共享,任务中的算子可以访问。
operator state 代码实现
-
需要实现CheckpointedFunction 或ListCheckpointed接口
- 其中CheckpointedFunction需要实现如下两个方法:
- void snapshotState(FunctionSnapshotContext context) throws Exception
- void initializeState(FunctionInitializationContext context) throws Exception
- 其中CheckpointedFunction需要实现如下两个方法:
-
示例:
-
public class BufferingSink implements SinkFunction<Tuple2<String, Integer>>, CheckpointedFunction { private final int threshold; private transient ListState<Tuple2<String, Integer>> checkpointedState; private List<Tuple2<String, Integer>> bufferedElements; public BufferingSink(int threshold) { this.threshold = threshold; this.bufferedElements = new ArrayList<>(); } // 将状态信息写到缓存的方法 @Override public void invoke(Tuple2<String, Integer> value) throws Exception { // 将状态信息写到缓存 bufferedElements.add(value); // 如果缓存的size达到阈值,则持久化 if (bufferedElements.size() == threshold) { for (Tuple2<String, Integer> element: bufferedElements) { // send it to the sink } bufferedElements.clear(); } } // 快照方法,将缓存的数据进行保存,保存到堆内存(checkpointedState) @Override public void snapshotState(FunctionSnapshotContext context) throws Exception { checkpointedState.clear(); for (Tuple2<String, Integer> element : bufferedElements) { checkpointedState.add(element); } } //初始化 @Override public void initializeState(FunctionInitializationContext context) throws Exception { ListStateDescriptor<Tuple2<String, Integer>> descriptor = new ListStateDescriptor<>( "buffered-elements", TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {})); checkpointedState = context.getOperatorStateStore().getListState(descriptor); // 用于恢复数据的逻辑 if (context.isRestored()) { for (Tuple2<String, Integer> element : checkpointedState.get()) { bufferedElements.add(element); } } } }
键控状态的使用
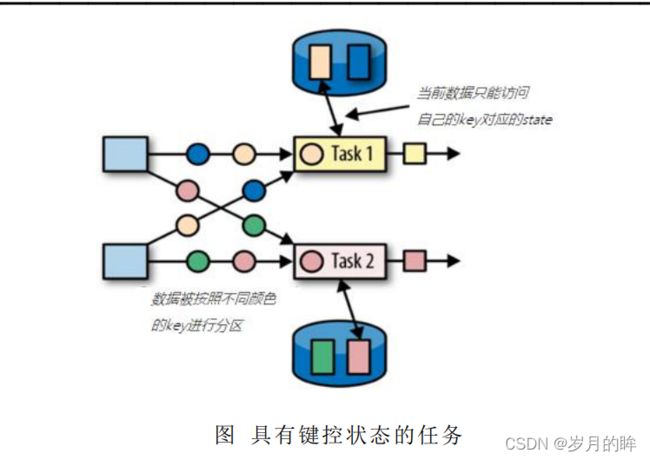
**键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。**当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。因此,具有相同 key 的所有数据都会访问相同的状态。Keyed State 很类似于一个分布式的 key-value map 数据结构,只能用于 KeyedStream(keyBy 算子处理之后)。
(1) Flink 的 Keyed State 支持以下五种数据类型:
-
ValueState[T]保存单个的值,值的类型为 T。
- get 操作: ValueState.value()
- set 操作: ValueState.update(value: T)
-
ListState[T]保存一个列表,列表里的元素的数据类型为 T。基本操作如下:
-
ListState.add(value: T)
-
ListState.addAll(values: java.util.List[T])
-
ListState.get()返回 Iterable[T]
-
ListState.update(values: java.util.List[T])
-
MapState[K, V]保存 Key-Value 对。
- MapState.get(key: K)
- MapState.put(key: K, value: V)
- MapState.contains(key: K)
- MapState.remove(key: K)
-
ReducingState[T]
-
AggregatingState[I, O]
State.clear()是清空操作。
(2)键控状态编程的使用大体上有3种方式:
- 使用富函数,如:main函数中keyBy之后调用算子,转入一个实现富函数 RichFlatMapFunction。
- 通过 RuntimeContext 注册 StateDescriptor。StateDescriptor 以状态 state 的名字和存储的数据类型为参数。
在 open()方法中创建 state 变量。
- 通过 RuntimeContext 注册 StateDescriptor。StateDescriptor 以状态 state 的名字和存储的数据类型为参数。
- 在main函数中,keyby之后调用process方法传入一个KeyedProcessFunction类的实现类。
- keyBy之后直接flatMapWithState ,flatMapWithState[(输出类型的泛型),状态值的泛型]
总结说明:
基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state。
保存状态的数据结构:
1.ValueState:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。
状态更新:update()
状态获取:value()
2.ListState:即key上的状态值为一个列表。
状态添加:add()方法往列表中附加值
状态获取:get()方法返回一个Iterable来遍历状态值
3.ReducingState:这种状态通过用户传入的reduceFunction,状态最终是一个单一的值
状态更新:每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值
4.MapState:即状态值为一个map。
添加:通过put或putAll方法添加元素
示例:keyed state的代码实现
第一种方式:
//1.在main函数中,keyby之后调用process方法传入一个KeyedProcessFunction类的实现类:
main{
val processedStream = dataStream.keyBy(_.id)
.process( new TempIncreAlert() )
}
//2.在自定义的函数中。先定义状态的存储结构
//3.用 getRunTimeContext.getState进行初始化传入状态描述器
class TempIncreAlert() extends KeyedProcessFunction[String, SensorReading, String]{
// 定义一个状态,用来保存上一个数据的温度值
lazy val lastTemp: ValueState[Double] = getRuntimeContext.getState( new ValueStateDescriptor[Double]("lastTemp", classOf[Double]) )
// 定义一个状态,用来保存定时器的时间戳
lazy val currentTimer: ValueState[Long] = getRuntimeContext.getState( new ValueStateDescriptor[Long]("currentTimer", classOf[Long]) )
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {
// 先取出上一个温度值
val preTemp = lastTemp.value()
// 更新温度值
lastTemp.update( value.temperature )
val curTimerTs = currentTimer.value()
if( value.temperature < preTemp || preTemp == 0.0 ){
// 如果温度下降,或是第一条数据,删除定时器并清空状态
ctx.timerService().deleteProcessingTimeTimer( curTimerTs )
currentTimer.clear()
} else if ( value.temperature > preTemp && curTimerTs == 0 ){
// 温度上升且没有设过定时器,则注册定时器
val timerTs = ctx.timerService().currentProcessingTime() + 5000L
ctx.timerService().registerProcessingTimeTimer( timerTs )
currentTimer.update( timerTs )
}
}
第二种方式:
//main函数中keyBy之后调用算子,转入一个实现富函数 RichFlatMapFunction
val processedStream2 = dataStream.keyBy(_.id)
.flatMap( new TempChangeAlert(10.0) )
//富函数的实现类
/**
*实现步骤:
*1.先定义一个存储状态的数据结构
*2.在open方法中初始化 getRuntimeContext.getState
*/
class TempChangeAlert(threshold: Double) extends RichFlatMapFunction[SensorReading, (String, Double, Double)]{
private var lastTempState: ValueState[Double] = _
override def open(parameters: Configuration): Unit = {
// 初始化的时候声明state变量
lastTempState = getRuntimeContext.getState(new ValueStateDescriptor[Double]("lastTemp", classOf[Double]))
}
override def flatMap(value: SensorReading, out: Collector[(String, Double, Double)]): Unit = {
// 获取上次的温度值
val lastTemp = lastTempState.value()
// 用当前的温度值和上次的求差,如果大于阈值,输出报警信息
val diff = (value.temperature - lastTemp).abs
if(diff > threshold){
out.collect( (value.id, lastTemp, value.temperature) )
}
lastTempState.update(value.temperature)
}
}
第三种方式:
//keyBy之后直接flatMapWithState
//flatMapWithState[(输出类型的泛型),状态值的泛型]
val processedStream3 = dataStream.keyBy(_.id)
.flatMapWithState[(String, Double, Double), Double]{
//用case判断输入的参数
// 如果没有状态的话,也就是没有数据来过,那么就将当前数据温度值存入状态
case ( input: SensorReading, None ) => ( List.empty, Some(input.temperature) )
// 如果有状态,就应该与上次的温度值比较差值,如果大于阈值就输出报警
case ( input: SensorReading, lastTemp: Some[Double] ) =>
val diff = ( input.temperature - lastTemp.get ).abs
if( diff > 10.0 ){
( List((input.id, lastTemp.get, input.temperature)), Some(input.temperature) )
} else
( List.empty, Some(input.temperature) )
}
更多细节复习flink状态编程和容错机制
DWD 层数据准备实现思路
-
功能 1:环境搭建
-
功能 2:计算用户行为日志 DWD 层
-
功能 3:计算业务数据DWD 层
项目环境
在工程中新建模块 gmall-realtime
创建如下包结构
| 目录 | 作用 |
|---|---|
| app | 产生各层数据的flink任务 |
| bean | 数据对象 |
| Common | 公共常量类 |
| utils | 项目中用到的工具类 |
修改配置文件
在 pom.xml 添加如下配置
1.8
${java.version}
${java.version}
1.12.0
2.12
3.1.3
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_${scala.version}
${flink.version}
org.apache.flink
flink-connector-kafka_${scala.version}
${flink.version}
org.apache.flink
flink-clients_${scala.version}
${flink.version}
org.apache.flink
flink-cep_${scala.version}
${flink.version}
org.apache.flink
flink-json
${flink.version}
com.alibaba
fastjson
1.2.68
org.apache.hadoop
hadoop-client
${hadoop.version}
org.slf4j
slf4j-api
1.7.25
org.slf4j
slf4j-log4j12
1.7.25
org.apache.logging.log4j
log4j-to-slf4j
2.14.0
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
在 resources 目录下创建 log4j.properties 配置文件
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
功能2_准备用户行为日志 DWD 层
我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层, 从 Kafka 的ODS 层读取的日志数据我们将其分为 3 类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回Kafka 不同主题中,作为日志 DWD 层。
- 页面日志输出到主流
- 启动日志输出到启动侧输出流
- 曝光日志输出到曝光侧输出流
这这一层我们有两大任务:一是识别新老用户,二是利用侧输出流实现数据拆分。
识别新老用户
思路:
本身客户端业务有新老用户的标识is_new,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)。
代码实现
1.接收 Kafka 数据,并进行转换
- 在 Kafka 的工具类中提供获取 Kafka 消费者的方法( 读)
/**
* 获取 KafkaSource 的方法
* @param topic 主题
* @param groupId 消费者组
*/
public static FlinkKafkaConsumer<String> getKafkaSource(String topic, String groupId) {
//给配置信息对象添加配置项
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//获取 KafkaSource
return new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), properties);
}
}
- Flink 调用工具类读取数据的主程序
public class BaseLogApp {
public static void main(String[] args) throws Exception {
//1.获取执行环境,设置并行度,开启 CK,设置状态后端(HDFS)
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
//为 Kafka 主题的分区数
env.setParallelism(1);
//1.1 设置状态后端
// env.setStateBackend(newFsStateBackend("hdfs://flink:8020/gmall/dwd_log/ck"));
// //1.2 开启CK
// env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000L);
//修改用户名
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//2.读取 Kafka ods_base_log 主题数据
String topic = "ods_base_log";
String groupId = "ods_dwd_base_log_app";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic,
groupId);
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
//3.将每行数据转换为 JsonObject
SingleOutputStreamOperator<JSONObject> jsonObjDS =
kafkaDS.map(JSONObject::parseObject);
//打印测试
jsonObjDS.print();
//执行任务
env.execute();
}
识别新老访客
保存每个 mid 的首次访问日期,每条进入该算子的访问记录,都会把 mid 对应的首次访问时间读取出来,只有首次访问时间不为空,则认为该访客是老访客,否则是新访客。同时如果是新访客且没有访问记录的话,会写入首次访问时间。
//4.按照 Mid 分组
KeyedStream<JSONObject, String> keyedStream = jsonObjDS.keyBy(data ->
data.getJSONObject("common").getString("mid"));
//5.使用状态做新老用户校验
SingleOutputStreamOperator<JSONObject> jsonWithNewFlagDS =
keyedStream.map(new RichMapFunction<JSONObject, JSONObject>() {
//声明状态用于表示当前 Mid 是否已经访问过
private ValueState<String> firstVisitDateState;
private SimpleDateFormat simpleDateFormat;
@Override
public void open(Configuration parameters) throws Exception {
firstVisitDateState = getRuntimeContext().getState(new
ValueStateDescriptor<String>("new-mid", String.class));
simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
}
@Override
public JSONObject map(JSONObject value) throws Exception {
//取出新用户标记
String isNew = value.getJSONObject("common").getString("is_new");
//如果当前前端传输数据表示为新用户,则进行校验
if ("1".equals(isNew)) {
//取出状态数据并取出当前访问时间
String firstDate = firstVisitDateState.value();
Long ts = value.getLong("ts");
//判断状态数据是否为 Null
if (firstDate != null) {
//修复
value.getJSONObject("common").put("is_new", "0");
} else {
//更新状态
firstVisitDateState.update(simpleDateFormat.format(ts));
}
}
//返回数据
return value;
}
});
//打印测试
//jsonWithNewFlagDS.print();
侧输出流实现数据拆分
思路:
根据日志数据内容,将日志数据分为 3 类,页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流。另外注意曝光日志是页面日志的一种,因此页面日志包含了曝光日志;处理的时候要格外注意。
//6.分流,使用 ProcessFunction 将 ODS 数据拆分成启动、曝光以及页面数据
SingleOutputStreamOperator<String> pageDS = jsonWithNewFlagDS.process(new
ProcessFunction<JSONObject, String>() {
@Override
public void processElement(JSONObject jsonObject, Context context, Collector<String>
collector) throws Exception {
//提取"start"字段
String startStr = jsonObject.getString("start");
//判断是否为启动数据
if (startStr != null && startStr.length() > 0) {
//将启动日志输出到侧输出流
context.output(new OutputTag<String>("start") {
}, jsonObject.toString());
} else {
//为页面数据,将数据输出到主流
collector.collect(jsonObject.toString());
//不是启动数据,继续判断是否是曝光数据
JSONArray displays = jsonObject.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
//为曝光数据,遍历写入侧输出流
for (int i = 0; i < displays.size(); i++) {
//取出单条曝光数据
JSONObject displayJson = displays.getJSONObject(i);
//添加页面 ID
displayJson.put("page_id",
jsonObject.getJSONObject("page").getString("page_id"));
//输出到侧输出流
context.output(new OutputTag<String>("display") {
}, displayJson.toString());
}
}
}
}
});
//7.将三个流的数据写入对应的 Kafka 主题
DataStream<String> startDS = pageDS.getSideOutput(new OutputTag<String>("start") {
});
DataStream<String> displayDS = pageDS.getSideOutput(new OutputTag<String>("display") {
});
//打印测试
pageDS.print("Page>>>>>>>>>");
startDS.print("Start>>>>>>>>>>");
displayDS.print("Display>>>>>>>>>>");
将不同流的数据推送到下游 kafka 的不同 Topic(分流)
1) 程序中调用 Kafka 工具类获取 Sink
pageDS.addSink(MyKafkaUtil.getKafkaSink("dwd_page_log"));
startDS.addSink(MyKafkaUtil.getKafkaSink("dwd_start_log"));
displayDS.addSink(MyKafkaUtil.getKafkaSink("dwd_display_log"));
2) 测试
- IDEA 中运行 BaseLogApp 类
- 运行 logger.sh,启动 Nginx 以及日志处理服务
- 运行applog 下模拟生成数据的jar 包
- 到 Kafka 不同的主题下查看输出效果
dwd层日志操作总结
数据流:web/app -> Nginx -> SpringBoot -> Kafka(ods) -> FlinkApp消费 ->写出到Kafka(dwd)
程 序:mockLog -> Nginx -> Logger.sh -> Kafka(ZK) -> BaseLogApp -> kafka
代码实现一共8步:
- 1.获取执行环境
- 2.消费 ods_base_log 主题数据创建流
- 3.将每行数据转换为JSON对象
- 4.新老用户校验 状态编程
- 5.分流 侧输出流 页面:主流 启动:侧输出流 曝光:侧输出流
- 6.提取侧输出流
- 7.将三个流进行打印并输出到对应的Kafka主题中
- 8.启动任务
public class BaseLogApp {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置CK&状态后端
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink-210325/ck"));
//env.enableCheckpointing(5000L);
//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//TODO 2.消费 ods_base_log 主题数据创建流
String sourceTopic = "ods_base_log";
String groupId = "base_log_app_210325";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtil.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为JSON对象
OutputTag<String> outputTag = new OutputTag<String>("Dirty") {
};
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() {
@Override
public void processElement(String value, Context ctx, Collector<JSONObject> out) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(value);
out.collect(jsonObject);
} catch (Exception e) {
//发生异常,将数据写入侧输出流
ctx.output(outputTag, value);
}
}
});
//打印脏数据
jsonObjDS.getSideOutput(outputTag).print("Dirty>>>>>>>>>>>");
//TODO 4.新老用户校验 状态编程
SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlagDS = jsonObjDS.keyBy(jsonObj -> jsonObj.getJSONObject("common").getString("mid"))
.map(new RichMapFunction<JSONObject, JSONObject>() {
private ValueState<String> valueState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<String>("value-state", String.class));
}
@Override
public JSONObject map(JSONObject value) throws Exception {
//获取数据中的"is_new"标记
String isNew = value.getJSONObject("common").getString("is_new");
//判断isNew标记是否为"1"
if ("1".equals(isNew)) {
//获取状态数据
String state = valueState.value();
if (state != null) {
//修改isNew标记
value.getJSONObject("common").put("is_new", "0");
} else {
valueState.update("1");
}
}
return value;
}
});
//TODO 5.分流 侧输出流 页面:主流 启动:侧输出流 曝光:侧输出流
OutputTag<String> startTag = new OutputTag<String>("start") {
};
OutputTag<String> displayTag = new OutputTag<String>("display") {
};
SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlagDS.process(new ProcessFunction<JSONObject, String>() {
@Override
public void processElement(JSONObject value, Context ctx, Collector<String> out) throws Exception {
//获取启动日志字段
String start = value.getString("start");
if (start != null && start.length() > 0) {
//将数据写入启动日志侧输出流
ctx.output(startTag, value.toJSONString());
} else {
//将数据写入页面日志主流
out.collect(value.toJSONString());
//取出数据中的曝光数据
JSONArray displays = value.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
//获取页面ID
String pageId = value.getJSONObject("page").getString("page_id");
for (int i = 0; i < displays.size(); i++) {
JSONObject display = displays.getJSONObject(i);
//添加页面id
display.put("page_id", pageId);
//将输出写出到曝光侧输出流
ctx.output(displayTag, display.toJSONString());
}
}
}
}
});
//TODO 6.提取侧输出流
DataStream<String> startDS = pageDS.getSideOutput(startTag);
DataStream<String> displayDS = pageDS.getSideOutput(displayTag);
//TODO 7.将三个流进行打印并输出到对应的Kafka主题中
startDS.print("Start>>>>>>>>>>>");
pageDS.print("Page>>>>>>>>>>>");
displayDS.print("Display>>>>>>>>>>>>");
startDS.addSink(MyKafkaUtil.getKafkaProducer("dwd_start_log"));
pageDS.addSink(MyKafkaUtil.getKafkaProducer("dwd_page_log"));
displayDS.addSink(MyKafkaUtil.getKafkaProducer("dwd_display_log"));
//TODO 8.启动任务
env.execute("BaseLogApp");
}
}
测试
数据流:web/app -> Nginx -> SpringBoot -> Kafka(ods) -> FlinkApp消费 ->写出到Kafka(dwd)
程 序:mockLog -> Nginx -> Logger.sh -> Kafka(ZK) -> BaseLogApp -> kafka
- 启动nginx.sh start、启动kafka
- 启动kafka消费者[root@flink kafka]# bin/kafka-console-consumer.sh --bootstrap-server flink:9092 --topic ods_base_log
- 启动生成日志数据脚本:cd /opt/module/applog
- java -jar gmall-mock-log.jar
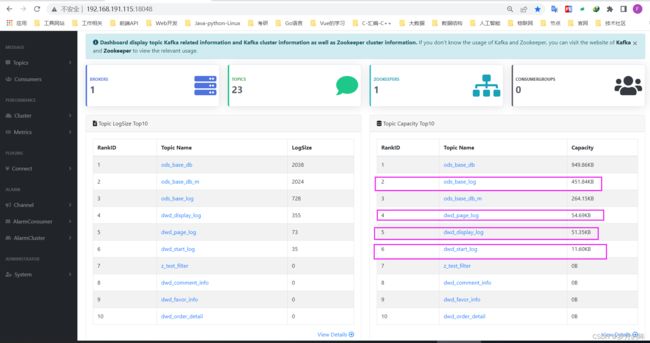
kafka_Eagle页面显示:
功能3_准备业务数据 DWD 层
业务数据的变化,我们可以通过 FlinkCDC 采集到,但是FlinkCDC 是把全部数据统一写入一个 Topic 中, 这些数据包括事实数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从Kafka 的业务数据ODS 层读取数据,经过处理后,将维度数据保存到 HBase,将事实数据写回Kafka 作为业务数据的 DWD 层。
主要任务
- 接收 Kafka 数据,过滤空值数据
对 FlinkCDC 抓取数据进行 ETL,有用的部分保留,没用的过滤掉。
- 实现动态分流功能
由于FlinkCDC 是把全部数据统一写入一个Topic 中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表, 就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
-
一种是用Zookeeper 存储,通过 Watch 感知数据变化;
-
另一种是用 mysql 数据库存储,周期性的同步;
-
另一种是用 mysql 数据库存储,使用广播流。
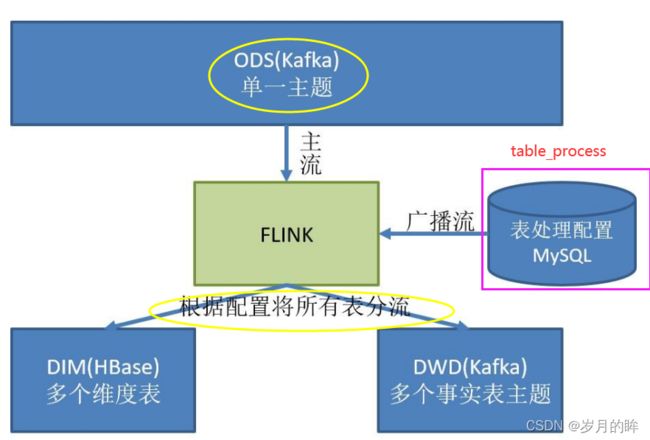
这里选择第二种方案,主要是 MySQL 对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
所以就有了如下图:
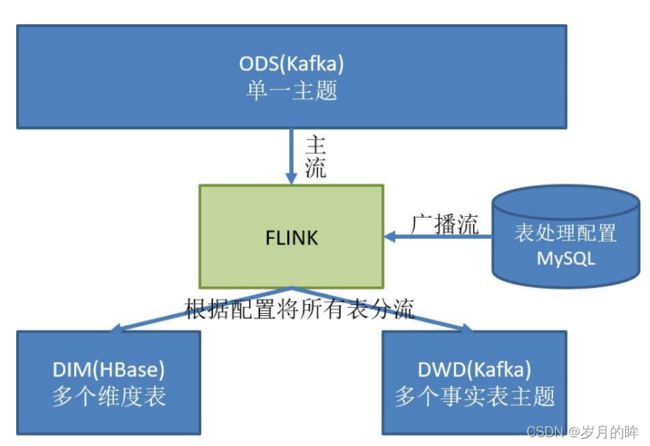
把分好的流保存到对应表、主题中
- 业务事实数据保存到 Kafka 的主题中
- 维度数据保存到 HBase 的表中
代码实现
我们首先需要思考的是业务库中有46张表,那么如果使用侧输出流进行处理,就需要写46个if …else语句进行处理;如此将会十分繁琐,还容易出错!另外是如果后期业务数据增加,有新的表,就需要暂停计算程序,然后再补充侧输出流;显然这个操作很不合理!
如果我们可以通过动态的方式根据表创建kafka主题、HBase表,就方便多了;那么我们该怎么办?
思路是:
-
创建一个gmall-realtime库,然后设计一个table_process表,对这个库开启binlog设置;然而表中字段该如何设置呢?
-
首先,我们处理这些表需要知道数据来源表名、操作类型operate type、写出到那里,也就是sink端是hbase还是kafka,如果是事实数据就写到kafka的主题中,如果是维度数据写出到HBase;那么对应写出到那个主题或库下面的表;主题名称和hbase表名是什么?
-
其次是写出到topic或表中的字段有哪些,字段是否为主键;另外如果是建表,执行引擎是什么?等等需要一个扩展字段。
table_process表的字段怎么设置
| sourceTable | type | sinkType | sinkTable | sinkColumn | pk | extend |
|---|---|---|---|---|---|---|
| base_trademark | insert | hbase | dim_base_trademark(Phoenix表名) | |||
| order_info | insert | Kafka | dwd_order_info_ins(主题名)–>新增 | |||
| order_info | update | kafka | dwd_order_info_up (主题名)—>变化 |
建表语句
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
MySQL 对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接形成连接流。
所以就有了如下图:
代码逻辑,一共是9步:
-
- 获取执行环境
-
- 消费Kafka ods_base_db主题数据创建流
-
- 将每行数据转换为SON对象并过滤(delete)–>主流
-
- 使用FLinkCDC消费配置表并处理成–>广播流
-
- 连接主流和广播流
-
- 分流处理数据,广播流数据、主流数据根据广播流数据进行处理)
-
- 提取Kafka流数据和HBase流数据
-
- 将Kafka数据写入Kafka主题,将HBase数据写入Phoenix表
-
- 启动任分
接收 Kafka 数据,过滤空值数据
public class BaseDBApp {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置状态后端
//env.setStateBackend(new
//FsStateBackend("hdfs://hadoop102:8020/gmall/dwd_log/ck"));
//1.2 开启 CK
//env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(60000L);
//2.读取 Kafka 数据
String topic = "ods_base_db_";
String groupId = "ods_db_group";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic,
groupId);
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
//3.将每行数据转换为 JSON 对象
SingleOutputStreamOperator<JSONObject> jsonObjDS =
kafkaDS.map(JSON::parseObject);
//4.过滤
SingleOutputStreamOperator<JSONObject> filterDS = jsonObjDS.filter(new
FilterFunction<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
//获取 data 字段
String data = value.getString("data");
return data != null && data.length() > 0;
}
});
//打印测试
filterDS.print();
//7.执行任务
env.execute();
}
}
根据mysql的配置表_动态进行分流
1) 引入 pom.xml 依 赖
org.projectlombok
lombok
1.18.12
org.apache.flink
flink-connector-jdbc_${scala.version}
${flink.version}
org.apache.phoenix
phoenix-spark
5.0.0-HBase-2.0
org.glassfish
javax.el
2) 在 Mysql 中创建数据库,创建配置表 table_process
建表语句:
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
3) 在 MySQL 配置文件中增加 gmall_realtime 开启 Binlog
4) 创建配置表实体类
import lombok.Data;
@Data
public class TableProcess{
//动态分流 Sink 常量
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
String sourceTable;
//操作类型 insert,update,delete
String operateType;
//输出类型 hbase kafka
String sinkType;
//输出表(主题)
String sinkTable;
//输出字段
String sinkColumns;
//主键字段
String sinkPk;
//建表扩展
String sinkExtend;
}
5) 编写操作读取配置表形成广播流
//5.创建 MySQL CDC Source
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("flink")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-realtime")
.tableList("gmall-realtime.table_process")
.deserializer(new DebeziumDeserializationSchema<String>() {
//反序列化方法
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector)
throws Exception {
//库名&表名
String topic = sourceRecord.topic();
String[] split = topic.split("\\.");
String db = split[1];
String table = split[2];
//获取数据
Struct value = (Struct) sourceRecord.value();
Struct after = value.getStruct("after");
JSONObject data = new JSONObject();
if (after != null) {
Schema schema = after.schema();
for (Field field : schema.fields()) {
data.put(field.name(), after.get(field.name()));
}
}
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//创建JSON 用于存放最终的结果
JSONObject result = new JSONObject();
result.put("database", db);
result.put("table", table);
result.put("type", operation.toString().toLowerCase());
result.put("data", data);
collector.collect(result.toJSONString());
}
//定义数据类型
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
//6.读取 MySQL 数据
DataStreamSource<String> tableProcessDS = env.addSource(sourceFunction);
//7.将配置信息流作为广播流
MapStateDescriptor<String, TableProcess> mapStateDescriptor = new
MapStateDescriptor<>("table-process-state", String.class, TableProcess.class);
BroadcastStream<String> broadcastStream = tableProcessDS.broadcast(mapStateDescriptor);
//8.将主流和广播流进行链接
BroadcastConnectedStream<JSONObject, String> connectedStream =
filterDS.connect(broadcastStream);
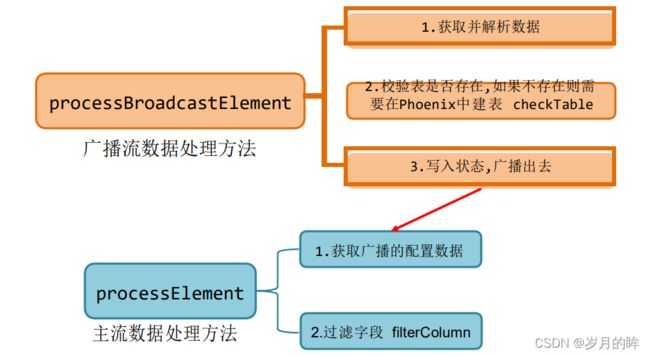
6) 程序流程分析
TableProcessFunction(BroadcastProcessFunction)
7) 定义一个项目中常用的配置常量类 GmallConfig
public class GmallConfig {
//Phoenix 库名
public static final String HBASE_SCHEMA = "GMALL_REALTIME";
//Phoenix 驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
//Phoenix 连接参数
public static final String PHOENIX_SERVER =
"jdbc:phoenix:flink:2181";
}
8) 自定义函数 TableProcessFunction
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class TableProcessFunction extends BroadcastProcessFunction<JSONObject, String,
JSONObject> {
privateOutputTag<JSONObject> outputTag;
public TableProcessFunction(OutputTag<JSONObject> outputTag) {
this.outputTag = outputTag;
}
@Override
public void processElement(JSONObject jsonObject, ReadOnlyContext readOnlyContext,
Collector<JSONObject> collector) throws Exception {
}
@Override
public void processBroadcastElement(String s, Context context, Collector<JSONObject>
collector) throws Exception {
}
}
9) 自定义函数 TableProcessFunction-open
//定义 Phoenix 的连接
private Connection connection = null;
@Override
public void open(Configuration parameters) throws Exception {
//初始化 Phoenix 的连接
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
10) 自定义函数 TableProcessFunction-processBroadcastElement
@Override
public void processBroadcastElement(String jsonStr, Context context, Collector<JSONObject>
collector) throws Exception {
//获取状态
BroadcastState<String, TableProcess> broadcastState =
context.getBroadcastState(mapStateDescriptor);
//将配置信息流中的数据转换为 JSON 对象
{"database":"","table":"","type","","data":{"":""}}
JSONObject jsonObject = JSON.parseObject(jsonStr);
//取出数据中的表名以及操作类型封装 key
JSONObject data = jsonObject.getJSONObject("data");
String table = data.getString("source_table");
String type = data.getString("operate_type");
String key = table + ":" + type;
//取出 Value 数据封装为 TableProcess 对象
TableProcesstableProcess = JSON.parseObject(data.toString(), TableProcess.class);
checkTable(tableProcess.getSinkTable(),tableProcess.getSinkColumns(),tableProcess.getSinkPk(),t
ableProcess.getSinkExtend());
System.out.println("Key:" + key + "," + tableProcess);
//广播出去
broadcastState.put(key, tableProcess);
}
11) 自定义函数 TableProcessFunction-checkTable
/**
* Phoenix 建表
* @param sinkTable 表名 test
* @param sinkColumns 表名字段 id,name,sex
* @param sinkPk 表主键 id
* @param sinkExtend 表扩展字段 ""
* create table if not exists mydb.test(id varchar primary key,name
varchar,sex varchar) ...
*/
private void checkTable(String sinkTable, String sinkColumns, String sinkPk, String sinkExtend)
{
//给主键以及扩展字段赋默认值
if (sinkPk == null) {
sinkPk = "id";
}
if (sinkExtend == null) {
sinkExtend = "";
}
//封装建表 SQL
StringBuilder createSql = new StringBuilder("create table if not exists
").append(GmallConfig.HBASE_SCHEMA).append(".").append(sinkTable).append("(");
//遍历添加字段信息
String[] fields = sinkColumns.split(",");
for (int i = 0; i < fields.length; i++) {
//取出字段
String field = fields[i];
//判断当前字段是否为主键
if (sinkPk.equals(field)) {
createSql.append(field).append(" varchar primary key ");
} else {
createSql.append(field).append(" varchar ");
}
//如果当前字段不是最后一个字段,则追加","
if (i < fields.length - 1) {
createSql.append(",");
}
}
createSql.append(")");
createSql.append(sinkExtend);
System.out.println(createSql);
//执行建表 SQL
PreparedStatement preparedStatement = null;
try {
preparedStatement = connection.prepareStatement(createSql.toString());
preparedStatement.execute();
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException("创建 Phoenix 表" + sinkTable + "失败!");
} finally {
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
});
12) 自定义函数 TableProcessFunction-processElement()
核心处理方法,根据 MySQL 配置表的信息为每条数据打标签,走Kafka 还是 HBase
@Override
public void processElement(JSONObject jsonObject, ReadOnlyContext readOnlyContext,
Collector<JSONObject> collector) throws Exception {
//获取状态
ReadOnlyBroadcastState<String, TableProcess> broadcastState =
readOnlyContext.getBroadcastState(mapStateDescriptor);
//获取表名和操作类型
String table = jsonObject.getString("table");
String type = jsonObject.getString("type");
String key = table + ":" + type;
//取出对应的配置信息数据
TableProcess tableProcess = broadcastState.get(key);
if (tableProcess != null) {
//向数据中追加 sink_table 信息
jsonObject.put("sink_table", tableProcess.getSinkTable());
//根据配置信息中提供的字段做数据过滤
filterColumn(jsonObject.getJSONObject("data"), tableProcess.getSinkColumns());
//判断当前数据应该写往 HBASE 还是 Kafka
if (TableProcess.SINK_TYPE_KAFKA.equals(tableProcess.getSinkType())) {
//Kafka 数据,将数据输出到主流
collector.collect(jsonObject);
} else if (TableProcess.SINK_TYPE_HBASE.equals(tableProcess.getSinkType())) {
//HBase 数据,将数据输出到侧输出流
readOnlyContext.output(hbaseTag, jsonObject);
}
} else {
System.out.println("No Key " + key + " In Mysql!");
}
}
13) 自定义函数 TableProcessFunction-filterColumn()
校验字段,过滤掉多余的字段
//根据配置信息中提供的字段做数据过滤
private void filterColumn(JSONObject data, String sinkColumns) {
//保留的数据字段
String[] fields = sinkColumns.split(",");
List<String> fieldList = Arrays.asList(fields);
Set<Map.Entry<String, Object>> entries = data.entrySet();
//while (iterator.hasNext()) {
//Map.Entry next = iterator.next();
//if (!fieldList.contains(next.getKey())) {
//iterator.remove();
//}
//}
entries.removeIf(next -> !fieldList.contains(next.getKey()));
}
14) 主程序 BaseDBApp 中调用 TableProcessFunction 进行分流
OutputTag<JSONObject> hbaseTag = new
OutputTag<JSONObject>(TableProcess.SINK_TYPE_HBASE) {
};
SingleOutputStreamOperator<JSONObject> kafkaJsonDS = connectedStream.process(new
TableProcessFunction(hbaseTag));
DataStream<JSONObject> hbaseJsonDS = kafkaJsonDS.getSideOutput(hbaseTag);
分流 Sink之保存维度到HBase(Phoenix)
1) 程序流程分析
维度数据写入HBase
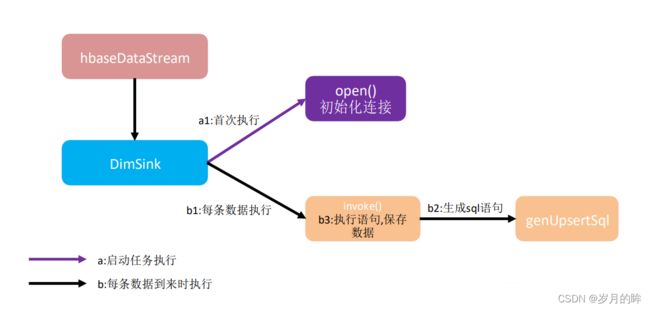
DimSink 继承了 RickSinkFunction,这个 function 得分两条时间线。
- 一条是任务启动时执行 open 操作(图中紫线),我们可以把连接的初始化工作放在此处一次性执行。
- 另一条是随着每条数据的到达反复执行 invoke()(图中黑线),在这里面我们要实现数据的保存,主要策略就是根据数据组合成 sql 提交给 hbase。
2) 因为要用单独的 schema,所以在程序中加入 hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://hadoop102:8020/HBasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>hadoop102,hadoop103,hadoop104value>
property>
<property>
<name>phoenix.schema.isNamespaceMappingEnabledname>
<value>truevalue>
property>
<property>
<name>phoenix.schema.mapSystemTablesToNamespacename>
<value>truevalue>
property>
**注意:**为了开启 hbase 的 namespace 和 phoenix 的 schema 的映射,在程序中需要加这个配置文件,另外在 linux 服务上,也需要在 hbase 以及 phoenix 的 hbase-site.xml 配置文件中,加上以上两个配置,并使用 xsync 进行同步。
3) 在 phoenix 中执行
create schema GMALL_REALTIME;
4) DimSink
public class DimSink extends RichSinkFunction<JSONObject> {
private Connection connection = null;
@Override
public void open(Configuration parameters) throws Exception {
//初始化 Phoenix 连接
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
}
//将数据写入 Phoenix:upsert into t(id,name,sex) values(...,...,...)
@Override
public void invoke(JSONObject jsonObject, Context context) throws Exception {
PreparedStatement preparedStatement = null;
try {
//获取数据中的 Key 以及 Value
JSONObject data = jsonObject.getJSONObject("data");
Set<String> keys = data.keySet();
Collection<Object> values = data.values();
//获取表名
String tableName = jsonObject.getString("sink_table");
//创建插入数据的 SQL
String upsertSql = genUpsertSql(tableName, keys, values);
System.out.println(upsertSql);
//编译 SQL
preparedStatement = connection.prepareStatement(upsertSql);
//执行
preparedStatement.executeUpdate();
//提交
connection.commit();
} catch (SQLException e) {
e.printStackTrace();
System.out.println("插入 Phoenix 数据失败!");
} finally {
if (preparedStatement != null) {
preparedStatement.close();
}
}
}
//创建插入数据的 SQL upsert into t(id,name,sex) values('...','...','...')
private String genUpsertSql(String tableName, Set<String> keys, Collection<Object> values) {
return "upsert into " + GmallConfig.HBASE_SCHEMA + "." +
tableName + "(" + StringUtils.join(keys, ",") + ")" +
" values('" + StringUtils.join(values, "','") + "')";
}
}
5) 主程序 BaseDBApp 中调用 DimSink
hbaseJsonDS.addSink(new DimSink());
6) 测试
- 启动 HDFS、ZK、Kafka、FlinkCDCApp、HBase
- 向 gmall_realtime 数据库的 table_process 表中插入测试数据

运行 idea 中的 BaseDBApp
- 向 gmall数据库的 base_trademark 表中插入一条数据
- 通过 phoenix 查看 hbase 的 schema 以及表情况
分流 Sink 之保存业务数据到 Kafka 主题
1) 在 MyKafkaUtil 中添加如下方法
public static <T> FlinkKafkaProducer<T> getKafkaSinkBySchema(KafkaSerializationSchema<T>
kafkaSerializationSchema) {
properties.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 5 * 60 * 1000 +
"");
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC,
kafkaSerializationSchema,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
2) 在 MyKafkaUtil 中添加属性定义
private static String DEFAULT_TOPIC = "dwd_default_topic";
3) 两个创建 FlinkKafkaProducer 方法对比
-
前者给定确定的 Topic
-
而后者除了缺省情况下会采用 DEFAULT_TOPIC,一般情况下可以根据不同的业务数据在 KafkaSerializationSchema 中通过方法实现。
4) 在主程序 BaseDBApp 中加入新 KafkaSink
FlinkKafkaProducer<JSONObject> kafkaSinkBySchema = MyKafkaUtil.getKafkaSinkBySchema(new
KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("开始序列化 Kafka 数据!");
}
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject element, @Nullable Long
timestamp) {
return new ProducerRecord<byte[], byte[]>(element.getString("sink_table"),
element.getString("data").getBytes());
}
});
kafkaJsonDS.addSink(kafkaSinkBySchema);
- 测试
- 启动 hdfs、zk、kafka、flinkcdc、hbase
- 向 gmall_realtime 数据库的 table_process 表中插入测试数据
在这里插入图片描述
运行 idea 中的 BaseDBApp
- 运行rt_dblog 下的 jar 包,模拟生成数据
ing> keys = data.keySet();
Collection<Object> values = data.values();
//获取表名
String tableName = jsonObject.getString("sink_table");
//创建插入数据的 SQL
String upsertSql = genUpsertSql(tableName, keys, values);
System.out.println(upsertSql);
//编译 SQL
preparedStatement = connection.prepareStatement(upsertSql);
//执行
preparedStatement.executeUpdate();
//提交
connection.commit();
} catch (SQLException e) {
e.printStackTrace();
System.out.println("插入 Phoenix 数据失败!");
} finally {
if (preparedStatement != null) {
preparedStatement.close();
}
}
}
//创建插入数据的 SQL upsert into t(id,name,sex) values('...','...','...')
private String genUpsertSql(String tableName, Set<String> keys, Collection<Object> values) {
return "upsert into " + GmallConfig.HBASE_SCHEMA + "." +
tableName + "(" + StringUtils.join(keys, ",") + ")" +
" values('" + StringUtils.join(values, "','") + "')";
}
}
5) 主程序 BaseDBApp 中调用 DimSink
hbaseJsonDS.addSink(new DimSink());
6) 测试
- 启动 HDFS、ZK、Kafka、FlinkCDCApp、HBase
- 向 gmall_realtime 数据库的 table_process 表中插入测试数据

运行 idea 中的 BaseDBApp
- 向 gmall数据库的 base_trademark 表中插入一条数据
- 通过 phoenix 查看 hbase 的 schema 以及表情况
分流 Sink 之保存业务数据到 Kafka 主题
1) 在 MyKafkaUtil 中添加如下方法
public static <T> FlinkKafkaProducer<T> getKafkaSinkBySchema(KafkaSerializationSchema<T>
kafkaSerializationSchema) {
properties.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 5 * 60 * 1000 +
"");
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC,
kafkaSerializationSchema,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
2) 在 MyKafkaUtil 中添加属性定义
private static String DEFAULT_TOPIC = "dwd_default_topic";
3) 两个创建 FlinkKafkaProducer 方法对比
-
前者给定确定的 Topic
-
而后者除了缺省情况下会采用 DEFAULT_TOPIC,一般情况下可以根据不同的业务数据在 KafkaSerializationSchema 中通过方法实现。
4) 在主程序 BaseDBApp 中加入新 KafkaSink
FlinkKafkaProducer<JSONObject> kafkaSinkBySchema = MyKafkaUtil.getKafkaSinkBySchema(new
KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("开始序列化 Kafka 数据!");
}
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject element, @Nullable Long
timestamp) {
return new ProducerRecord<byte[], byte[]>(element.getString("sink_table"),
element.getString("data").getBytes());
}
});
kafkaJsonDS.addSink(kafkaSinkBySchema);
- 测试
- 启动 hdfs、zk、kafka、flinkcdc、hbase
- 向 gmall_realtime 数据库的 table_process 表中插入测试数据

运行 idea 中的 BaseDBApp
-
运行rt_dblog 下的 jar 包,模拟生成数据
-
查看控制台输出以及在配置表中配置的 kafka 主题名消费情况
DWS 层与 DWM 层的设计
思路
我们在之前通过分流等手段,把数据分拆成了独立的 Kafka Topic。那么接下来如何处理数据,就要思考一下我们到底要通过实时计算出哪些指标项。
因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况考虑是否有必要象离线数仓一样,建一个大而全的中间层。如果没有必要大而全,这时候就需要大体规划一下要实时计算出的指标需求了。把这些指标以主题宽表的形式输出就是我们的 DWS 层。
需求梳理
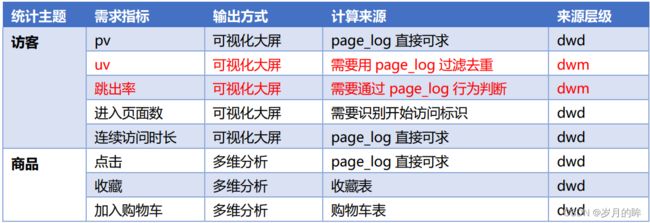
- dwm层是dwd层和dws层的公共部分,那么这个公共部分怎么找?

- 访客维度
- 商品维度主题
- 地区维度
- 关键字维度
实时数仓为什么没有DWT层,因为离线数仓的DWT层是对历史数据的聚集,是历史数据的累积汇总。而实时数仓针对的是实时的数据分析需求,无需历史数据沉淀。

dwm层是dwd层和dws层的公共部分,那么这个公共部分怎么找?
-
我们根据dws层的统计主题,把所有主题的需求指标都列出来,如果直接可以从dwd层获取的就无需加工;如果需要对数据进行加工,比如过滤去重、形成宽表等,那么这些指标应该放到dwm中间层。
DWM 层的定位是什么,DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间会有一定的计算量,而且这部分计算的结果很有可能被多个 DWS 层主题复用,所以部分 DWD 层会形成一层DWM,我们这里主要涉及业务。
dwm层的指标:
- 访客UV统计
- 跳出率统计
- 订单宽表
- 支付宽表
DWM 层-访客 UV 计算
DWM 层-跳出明细计算
需求分析与思路
什么是跳出
跳出就是用户成功访问了网站的一个页面后就退出,不在继续访问网站的其它页面。而跳出率就是用跳出次数除以访问次数。
关注跳出率,可以看出引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间的质量对比,对于应用优化前后跳出率的对比也能看出优化改进的成果。
计算跳出行为的思路
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么要抓住几个特征:
-
该页面是用户近期访问的第一个页面
- 这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
-
**首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。**这第一个特征的识别很简单,保留 last_page_id 为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。
- 而且要通过一个不存在的数据求得一条存在的数据。更麻烦的他并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
-
最简单的办法就是Flink 自带的 CEP 技术。这个CEP 非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
DWS 层业务实现
DWS 层与 DWM 层的设计
设计思路
需求梳理
DWS层的定位
DWS层-访客主题宽表的计算

设计一张 DWS 层的表其实就两件事:维度和度量(事实数据)
- 度量包括 PV、UV、跳出次数、进入页面数(session_count)、连续访问时长
- 维度包括在分析中比较重要的几个字段:渠道、地区、版本、新老用户进行聚合。