Pandas read_csv读取文本文件速度测试
Pandas read_csv读取文本文件速度测试
目录
Pandas read_csv读取文本文件速度测试
问题发现
一、测试条件
1.测试环境
2.测试对象
二、测试程序
三、测试结果
1.Pandas1.0.3 read_csv读取文件
2.Pandas0.23.4 read_csv读取文件
3.Pandas0.24.1 read_csv读取文件
4.Pandas0.25.3 read_csv读取文件
总结和分析
1.测试总结
2.分析
问题发现
在将Pandas升级到1.0.x版本后发现read_csv函数相比之前的版本,在读取文本文件时速度大幅变慢。
本文根据这个问题做一个测试记录问题情况,寻找有效的解决方法。
一、测试条件
分别在Pandas 1.0.3、0.23.4、0.24.1、0.25.3版本下测试,pd.read_csv函数读取144MB的txt文件的速度。
1.测试环境
基本运行平台:Windows 7 64位,Python 3.7.7。
详细测试配置:
- Pandas 1.0.3
INSTALLED VERSIONS
------------------
commit : None
python : 3.7.7.final.0
python-bits : 64
OS : Windows
OS-release : 7
machine : AMD64
processor : Intel64 Family 6 Model 78 Stepping 3, GenuineIntel
byteorder : little
LC_ALL : None
LANG : None
LOCALE : Chinese (Simplified)_People's Republic of China.936
pandas : 1.0.3
numpy : 1.18.4
pytz : 2020.1
dateutil : 2.8.1
pip : 19.2.3
setuptools : 41.2.0
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fastparquet : None
gcsfs : None
lxml.etree : None
matplotlib : 3.1.1
numexpr : 2.7.1
odfpy : None
openpyxl : 3.0.5
pandas_gbq : None
pyarrow : None
pytables : None
pytest : None
pyxlsb : None
s3fs : None
scipy : 1.4.1
sqlalchemy : None
tables : 3.6.1
tabulate : None
xarray : None
xlrd : 1.2.0
xlwt : None
xlsxwriter : None
numba : None- Pandas 0.23.4
INSTALLED VERSIONS
------------------
commit: None
python: 3.7.7.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 78 Stepping 3, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
LOCALE: Chinese (Simplified)_People's Republic of China.936
pandas: 0.23.4
pytest: None
pip: 19.2.3
setuptools: 41.2.0
Cython: None
numpy: 1.18.4
scipy: 1.4.1
pyarrow: None
xarray: None
IPython: None
sphinx: None
patsy: None
dateutil: 2.8.1
pytz: 2020.1
blosc: None
bottleneck: None
tables: 3.6.1
numexpr: 2.7.1
feather: None
matplotlib: 3.1.1
openpyxl: 3.0.5
xlrd: 1.2.0
xlwt: None
xlsxwriter: None
lxml: None
bs4: None
html5lib: None
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: None
s3fs: None
fastparquet: None
pandas_gbq: None
pandas_datareader: None- Pandas0.24.1
INSTALLED VERSIONS
------------------
commit: None
python: 3.7.7.final.0
python-bits: 64
OS: Windows
OS-release: 7
machine: AMD64
processor: Intel64 Family 6 Model 78 Stepping 3, GenuineIntel
byteorder: little
LC_ALL: None
LANG: None
LOCALE: Chinese (Simplified)_People's Republic of China.936
pandas: 0.24.1
pytest: None
pip: 19.2.3
setuptools: 41.2.0
Cython: None
numpy: 1.18.4
scipy: 1.4.1
pyarrow: None
xarray: None
IPython: None
sphinx: None
patsy: None
dateutil: 2.8.1
pytz: 2020.1
blosc: None
bottleneck: None
tables: 3.6.1
numexpr: 2.7.1
feather: None
matplotlib: 3.1.1
openpyxl: 3.0.5
xlrd: 1.2.0
xlwt: None
xlsxwriter: None
lxml.etree: None
bs4: None
html5lib: None
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: None
s3fs: None
fastparquet: None
pandas_gbq: None
pandas_datareader: None
gcsfs: None- Pandas0.25.3
INSTALLED VERSIONS
------------------
commit : None
python : 3.7.7.final.0
python-bits : 64
OS : Windows
OS-release : 7
machine : AMD64
processor : Intel64 Family 6 Model 78 Stepping 3, GenuineIntel
byteorder : little
LC_ALL : None
LANG : None
LOCALE : Chinese (Simplified)_People's Republic of China.936
pandas : 0.25.3
numpy : 1.18.4
pytz : 2020.1
dateutil : 2.8.1
pip : 19.2.3
setuptools : 41.2.0
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : None
html5lib : None
pymysql : None
psycopg2 : None
jinja2 : None
IPython : None
pandas_datareader: None
bs4 : None
bottleneck : None
fastparquet : None
gcsfs : None
lxml.etree : None
matplotlib : 3.1.1
numexpr : 2.7.1
odfpy : None
openpyxl : 3.0.5
pandas_gbq : None
pyarrow : None
pytables : None
s3fs : None
scipy : 1.4.1
sqlalchemy : None
tables : 3.6.1
xarray : None
xlrd : 1.2.0
xlwt : None
xlsxwriter : None
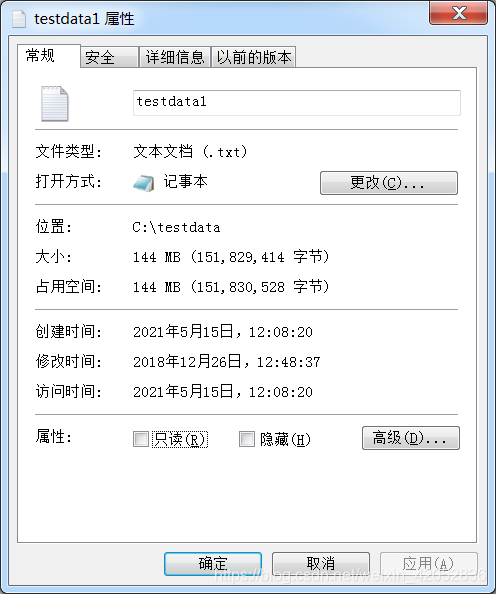
2.测试对象
pd.read_csv函数读取的文件大小为144MB,文件内容为表格式数据的时间历程数据,数据按列以\t分隔。
二、测试程序
测试代码如下:
import profile
import pandas as pd
path = r'C:\testdata\testdata1.txt'
def test():
df = pd.read_csv(path, sep='\s+', engine='c')
profile.run('test()')三、测试结果
1.Pandas1.0.3 read_csv读取文件
如下所示,Pandas1.0.3读取文件共耗时112.922秒,其中C engine的read函数部分112.492秒,占了耗时的绝大部分。
30826 function calls (30667 primitive calls) in 112.992 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
8 0.000 0.000 0.000 0.000 :0(__new__)
19 0.000 0.000 0.016 0.001 :0(_abc_instancecheck)
65/10 0.016 0.000 0.016 0.002 :0(_abc_subclasscheck)
9/8 0.000 0.000 0.000 0.000 :0(all)
6 0.000 0.000 0.000 0.000 :0(any)
59 0.000 0.000 0.000 0.000 :0(append)
3 0.000 0.000 0.000 0.000 :0(arange)
49 0.000 0.000 0.000 0.000 :0(array)
2 0.000 0.000 0.000 0.000 :0(array_equivalent_object)
1 0.000 0.000 0.000 0.000 :0(callable)
2 0.000 0.000 0.000 0.000 :0(clean_index_list)
1 0.000 0.000 0.000 0.000 :0(close)
2 0.000 0.000 0.000 0.000 :0(copy)
8 0.000 0.000 0.000 0.000 :0(empty)
4 0.000 0.000 0.000 0.000 :0(endswith)
6 0.000 0.000 0.000 0.000 :0(ensure_object)
1 0.000 0.000 112.992 112.992 :0(exec)
2 0.000 0.000 0.000 0.000 :0(extend)
2 0.000 0.000 0.000 0.000 :0(fill)
1 0.000 0.000 0.000 0.000 :0(find)
29 0.000 0.000 0.000 0.000 :0(format)
3 0.000 0.000 0.000 0.000 :0(fspath)
66 0.000 0.000 0.000 0.000 :0(get)
5685 0.078 0.000 0.078 0.000 :0(getattr)
4 0.000 0.000 0.000 0.000 :0(geterrobj)
1 0.000 0.000 0.000 0.000 :0(getfilesystemencoding)
169 0.000 0.000 0.000 0.000 :0(hasattr)
17 0.000 0.000 0.000 0.000 :0(hash)
29 0.250 0.009 0.250 0.009 :0(implement_array_function)
1 0.000 0.000 0.000 0.000 :0(infer_datetimelike_array)
4 0.016 0.004 0.016 0.004 :0(infer_dtype)
1 0.000 0.000 0.000 0.000 :0(is_bool)
1 0.000 0.000 0.000 0.000 :0(is_datetime_array)
29 0.000 0.000 0.000 0.000 :0(is_float)
2 0.000 0.000 0.000 0.000 :0(is_integer)
13 0.000 0.000 0.000 0.000 :0(is_list_like)
35 0.000 0.000 0.016 0.000 :0(is_scalar)
6356 0.078 0.000 0.218 0.000 :0(isinstance)
1 0.000 0.000 0.000 0.000 :0(isnaobj)
3102 0.016 0.000 0.016 0.000 :0(issubclass)
6 0.000 0.000 0.000 0.000 :0(items)
1 0.000 0.000 0.000 0.000 :0(iter)
167/124 0.000 0.000 0.000 0.000 :0(len)
1 0.000 0.000 0.000 0.000 :0(lower)
1 0.000 0.000 0.000 0.000 :0(next)
1 0.000 0.000 0.000 0.000 :0(ord)
19 0.000 0.000 0.000 0.000 :0(pop)
5 0.000 0.000 0.000 0.000 :0(ravel)
1 111.837 111.837 112.492 112.492 :0(read)2.Pandas0.23.4 read_csv读取文件
如下所示,Pandas0.23.4读取文件共耗时132.195秒,其中C engine的read函数部分131.680秒,占了耗时的绝大部分。
10284 function calls (10161 primitive calls) in 132.195 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
8/4 0.000 0.000 0.016 0.004 :0(__import__)
7 0.000 0.000 0.000 0.000 :0(__new__)
6 0.000 0.000 0.000 0.000 :0(_abc_instancecheck)
45/3 0.000 0.000 0.000 0.000 :0(_abc_subclasscheck)
40 0.000 0.000 0.000 0.000 :0(acquire_lock)
6/5 0.000 0.000 0.000 0.000 :0(all)
24 0.000 0.000 0.000 0.000 :0(allocate_lock)
3 0.000 0.000 0.000 0.000 :0(any)
59 0.000 0.000 0.000 0.000 :0(append)
3 0.000 0.000 0.000 0.000 :0(arange)
43 0.000 0.000 0.000 0.000 :0(array)
2 0.000 0.000 0.000 0.000 :0(array_equivalent_object)
1 0.000 0.000 0.000 0.000 :0(callable)
2 0.000 0.000 0.000 0.000 :0(clean_index_list)
1 0.000 0.000 0.000 0.000 :0(close)
3 0.000 0.000 0.000 0.000 :0(copy)
8 0.016 0.002 0.016 0.002 :0(empty)
4 0.000 0.000 0.000 0.000 :0(endswith)
6 0.000 0.000 0.000 0.000 :0(ensure_object)
1 0.000 0.000 132.180 132.180 :0(exec)
2 0.000 0.000 0.000 0.000 :0(extend)
2 0.000 0.000 0.000 0.000 :0(fill)
1 0.000 0.000 0.000 0.000 :0(find)
39/38 0.000 0.000 0.000 0.000 :0(format)
1 0.000 0.000 0.000 0.000 :0(fspath)
91 0.000 0.000 0.000 0.000 :0(get)
24 0.000 0.000 0.000 0.000 :0(get_ident)
313 0.000 0.000 0.000 0.000 :0(getattr)
4 0.000 0.000 0.000 0.000 :0(geterrobj)
1 0.000 0.000 0.000 0.000 :0(getfilesystemencoding)
84 0.000 0.000 0.000 0.000 :0(hasattr)
30 0.328 0.011 0.328 0.011 :0(implement_array_function)
1 0.000 0.000 0.000 0.000 :0(infer_datetimelike_array)
3 0.000 0.000 0.000 0.000 :0(infer_dtype)
1 0.000 0.000 0.000 0.000 :0(is_bool)
2 0.000 0.000 0.000 0.000 :0(is_builtin)
1 0.000 0.000 0.000 0.000 :0(is_datetime_array)
4 0.000 0.000 0.000 0.000 :0(is_frozen)
3 0.000 0.000 0.000 0.000 :0(is_integer)
35 0.000 0.000 0.000 0.000 :0(is_scalar)
2055 0.016 0.000 0.016 0.000 :0(isinstance)
1 0.000 0.000 0.000 0.000 :0(isnaobj)
1976 0.016 0.000 0.016 0.000 :0(issubclass)
10 0.000 0.000 0.000 0.000 :0(items)
9 0.000 0.000 0.000 0.000 :0(iter)
90 0.000 0.000 0.000 0.000 :0(join)
134/123 0.000 0.000 0.000 0.000 :0(len)
1 0.000 0.000 0.000 0.000 :0(lower)
32 0.000 0.000 0.000 0.000 :0(max)
1 0.000 0.000 0.000 0.000 :0(next)
1 0.000 0.000 0.000 0.000 :0(ord)
18 0.000 0.000 0.000 0.000 :0(pop)
5 0.000 0.000 0.000 0.000 :0(ravel)
1 131.212 131.212 131.680 131.680 :0(read)3.Pandas0.24.1 read_csv读取文件
如下所示,Pandas0.24.1读取文件共耗时18.096秒,其中C engine的read函数部分17.503秒,读取速度相比其它版本要快很多。
30648 function calls (30495 primitive calls) in 18.096 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
8/4 0.000 0.000 0.016 0.004 :0(__import__)
8 0.000 0.000 0.000 0.000 :0(__new__)
17 0.000 0.000 0.000 0.000 :0(_abc_instancecheck)
67/10 0.000 0.000 0.000 0.000 :0(_abc_subclasscheck)
40 0.000 0.000 0.000 0.000 :0(acquire_lock)
6/5 0.000 0.000 0.000 0.000 :0(all)
24 0.000 0.000 0.000 0.000 :0(allocate_lock)
3 0.000 0.000 0.000 0.000 :0(any)
59 0.000 0.000 0.000 0.000 :0(append)
3 0.000 0.000 0.000 0.000 :0(arange)
43 0.000 0.000 0.000 0.000 :0(array)
2 0.000 0.000 0.000 0.000 :0(array_equivalent_object)
1 0.000 0.000 0.000 0.000 :0(callable)
2 0.000 0.000 0.000 0.000 :0(clean_index_list)
1 0.000 0.000 0.000 0.000 :0(close)
3 0.000 0.000 0.000 0.000 :0(copy)
8 0.016 0.002 0.016 0.002 :0(empty)
4 0.016 0.004 0.016 0.004 :0(endswith)
6 0.000 0.000 0.000 0.000 :0(ensure_object)
1 0.000 0.000 18.096 18.096 :0(exec)
2 0.000 0.000 0.000 0.000 :0(extend)
2 0.000 0.000 0.000 0.000 :0(fill)
1 0.000 0.000 0.000 0.000 :0(find)
39/38 0.000 0.000 0.000 0.000 :0(format)
3 0.000 0.000 0.000 0.000 :0(fspath)
93 0.000 0.000 0.000 0.000 :0(get)
24 0.000 0.000 0.000 0.000 :0(get_ident)
5506 0.031 0.000 0.031 0.000 :0(getattr)
4 0.000 0.000 0.000 0.000 :0(geterrobj)
1 0.000 0.000 0.000 0.000 :0(getfilesystemencoding)
123 0.000 0.000 0.000 0.000 :0(hasattr)
1 0.000 0.000 0.000 0.000 :0(hash)
30 0.265 0.009 0.265 0.009 :0(implement_array_function)
1 0.000 0.000 0.000 0.000 :0(infer_datetimelike_array)
4 0.016 0.004 0.016 0.004 :0(infer_dtype)
1 0.000 0.000 0.000 0.000 :0(is_bool)
2 0.000 0.000 0.000 0.000 :0(is_builtin)
1 0.000 0.000 0.000 0.000 :0(is_datetime_array)
29 0.000 0.000 0.000 0.000 :0(is_float)
4 0.000 0.000 0.000 0.000 :0(is_frozen)
3 0.000 0.000 0.000 0.000 :0(is_integer)
35 0.000 0.000 0.000 0.000 :0(is_scalar)
6001 0.062 0.000 0.187 0.000 :0(isinstance)
1 0.000 0.000 0.000 0.000 :0(isnaobj)
2989 0.031 0.000 0.031 0.000 :0(issubclass)
10 0.000 0.000 0.000 0.000 :0(items)
8 0.000 0.000 0.000 0.000 :0(iter)
90 0.000 0.000 0.000 0.000 :0(join)
135/124 0.000 0.000 0.000 0.000 :0(len)
1 0.000 0.000 0.000 0.000 :0(lower)
32 0.000 0.000 0.000 0.000 :0(max)
1 0.000 0.000 0.000 0.000 :0(next)
1 0.000 0.000 0.000 0.000 :0(ord)
18 0.000 0.000 0.000 0.000 :0(pop)
5 0.000 0.000 0.000 0.000 :0(ravel)
1 16.692 16.692 17.503 17.503 :0(read)4.Pandas0.25.3 read_csv读取文件
如下所示,Pandas0.25.3读取文件共耗时9.656秒,其中C engine的read函数部分9.157秒,读取速度又是0.24.1版本的两倍。
29951 function calls (29800 primitive calls) in 9.656 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
8 0.000 0.000 0.000 0.000 :0(__new__)
15 0.000 0.000 0.000 0.000 :0(_abc_instancecheck)
60/8 0.000 0.000 0.000 0.000 :0(_abc_subclasscheck)
6/5 0.000 0.000 0.016 0.003 :0(all)
3 0.000 0.000 0.000 0.000 :0(any)
59 0.000 0.000 0.000 0.000 :0(append)
3 0.000 0.000 0.000 0.000 :0(arange)
43 0.000 0.000 0.000 0.000 :0(array)
2 0.000 0.000 0.000 0.000 :0(array_equivalent_object)
1 0.000 0.000 0.000 0.000 :0(callable)
2 0.000 0.000 0.000 0.000 :0(clean_index_list)
1 0.016 0.016 0.016 0.016 :0(close)
2 0.000 0.000 0.000 0.000 :0(copy)
8 0.016 0.002 0.016 0.002 :0(empty)
4 0.000 0.000 0.000 0.000 :0(endswith)
6 0.000 0.000 0.000 0.000 :0(ensure_object)
1 0.000 0.000 9.641 9.641 :0(exec)
2 0.000 0.000 0.000 0.000 :0(extend)
2 0.000 0.000 0.000 0.000 :0(fill)
1 0.000 0.000 0.000 0.000 :0(find)
35/34 0.000 0.000 0.000 0.000 :0(format)
3 0.000 0.000 0.000 0.000 :0(fspath)
67 0.000 0.000 0.000 0.000 :0(get)
5561 0.047 0.000 0.047 0.000 :0(getattr)
4 0.000 0.000 0.000 0.000 :0(geterrobj)
1 0.000 0.000 0.000 0.000 :0(getfilesystemencoding)
103 0.000 0.000 0.000 0.000 :0(hasattr)
1 0.000 0.000 0.000 0.000 :0(hash)
29 0.218 0.008 0.218 0.008 :0(implement_array_function)
1 0.000 0.000 0.000 0.000 :0(infer_datetimelike_array)
4 0.016 0.004 0.016 0.004 :0(infer_dtype)
1 0.000 0.000 0.000 0.000 :0(is_bool)
1 0.000 0.000 0.000 0.000 :0(is_datetime_array)
29 0.000 0.000 0.000 0.000 :0(is_float)
2 0.000 0.000 0.000 0.000 :0(is_integer)
9 0.000 0.000 0.000 0.000 :0(is_list_like)
34 0.000 0.000 0.000 0.000 :0(is_scalar)
6155 0.140 0.000 0.172 0.000 :0(isinstance)
1 0.000 0.000 0.000 0.000 :0(isnaobj)
3054 0.016 0.000 0.016 0.000 :0(issubclass)
10 0.000 0.000 0.000 0.000 :0(items)
1 0.000 0.000 0.000 0.000 :0(iter)
166/123 0.000 0.000 0.000 0.000 :0(len)
1 0.000 0.000 0.000 0.000 :0(lower)
1 0.000 0.000 0.000 0.000 :0(next)
1 0.000 0.000 0.000 0.000 :0(ord)
19 0.000 0.000 0.000 0.000 :0(pop)
5 0.000 0.000 0.000 0.000 :0(ravel)
1 8.440 8.440 9.157 9.157 :0(read)总结和分析
1.测试总结
根据以上测试结果,在Win7系统Python3.7.7环境下,Pandas不同版本读取144MB的表式文本文件时间为:
| Pandas版本 | read_csv耗时 |
|---|---|
| 0.23.4 | 132.195s |
| 0.24.1 | 18.096s |
| 0.25.3 | 9.656s |
| 1.0.3 | 112.922s |
2.分析
参考Pandas的github issue #23516:https://github.com/pandas-dev/pandas/issues/23516,Python3.7.x和Pandas0.23.4环境下read_csv由于isdigit函数调用问题造成了3.5倍的速度延迟,这个问题在0.24.0版本已经解决,因此可以看到本测试中0.24.1相比0.23.4读取速度显著提高。
Pandas0.25.x版本比0.24.x版本相比速度更快,具体原因不清楚。
Pandas1.0.x版本速度再次大幅变慢,具体原因不清楚。
后续可以继续测试Python其它版本下Pandas read_csv函数的性能情况。