【李沐AI论文精读】ICLR2021 ViT transformer
读论文系列最前言
写在前面的一些(废)话
上岸以后一直在摸鱼,浑浑噩噩拖拖拉拉的学完了动手学深度学习
PyTorch版,太感谢沐神了!彻底入坑他的各种系列课程了!因为最近两个月老师要求组里面每周都要开组会汇报论文。于是开始了欢欢喜喜读论文的道路orz(bushi
自己读论文有很多细节会理解不到位,前几天又刚好看完了沐神的transformer和注意力机制的讲解,以及李宏毅老师的课,感觉不如趁热打铁,赶紧把transformer方面的几篇与CV相关的重要论文学习一下
决定将跟着沐神的AI论文精读课,继续深入了解。
下面将把跟着沐神 / bryanyzhu读论文的笔记整理贴出来。写这个博客的目的更多的是帮助自己去繁化简,把笔记里重要的内容条理清晰的表达出来~当然也希望能帮助到正在学习的小伙伴们,希望你们能通过我的整理(笔记)获得你们想要的知识。
持续更新————挖坑~~~:
NIPS2017 transformer论文 (CNN和RNN的终结者?)
ICLR2021 ViT 论文(transformer出圈到CV)
ICCV2021 bestpaper Swin transformer(披着transformer羊皮的CNN?)
CVPR2021 MAE (CV版的Bert)
CVPR2020 bestpaper提名 MoCo自监督 (无监督学习在CV界也香了)
CVPR2021 CLIP论文 (打通文本图像、迁移学习的新高度)
论文题目:
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文地址:https://arxiv.org/pdf/2010.11929.pdf
code:https://github.com/google-research/vision_transformer
下面将按照沐神的推荐的阅读顺序进行梳理
一、标题
An Image is worth 16*16 words: transformers for image recognition at scale.一张图片等同于16×16大小的单词,(切割成块儿)transformer去做大规模的图像识别。
二、摘要
简要概述:注意力机制要么被用在连接CNN的,要么被用在取代卷积网络的某个特定组块,然而整体还是保持着CNN的架构。然而CNN并不是必须的,纯transformer架构直接用在一堆图像块序列也能够在图像分类任务上取得非常好的效果。当对大量数据进行预训练并传输到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB等)时,与SOTA的卷积网络相比,ViT也可以获得出色的结果,同时需要更少的计算资源进行训练(但还是相当烧钱/doge 钞能力)。
三、引言
para1:
性能还没有饱和,规模越大性能表现越好
para2:
回顾一下注意力机制里讲过计算复杂度。注意力机制的运算过程如下图,输入之间两两做运算,得到attention图之后,乘value作加权和得到输出,复杂度与输入序列长度的平方有关。如果把输入图片按照像素比如224×224分割输入进去,计算复杂度太高。
但是CV还是想尝试使用注意力机制嘛,所以提到了前人的工作有哪些:
①用类CNN架构,把网络中间的特征图当作transformer的输入。
②完全用注意力取代CNN的
- 孤立注意力:因为复杂度来源于整张图做输入,所以想到只用局部的某个小窗口做输入,完全的transformer架构。
- 轴注意力:图片复杂度是H×W,是2d矩阵,把图片2d矩阵,拆分成两个1d向量。先在高度dimension做一次self-attention,再在宽度上做一次,相当于在两个1d向量上分别做操作,这样计算复杂度大幅降低。
但是由于使用了上面这种特殊的方法所以没法在现代硬件加速器上有效的大规模实现。
同时也可以看到,之前的工作中,自注意力早已应用在CV了,甚至早已有用自注意力完全取代CNN的方法了。
于是作者换了个角度讲故事(doge),直接使用标准的transformer结构用在image,尽可能最少的modification,看能否取得好的效果。
那么问题又回来了,这么长的序列该怎么办?
para3:
对输入图像做了一个预处理。
为此划分一个image为a set of patch(比如一个图224×224,被缩小16倍。就W和H都变成了224/16=14.每一个patch看成一个元素,则变成了N=14×14大小了。),给这些patches提供the sequence of linear embeddings(FC 把每一个patch作为一个元素)作为transformer的输入。每一个patch被当作NLP应用里面的token来对待。用有监督的方式来训练模型实现图片分类。(为什么要强调是因为,在NLP里面。大多数无监督的要么是language modeling,要么是mask language modeling等等)但是视觉大部分还是有监督的。
para4:
transformer跟CNN相比,没有inductive biases归纳偏置,解释如下
一个是locality:CNN里是类似于滑动窗口的一点点的进行卷积的,所以假设图片上相邻区域会有相邻的特征,比如桌子和椅子。
另一个是平移等变性equivariance:f(g(x))=g(f(x)) 无论先平移还是先卷积,结果一样。卷积核相当于模板,无论图片同样的物体移动到哪里, 输出都一样。CNN有了这两个性质之后,他就有了很多先验信息。(我理解的卷积核就是他的先验信息。transformer需要自己去学这些东西)
然而作者发现,只要transformer在足够大的数据集上进行预训练和转移到数据点较少的任务中时,也会取得良好的效果。即大规模的训练能胜过归纳偏置。
这样通过实验,验证了受NLP启发的标准的transformer架构在CV的图像分类任务上也能取得不错的效果,为CV和NLP大一统迈出了一大步。也挖了很多坑~~
四、结论
contributions:
1、没有引入CV中专门的操作到网络结构中,除了数据预处理时,把图片变成patch。是纯正的transformer架构。好处,不需要domain knowledge,直接把他理解成序列的图像块。
2、在大规模数据集上预训练之后性能更好,超过了SOTA。
挑战(展望):
1、ViT适应到其他任务像是检测和分割,仍然很有promise.
(挖坑 比如DETR 改变了之前出框的方式,事实证明确实如此,这个工作出来一个半月后,就出来了ViT-frcnn,已经把ViT用到detection了;SETR2020.12月 大家手速太快了吧。。。。他在2020年11月之前就已经完成论文写作了。。。。CV卷的程度要用天来计算了。。。紧接着3个月后,swin 横空出世, 把多尺度融合进去了,更加适合做视觉的设计了 ,真的证明transformer或许能够作为cv里一个通用的骨干网络。 )
2、持续的探索自监督的预训练方法。最初的实验也展示了自监督的预训练方法带来性能提升,但是跟大规模有监督预训练比起来, 性能方面仍有Gap差距(论文的4.6也会讨论 怎么做自监督预训练的)
3、因为性能没有饱和,所以进一步扩大训练规模可能仍然能提升性能。(呵呵.。。os : 反正都没我有钱,我就又继续实验,做了这个验证)
4、还挖了一个隐藏的大坑,是不是在CV和NLP大一统后,多模态就可以用一个transformer去解决了呢?还可以用它去做视频等等。(最近两年多模态的工作也是井喷式增长)
五、相关工作
para1:
NLP现状
para2、3:
直接在像素层面使用transformer不太现实。
过去的工作中对输入数据的操作的一些尝试:
1、仅在for each query pixel的局部邻域中应用自注意力,而不是全局应用自注意力。
2、局部多头dot-product自注意力机制block可以完全取代CNN。
3、sparse transformer稀疏输入
4、用到不同大小的block上或者在极端情况下只沿着轴(轴注意力)
这些特制的注意力结构其实在计算机视觉上结果都不错,但需要很复杂的工程去加速算子,在gpu上跑得快些。
就有疑问,直接用standard transformer架构作用到CV上,这么简单的想法,之前没有人做吗?——肯定有啊,
跟这个论文工作最像的一个model是2020年的Cordonnier,从输入图片中提取到2×2大小的patch,应用全自注意力机制。(还得是钞能力)
Vit的证明不过是,我们的模型通过在更多更大的规模的数据集上预训练后能更好的适应更多CV任务,而且之前那个工作的patch太小了,只能适应小的图片的任务。
para4:
还有一些工作是将CNN和自注意力机制结合的,跟前面引言里para2提到的相关,通过增强图像分类的特征图,或通过使用自注意力进一步处理CNN的输出等。
image GPT(NLP上的 生成式网络)作为一个特征提取器,在ImageNet上最好的效果才72.
(这里的生成式、还提到了MAE网络的优点,没听懂,还未接触)
总之,相关工作的目的就是要告诉读者,在你的工作之前,别人的工作做了哪些,你跟他们的区别是什么。这个写清楚了对你的论文是有好处的,并不会因此影响novelty。
六、ViT模型
最重要的环节~!
作者说模型设计上,尽可能按照最原始的transformer架构设计。
模型总览图很重要,清楚的能让读者在不读论文的情况,大概通过论文就知道你在做什么。
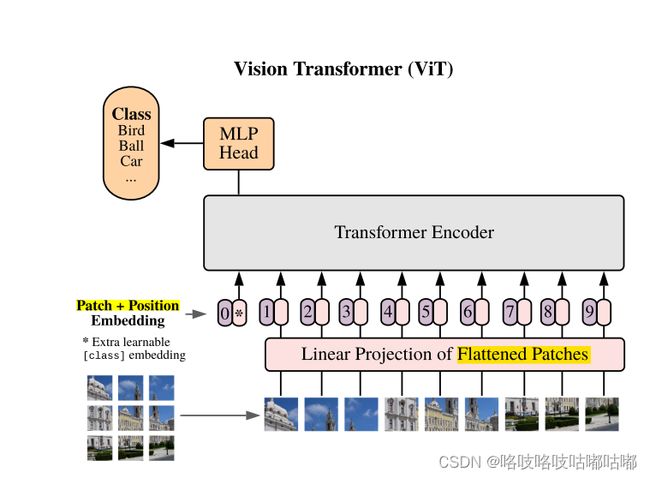 先大体过一遍整体的流程,然后再具体的过一遍整个网络的前向操作。这样对ViT的理解更深刻些。
先大体过一遍整体的流程,然后再具体的过一遍整个网络的前向操作。这样对ViT的理解更深刻些。
整体流程
把这些patch变成一个序列,每个patch通过一个线性投射层Linear Projection的得到一个特征,也就是这篇论文里的patch embedding。这个自注意力是所有元素两两之间做交互,本身不存在顺序问题,但是对于图片来说,是一个整体的,有顺序的,如果顺序颠倒了就不是原图了。所以加一个position embedding。一旦加入了position编码后,整体的信息既包含了图像块原本有的图像信息,又有图像块的所在位置信息。
一旦得到了一个个的token,就跟NLP处理一模一样了。
经过Transformer Encoder之后得到很多输出,究竟该拿哪个输出做最后的分类?这里借鉴了NLP Bert里的extra learnable embedding也就是一个特殊字符cls分类字符。
因为所有的token都在跟所有的token做交互信息,他们相信这个cls能从别的embedding里学到有用的信息,从而只需要根据他的输出做最后的判断。
MLP head 就是一个通用的分类头了。
最后用交叉熵函数去进行模型的训练。
具体的前向传递
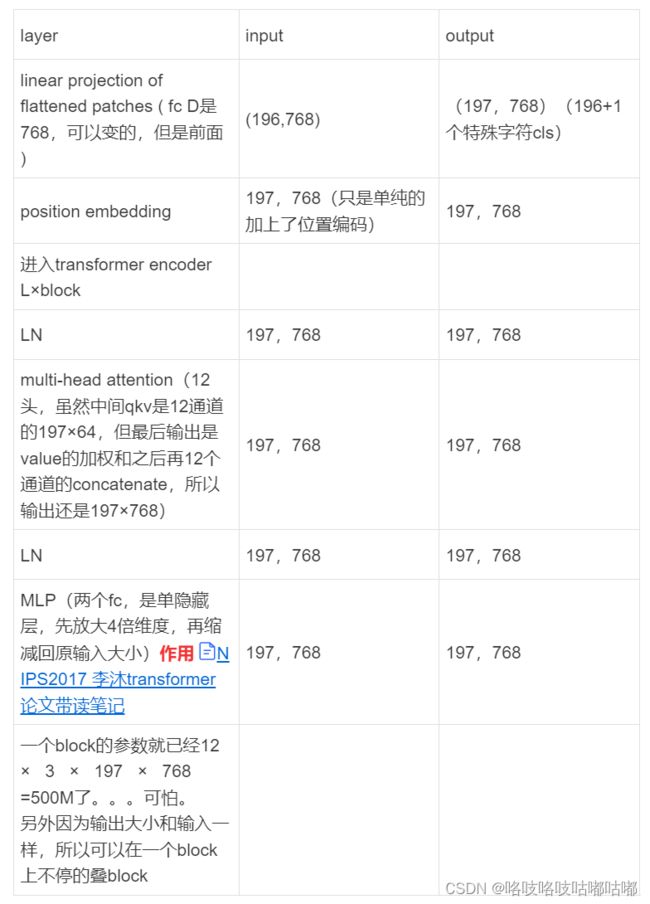
开始详细举例,比如输入一个图片是224×224×3。用16×16的patch size大小,会得到多少个token呢?
0、图像预处理操作:把图片打成patch后,224/16=14.所以得到N=14×14=196个token。每个图像块的维度是多少?是16×16×3=768 与输入图像大小无关。然后经过MLP(一个全连接),根据公式(1)也可以看出,每个 Xi 图像块都会和E(权重矩阵)相乘。(orz 暂时还不会打公式。。)
1、线性投射层就是一个FC全连接,他的参数矩阵用E来表示,大小是输入数据的flattened大小×输出维度,即E∈R768×D , 因为论文里D=768,则输出维度保持跟输入一样(768 = 16×16×3 是每个token里面包含的元素,所以说是flattened patches)
X·E∈R196×768 另外加一个特殊字符cls, 所以总共是197×768 ,可见公式(1)理解。
2、位置编码具体的做法是有一个表,每一行代表了1234…N的序号,每一行是一个向量(token)长度为768。把所有向量的位置信息加到token里,注意是直接sum不是concat! 加完位置编码信息之后,还是 (197,768) 然后进入transformer encoder里面。
3、trans encoder的输入就是197×768。每一个block都是,输入变成了三份,分别是k、q、v。因为是多头注意力机制,比如输入transformer encoder 的是197个token,每个token向量长度为768. 如果是多头,比如12头,则每个qkv向量的长度都变成了768/12=64。qkv 变成12× 197×64。表示有12种qkv ,出来后concat一下恢复成197×768了。然后再过一层LN。再过一层MLP,会把维度相应的放大,一般放大4倍,然后再缩小回原输入。然后进行L个block的操作。
4、用cls作为输出,经过MLP Head。
5、最后计算损失函数,得分类。
整个模型已经讲完了。
最后的cls这个特殊token的结果作为整个图的特征,是1×768。
另外,position编码使用的是标准的可学习的1D的位置编码,因为实验发现2D的位置编码没什么差别。然后embedding 后的结果序列输入到transformer encoder里。
具体的transformer结构如下

具体的数据维度变化可以做成一个表格更清晰直观。
关于分类头的问题:
为什么不能像以前CNN一样,不如最后是16×16×512通道,最后做一个global pooling,得到1×512的一维特征向量,然后再去fc,再softmax得到最后的分类输出呢??这里把197×768的结果给他pooling成一个1×768的一维向量呢?
而是用这里的一个extra token cls 作为输出的特征呢?
其实作者通过实验,得出结论,这两种都可以哈哈哈。。性能的区别在于lr学习率的设置!
他的目的只是为了尽可能和原始transformer保持一致。告诉我们NLP的模型照样能作CV。
未完待续。。。。不肝了碎觉啦,明天还要赶紧把swin看完以及选一篇要汇报的论文题目orz 鲨我