【重识云原生】第六章容器6.3.5节——Controller Manager概述

1 Controller Manager概述
1.1 Controller Manager简介
Controller Manager作为K8S集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。

每个Controller通过API Server提供的接口实时监控整个集群的每个资源对象的当前状态,当发生各种故障导致系统状态发生变化时,会尝试将系统状态修复到“期望状态”。
Controller Manager 由 kube-controller-manager 和 cloud-controller-manager 组成,是 Kubernetes 的大脑,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。

kube-controller-manager 由一系列的控制器组成:
- Replication Controller
- Node Controller
- CronJob Controller
- Daemon Controller
- Deployment Controller
- Endpoint Controller
- Garbage Collector
- Namespace Controller
- Job Controller
- Pod AutoScaler
- RelicaSet
- Service Controller
- ServiceAccount Controller
- StatefulSet Controller
- Volume Controller
- Resource quota Controller
cloud-controller-manager 在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,也包括一系列的控制器,如:
- Node Controller
- Route Controller
- Service Controller

从 v1.6 开始,cloud provider 已经经历了几次重大重构,以便在不修改 Kubernetes 核心代码的同时构建自定义的云服务商支持。参考 这里 查看如何为云提供商构建新的 Cloud Provider。
1.2 Metrics
Controller manager metrics 提供了控制器内部逻辑的性能度量,如 Go 语言运行时度量、etcd 请求延时、云服务商 API 请求延时、云存储请求延时等。
Controller manager metrics 默认监听在 kube-controller-manager 的 10252 端口,提供 Prometheus 格式的性能度量数据,可以通过 http://localhost:10252/metrics 来访问。
$ curl http://localhost:10252/metrics
...
# HELP etcd_request_cache_add_latencies_summary Latency in microseconds of adding an object to etcd cache
# TYPE etcd_request_cache_add_latencies_summary summary
etcd_request_cache_add_latencies_summary{quantile="0.5"} NaN
etcd_request_cache_add_latencies_summary{quantile="0.9"} NaN
etcd_request_cache_add_latencies_summary{quantile="0.99"} NaN
etcd_request_cache_add_latencies_summary_sum 0
etcd_request_cache_add_latencies_summary_count 0
# HELP etcd_request_cache_get_latencies_summary Latency in microseconds of getting an object from etcd cache
# TYPE etcd_request_cache_get_latencies_summary summary
etcd_request_cache_get_latencies_summary{quantile="0.5"} NaN
etcd_request_cache_get_latencies_summary{quantile="0.9"} NaN
etcd_request_cache_get_latencies_summary{quantile="0.99"} NaN
etcd_request_cache_get_latencies_summary_sum 0
etcd_request_cache_get_latencies_summary_count 0
...1.3 kube-controller-manager 启动示例
kube-controller-manager \
--enable-dynamic-provisioning=true \
--feature-gates=AllAlpha=true \
--horizontal-pod-autoscaler-sync-period=10s \
--horizontal-pod-autoscaler-use-rest-clients=true \
--node-monitor-grace-period=10s \
--address=127.0.0.1 \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/controller-manager.conf \
--cluster-signing-key-file=/etc/kubernetes/pki/ca.key \
--use-service-account-credentials=true \
--controllers=*,bootstrapsigner,tokencleaner \
--root-ca-file=/etc/kubernetes/pki/ca.crt \
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt \
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \
--node-cidr-mask-size=241.4 kube-controller-manager控制器分类
kube-controller-manager 由一系列的控制器组成,这些控制器可以划分为三组:
1)必须启动的控制器:18个
- EndpointController
- ReplicationController
- PodGCController
- ResourceQuotaController
- NamespaceController
- ServiceAccountController
- GarbageCollectorController
- DaemonSetController
- JobController
- DeploymentController
- ReplicaSetController
- HPAController
- DisruptionController
- StatefulSetController
- CronJobController
- CSRSigningController
- CSRApprovingController
- TTLController
2)默认启动可选的控制器,可以通过选项设置是否开启
- TokenController
- NodeController
- ServiceController
- RouteController
- PVBinderController
- AttachDetachController
3)默认禁止的可选控制器,可通过选项设置是否开启
- BootstrapSignerController
- TokenCleanerController
1.5 cloud-controller-manager控制器分类
cloud-controller-manager 在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,也包括一系列的控制器:
- CloudNodeController
- RouteController
- ServiceController
1.6 高可用
在启动时设置 --leader-elect=true 后,controller manager 会使用多节点选主的方式选择主节点。只有主节点才会调用 StartControllers() 启动所有控制器,而其他从节点则仅执行选主算法。
多节点选主的实现方法见 leaderelection.go。它实现了两种资源锁(Endpoint 或 ConfigMap,kube-controller-manager 和 cloud-controller-manager 都使用 Endpoint 锁),通过更新资源的 Annotation(control-plane.alpha.kubernetes.io/leader),来确定主从关系。
1.7 高性能
从 Kubernetes 1.7 开始,所有需要监控资源变化情况的调用均推荐使用 Informer。Informer 提供了基于事件通知的只读缓存机制,可以注册资源变化的回调函数,并可以极大减少 API 的调用。
Informer 的使用方法可以参考 这里。
1.8 node驱逐
Node 控制器在节点异常后,会按照默认的速率(–node-eviction-rate=0.1,即每10秒一个节点的速率)进行 Node 的驱逐。Node 控制器按照 Zone 将节点划分为不同的组,再跟进 Zone 的状态进行速率调整:
- Normal:所有节点都 Ready,默认速率驱逐。
- PartialDisruption:即超过33% 的节点 NotReady 的状态。当异常节点比例大于 --unhealthy-zone-threshold=0.55 时开始减慢速率:
- 小集群(即节点数量小于 --large-cluster-size-threshold=50):停止驱逐
- 大集群,减慢速率为 --secondary-node-eviction-rate=0.01
- FullDisruption:所有节点都 NotReady,返回使用默认速率驱逐。但当所有 Zone 都处在 FullDisruption 时,停止驱逐。
2 工作原理
在机器人技术和自动化领域,控制回路(Control Loop)是一个非终止回路,用于调节系统状态。比如温度自动控制,当你设置了温度,告诉了温度自动调节器你的期望状态(Desired State)。 房间的实际温度是当前状态(Current State)。 通过对设备的开关控制,温度自动调节器让其当前状态接近期望状态。

在 Kubernetes 中,控制器通过监控集群的公共状态,并致力于将当前状态转变为期望的状态。
一个控制器至少追踪一种类型的 Kubernetes 资源。这些对象有一个代表期望状态的spec字段。 该资源的控制器负责确保其当前状态接近期望状态。每个控制器的control loop 可以用以下的伪代码来解释:
for {
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired, current)
}讲到这里,我们基本上明白控制器工作原理了。那一个控制器包含哪些组件那?进而我们可以实现一个自定义的控制器。
控制器有两个主要组件:Informer/SharedInformer 和 Workqueue。 Informer/SharedInformer监视Kubernetes对象当前状态的变化,并将事件发送到Workqueue,然后由Workers pop 事件进行处理。

Reflector 和 APIServer 建立长连接,并使用 ListAndWatch 方法获取并监听某一个资源的变化。List 方法将会获取某个资源的所有实例(如ReplicaSet、Deployment等),Watch 方法则监听资源对象的创建、更新以及删除事件,获取到的事件称之为一个增量(Delta),该增量会被放进一个称之为 Delta FIFO Queue,即增量先进先出队列中。
然后,Informer会不断的从 Delta FIFO Queue 中 pop 增量事件,并根据事件的类型来决定新增、更新或者是删除本地缓存,也就是 Local Key-Value Sotrage。根据集群中某资源的事件来更新本地缓存是Informer的第一个职责。
Informer 的另外一个职责就是根据事件类型来触发事先注册好的 Event Handler。在回调函数中通常只会做一些简单的过滤处理,然后将该事件的Key(注意不是事件本身,只是事件的key,key的格式如/)添加到 Work Queue 这个工作队列中。
Work Queue提供了方便的功能来管理事件的Key。下图描述了Work Queue 事件的Key的生命周期:

在处理事件失败的情况下,控制器将调用AddRateLimited()函数将其Key推回到Work Queue,以便以后以预定义的重试次数进行处理。否则,如果处理成功,则可以通过调用Forget()函数从Work Queue中删除Key。但是,该功能只能停止Work Queue跟踪事件的历史记录。为了将事件Key从Work Queue中完全删除,控制器必须触发Done()函数。
接下来就是 Controller 的业务逻辑了,也就是上图中的 Processer。控制器从 Work Queue 中取出一个事件Key,然后通过indexer从本地存储获取具体事件,并根据自身的业务逻辑对其进行处理,不同的控制器会有不同的处理逻辑。
社区提供了一个示例controller -- sample-controller 。大家可以参阅学习。
编写一个自定义控制器,我们需要注意另外一个参数:resyncPeriod。如果resyncPeriod不为零,那么Reflector为以resyncPeriod为周期定期执行list的操作,这样就可以使用Reflector来定期处理所有的对象,也可以逐步处理变化的对象。
3 几种Controller简介
3.1 Replication Controller
controller manager 中的 Replication controller(副本控制器) 和 K8S 中的资源 replication controller 不是同一个东西, 为了区别, 此处将资源类型的 replication controller 用RC 表示, controller manager 中的replication controller 仍然用 replication controller 表示,指代副本控制器。
replication controller 的核心作用是保障集群中某个 RC 关联的pod副本数与预设值一致. 当pod 重启策略为always 时(RestartPolicy=Always), Replication Controller 才会管理该 POD 的操作(创建, 销毁, 重启等), 在默认情况下, POD 对象被创建成功后不会消失, 唯一例外是当pod 处于succeed 或failed 状态的实践过长(超时参数由系统设定)时, 该pod 会被系统自动回收, 管理该 pod 的副本控制器将在其他工作节点上重新创建,运行该POD 副本。
RC 中的POD 模版就像模具, POD 一旦通过模版制作出来,就和RC 再也没有联系了. 无论模版如何变化, 甚至换成一个新的模版, 也不会影响到已经创建的POD . 因此POD 可以通过修改标签来脱离 RC 的管控. 改方法可以用于将POD 从集群中迁移, 数据修复等调试。
- replication controller 的职责
- 确保集群中有且仅有N 个POD的实例, N 是RC 中定义的POD 副本数量;
- 通过调整 RC 的 spec.replicas 属性值来扩容或缩容;
- 通过改变 RC 中的 POD 模版(主要是镜像), 来实现滚动升级;
- replication controller 的使用场景
- 重新调度。当发生节点故障或Pod被意外终止运行时,可以重新调度保证集群中仍然运行指定的副本数。
- 弹性伸缩。通过手动或自动扩容代理修复副本控制器的spec.replicas属性,可以实现弹性伸缩。
- 滚动升级。创建一个新的RC文件,通过kubectl 命令或API执行,则会新增一个新的副本同时删除旧的副本,当旧副本为0时,删除旧的RC。
当 RC 的spec.relicas 设置为0 时, 相关pod 将会被删除。
3.2 Node Controller
kubelet在启动时会通过API Server注册自身的节点信息,并定时向API Server汇报状态信息,API Server接收到信息后将信息更新到etcd中。
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能。流程如下
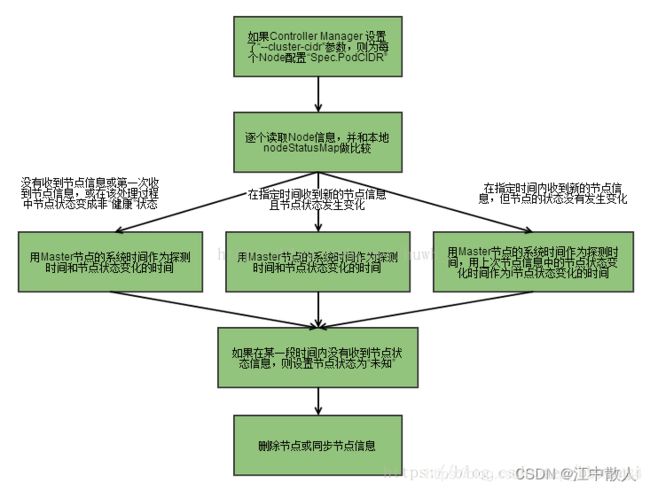
- controller manager 判断是否有 --cluster-cidr 参数, 如果有在每个节点设置spec.PodCIDR 并保障cidr 不冲突;
- 逐个读取Node 信息, 多次尝试修改nodeStatusMap中的节点状态信息, 将该节点信息和 Node Controller 的 nodeStatusMap 中保存的信息作比较;
- 如果判断出没有收到 kubelet 发送的信息, 第一次收到 kubelet 发送的的节点信息, 或在该处理过程中节点状态编程非"健康", 则在 nodeStatusMap 中保存该节点状态信息, 并用 Node Controller 所在节点的系统时间,作为探测时间和节点状态变化时间。
- 如果判断出在指定时间内受到的新的节点信息, 且节点状态发生变化, 则在 nodeStatusMap 中保存该界节点的状态信息. 并用 Node Controller 所在节点的系统时间,作为探测时间和节点状态变化时间。
- 如果判断出在指定时间内收到新的节点信息, 但状态没有变化则在 nodeStatusMap 中保存该节点的状态信息. 并用 Node Controller 所在节点的系统时间作为探测时间, 将上次节点信息中的节点状态变化时间作为该节点的状态变化时间. 如果判断出某段时间(gracePeriod) 内没有收到节点状态信息, 则设置节点状态为"位置", 并通过api server 保存节点状态。
- 逐个读取节点信息, 如果节点状态变为非"就绪"状态, 则将节点加入待删除队列, 否则将节点从该队列删除. 如果节点为非就绪状态, 且系统指定了 cloud provider, 则 Node Controller 调用 cloud provider 查看节点, 若发现节点故障 则删除etcd中的信息, 并删除该节点相关的pod 等资源信息。
3.3 ResourceQuota Controller
K8S 的配额管理是通过admiss control 来控制的, admission control 当前提供了两种方式进行配额约束, 分别是 LimitRanger 与 ResourceQuota. 其中 LimitRanger 作用于 POD 和 Container , ResourceQuota 作用于 Namespace。
资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源。 支持三个层次的资源配置管理:
1)容器级别:对CPU和Memory进行限制
2)Pod级别:对一个Pod内所有容器的可用资源进行限制
3)Namespace级别:包括Pod数量、Replication Controller数量、Service数量、ResourceQuota数量、Secret数量、可持有的PV(Persistent Volume)数量
1、k8s配额管理是通过Admission Control(准入控制)来控制的;
2、Admission Control提供两种配额约束方式:LimitRanger和ResourceQuota;
3、LimitRanger作用于Pod和Container;
4、ResourceQuota作用于Namespace上,限定一个Namespace里的各类资源的使用总额。
3.4 ResourceQuota Controller
用户通过API Server可以创建新的Namespace并保存在etcd中,Namespace Controller定时通过API Server读取这些Namespace信息。
如果Namespace被API标记为优雅删除(即设置删除期限,DeletionTimestamp),则将该Namespace状态设置为“Terminating”,并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount、RC、Pod等资源对象。
3.5 Endpoint Controller
Endpoints表示了一个Service对应的所有Pod副本的访问地址,而Endpoints Controller负责生成和维护所有Endpoints对象的控制器。它负责监听Service和对应的Pod副本的变化:
- 如果监测到Service被删除,则删除和该Service同名的Endpoints对象;
- 如果监测到新的Service被创建或修改,则根据该Service信息获得相关的Pod列表,然后创建或更新Service对应的Endpoints对象。
- 如果监测到Pod的事件,则更新它对应的Service的Endpoints对象。
Service、Endpoint、Pod的关系:
kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能。

3.6 Service Controller
Service Controller是属于kubernetes集群与外部的云平台之间的一个接口控制器。Service Controller监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表。
参考链接
k8s基础介绍(详细)_南柯一梦,笑谈浮生的博客-CSDN博客_k8s基础
一文看懂 Controller Manager - 知乎
kube-controller-manager · Kubernetes指南
[k8s] 第六章 Pod控制器详解(Controller-manager)_Young丶的博客-CSDN博客
k8s学习笔记(10)--- kubernetes核心组件之controller manager详解_victoruu的博客-CSDN博客
kubernetes之Controller Manager原理分析 - 走看看
Kubernetes Controller Manager 工作原理 - DockOne.io