MyBatis的使用(完整)
目录
一、mybatis框架介绍
1.1 什么是框架?
1.2 mybatis的介绍
1.3 为什么要使用mybatis
二、如何使用mybatis
2.1 引入mybatis和mysql的jar
2.2 创建mybatis的配置文件(可以直接复制)
2.3 创建数据库和表
2.4创建实体类
2.5 创建mybatis和数据库的映射文件(同样可以直接复制)
2.6测试mybatis
三、lombok插件
3.1idea安装lombok插件。(只需安装一次,如果已经安装直接跳到下一步)
编辑3.2在pom.xml中引入lombok的依赖
3.3 在实体类上添加lombok注解。
四、使用mybatis完成crud(增删改查)
五、mybatis优化
5..1 为实体类起别名
5.2 添加sql日志
六、添加模板(非常方便)
七、正规企业里的开发模式
7.1 实现过程
(1)创建一个dao接口(interface)并自定义需要的方法
(2)创建映射文件 (和上一章创建映射文件相同,如果你最后也添加了模板,我们直接new映射文件的模板即可)
3)测试
7.2 典型bug
(1)namespace和接口名不对应。 xml文件没有注册到mybatis配置文件中
(2) 映射文件中的标签id和接口中方法名不对应
7.3 安装mybatis插件
八、@Param实现传递多个参数
九、返回递增的主键值(添加方法时)
十、解决列名和属性名不一致问题的两种方法
10.1 方法一:为查询的列起别名,而别名和属性名一致 为sql语句中查询的列名起别名。在sql语句中,我们时可以为我们查询列名起别名的。
10.2 方法二:使用resultMap完成列和属性之间的映射关系。 通过resultMap标签将列名和属性名对应起来。
十一、动态sql
11.1 什么是动态sql
11.2 为什么要使用动态sql
11.3 mybatis中的动态sql标签
11.3.1 if标签--单条件判断
11.3.2 choose标签--多条件分支判断
11.3.3 where标签
11.4 foreach标签
十二、映射文件特殊字符的处理
十三、模糊查询
十四、联表查询
十五、分页插件PageHelper
十六、Generator----mybatis代码生成器
十七、mybatis的缓存
一级缓存的演示:
二级缓存的演示:
mybatis查询的顺序:
一、mybatis框架介绍
1.1 什么是框架?
框架就是别人搭建好的某些功能,你只需要引用该框架并加入自己的业务代码。就好比盖房子,有了别人搭建好的结构,一个月就能盖好几层。
使用框架的好处:可以提高我们的开发效率。
1.2 mybatis的介绍
MyBatis 是一款优秀的持久层Dao框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Java实体类)映射成数据库中的记录.
1.3 为什么要使用mybatis
可以简化jdbc的操作以及占位符赋值以及查询结果集的封装
二、如何使用mybatis
2.1 引入mybatis和mysql的jar
在我们的maven的java工程中的pom.xml文件中,引入我们的jar(不会的可以参考我的文章----maven的使用)。效果如下:
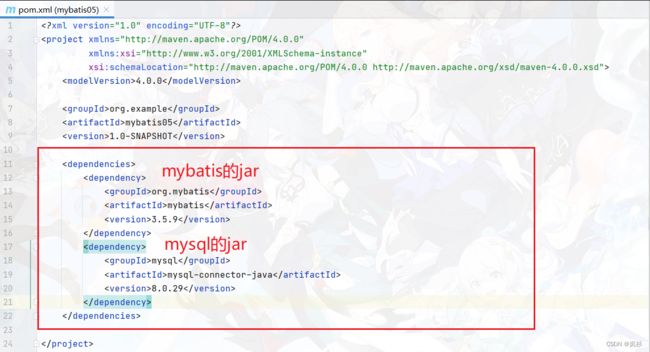
注意:引入完jar以后,千万不要忘记了刷新maven (刷新方法也在那一章博客里)
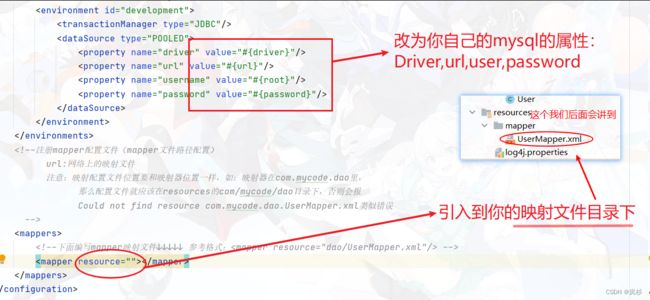
2.2 创建mybatis的配置文件(可以直接复制)
在resources下新建一个mybatis的xml文件

将下面的内容复制:
注意修改这些地方(非常重要):映射文件不懂得可以等到第五步会讲到
最终完整的例子:
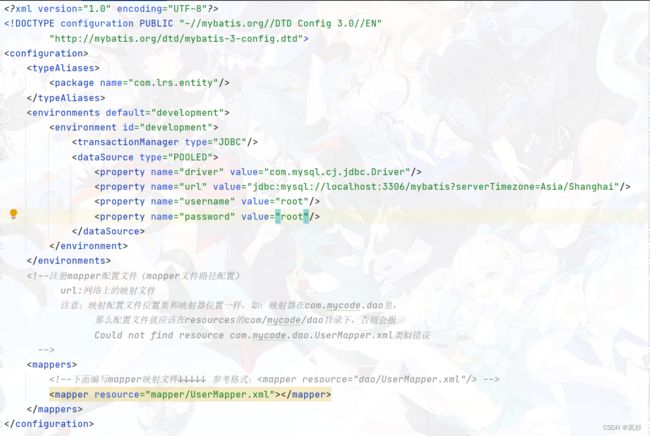
2.3 创建数据库和表
在Navicat中新建一个数据库和表,例如我上面的url中写的库名是mybatis,如果你想用你已经有的库和表的话就忽略此步。(Mysql相关的知识可以详见我的博客----Mysql基础部分)
2.4创建实体类
JDBC中的知识点。需要我们在entity包下新建一个实体类,这个实体类的类名就是你想用的数据库中的表名。里面的私有属性为你的列名。并且写上get和set方法以及同String方法。
public class User {
private int userid;
private String username;
private String realname;
public User() {
}
public User(String username, String realname) {
this.username = username;
this.realname = realname;
}
public User(int userid, String username, String realname) {
this.userid = userid;
this.username = username;
this.realname = realname;
}
@Override
public String toString() {
return "User{" +
"userid=" + userid +
", username='" + username + '\'' +
", realname='" + realname + '\'' +
'}';
}
public int getUserid() {
return userid;
}
public void setUserid(int userid) {
this.userid = userid;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getRealname() {
return realname;
}
public void setRealname(String realname) {
this.realname = realname;
}
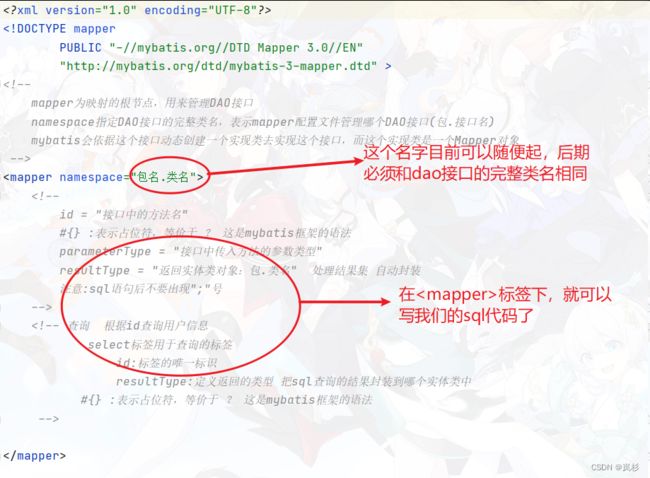
}2.5 创建mybatis和数据库的映射文件(同样可以直接复制)
在resources下建立mapper文件夹,并在文件夹中建立文件:XxxMapper.xml(Xxx为你的实体类名)。

注意修改这些地方(非常重要)
2.6测试mybatis
可以在这里建一个测试类,名字不要与”Test“重复(避免与junit冲突)。所以我们在测试之前可以在pom.xml文件中引入junit的jar,刷新以后再写测试。
测试代码如下所示
package com.test;
import com.lrs.entity.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import org.omg.CORBA.PUBLIC_MEMBER;
import java.io.IOException;
import java.io.Reader;
import java.util.List;
/**
* @作者:徐志豪
* @创建时间 2022/6/5
**/
public class Test01 {
@Test //测试根据id查询
public void testSelectOne() throws Exception{
Reader reader = Resources.getResourceAsReader("mybatis.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = factory.openSession();
Object o = session.selectOne("lrs.user.findById", 1);
System.out.println(o);
session.close();
}
}三、lombok插件
它可以帮你生成实体类的get和set方法 而且可以帮你生成构造方法。重写toString方法
插件引入步骤:
3.1idea安装lombok插件。(只需安装一次,如果已经安装直接跳到下一步)
-
 3.2在pom.xml中引入lombok的依赖
3.2在pom.xml中引入lombok的依赖
3.3 在实体类上添加lombok注解。
现在我们就可以很简介的书写我们的实体类了,只需要加入注解即可完成set,get,有参构造,无参构造和toString方法。
@Data //set和get方法以及toString方法
@NoArgsConstructor //无参构造
@AllArgsConstructor //全部参数构造函数
public class User {
private int userid;
private String username;
private String realname;
}四、使用mybatis完成crud(增删改查)
在UserMapper中写入sql的代码:
-
insert into tb_user values(null,#{username},#{realname}) delete from tb_user where userid = #{userid} update tb_user set username=#{username},realname=#{realname} where userid=#{userid} 测试部分的代码:
-
package com.test; import com.lrs.entity.User; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.junit.Test; import org.omg.CORBA.PUBLIC_MEMBER; import java.io.IOException; import java.io.Reader; import java.util.List; /** * @作者:徐志豪 * @创建时间 2022/6/5 **/ public class Test01 { @Test public void testSelectOne() throws Exception{ Reader reader = Resources.getResourceAsReader("mybatis.xml"); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader); SqlSession session = factory.openSession(); Object o = session.selectOne("lrs.user.findById", 1); System.out.println(o); session.close(); } @Test public void testSelectAll() throws Exception{ Reader reader = Resources.getResourceAsReader("mybatis.xml"); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader); SqlSession session = factory.openSession(); Listlist = session.selectList("lrs.user.selectAll"); System.out.println(list); session.close(); } @Test public void testAdd() throws IOException { Reader reader = Resources.getResourceAsReader("mybatis.xml"); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader); SqlSession session = factory.openSession(); User user = new User(); user.setUsername("lm"); user.setRealname("黎明"); int insert = session.insert("lrs.user.add", user); System.out.println(insert); session.commit(); //必须提交 session.close(); } @Test public void testDelete() throws Exception{ Reader reader = Resources.getResourceAsReader("mybatis.xml"); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader); SqlSession session = factory.openSession(); int delete = session.delete("lrs.user.delete", 8); System.out.println(delete); session.commit(); session.close(); } @Test public void testUpdate() throws Exception{ Reader reader = Resources.getResourceAsReader("mybatis.xml"); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader); SqlSession session = factory.openSession(); User user = new User(9,"wjk","王俊凯"); int update = session.update("lrs.user.update", user); System.out.println(update); session.commit(); session.close(); } } 注意: 当我们对数据库里的表做删除修改添加的时候,也就是需要改变表里的数据的时候,一定不要忘记了加上提交(session.commit();),不然数据库里的内容不会发生改变。像查询方法就不需要写这一行代码,因为查询的时候没有改动表内容。
-
五、mybatis优化
5..1 为实体类起别名
- 在mybatis.xml文件中配置文件:
-

5.2 添加sql日志
未来在你的项目上线以后,需要sql日志来帮助我们维护我们的项目,他可以方便我们查询sql语句以及占位符处传入的参数是否正确,是我们修改bug的好帮手!
步骤:
- 在po.xml中添加日志的jar.
-
log4j log4j 1.2.17 - 添加日志的文件配置------ log4j.properties 必须以这样命名!不能随便乱起名。在文件中复制下面的代码:
-
log4j.rootLogger=DEBUG, Console #Console log4j.appender.Console=org.apache.log4j.ConsoleAppender log4j.appender.Console.layout=org.apache.log4j.PatternLayout log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n log4j.logger.java.sql.ResultSet=INFO log4j.logger.org.apache=INFO log4j.logger.java.sql.Connection=DEBUG log4j.logger.java.sql.Statement=DEBUG log4j.logger.java.sql.PreparedStatement=DEBUG六、添加模板(非常方便)
-
了解学习了上面的mybatis后,我们知道,在mybatis.xml和XxxMapper.xml文件中,有很多我们需要复制的代码,那么我们可以将这些代码作为一个模板,以后再new这些文件的时候可以直接new你的模板,然后再修改相关内容,可以大大节省我们的时间!
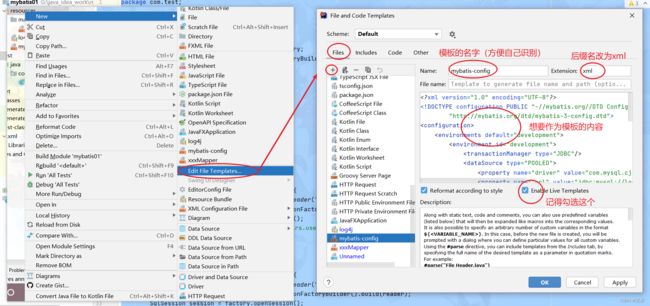
最后点击OK或者Apply即可。以后在new的时候直接选择模板。

七、正规企业里的开发模式
在上面,使用了 SqlSession封装的一些方法完成了crud操作,但是SqlSession封装的方法,传递占位符的参数只能传递一个。而且他的方法名称都是固定。
真实在开发环境下我们不使用SqlSession封装的方法,而是习惯自己定义方法,自己调用自己的方法。也就是通过dao和映射文件的关联来完成操作
7.1 实现过程
(1)创建一个dao接口(interface)并自定义需要的方法
public interface UserDao {
/**
* 查询所有
* @return
*/
public List findAll();
} (2)创建映射文件 (和上一章创建映射文件相同,如果你最后也添加了模板,我们直接new映射文件的模板即可)
这里面要特别注意的是,我们的命名空间(namespace)不能再像上一章时随便起了,这里必须必须和dao的接口相同。mapper里面的sql标签里的id也不能随便起了,必须和你dao里面的方法名相同。
3)测试
@Test
public void testFindAll() throws Exception{
Reader resourceAsReader = Resources.getResourceAsReader("mybatis.xml");
SqlSessionFactory factory=new SqlSessionFactoryBuilder().build(resourceAsReader);
SqlSession session=factory.openSession();
//获取相应接口的代理对象
UserDao userDao=session.getMapper(UserDao.class);
List list = userDao.findAll();
System.out.println(list);
session.commit();
session.close();
} 这里面需要注意的是,前几行的代码和我们上一章的写法一样,但是我们不再使用session里面有的方法了,我们需要用我们自己定义的方法。那么想要实现用自己定义的方法,就需要获取结接口相应的代理对象 。
UserDao userDao=session.getMapper(UserDao.class);我们输出一下这个userDao变量到控制台,他会显示如下的内容:
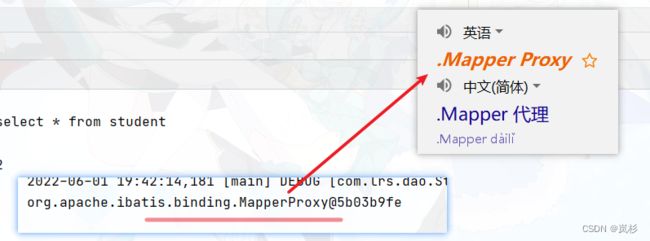
翻译一下就知道,这个userDao变量就相当于我们的xxx接口的代理对象了。我们直接用这个变量就可以
7.2 典型bug
(1)namespace和接口名不对应。 xml文件没有注册到mybatis配置文件中
![]()
(2) 映射文件中的标签id和接口中方法名不对应
![]()
7.3 安装mybatis插件
在我们用这种规范来书写代码时,会感到有些略微繁琐和不方便 ,这是idea中有一个插件,可以帮助我们生成mapper xml文件、快速从代码跳转到mapper及从mapper返回代码、mybatis自动补全及语法错误提示、集成mybatis generator gui界面、根据数据库注解,生成swagger model注解等功能,非常 的方便
如果mapper中没有对应的方法,可以alt+enter自动生成(sql代码还是需要自己写的)
如果mapper里面的id没有找到与dao里面的方法名相对应的也会报红提示。
八、@Param实现传递多个参数
我们在dao接口中某些方法可能需要传递多个参数,譬如: 登录(username,password),但是我们只能传一个参数。之前我们采取的办法是把多个参数封装到一个对象里再把对象当作参数传输。现在我们可以在参数处使用@Param()为参数起名。 不然不可以在 #{ } 里面写自己的参数名,会变成param1,param2...
九、返回递增的主键值(添加方法时)
需要返回添加数据库后的id值。 需要用到标签里面的两个属性:(1)useGeneratedKeys:设置使用生成的主键 (2)keyProperty:将接到的值 赋值给你实体类中的哪个属性 注意这里的属性名不能写错,不然就接不到值了。
insert into tb_user values(null,#{username},#{realname})
控制台生成的效果如下,我们可以看到,数据库里的主键id已经成功的传到了我们的id属性中。

十、解决列名和属性名不一致问题的两种方法
如果我们的实体类中的属性名,和我们的数据库里表的列名不相同,那么我们在输出查询的结果时,就接不到值,因为名称不同,不能将值传到与之对应的属性内。
这时我们就需要想办法去解决这个问题。下面提供两个方法来解决这个问题:
10.1 方法一:为查询的列起别名,而别名和属性名一致
为sql语句中查询的列名起别名。在sql语句中,我们时可以为我们查询列名起别名的。
select id as '学号' from student ;
这里的as是可以省略的。我们需要通过别名将列名变为我们的实体类中对应的属性名。这样属性名和列名就可以对应起来了。
10.2 方法二:使用resultMap完成列和属性之间的映射关系。
通过resultMap标签将列名和属性名对应起来。
需要注意的是:
sql标签中的resultMap属性和resultType二者只能用一个。
resultMap标签可以有多个。
sql标签中的resultMap的名称必须和想要使用的resultMap标签的id名相同。
如果列名和属性名有些一致的,可以在resultMap中不写映射关系
十一、动态sql
11.1 什么是动态sql
根据参数的值,判断sql的条件。 就好比,前端传入的name值如果为空,就查询所有,如果有值,就加上条件 where name=#{name}
11.2 为什么要使用动态sql
当我们的列名特别多,数据量特别大的时候,我们不可能一条一条写sql语句。这不现实。就好比你在网上商城买东西,搜索物品时的检索条件,可以是价格范围,品牌,大小,颜色,系列等等,那么组合出来的sql语句就成千上万条了。这时就需要用到我们的动态sql。
11.3 mybatis中的动态sql标签
大致有这些,我们下面一个一个讲解

11.3.1 if标签--单条件判断
好比我们的if判断语句,如果满足条件就执行if标签内的sql语句,如果不满足就不执行。
//如果name不为null则按照name查询 如果为null则查询所有
public List findByCondition(@Param("name")String name,@Param("money") Double money); 注意:”where“是不能放在下面的if里面的。而且where后面需要跟一个恒等式。这样不管是哪种拼接方式都是合理的。这个大家可以自己悟一悟,多想一想就可以明白了。
11.3.2 choose标签--多条件分支判断
好比我们的switch case语句。他是自带break功能的。如果里面的
11.3.3 where标签
我们观察到上面的sql都加了 where 1=1 ,如果不使用where 1=1 那么你的动态sql可能会出错。 我们能不能不加where 1=1呢! 可以 那么我们就可以使用where标签,作用:可以自动为你添加where关键字,并且可以帮你去除第一个and |or
@Test
public void testUpdateBySet() throws Exception{
SqlSession session = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("mybatis.xml")).openSession();
StudentDao studentDao = session.getMapper(StudentDao.class);
Student student = new Student(1,"lrs",45,2,null);
//Student student1 = new Student(2,"",18,null,null);
int i = studentDao.updateBySet(student);
System.out.println(i);
session.commit();
session.close();
}我们需要修改的值为name,age,cid,这些都不为空, 那么动态sql语句就应该变成:
可以发现,set标签会自动帮我们去除最后cid处的逗号。
11.4 foreach标签
循环标签,可以帮助我们处理一些动态的批量任务,例如批量添加,批量查询,批量删除等等。我们可以传入一个数组或者一个list集合,然后通过foreach标签将集合内的条件一个一个的放入我们的sql语句从而实现动态的批量处理效果。
foreach标签内属性:
collection:类型 如果你使用的为数组array 如果你使用的为集合 那么就用list
item:数组中每个元素赋值的变量名
open: 以谁开始
close:以谁结束
separator:分割符
用到的数据库的表如图。下面给大家列举三个例子:
(1)根据id批量查询学生信息
StudentDao:
StudentMapper:
stu_id,stu_name,stu_age,cid
(2)根据id批量删除
StudentDao:

StudentMapper:
delete from student where stu_id in
#{id}
(3)批量添加学生信息
这里我们传入的参数可以换成集合类型------List
StudentDao:
StudentMapper:注意,我们要想调用list集合内的Student对象的属性,调用的写法应该为“Xxx(item名称).xxx(属性名)”。同样自定义对象类型的数组也应该这样调用属性。
insert into student values
(null,#{stu.name},#{stu.age},#{stu.cid})
十二、映射文件特殊字符的处理
在Mapper中写我们的sql语句中,会遇到一些特殊的字符,他会与我们的sql代码会产生冲突,例如我们sql中写这样的语句:
可以看到我们的小于号,就是一种特殊字符。那么我们该如何处理这种问题?
有两种方法可以解决。
第一种:使用转义符。java中有这些特殊字符的转义符。
第二种:用 方法 注意这种方法不能括住我们的标签(例如include标签),我们可以在需要用到的地方使用这个方法,没必要整个sql语句都套入在内。
十三、模糊查询
模糊查询的sql语句:
select * from 表名 where 列名 like '%a%'有两种方法可以实现这种拼接。
(1)使用字符串函数 完成拼接 -----concat(这属于sql基础的知识点)
(2) 使用${ } 代替。 这种方式实际上是字符串的拼接,他并不能防止sql注入问题,而我们之前用的#{ }就相当于预编译,可以防止sql注入问题。所有这种方式不推荐使用,所谓防君子不防小人。
十四、联表查询
例子:根据id查询学生信息并包括该学生所在的班级信息。
需要用的表:我们需要从多的一方来查询一的一方。这里学生表就相当于多的一方,班级表就相当于1的一方。
sql语句:
select * from tb_stu s join tb_class c on s.class_id=c.cid where stu_id= xxx
实现方式一:
首先在我们的Student实体类种(相当于多的一方)加入我们AClass类型(一的一方)的属性
package com.lrs.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @作者:徐志豪
* @创建时间 2022/6/5
**/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private Integer id;
private String name;
private Integer age;
private Integer cid;
private AClass aClass; //AClass类型的属性。
}
StudentDao:
StudentMapper: 重点:resultMap标签内的association标签 :表示 一 的一方。property:表示属性名(就是我们实体类种的aclass属性)。javaType:表示该属性名对应的数据类型。
stu_id,stu_name,stu_age,s.cid c_id,c.cid,cname
实现方式二:
map封装(不推荐这种方式)。用这种方式封装我们查询到的数据,就不需要改动我们的实体类,也不用关心其属性内的映射关系。
StudentDao:
StudentMapper:
需要避免的问题:两个表的列名应该尽量避免相同,如果相同,需要起别名来区别。resultMap中的标签内的column属性应该与你起了别名后的列名相同。Map本身也是无序不重复的,我们的属性名也就是map中的key值也需要保证不能相同。
体会:使用mybatis我们需要做的事情就是处理好查询到的结果与返回值,难点就在于将返回的内容处理好,其他的一些包括sql语句标签和动态sql标签都是帮助我们书写sql语句的,基础的sql部分的知识点需要掌握。框架的好处就是帮我们简化流程
十五、分页插件PageHelper
在我们日常使用中,缺少不了分页查询,就好比你百度时,那么多的数据,肯定需要分页来处理。那么我们就可以用分页插件来帮我们快速实现分页查询操作
首先了解一下分页查询的sql语句:
select * from 表名 [where条件] limit (page-1)*pageSize,pageSize其中的page代表你想要查询的页码数,pageSize代表你想要每页显示的数据个数。
那么我们该如何使用分页插件呢?具体步骤如下:
(1)在pom.xml中引入pageHelper的依赖jar包
com.github.pagehelper
pagehelper
5.1.11
(2) 在mybatis.xml中设置pageHelper的拦截器(写在mybatis中得configuration标签内)
注意:这里有一个需要注意的地方,我们的拦截器写的位置是有要求的。在

(3)使用pageHelper
我们可以在测试里使用,未来就相当于在servlet层中使用。我们分页查询出来的内容记得要封装到pageInfo类中,因为pageInfo类中有get方法,可以调用出我们想要的数据。
注意:要在执行查询的方法之前写PageHelper。
@Test
public void testSelect() throws Exception{
Reader reader = Resources.getResourceAsReader("mybatis.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = factory.openSession();
UserMapper sessionMapper = session.getMapper(UserMapper.class);
PageHelper.startPage(1,3);
List users = sessionMapper.selectAll();
//封装到PageInfo类中
PageInfo userPageInfo = new PageInfo(users);
//getTotal():获取表中数据的总个数
//getPages():获取总页数
//getPageSize():获取当前页查询到的数据的个数
//getList():获取当前页码对应的数据
long total = userPageInfo.getTotal();
System.out.println("表中一共有"+total+"条数据");
System.out.println(users);
session.commit();
session.close();
} 
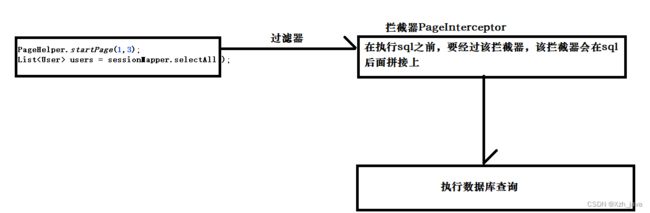
分页拦截器原理:
在我们使用了pageHelper以后,他会在我们执行查询数据库的方法之前,先在sql语句中拼接上我们limit分页关键字以及后面跟的数据,然后再执行查询。
十六、Generator----mybatis代码生成器
作用:generator可以帮我们快速生成实体类,dao和xml映射文件,帮我们实现简单的增删改查功能。
这是官网,上面有具体的介绍和使用方法等。
http://mybatis.org/generator/ http://mybatis.org/generator/
http://mybatis.org/generator/
这里讲一下java中如何使用。
(1)引入mybatis-generator的jar包
org.mybatis.generator
mybatis-generator-core
1.4.0
2)generator的配置文件。
注意:这个配置文件必须写在工程目录下。
代码如下:直接复制即可。(设置file名为generatorConfig)
需要修改的地方见代码中的注释。其中包含了一个解决mybatis逆向工程生成xml时重复生成多次数据库表配置的问题。再生成后可能会出现这种问题,原因是如果你不是标准的数据库表命名格式,就有可能出现数据库中的所有同名表被多次生成的情况。
(3) 运行配置文件
可以在我们的测试中运行配置文件。直接复制粘贴代码即可。
List warnings = new ArrayList();
boolean overwrite = true;
File configFile = new File("generator.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
myBatisGenerator.generate(null); 注意:new File( )中的xml文件名是你配置文件的文件名,不要忘记修改成自己的。
运行以后就生成好了dao,实体类和mapper映射文件。里面包含了一些基础的增删改查方法。(没有查询所有)。没有的方法可以像以前一样自己写。

十七、mybatis的缓存
什么是缓存?
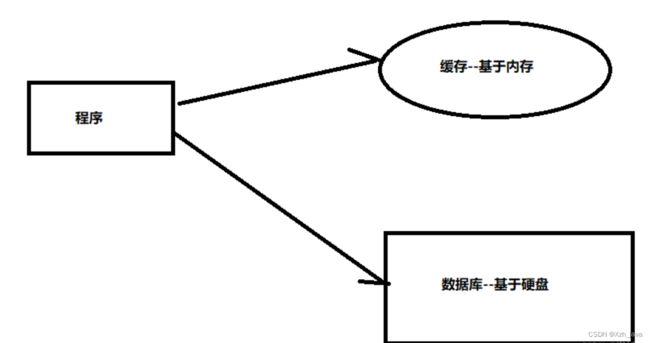
缓存就是存在与内存中的临时数据。mysql数据库中的数据存在表中,表中的数据存在我们电脑的磁盘里,所以我们就算关掉数据库,关掉电脑,我们数据库中的数据也会存在。
缓存的好处
使用缓存可以减少和数据库之间的交互次数,提高代码的执行效率。可以理解为我们电脑的内存,固态,机械硬盘,缓存可以相当于内存,那么效率孰高孰低一目了然。
如果是第一次执行查询该数据,那么会先查询数据库,并把查询的结果放到缓存中,以后可以直接从缓存中获取数据,从而减少对数据库的访问频率。之后再查询的时候,程序会先看缓存中是否有目标数据,如果有直接在缓存中获取结果,如果没有那么还会在数据库中查询。
缓存中适合放入的数据:
(1)经常查询,且不回经常改变的数据。
(2)数据的正确与否对最终影响结果不大的。
缓存中不适合放入的数据:
(1)经常改变的数据
(2)数据的正确与否对最终结果影响很大的。即对数据安全性要求很高。
例如:商品的库存,银行的汇率,股市的牌价。
mybatis中的缓存
mybatis支持两种缓存
(1)一级缓存,基于SqlSession级别的缓存。默认一级缓存是开启的,不能关闭。
(2)二级缓存--基于SqlSessionFactory级别的缓存,它可以做到多个SqlSession共享数据。默认它是关闭。需要手动开启。
一级缓存的演示:
@Test
public void testSelect() throws Exception{
//一级缓存基于同一个session
Reader reader = Resources.getResourceAsReader("mybatis.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = factory.openSession();
UserMapper sessionMapper = session.getMapper(UserMapper.class);
PageHelper.startPage(1,3);
List users = sessionMapper.selectAll();
System.out.println(users);
List users1 = sessionMapper.selectAll();
System.out.println(users1);
} 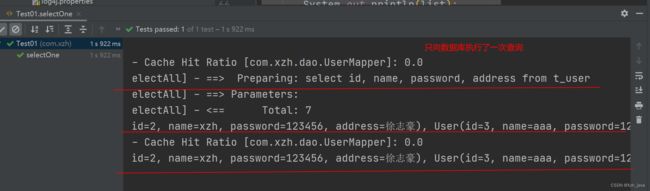
当我们查询同一个数据时,sql语句只执行了一次,第二次查询的时候就没有再去数据库中执行查询了。如果缓存中没有这个数据,那么它就会在数据库中执行查询,然后把查询的结果存到缓存中。注意:必须是在同一个SqlSession中执行,否则还是会在数据库中查询。
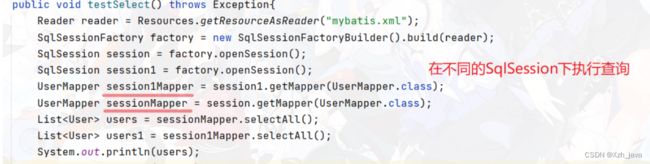
可以看到sql语句被执行了两遍,相当于第二次查询并没有在缓存中执行。

二级缓存的演示:
二级缓存默认是关闭的,需要我们手动开启。
(1)开启二级缓存。
在mybatis.xml中加入如下代码,注意放入的位置。在分页插件中我们就讲过里面的顺序问题,settings应该放在plugins的前面。

在mybatis下configuration标签下加入
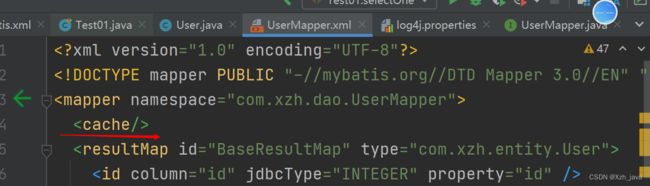
(2)在映射文件中的mapper下使用二级缓存。只需加入一句:
加入这个代码后,映射文件里的所有查询都使用了二级缓存。
(3)实体类中实现序列化接口
二级缓存实际底层的原理时HashMap,调用缓存就相当于进行IO操作。在java中,对java对象进行IO操作时,需要让类实现序列化,也就是类要有Serializable接口。所以我们的实体类中也要加序列化接口。

(4)测试二级缓存
@Test
public void testSlectById() throws Exception{
Reader reader = Resources.getResourceAsReader("mybatis.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = factory.openSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectByPrimaryKey(2);
System.out.println(user);
session.close();
SqlSession session1 = factory.openSession();
UserMapper mapper1 = session1.getMapper(UserMapper.class);
User user1 = mapper1.selectByPrimaryKey(2);
System.out.println(user1);
}为了区别一级缓存,我们先在执行完一遍查询以后,先关闭一级缓存,然后新建SqlSession在执行同样的查询。可以看到,数据库查询只执行了一次。

mybatis查询的顺序:
二级缓存→一级缓存→数据库。
如果二级缓存没有命中,就去一级缓存中查询,一级缓存中也没有命中,就在数据库中查询。