Opencv项目实战:10 面部特征提取及添加滤镜
1、效果展示
这是打开摄像头的展示,用的手机的图片,我是十分的不好意思露面,诸位看看效果就好。
让我们来看看图片的形式吧:
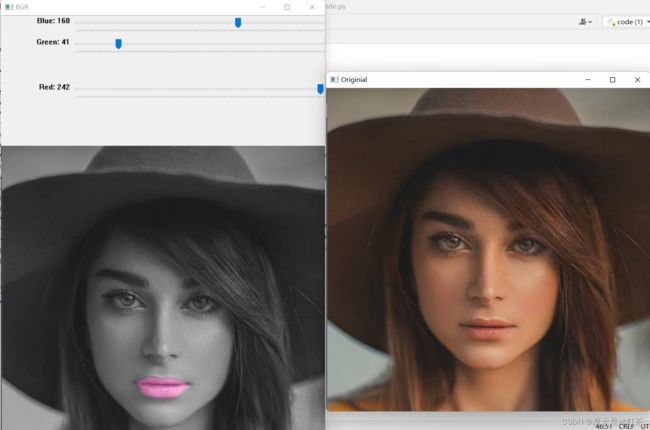
很不错的死亡芭比粉,效果也是相当不错的,而且图片不像摄像头那样,它的展示效果更好。
2、项目介绍
本次项目,我将采取dlib和shape_predictor_68_face_landmarks.dat文件,为图像添加蒙版,更改嘴唇的色号,如果你想修改其他的部位,它的方法是同理的,除此之外,我还会让图片显示出脸部的68个地表,请敬请期待吧!
3、项目搭建
本次项目的搭建只是需要找到官网下载的一个文件。
点击这里进入Index of /files (dlib.net)
你会看见这个页面:

紧接着,我们拉到最底下,下载这个文件。
 请注意,你所下载下来的文件是个压缩包,只有解压后才能使用。以上是所需文件的来源。
请注意,你所下载下来的文件是个压缩包,只有解压后才能使用。以上是所需文件的来源。
由于GitHub上面上传的东西不能超过25MB,所以这一步需要你自己去下载。
1.png为我们图像所要检测的,2.jpg为视频中检测的。
4、代码展示与讲解
import cv2
import numpy as np
import dlib
webcam = False
cap = cv2.VideoCapture(0)
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def empty(a):
pass
cv2.namedWindow("BGR")
cv2.resizeWindow("BGR", 640, 240)
cv2.createTrackbar("Blue", "BGR", 153, 255, empty)
cv2.createTrackbar("Green", "BGR", 0, 255, empty)
cv2.createTrackbar("Red", "BGR", 137, 255, empty)
def createBox(img, points, scale=5, masked=False, cropped=True):
if masked:
mask = np.zeros_like(img)
mask = cv2.fillPoly(mask, [points], (255, 255, 255))
img = cv2.bitwise_and(img, mask)
# cv2.imshow('Mask',mask)
if cropped:
bbox = cv2.boundingRect(points)
x, y, w, h = bbox
imgCrop = img[y:y + h, x:x + w]
imgCrop = cv2.resize(imgCrop, (0, 0), None, scale, scale)
cv2.imwrite("Mask.jpg", imgCrop)
return imgCrop
else:
return mask
while True:
if webcam:
success, img = cap.read()
else:
img = cv2.imread('1.png')
img = cv2.resize(img, (0, 0), None, 0.80, 0.80)
imgOriginal = img.copy()
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(imgOriginal)
for face in faces:
x1, y1 = face.left(), face.top()
x2, y2 = face.right(), face.bottom()
# imgOriginal=cv2.rectangle(imgOriginal, (x1, y1), (x2, y2), (0, 255, 0), 2)
landmarks = predictor(imgGray, face)
myPoints = []
for n in range(68):
x = landmarks.part(n).x
y = landmarks.part(n).y
myPoints.append([x, y])
# cv2.circle(imgOriginal, (x, y), 5, (50,50,255),cv2.FILLED)
# cv2.putText(imgOriginal,str(n),(x,y-10),cv2.FONT_HERSHEY_COMPLEX_SMALL,0.8,(0,0,255),1)
# print(myPoints)
if len(myPoints) != 0:
try:
myPoints = np.array(myPoints)
imgEyeBrowLeft = createBox(img, myPoints[17:22])
imgEyeBrowRight = createBox(img, myPoints[22:27])
imgNose = createBox(img, myPoints[27:36])
imgLeftEye = createBox(img, myPoints[36:42])
imgRightEye = createBox(img, myPoints[42:48])
imgLips = createBox(img, myPoints[48:61])
cv2.imshow('Left Eyebrow', imgEyeBrowLeft)
cv2.imshow('Right Eyebrow', imgEyeBrowRight)
cv2.imshow('Nose', imgNose)
cv2.imshow('Left Eye', imgLeftEye)
cv2.imshow('Right Eye', imgRightEye)
cv2.imshow('Lips', imgLips)
maskLips = createBox(img, myPoints[48:61], masked=True, cropped=False)
imgColorLips = np.zeros_like(maskLips)
b = cv2.getTrackbarPos("Blue", "BGR")
g = cv2.getTrackbarPos("Green", "BGR")
r = cv2.getTrackbarPos("Red", "BGR")
imgColorLips[:] = b, g, r
imgColorLips = cv2.bitwise_and(maskLips, imgColorLips)
imgColorLips = cv2.GaussianBlur(imgColorLips, (7, 7), 10)
imgOriginalGray = cv2.cvtColor(imgOriginal, cv2.COLOR_BGR2GRAY)
imgOriginalGray = cv2.cvtColor(imgOriginalGray, cv2.COLOR_GRAY2BGR)
imgColorLips = cv2.addWeighted(imgOriginalGray, 1, imgColorLips, 0.4, 0)
cv2.imshow('BGR', imgColorLips)
except:
pass
cv2.imshow("Originial", imgOriginal)
if cv2.waitKey(1) == 27:
break今天的讲解方式不一样,这个代码是完成最终效果后的,大家要理解这其中的道理还需要借助已经注释掉的内容,所幸我今天下午才做好,带着大家过一过思路吧。
大家看我的题目就知道是分为两个部分的;请注意,如果你没有看过我的实战项目(1条消息) Opencv项目实战:07 人脸识别和考勤系统_夏天是冰红茶的博客-CSDN博客,请看看此篇。你也可以直接跳转到这里,查看dlib的下载方法(1条消息) Python3.7最简便的方式解决下载dlib和face_recognition的问题_夏天是冰红茶的博客-CSDN博客
part1 面部特征提取
import cv2
import numpy as np
import dlib
img = cv2.imread('1.png')
img = cv2.resize(img, (0, 0), None, 0.80, 0.80)
imgOriginal = img.copy()
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(imgOriginal)
for face in faces:
x1, y1 = face.left(), face.top()
x2, y2 = face.right(), face.bottom()
imgOriginal=cv2.rectangle(imgOriginal, (x1, y1), (x2, y2), (0, 255, 0), 2)
landmarks = predictor(imgGray, face)
myPoints = []
for n in range(68):
x = landmarks.part(n).x
y = landmarks.part(n).y
myPoints.append([x, y])
cv2.circle(imgOriginal, (x, y), 5, (50,50,255),cv2.FILLED)
cv2.putText(imgOriginal,str(n),(x,y-10),cv2.FONT_HERSHEY_COMPLEX_SMALL,0.8,(0,0,255),1)
print(myPoints)
cv2.imshow("Originial", imgOriginal)
cv2.waitKey(0)在讲解之前,我们先来看看它的效果图:
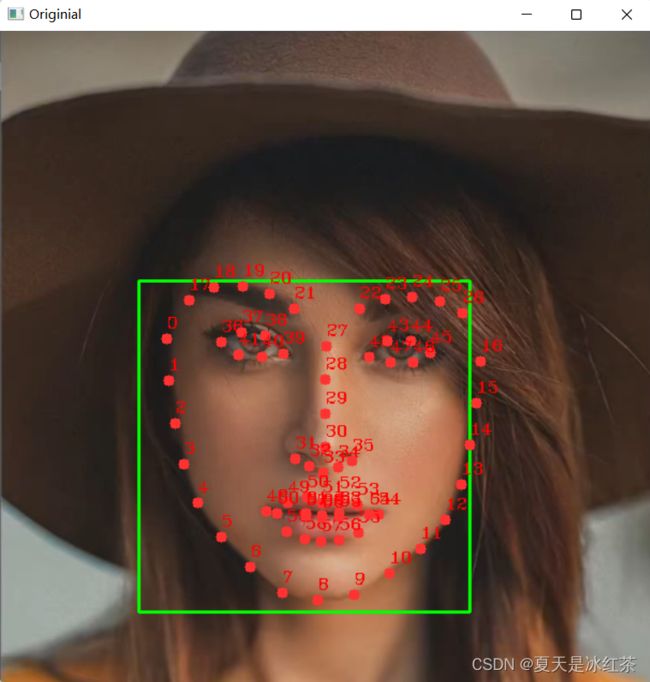
相当的棒,各位也看到了,我们是成功识别了面部,并得到了68个面部特征。
- 首先,包的引入,读取图片,修改图片的大小,copy原图像,都是相当基础的操作了。detector变量用来接受返回默认人脸检测器,找到图中的脸;
- 接着需要一个预测变量,用dlib.shape_predictor来获得我们下载的检测面部68个特征的文件。将copy后的图像传入检测器,在for循环当中检测出我们的边界框,内部嵌入中的x,y是作为dlib点的对象的单个部分,画出这个点,并标记出它的数值;
- 最后,展示我们最终的图像。
part2 提取面部的某个部分
这次先看我们的效果图,我们的目的是为了提取出相应的脸部部位。
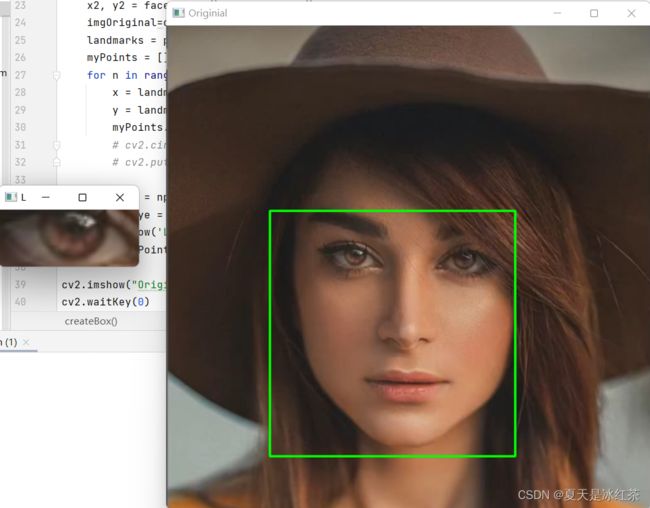
import cv2
import numpy as np
import dlib
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def createBox(img, points, scale=3):
bbox = cv2.boundingRect(points)
x, y, w, h = bbox
imgCrop = img[y:y + h, x:x + w]
imgCrop = cv2.resize(imgCrop, (0, 0), None, scale, scale)
return imgCrop
img = cv2.imread('1.png')
img = cv2.resize(img, (0, 0), None, 0.80, 0.80)
imgOriginal = img.copy()
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(imgOriginal)
for face in faces:
x1, y1 = face.left(), face.top()
x2, y2 = face.right(), face.bottom()
imgOriginal=cv2.rectangle(imgOriginal, (x1, y1), (x2, y2), (0, 255, 0), 2)
landmarks = predictor(imgGray, face)
myPoints = []
for n in range(68):
x = landmarks.part(n).x
y = landmarks.part(n).y
myPoints.append([x, y])
# cv2.circle(imgOriginal, (x, y), 5, (50,50,255),cv2.FILLED)
# cv2.putText(imgOriginal,str(n),(x,y-10),cv2.FONT_HERSHEY_COMPLEX_SMALL,0.8,(0,0,255),1)
myPoints = np.array(myPoints)
imgEyeBrowLeft = createBox(img, myPoints[17:22])
imgEyeBrowRight = createBox(img, myPoints[22:27])
imgNose = createBox(img, myPoints[27:36])
imgLeftEye = createBox(img, myPoints[36:42])
imgRightEye = createBox(img, myPoints[42:48])
imgLips = createBox(img, myPoints[48:61])
cv2.imshow('Left Eyebrow', imgEyeBrowLeft)
cv2.imshow('Right Eyebrow', imgEyeBrowRight)
cv2.imshow('Nose', imgNose)
cv2.imshow('Left Eye', imgLeftEye)
cv2.imshow('Right Eye', imgRightEye)
cv2.imshow('Lips', imgLips)
cv2.imshow("Originial", imgOriginal)
cv2.waitKey(0)效果图展示的只是左眼,而在我们的代码里面我们提取的特征有左、右眉毛;左、右眼睛;鼻子,嘴唇等。而在这里新写的createBox函数,我们还会继续拓展,所以在此处略过。
part3 建立面部的蒙版
我们知道,在上色时我们需要准确的位置,不能用矩形,而要用多边形,这就需要我们知道嘴唇精确的点,为求方便,我们就来看嘴唇部分的蒙版。
import cv2
import numpy as np
import dlib
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def createBox(img, points, scale=3):
mask = np.zeros_like(img)
mask = cv2.fillPoly(mask, [points], (255, 255, 255))
img = cv2.bitwise_and(img, mask)
cv2.imshow('Mask',mask)
bbox = cv2.boundingRect(points)
x, y, w, h = bbox
imgCrop = img[y:y + h, x:x + w]
imgCrop = cv2.resize(imgCrop, (0, 0), None, scale, scale)
return imgCrop
img = cv2.imread('1.png')
img = cv2.resize(img, (0, 0), None, 0.80, 0.80)
imgOriginal = img.copy()
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(imgOriginal)
for face in faces:
x1, y1 = face.left(), face.top()
x2, y2 = face.right(), face.bottom()
imgOriginal=cv2.rectangle(imgOriginal, (x1, y1), (x2, y2), (0, 255, 0), 2)
landmarks = predictor(imgGray, face)
myPoints = []
for n in range(68):
x = landmarks.part(n).x
y = landmarks.part(n).y
myPoints.append([x, y])
myPoints = np.array(myPoints)
imgLips = createBox(img, myPoints[48:61])
cv2.imshow('Lips', imgLips)
cv2.imshow("Originial", imgOriginal)
cv2.waitKey(0)
它的效果图是这样的:

对其中的createBox函数进行修改
cv2.imshow('Mask',img) 我们会得到下面的图,很成果的得到了我们想要的效果,在这里我主要是想要展示蒙版与位运算的关系,本人学过ps和pr,所以对于蒙版还是比较了解的,而在我初学时对于蒙版这个概念真的是闻所未闻,所以我在这里多提了一嘴。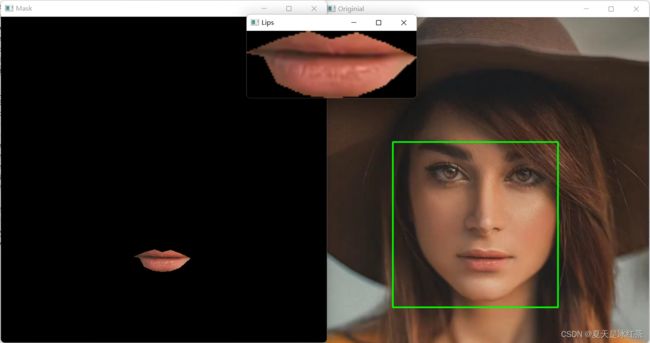
part4 为原图像上色
import cv2
import numpy as np
import dlib
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def createBox(img, points, scale=3, masked=False, cropped=True):
if masked:
mask = np.zeros_like(img)
mask = cv2.fillPoly(mask, [points], (255, 255, 255))
img = cv2.bitwise_and(img, mask)
# cv2.imshow('Mask',mask)
if cropped:
bbox = cv2.boundingRect(points)
x, y, w, h = bbox
imgCrop = img[y:y + h, x:x + w]
imgCrop = cv2.resize(imgCrop, (0, 0), None, scale, scale)
cv2.imwrite("Mask.jpg", imgCrop)
return imgCrop
else:
return mask
img = cv2.imread('1.png')
img = cv2.resize(img, (0, 0), None, 0.80, 0.80)
imgOriginal = img.copy()
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(imgOriginal)
for face in faces:
x1, y1 = face.left(), face.top()
x2, y2 = face.right(), face.bottom()
landmarks = predictor(imgGray, face)
myPoints = []
for n in range(68):
x = landmarks.part(n).x
y = landmarks.part(n).y
myPoints.append([x, y])
myPoints = np.array(myPoints)
maskLips = createBox(img, myPoints[48:61], masked=True, cropped=False)
imgColorLips = np.zeros_like(maskLips)
imgColorLips[:] = 153, 0, 158
imgColorLips = cv2.bitwise_and(maskLips, imgColorLips)
imgColorLips = cv2.GaussianBlur(imgColorLips, (7, 7), 10)
imgColorLips = cv2.addWeighted(imgOriginal, 1, imgColorLips, 0.4, 0)
cv2.imshow('Color', imgColorLips)
cv2.imshow('Lips', maskLips)
cv2.imshow("Originial", imgOriginal)
cv2.waitKey(0)我重点标记一下这些:
imgColorLips = cv2.bitwise_and(maskLips, imgColorLips) #用位运算将蒙版与纯颜色背景板结合起来
imgColorLips = cv2.GaussianBlur(imgColorLips, (7, 7), 10) #添加高斯模糊,不让图像变得生硬
imgColorLips = cv2.addWeighted(imgOriginal, 1, imgColorLips, 0.4, 0) #配置权重,使颜色与嘴唇更加融合详情请看注释,我们得到下面的效果图。
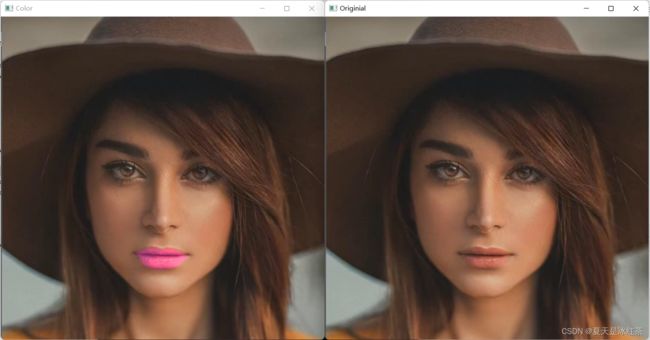
修改并添加上下面的代码
imgOriginalGray = cv2.cvtColor(imgOriginal, cv2.COLOR_BGR2GRAY)
imgOriginalGray = cv2.cvtColor(imgOriginalGray, cv2.COLOR_GRAY2BGR)
imgColorLips = cv2.addWeighted(imgOriginalGray, 1, imgColorLips, 0.4, 0)为了更好的观察嘴唇的上色,我们将原图转化为了灰度图像,又因为要对图像上色,所以我们需要三个通道,故将其转化为了拥有三个通道的灰色的图像。
再来看看它的效果:
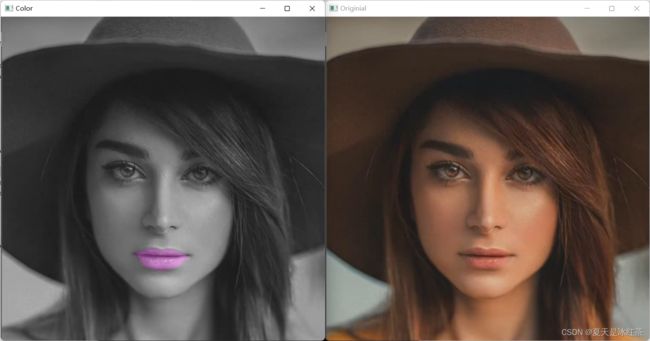
cool!!!效果非常的明显,更好的观察到我们的项目。
part5 添加轨迹栏实时修改颜色
那么这一步的完成,就是我最开始展示的代码,使用cv2.createTrackbar的函数时,要添加一个函数,可以直接pass。
那么经过上面的讲解,或许你对于上面的已经相当清楚了,我这里就不再细讲了。
5、项目资源
GitHub:Opencv-project-training/Opencv project training/10 Facial Landmarks and Face Filter at main · Auorui/Opencv-project-training · GitHub
6、项目总结
好像有点久没有更新了,最近在补数据分析,由于我要学完之后还要写博客,所以会稍稍显得有点慢,昨天刚刚下单买了西瓜书、南瓜书和李航的统计学习方法。说实话我虽然都有这些资源的电子版,可我看着不得劲,眼睛看着不舒服,还是更喜欢纸制版的感觉,希望我早点机器学习入门,我的高数都快忘完了,线代只能说还有印象,别的不说,我一定要加油啃下这些知识点。
希望你在本项目中玩得开心,否则我会在下一个项目中见到你!!!
