pytorch文本分类
“Deep Learning is more than adding layers”
“深度学习不仅仅是增加层次”
The objective of this blog is to develop a step by step text classifier by implementing convolutional neural networks. So, this blog is divided into the following sections:
该博客的目的是通过实现卷积神经网络来逐步开发文本分类器。 因此,此博客分为以下部分:
Introduction
介绍
Preprocessing
前处理
The model
该模型
Training
训练
Evaluation
评价
So, let’s get started!
所以,让我们开始吧!
介绍 (Introduction)
The text classification problem can be addressed from different approaches, for example, considering the frequency of occurrence of words in a given text with respect to the occurrence of these words in the complete corpus.
可以通过不同的方法来解决文本分类问题,例如,考虑到给定文本中单词出现的频率相对于完整语料库中这些单词的出现频率。
On the other hand, there exists other approaches where the text is modeled as a sequence of words or characters, this type of approach makes use mainly of models based on Recurrent Neural Network architectures.
另一方面,存在将文本建模为单词或字符序列的其他方法,这种方法主要利用基于递归神经网络体系结构的模型。
If you want to know more about text classification with LSTM recurrent neural networks, take a look at this blog: Text Classification with LSTMs in PyTorch
如果您想了解有关LSTM递归神经网络的文本分类的更多信息,请查看此博客: PyTorch中的LSTM文本分类。
However, there is another approach where the text is modeled as a distribution of words in a given space. This is achieved through the use of Convolutional Neural Networks (CNNs).
但是,还有另一种方法将文本建模为给定空间中单词的分布。 这是通过使用卷积神经网络(CNN)实现的。
So, we are going to start from the last mentioned approach, we are going to build a model to classify text considering the distribution in space of a set of words that make up the text using an architecture based on CNNs.
因此,我们将从最后提到的方法开始,我们将使用基于CNN的架构,考虑组成文本的一组单词在空间中的分布,构建一个模型来对文本进行分类。
Let’s start!
开始吧!
前处理 (Preprocessing)
The data used in this model was obtained from the Kaggle contest: Real or Not? NLP with Disaster Tweets
该模型中使用的数据是从Kaggle竞赛中获得的:真实还是非真实? NLP与灾难鸣叫
The first lines of the dataset look like Figure 1:
数据集的第一行如图1所示:

As we can see, it is necessary to create a preprocessing pipeline to load the text, clean it, tokenize it, padding it and split into train and test sets.
如我们所见,有必要创建一个预处理管道来加载文本,清理文本,标记化文本,填充文本并将其拆分为训练集和测试集。
Load text. Since the text we are going to work with is already in our repository, we only need to call it locally and remove some columns that will not be useful.
载入文字。 由于我们要使用的文本已经在我们的存储库中,因此我们只需要在本地调用它并删除一些无用的列即可。
def load_data(self):
# Reads the raw csv file and split into
# sentences (x) and target (y)
df = pd.read_csv(self.data)
df.drop(['id','keyword','location'], axis=1, inplace=True)
self.x_raw = df['text'].values
self.y = df['target'].valuesClean text. In this case, we will need to remove special symbols and numbers from the text. We are only going to work with lowercase words.
干净的文字。 在这种情况下,我们将需要从文本中删除特殊符号和数字。 我们将只使用小写单词。
def clean_text(self):
# Removes special symbols and just keep
# words in lower or upper form
self.x_raw = [x.lower() for x in self.x_raw]
self.x_raw = [re.sub(r'[^A-Za-z]+', ' ', x) for x in self.x_raw]Word tokenization. For tokenization, we are going to make use of the word_tokenize function from the nltk library (a very simple way to tokenize a sentence). After this, we will need to generate a dictionary with the “x” most frequent words in the dataset (this is in order to reduce the complexity of the problem). Therefore, as you can see in line 3 of code 3, tokenization is applied. In line 14 the most common “x” words are selected and in line 16 the dictionary of words is built (as you can see, the dictionary begins with the index 1, this is because we are reserving the index 0 to apply the padding).
单词标记化。 对于符号化,我们要利用word_tokenize功能从NLTK库(一个非常简单的方式来标记句子)。 此后,我们将需要用数据集中最频繁出现的单词“ x ”生成字典(这是为了降低问题的复杂性)。 因此,正如您在代码3的第3行中看到的那样,将应用标记化。 在第14行中,选择了最常见的“ x ”单词,在第16行中,构建了单词词典(如您所见,该词典以索引1开头,这是因为我们保留了索引0以应用填充) 。
def text_tokenization(self):
# Tokenizes each sentence by implementing the nltk tool
self.x_raw = [word_tokenize(x) for x in self.x_raw]
def build_vocabulary(self):
# Builds the vocabulary and keeps the "x" most frequent words
self.vocabulary = dict()
fdist = nltk.FreqDist()
for sentence in self.x_raw:
for word in sentence:
fdist[word] += 1
common_words = fdist.most_common(self.num_words)
for idx, word in enumerate(common_words):
self.vocabulary[word[0]] = (idx+1)Until now each tweet is already tokenized, however we need to transform each word token into a numeric format, therefore we will use the dictionary generated in Code 3 to transform each word into its representation based on indexes.
到目前为止,每个推特都已被标记化,但是我们需要将每个词标记转换为数字格式,因此,我们将使用代码3中生成的字典将每个词转换为基于索引的表示形式。
def word_to_idx(self):
# By using the dictionary (vocabulary), it is transformed
# each token into its index based representation
self.x_tokenized = list()
for sentence in self.x_raw:
temp_sentence = list()
for word in sentence:
if word in self.vocabulary.keys():
temp_sentence.append(self.vocabulary[word])
self.x_tokenized.append(temp_sentence)Padding. As you can imagine, not all tweets are the same length, however it is important that each one has the same number of words. That is why we introduced padding. Padding is implemented in order to standardize the length of each tweet. In this case, the value that we will use for padding will be the number zero (the index that we reserve when we build the vocabulary dictionary).
填充。 您可以想象,并非所有的推文都具有相同的长度,但是重要的是每个推文都具有相同的单词数。 这就是我们引入填充的原因。 实施填充是为了标准化每个推文的长度。 在这种情况下,我们用于填充的值将为数字零(我们在构建词汇词典时保留的索引)。
def padding_sentences(self):
# Each sentence which does not fulfill the required len
# it's padded with the index 0
pad_idx = 0
self.x_padded = list()
for sentence in self.x_tokenized:
while len(sentence) < self.seq_len:
sentence.insert(len(sentence), pad_idx)
self.x_padded.append(sentence)
self.x_padded = np.array(self.x_padded)Split intro train and test. The last step in this preprocessing pipeline is to divide the data into training and testing. For this we will use the function provided by scikit learn.
拆分介绍培训和测试。 该预处理流程的最后一步是将数据分为训练和测试。 为此,我们将使用scikit learning提供的功能。
def split_data(self):
self.x_train, self.x_test, self.y_train, self.y_test = train_test_split(self.x_padded, self.y, test_size=0.25, random_state=42)The complete preprocessing class looks like:
完整的预处理类如下所示:
import re
import nltk
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from nltk.tokenize import word_tokenize
class Preprocessing:
def __init__(self, num_words, seq_len):
self.data = 'data/tweets.csv'
self.num_words = num_words
self.seq_len = seq_len
self.vocabulary = None
self.x_tokenized = None
self.x_padded = None
self.x_raw = None
self.y = None
self.x_train = None
self.x_test = None
self.y_train = None
self.y_test = None
def load_data(self):
# Reads the raw csv file and split into
# sentences (x) and target (y)
df = pd.read_csv(self.data)
df.drop(['id','keyword','location'], axis=1, inplace=True)
self.x_raw = df['text'].values
self.y = df['target'].values
def clean_text(self):
# Removes special symbols and just keep
# words in lower or upper form
self.x_raw = [x.lower() for x in self.x_raw]
self.x_raw = [re.sub(r'[^A-Za-z]+', ' ', x) for x in self.x_raw]
def text_tokenization(self):
# Tokenizes each sentence by implementing the nltk tool
self.x_raw = [word_tokenize(x) for x in self.x_raw]
def build_vocabulary(self):
# Builds the vocabulary and keeps the "x" most frequent word
self.vocabulary = dict()
fdist = nltk.FreqDist()
for sentence in self.x_raw:
for word in sentence:
fdist[word] += 1
common_words = fdist.most_common(self.num_words)
for idx, word in enumerate(common_words):
self.vocabulary[word[0]] = (idx+1)
def word_to_idx(self):
# By using the dictionary (vocabulary), it is transformed
# each token into its index based representatio
self.x_tokenized = list()
for sentence in self.x_raw:
temp_sentence = list()
for word in sentence:
if word in self.vocabulary.keys():
temp_sentence.append(self.vocabulary[word])
self.x_tokenized.append(temp_sentence)
def padding_sentences(self):
# Each sentence which does not fulfill the required le
# it's padded with the index 0
pad_idx = 0
self.x_padded = list()
for sentence in self.x_tokenized:
while len(sentence) < self.seq_len:
sentence.insert(len(sentence), pad_idx)
self.x_padded.append(sentence)
self.x_padded = np.array(self.x_padded)
def split_data(self):
self.x_train, self.x_test, self.y_train, self.y_test = train_test_split(self.x_padded, self.y, test_size=0.25, random_state=42)Great, so far we have done all the preprocessing and we already have our training and testing sets, it’s time to see the model!
太好了,到目前为止,我们已经完成了所有预处理,并且已经有了我们的培训和测试集,现在该看模型了!
模型 (Model)
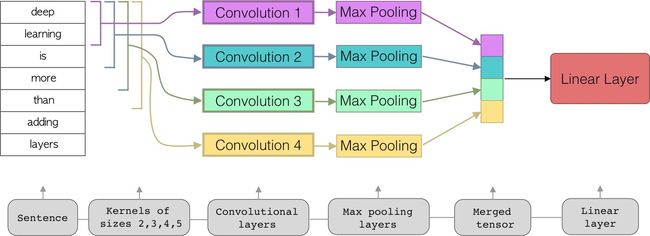
The implemented model will use n-grams of words, that is, different kernel sizes will be applied to the same sentence (referring to a composition based on n-grams). Then, each of the outputs of these kernels will be reduced using the max pooling function. Finally, each of these outputs will be concatenated in a single tensor to be introduced to a linear layer which will be filtered by an activation function to obtain the final result.
实现的模型将使用n-gram的单词,也就是说,将不同的内核大小应用于相同的句子(指的是基于n-gram的组合)。 然后,将使用max pooling函数减少这些内核的每个输出。 最后,这些输出中的每一个都将在单个张量中串联起来,以引入到线性层,该线性层将通过激活函数进行滤波以获得最终结果。
Here you have the complete implementation: https://github.com/FernandoLpz/Text-Classification-CNN-PyTorch
在这里,您具有完整的实现: https : //github.com/FernandoLpz/Text-Classification-CNN-PyTorch
As we can see, the convolutional layers are not stacked. Each convolutional layer is defined by a specific kernel size, this size is what defines the “n-gram” in question. Also, each output of each convolution is reduced using max pooling. Finally each tensor is concatenated to form a single tensor that will be introduced to the linear layer.
如我们所见,卷积层没有堆叠。 每个卷积层都由特定的内核大小定义,该大小定义了所讨论的“ n-gram”。 同样,使用最大池化减少每个卷积的每个输出。 最后,将每个张量级联以形成单个张量,该张量将引入线性层。
Now let’s see how we do all this in code using the PyTorch framework. First we need to create the constructor of our neural network, for this we are going to define some important parameters as well as the convolutional, max pooling and linear layers.
现在,让我们看看如何使用PyTorch框架在代码中完成所有这些操作。 首先,我们需要创建神经网络的构造函数,为此,我们将定义一些重要的参数以及卷积,最大池化和线性层。
class TextClassifier(nn.ModuleList):
def __init__(self, params):
super(TextClassifier, self).__init__()
# Parameters regarding text preprocessing
self.seq_len = params.seq_len
self.num_words = params.num_words
self.embedding_size = params.embedding_size
# Dropout definition
self.dropout = nn.Dropout(0.25)
# CNN parameters definition
# Kernel sizes
self.kernel_1 = 2
self.kernel_2 = 3
self.kernel_3 = 4
self.kernel_4 = 5
# Output size for each convolution
self.out_size = params.out_size
# Number of strides for each convolution
self.stride = params.stride
# Embedding layer definition
self.embedding = nn.Embedding(self.num_words + 1, self.embedding_size, padding_idx=0)
# Convolution layers definition
self.conv_1 = nn.Conv1d(self.seq_len, self.out_size, self.kernel_1, self.stride)
self.conv_2 = nn.Conv1d(self.seq_len, self.out_size, self.kernel_2, self.stride)
self.conv_3 = nn.Conv1d(self.seq_len, self.out_size, self.kernel_3, self.stride)
self.conv_4 = nn.Conv1d(self.seq_len, self.out_size, self.kernel_4, self.stride)
# Max pooling layers definition
self.pool_1 = nn.MaxPool1d(self.kernel_1, self.stride)
self.pool_2 = nn.MaxPool1d(self.kernel_2, self.stride)
self.pool_3 = nn.MaxPool1d(self.kernel_3, self.stride)
self.pool_4 = nn.MaxPool1d(self.kernel_4, self.stride)
# Fully connected layer definition
self.fc = nn.Linear(self.in_features_fc(), 1)From lines 16 to 19, we are defining the different kernels for each convolution (remember that the kernel size acts as the size of the n-gram in this case).
从第16到19行,我们为每个卷积定义了不同的内核(请记住,在这种情况下,内核大小充当n-gram的大小)。
Line 22 refers to the definition of the number of output channels of the convolution for each layer. Line 24 refers to the number of jumps that will be considered when sliding the window (the kernel).
第22行是对每一层卷积输出通道数的定义。 第24行是在滑动窗口(内核)时要考虑的跳转数。
In line 27 the embedding layer is defined. As we can see the number of input words (the size of the vocabulary), contains a “+1” this because we are considering the index that refers to the padding, in this case it is the index 0.
在第27行中,定义了嵌入层。 如我们所见,输入单词的数量(词汇的大小)包含一个“ +1 ”,这是因为我们正在考虑引用填充的索引,在本例中是索引0。
From lines 30 to 33 we define each convolutional layer. Likewise, from lines 36 to 39 we define each max pooling layer.
从第30到33行,我们定义每个卷积层。 同样,从第36行到第39行,我们定义每个最大池化层。
Finally on line 42 we define the linear layer. It is very important to note that the number of input elements for this layer is defined by a function. This is because by applying convolution and max pooling (under different kernel sizes), the size of the output tensors is modified. Likewise such output tensors will be concatenated and reduced to a 1-dimensional tensor, (flattening). That is why we implement a function to calculate such input size for the linear layer.
最后,在第42行,我们定义了线性层。 非常重要的一点是,此层的输入元素的数量由函数定义。 这是因为通过应用卷积和最大池化(在不同的内核大小下),可以修改输出张量的大小。 同样,此类输出张量将被串联并简化为一维张量(展平)。 这就是为什么我们实现一个函数来计算线性层的这种输入大小的原因。
The size of the output tensor for each convolution and max pooling layers is defined by the following function:
每个卷积和最大池化层的输出张量的大小由以下函数定义:

So the function to calculate the input size for the linear layer is determined by:
因此,用于计算线性图层的输入大小的函数由以下方式确定:
def in_features_fc(self):
'''Calculates the number of output features after Convolution + Max pooling
Convolved_Features = ((embedding_size + (2 * padding) - dilation * (kernel - 1) - 1) / stride) + 1
Pooled_Features = ((embedding_size + (2 * padding) - dilation * (kernel - 1) - 1) / stride) + 1
source: https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
'''
# Calcualte size of convolved/pooled features for convolution_1/max_pooling_1 features
out_conv_1 = ((self.embedding_size - 1 * (self.kernel_1 - 1) - 1) / self.stride) + 1
out_conv_1 = math.floor(out_conv_1)
out_pool_1 = ((out_conv_1 - 1 * (self.kernel_1 - 1) - 1) / self.stride) + 1
out_pool_1 = math.floor(out_pool_1)
# Calcualte size of convolved/pooled features for convolution_2/max_pooling_2 features
out_conv_2 = ((self.embedding_size - 1 * (self.kernel_2 - 1) - 1) / self.stride) + 1
out_conv_2 = math.floor(out_conv_2)
out_pool_2 = ((out_conv_2 - 1 * (self.kernel_2 - 1) - 1) / self.stride) + 1
out_pool_2 = math.floor(out_pool_2)
# Calcualte size of convolved/pooled features for convolution_3/max_pooling_3 features
out_conv_3 = ((self.embedding_size - 1 * (self.kernel_3 - 1) - 1) / self.stride) + 1
out_conv_3 = math.floor(out_conv_3)
out_pool_3 = ((out_conv_3 - 1 * (self.kernel_3 - 1) - 1) / self.stride) + 1
out_pool_3 = math.floor(out_pool_3)
# Calcualte size of convolved/pooled features for convolution_4/max_pooling_4 features
out_conv_4 = ((self.embedding_size - 1 * (self.kernel_4 - 1) - 1) / self.stride) + 1
out_conv_4 = math.floor(out_conv_4)
out_pool_4 = ((out_conv_4 - 1 * (self.kernel_4 - 1) - 1) / self.stride) + 1
out_pool_4 = math.floor(out_pool_4)
# Returns "flattened" vector (input for fully connected layer)
return (out_pool_1 + out_pool_2 + out_pool_3 + out_pool_4) * self.out_sizeOk, so far we have already defined the constructor. It’s time to move on to the forward function, let’s go for it!
好的,到目前为止,我们已经定义了构造函数。 现在该继续前进功能了,让我们继续吧!
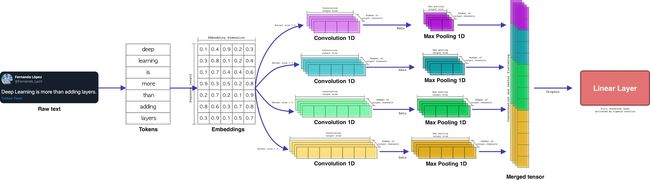
The forward function will take the vector of tokenized words and pass them through the embedding layer. Subsequently, each embedded sentence will be passed through each of the convolutional and max pooling layers, finally, the resulting vectors will be concatenated and reduced to be introduced to the linear layer.
forward函数将获取标记词的向量,并将其传递通过嵌入层。 随后,每个嵌入的句子将通过卷积和最大池化层中的每个,最后,结果向量将被级联并缩小以引入线性层。
def forward(self, x):
# Sequence of tokes is filterd through an embedding layer
x = self.embedding(x)
# Convolution layer 1 is applied
x1 = self.conv_1(x)
x1 = torch.relu(x1)
x1 = self.pool_1(x1)
# Convolution layer 2 is applied
x2 = self.conv_2(x)
x2 = torch.relu((x2))
x2 = self.pool_2(x2)
# Convolution layer 3 is applied
x3 = self.conv_3(x)
x3 = torch.relu(x3)
x3 = self.pool_3(x3)
# Convolution layer 4 is applied
x4 = self.conv_4(x)
x4 = torch.relu(x4)
x4 = self.pool_4(x4)
# The output of each convolutional layer is concatenated into a unique vector
union = torch.cat((x1, x2, x3, x4), 2)
union = union.reshape(union.size(0), -1)
# The "flattened" vector is passed through a fully connected layer
out = self.fc(union)
# Dropout is applied
out = self.dropout(out)
# Activation function is applied
out = torch.sigmoid(out)
return out.squeeze()In line 4 the input vector is passed through the embedding layer. In lines 7, 12, 17 and 22 the convolution operation (with different kernel sizes) is applied to the embedded sequence. On line 27 each output vector is concatenated and on line 28 this vector is reduced to one dimension (flattening). Subsequently, the flattened vector is passed through a linear layer whose activation function is sigmoid.
在第4行中,输入向量穿过嵌入层。 在第7、12、17和22行中,将卷积运算(具有不同的内核大小)应用于嵌入序列。 在第27行,将每个输出向量连接起来,在第28行,将该向量缩小为一维(展平)。 随后,平整后的矢量通过激活函数为S型的线性层。
So the complete architecture will look like:
因此,完整的架构将如下所示:
Great, we already saw how to define the architecture of the neural network as well as the forward function, it is time to see the training function, let’s go for it!
太好了,我们已经了解了如何定义神经网络的结构以及正向函数,是时候来看一下训练函数了,让我们开始吧!
训练 (Training)
As we saw in the preprocessing phase, the training and test data are ready to be implemented. However, we need to transform them to a torch-based data type as well as create the batch generator. For this we will make use of the Dataset and DataLoader modules that the PyTorch framework provides, this is how the implementation will look like:
正如我们在预处理阶段所看到的,训练和测试数据已准备好实施。 但是,我们需要将它们转换为基于火炬的数据类型,并创建批处理生成器。 为此,我们将利用PyTorch框架提供的Dataset和DataLoader模块,这是实现的样子:
from torch.utils.data import Dataset, DataLoader
class DatasetMaper(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]To make use of the class, we only need to instantiate and then initialize the data loader.
要使用该类,我们只需要实例化然后初始化数据加载器。
# Initialize dataset maper
train = DatasetMaper(data['x_train'], data['y_train'])
test = DatasetMaper(data['x_test'], data['y_test'])
# Initialize loaders
loader_train = DataLoader(train, batch_size=params.batch_size)
loader_test = DataLoader(test, batch_size=params.batch_size)For the training phase, we have to define the data loader (we did this in the previous step) and define the optimizer (in this case we are using the RMSprop optimizer). Once everything is ready, we can start with the training loop.
在训练阶段,我们必须定义数据加载器(在上一步中已完成)并定义优化器(在这种情况下,我们正在使用RMSprop优化器)。 一旦一切准备就绪,我们就可以从训练循环开始。
def train(model, data, params):
# Initialize dataset maper
train = DatasetMaper(data['x_train'], data['y_train'])
test = DatasetMaper(data['x_test'], data['y_test'])
# Initialize loaders
loader_train = DataLoader(train, batch_size=params.batch_size)
loader_test = DataLoader(test, batch_size=params.batch_size)
# Define optimizer
optimizer = optim.RMSprop(model.parameters(), lr=params.learning_rate)
# Starts training phase
for epoch in range(params.epochs):
# Set model in training model
model.train()
predictions = []
# Starts batch training
for x_batch, y_batch in loader_train:
y_batch = y_batch.type(torch.FloatTensor)
# Feed the model
y_pred = model(x_batch)
# Loss calculation
loss = F.binary_cross_entropy(y_pred, y_batch)
# Clean gradientes
optimizer.zero_grad()
# Gradients calculation
loss.backward()
# Gradients update
optimizer.step()
# Save predictions
predictions += list(y_pred.detach().numpy())
# Evaluation phase
test_predictions = Run.evaluation(model, loader_test)
# Metrics calculation
train_accuary = Run.calculate_accuray(data['y_train'], predictions)
test_accuracy = Run.calculate_accuray(data['y_test'], test_predictions)
print("Epoch: %d, loss: %.5f, Train accuracy: %.5f, Test accuracy: %.5f" % (epoch+1, loss.item(), train_accuary, test_accuracy))In line 15 we are iterating for each epoch. In line 20 we are iterating for each batch using the data loader. In line 17 the model is set in training mode (this means that the gradients will be updated). In line 25 the model is fed. In line 28 the error is calculated. In line 29 the variables that host the gradients are cleaned. On line 34 the gradients are calculated. On line 37 the parameters are updated.
在第15行中,我们为每个时期进行迭代。 在第20行中,我们使用数据加载器对每个批次进行迭代。 在第17行中,将模型设置为训练模式(这意味着将更新渐变)。 在第25行中输入模型。 在第28行中计算了误差。 在第29行中,将清理托管渐变的变量。 在线34上计算梯度。 在第37行,参数被更新。
Finally the predictions are saved and the evaluation function is called to obtain the accuracy for both the training and test data. So, let’s see this in the next section!
最后,保存预测并调用评估函数以获得训练数据和测试数据的准确性。 因此,让我们在下一部分中看到它!
评价 (Evaluation)
Great, we are finally in the evaluation section. Let’s see how this is.
太好了,我们终于可以进入评估部分。 让我们看看这是怎么回事。
This time we are going to use accuracy as a metric to measure the performance of the model. Although there are predefined functions to calculate it directly, this time we are going to do it manually, that is, calculating the true positives as well as the false positives.
这次,我们将使用准确性作为衡量模型性能的指标。 尽管有预定义的函数可以直接计算它,但是这次我们将手动进行计算,即计算真实的肯定和错误的肯定。
def calculate_accuray(grand_truth, predictions):
true_positives = 0
true_negatives = 0
# Gets frequency of true positives and true negatives
# The threshold is 0.5
for true, pred in zip(grand_truth, predictions):
if (pred >= 0.5) and (true == 1):
true_positives += 1
elif (pred < 0.5) and (true == 0):
true_negatives += 1
else:
pass
# Return accuracy
return (true_positives+true_negatives) / len(grand_truth)In this case, we are defining 0.5 as the threshold to determine if the value of the resulting class is positive or negative.
在这种情况下,我们将阈值定义为0.5,以确定结果类的值是正还是负。
Congratulations! We have reached the end of this tutorial blog. The code is open for any suggestions and/or comments. Feel free to fork or clone!
恭喜你! 我们已经到了本教程博客的结尾。 该代码对任何建议和/或评论开放。 随意分叉或克隆!
Here you have the complete implementation: https://github.com/FernandoLpz/Text-Classification-CNN-PyTorch
在这里,您具有完整的实现: https : //github.com/FernandoLpz/Text-Classification-CNN-PyTorch
结论 (Conclusion)
In this tutorial blog we learned how to generate a text classification model using a convolution-based neural network architecture implementing the PyTorch framework.
在本教程博客中,我们学习了如何使用实现PyTorch框架的基于卷积的神经网络体系结构来生成文本分类模型。
翻译自: https://towardsdatascience.com/text-classification-with-cnns-in-pytorch-1113df31e79f
pytorch文本分类