2022年大数据技能大赛训练
任务书3
赛题说明
- 竞赛内容分布
- 竞赛时长
| 任务一:Spark 组件部署管理(Standalone 模式) |
15% |
| 任务二:数据采集 |
20% |
| 任务三:数据清洗与分析 |
30% |
| 任务四:数据可视化 |
20% |
| 任务五:综合分析 |
10% |
| 团队分工明确合理、操作规范、文明竞赛 |
5% |
竞赛时长为4个小时。
- 竞赛注意事项
1.竞赛所需的硬件、软件和辅助工具由组委会统一布置,选手不得私自携带任何软件、移动存储、辅助工具、移动通信等进入赛场;
2.请根据大赛所提供的比赛环境,检查所列的软件及工具组件清单是否齐全,计算机设备是否能正常使用;
3.比赛完成后,比赛设备、软件和赛题请保留在座位上,禁止将比赛所用的所有物品(包括试卷和草纸)带离赛场;
4.裁判以各参赛队提交的竞赛结果文档为主要评分依据。所有提交的文档必须按照赛题所规定的命名规则命名,不得以任何形式体现参赛院校、赛位号等信息;
5.本次比赛采用统一网络环境比赛,请不要随意更改客户端的网络地址信息,对于更改客户端信息造成的问题,由参赛选手自行承担比赛损失;
6.请不要恶意破坏竞赛环境,对于恶意破坏竞赛环境的参赛者,组委会根据其行为予以处罚直至取消比赛资格;
7.比赛中出现各种问题及时向监考裁判举手示意,不要影响其他参赛队比赛。
- 竞赛结果文件的提交
按照题目要求,提交符合模板的WORD文件以及对应的PDF文件(利用Office Word另存为pdf文件方式生成pdf文件)和代码文件。
- 任务说明
请按照下面步骤完成本次技术展示任务,并提交技术报告。
模块一:环境搭建
任务一:Hadoop 组件部署管理(集群模式)
说明:
本环节需要使用 root 用户完成相关配置,具体部署要求如下:
1、 在 master节点(/opt/package) 解 压 java、hadoop 安装包 ,将解压后的安装文件移动到各个节点“/usr/local/”路径下并更名为jdk ,将全部命令复制并粘贴;
2、 设置 java、hadoop 环境变量,并使环境变量对所有用户生效,将变量配置内容复制粘贴;
3、完善其他配置,并启动hadoop集群,将所有配置内容以及命令复制粘贴
任务二:Spark 组件部署管理(Standalone 模式)
说明:
本环节需要使用 root 用户完成相关配置,具体部署要求如下:
1、 在 master节点解压 scala 安装包 ,将解压后的安装文件移动到“/usr/local/”路径下并更名为 scala,将全部命令复制并粘贴;
2、 设置 scala 环境变量,并使环境变量只对 root 用户生效,将变量配置内容复制粘贴;
3、 在 master 节 点 解 压 Spark 安装包 ,将解压后的安装文件移动 到“usr/local/”路径下,更名为 spark,并配置slaves文件,将命令与修改内容复制粘贴;
4、 修改 spark-env.sh.template 为 spark-env.sh 并在其中配置 Spark 的 master 节点主机名、端口、worker 结点的核数、内存,将修改的配置内容复制粘贴;
5、 完善其他配置并启动 Spark(Standalone 模式)集群,启动 Spark Shell 连接 集群,将连接结果截图(截图需包含连接命令)粘贴。
任务三:Sqoop的安装与部署
- 在master节点解压sqoop安装包,将解压后的安装文件移动到“/usr/local/”路径下并更名为 sqoop,将全部命令复制并粘贴;
- 完善sqoop的配置文件,将所有命令以及配置内容复制粘贴
- 设置sqoop的环境变量,将mysql驱动解压并移动到相应位置,并连接MySQL数据库(密码为Passwd1!)显示所有数据库
任务四:Hive的安装与部署
- 在master节点解压Hive安装包,将解压后的安装文件移动到“/usr/local/”路径并更名为hive,将全部命令复制并粘贴;
- 完善hive配置文件(配置数据库),将hive-sitem.xml文件的内容截图并粘贴
- 启动hive,新建一个数据库(stu)和数据表(student, 字段为id int, name char),在$HIVE_HOME下创建一个数据文件(.dat)写入下列数据,并导入hive数据库中,最后检查写入是否成功。
student.dat
1 Kevin
2 Kyrie
3 Harden
任务五:Flume的安装与部署
- 在master节点解压Flume安装包,将解压后的安装文件移动到“/usr/local/”路径并更名为flume,将全部命令复制粘贴
- 完善其他配置,启动flume,将过程命令和结果复制粘贴
模块二:数据采集与数据预处理(20分)
请使用网页分析、网络爬虫等相关技术,完成网页分析、数据爬取、数据存储等任务。(请注意:任务二爬取的数据将会用于任务三和任务四中)
具体要求如下:
- 从https://newhouse.fang.com/house/s/网站中爬取北京房源信息,每个信息包括:城市、区、楼盘名称、价格(元/平)、地址、评论数、楼盘评级、项目户型、交通配套、教育配套、生活配套。保存为csv格式。将代码复制粘贴,
items.py
import scrapy
# 城市、区、楼盘名称、价格(元/平)、地址、评论数、楼盘评级、项目户型、交通配套、教育配套、生活配套
# city,name,place,price,comment_num,open,score,house,transport,edu,live
class FangtianxiaItem(scrapy.Item):
# city = scrapy.Field()
place = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
address = scrapy.Field()
comment_num = scrapy.Field()
score = scrapy.Field()
house = scrapy.Field()
transport = scrapy.Field()
edu = scrapy.Field()
live = scrapy.Field()Spider
import scrapy
from ..items import FangtianxiaItem
class HouseSpiderSpider(scrapy.Spider):
name = 'house_spider'
allowed_domains = ['newhouse.fang.com']
start_urls = [f'https://newhouse.fang.com/house/s/b9{page}/'for page in range(1, 11)]
# 城市、区、楼盘名称、价格(元/平)、地址、评论数、楼盘评级、项目户型、交通配套、教育配套、生活配套
# city,place,name,price,address,comment,grade,type,traffic,edu,live
# name,place,price,comment_num,open,score,house,transport,edu,live
def parse(self, response):
li = response.css('#newhouse_loupan_list').xpath('./ul/li')
for l in li:
item = FangtianxiaItem()
href = l.xpath('.//div[@class="nlcd_name"]/a/@href').extract_first()
# item['city'] = response.xpath('.//ul[@class="tf f12"]/li[2]/a/text()').extract_first().split("楼盘")[0]
item['place'] = l.xpath('.//div[@class="address"]/a/span/text()').extract_first().strip().split(']')[0][1:]
item['address'] = l.xpath('.//div[@class="address"]/a/text()[2]').extract_first().strip()
item['name'] = l.xpath('.//div[@class="nlcd_name"]/a/text()').extract_first().strip()
em = l.xpath('.//div[@class="nhouse_price"]/em/text()').extract_first('') #单位 (万元/套起,元/㎡起)
if '套' in em:
item['price'] = ''
else:
item['price'] = l.xpath('.//div[@class="nhouse_price"]/span/text()').extract_first()
item['comment_num'] = l.xpath('.//span[@class="value_num"]/text()').extract_first().split("条")[0][1:]
print(href)
yield scrapy.Request(response.urljoin(href), callback=self.new_parse, meta={'item': item})
def new_parse(self, response):
item = response.meta['item']
item['score'] = response.xpath('.//div[@class="num_bg"]/h3/text()').extract_first()
item['house'] = response.css('.report_num_item h4::text').extract()[0]
item['transport'] = response.css('.report_num_item h4::text').extract()[1]
item['edu'] = response.css('.report_num_item h4::text').extract()[2]
item['live'] = response.css('.report_num_item h4::text').extract()[3]
yield item
pipelines.py
class FangtianxiaPipeline:
def process_item(self, item, spider):
if '无' in item['house']:
item['house'] = ''
return item- 展示csv表格的前十五行
- 对数据进行预处理,丢弃缺失值,将字段的属性统一,将代码复制粘贴
import pandas as pd
df = pd.read_csv('./house.csv')
df = df.drop(["open"], axis=1)
df = df.drop(["address"], axis=1)
df = df.dropna()
df.to_csv('./beijing.csv')- 展示表格的前十五行
模块三:数据清洗与分析(30分)
- 对爬取数据进行清洗保留城市、区、楼盘名称、价格(元/平)、评论数、楼盘评级
- 分析得出上海房价信息中,楼盘评级大于9分的楼盘名称以及区、,截图并提交;
- 分析得出上海房价信息中,各个区的楼盘个数以及均价,截图并提交;
- 合并北京上海房价数据信息,展示前十五行,复制并粘贴代码;
- 分析得出北京上海房价信息中,楼盘评级大于9分的楼盘名称、城市以及区,截图并提交
- 分析得出北京上海房价信息中,各个区的楼盘个数以及均价,截图并提交
- 分析得出北京上海房价信息中,上海北京楼盘均价最高的前十名,截图并提交
- 分析得出北京上海房价信息中,上海北京楼盘评论数的前十名,截图并提交
- 分析得出北京上海房价信息中,上海北京的楼盘均价,截图并提交
- 分析得出北京上海房价信息中,上海北京的评论总和,截图并提交
- 将按区进行划分,上海北京各个区的房价信息, 根据评论总和(分析得到)降序、楼盘均价(分析得到)、楼盘个数(分析得到);将得到的前十五的数据信息写入MySQL数据库,表名为jinghu
模块四:数据可视化(20分)
为更好地帮助分析人员理解数据,需要从数据库中提取数据、对数据进行统计分析、并对数据分析结果用进行可视化呈现,具体包括以下四个子任务:
Python的flask及获取数据库数据代码:
from flask import Flask, render_template
import pymysql
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route("/")
def filename(filename):
return render_template(filename,place=place,count=count,price=price,comment_num=comment_num,data=data,
jh_place=jh_place,jh_price=jh_price,jh_score=jh_score,jh_count=jh_count)
def get_sql():
db = pymysql.connect(host='192.168.31.104',user='root',password='Passwd1!',port=3306,db='spark')
cursor = db.cursor()
sql = 'select * from shanghai'
cursor.execute(sql)
datas = cursor.fetchall()
data = []
for i in datas:
dic={}
dic['name'] = i[0]
dic['value'] = i[4]
data.append(dic)
return datas,data
def jh_sql():
db = pymysql.connect(host='192.168.31.104',user='root',password='Passwd1!',port=3306,db='spark')
cursor = db.cursor()
sql = 'select * from jinghu'
cursor.execute(sql)
jh_data = cursor.fetchall()
return jh_data
def get_data(datas):
place = [i[0]for i in datas]
price = [round(i[1]/10000,2)for i in datas]
comment_num = [round(i[2],2)for i in datas]
score = [i[3]for i in datas]
count = [i[4]for i in datas]
return place,count,price,comment_num
def get_jh(jh_data):
jh_place = [i[0]for i in jh_data]
jh_price = [round(i[1]/10000,2)for i in jh_data]
jh_score = [round(i[3],2)for i in jh_data]
jh_count = [i[4]for i in jh_data]
return jh_place,jh_price,jh_score,jh_count
if __name__=='__main__':
datas,data = get_sql()
jh_data = jh_sql()
jh_place,jh_price,jh_score,jh_count = get_jh(jh_data)
print(jh_place)
place,count,price,comment_num = get_data(datas)
app.run(debug=True) 
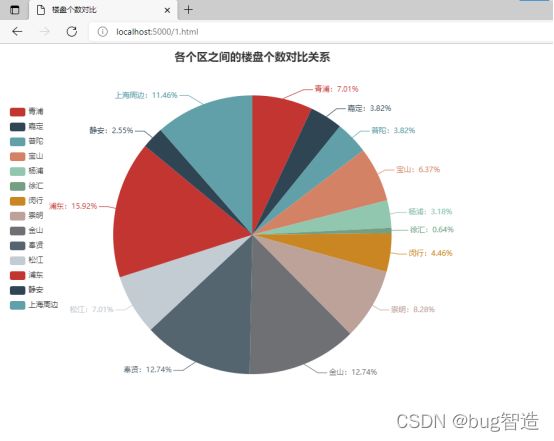
- 选用适当的图形表达描述MySQL数据库中shanghai表中各个区之间的楼盘个数对比关系。(5分)
要求:图形表达准确,外观整洁大方,能完整的表达数据的含义。
代码:
楼盘个数对比
图表展示:
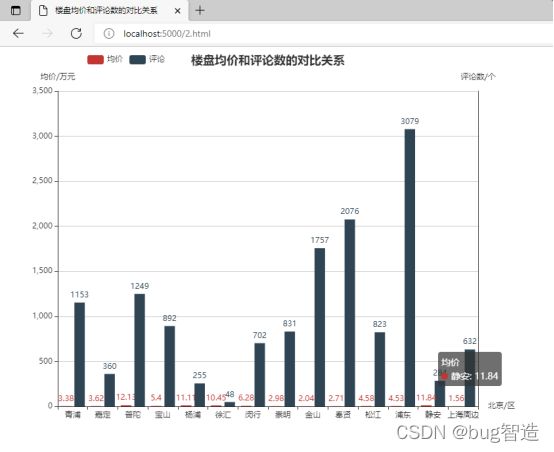
- 选用适当的图形表达描述MySQL数据库中shanghai表中各个区楼盘均价和评论数的对比关系。(4分)
要求:图形表达准确,外观整洁大方,能完整的表达数据的含义。
代码:
楼盘均价和评论数的对比关系
运行结果即可视化展示:
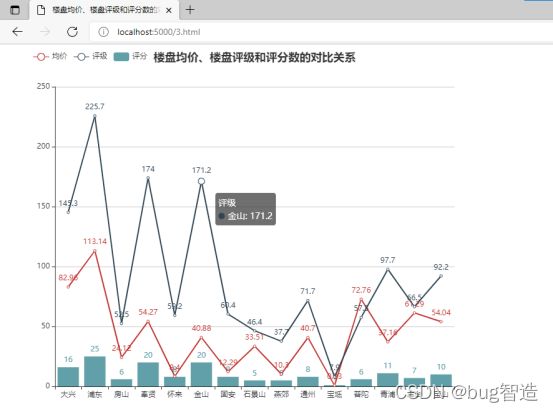
- 选用适当的图形表达描述jinghu数据表中,北京上海各个区的楼盘均价、楼盘评级和评分数的对比关系。(4分)
要求:图形表达准确,外观整洁大方,能完整的表达数据的含义。
代码:
楼盘均价、楼盘评级和评分数的对比关系
运行结果即展示图表如下:
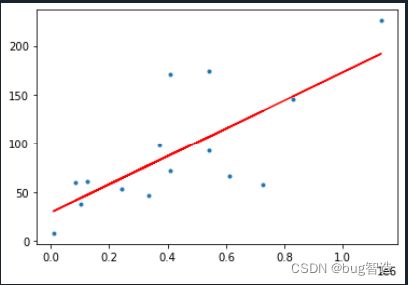
- 针对jinghu数据集中,运用线性回归,分析楼盘评级和楼盘均价之间的关系,并给出线性回归的直线图。(7分)
要求:图形表达准确,外观整洁大方,能完整的表达数据的含义。
代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Jan 6 03:24:35 2022
@author: admin
"""
from sklearn.linear_model import LinearRegression
import pymysql
import numpy as np
from matplotlib import pyplot as plt
db = pymysql.connect(host='192.168.31.104', user='root', password='Passwd1!', db='spark')
cursor = db.cursor()
sql = "select * from jinghu"
cursor.execute(sql)
datas = cursor.fetchall()
data = np.array(datas)
x_data = data[:, 1]
y_data = data[:, 3]
x_data = x_data.astype(np.float32)[:, np.newaxis]
y_data = y_data.astype(np.float32)[:, np.newaxis]
model = LinearRegression()
model.fit(x_data, y_data)
pre = model.predict(x_data)
plt.plot(x_data, y_data, ".")
plt.plot(x_data, model.predict(x_data), 'r')
plt.show()运行即可视化图表展示如下: