Hive DDL操作出现卡住现象源码分析与解决方法
最近遇到对Hive进行alter table时卡住无后续响应的问题,如下图所示:
![]()
即使重启Hive Metastore也依然无法解决这个问题,但是其他表的ddl操作都是正常的,只有这张表不行,经过排查后基本知道了原因所在,以及可以解决的办法。
一、相关机制和源码
1.1、如何维护锁信息
Hive2之后引入了一张新的MySQL元数据表叫hive.hive_locks,如下图所示:
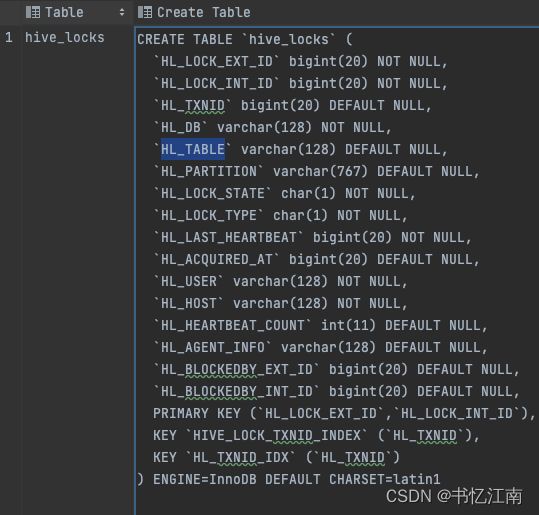
顾名思义,这张表的作用是存储在诸多客户端并发请求情况下,Hive Metastore作为服务端为了保障事务和并发操作正确性而所需要的表锁信息。
所以会有一个隐患,假如Hive Metastore因为非正常原因突然挂了,或者一些冷门bug,导致来不及清除这张表上的一些锁信息,这样如果还没有配置自动清理过时锁记录的机制,即使重启Hive Metastore,每次DDL操作时HMS还是会查到这张表里一直存在的相关table的锁记录,以为还是有其他客户端在操作,就会挂起所有其他涉及的alter table等ddl操作请求,直到锁记录消失,它认为不会有并发一致性问题为止。
Hive Metastore获取锁的逻辑入口在编译中通过Thrift框架自动生成的代码类org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore中,如下图所示:

用户通过客户端ThriftHiveMetastore.Iface提供的接口,利用Thrift协议向ThriftHiveMetastore类发起请求,经过该类进行反序列化等RPC通信处理后,实际的服务端响应逻辑会交给继承它的子类org.apache.hadoop.hive.metastore.HiveMetaStore来处理。
而在HiveMetaStore类中,它还有一个内部子类HMSHandler,里面会实现具体的锁相关接口,如下图所示:

可以看到加锁的核心逻辑还是在org.apache.hadoop.hive.metastore.txn.TxnHandler类中,如下图所示:
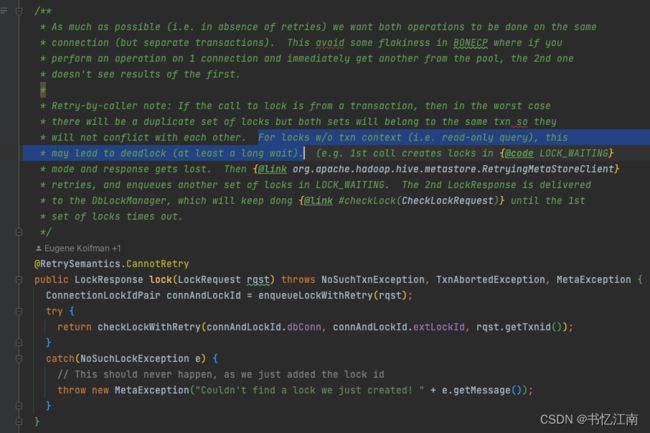
社区自己都说了在一些情况下可能会导致死锁或者长时间等待,我们看看checkLockWithRetry()的逻辑:

看到java.sql.Connection,显然本质上是通过JDBC查数据库来实现的,细节逻辑在checkLock()中,如下图所示:

所以一开始注释中就已经提到了会和hive_locks表有关,而且注释末尾再次强调了这里可能会导致锁等待较久的现象,接着往下看:
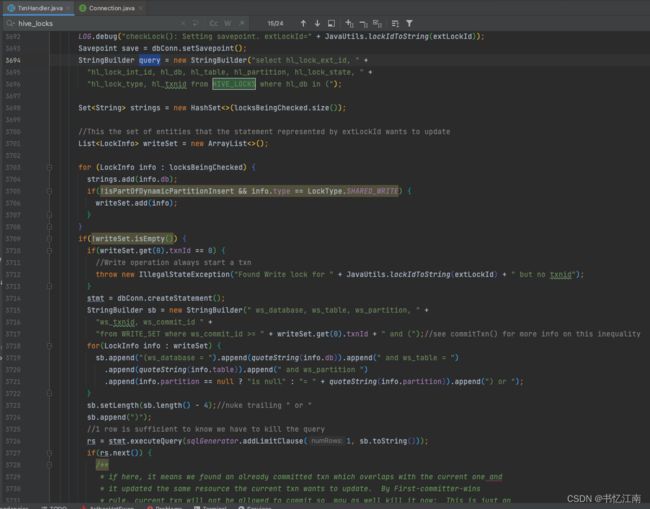
确实是通过拼SQL字符串的方式,来查hive.hive_locks这张表的信息,后面的长串逻辑很多是在拼各种SQL过滤条件和其他操作,我们直接到后面要执行这个SQL的地方:

所以这里会把MySQL表hive.hive_locks中的相应锁信息查出来,加入到要维护的lockSet里。后面重点来了:


所以如果遇到了锁冲突等情况,这里会更新hive_locks表,记录被谁block住等信息,然后返回响应让客户端接着等待,这就是Presto等操作Hive Metastore客户端会等待的原因。
而如果不处于WAITING状态,可以获得锁,那么同样也会去更新这张表,acquire()说明了一切:

1.2、过时清理机制
显然社区轮子大佬心里是清楚会遇到死锁和长时间等待的问题的,那咋办呢?在org.apache.hadoop.hive.metastore.HiveMetaStore.init()启动进程的时候,会利用反射机制获取一些线程类实例,开启一些后台定时调度线程,如下图所示:
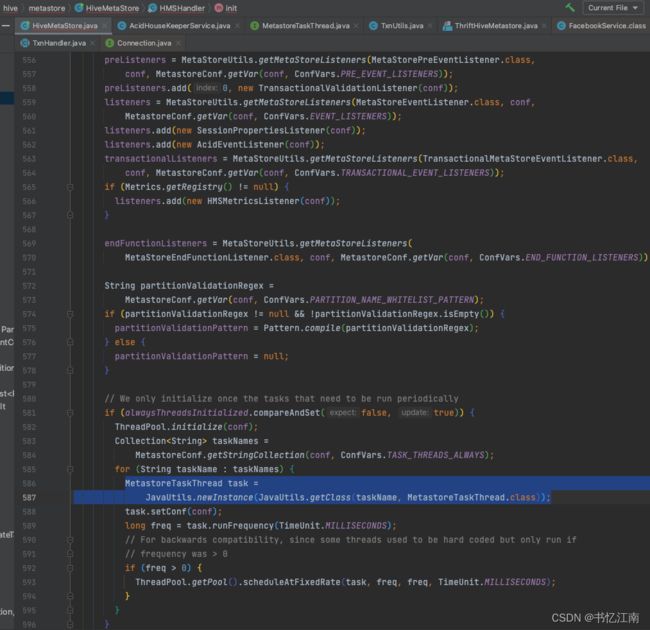
而其中有个实现类org.apache.hadoop.hive.metastore.txn.AcidHouseKeeperService会实现MetastoreTaskThread接口,并且会默认每3分钟定时执行performTimeOuts(),如下所示:

巧了,又回到了前面提到的TxnHandler,注释提到了会清掉心跳超时的锁信息,关键在于timeOutLocks(),如下所示:


所以这里还是老把戏,会去拼凑从hive.hive_locks表中删除默认5分钟前心跳的锁信息的SQL字符串然后执行,这样可以缓解死锁和长时间锁等待的问题。
那为什么这样子Hive Metastore还会遇到开头那种现象呢?因为默认社区没开。。配置参数在org.apache.hadoop.hive.metastore.conf.MetastoreConf的TASK_THREADS_ALWAYS参数中,里面并没有包括AcidHouseKeeperService,如下所示:

二、解决方法
2.1、临时急用
本质上其实清除MySQL元数据库的hive.hive_locks表中的相关锁信息就行,所以临时解决问题可以用delete from或者truncate语句删掉相关的条目就行,但是每次都要手动去操作。
2.2、长期方法
(1)首先在停止Hive Metastore服务的脚本中,要加上先kill -15,等一等再kill -9的逻辑,因为kill -15本质上是给服务发送停止信号,让进程知道后自杀,Hive Metastore收到信号会先调用启动时注册的shutdownHook来做自动清理hive.hive_locks表等操作,如果直接kill -9强干了,它会来不及反应,锁信息就会一直留在hive.hive_locks中(如果没开AcidHouseKeeperService的话)。
(2)在hive-site.xml中配置如下参数,加上AcidHouseKeeperService:
metastore.task.threads.always
org.apache.hadoop.hive.metastore.events.EventCleanerTask,org.apache.hadoop.hive.metastore.RuntimeStatsCleanerTask,org.apache.hadoop.hive.metastore.repl.DumpDirCleanerTask,org.apache.hadoop.hive.metastore.txn.AcidHouseKeeperService
配好后重启Hive Metastore,观察hive.hive_locks表一段时间能看到会自动清掉太久之前的锁记录。