BERT微调
bert微调步骤:
首先从主函数开刀:
copy run_classifier.py 随便重命名 my_classifier.py
先看主函数:
if __name__ == "__main__":
flags.mark_flag_as_required("data_dir")
flags.mark_flag_as_required("task_name")
flags.mark_flag_as_required("vocab_file")
flags.mark_flag_as_required("bert_config_file")
flags.mark_flag_as_required("output_dir")
tf.app.run()1,data_dir
flags.mark_flag_as_required("data_dir")中data_dir为数据的路径文件夹,数据格式已经定义好了:
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label要求的数据格式是:必选参数:guid, text_a,可选参数text_b, label
其中单句子分类任务不需要text_b,且在test数据样本中不需要输入label
2,task_name
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
}其中task_name表示processors这个字典中的键值对,在bert中给了四个,分别是:"cola","mnli","mrpc","xnli",如果需要别的,另行添加
值得注意的是:
task_name = FLAGS.task_name.lower()
if task_name not in processors:
raise ValueError("Task not found: %s" % (task_name))
processor = processors[task_name]()
label_list = processor.get_labels()task_name是用来选择processor的,在bert的源码中有4个processors,而我们进行微调,需要自定义自己的processor,如下:
class MrpcProcessor(DataProcessor):
"""Processor for the MRPC data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"] #todo
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[3])
text_b = tokenization.convert_to_unicode(line[4])
if set_type == "test":
label = "0"
else:
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples其实processor表示对数据进行处理的类,它继承了DataProcessor类对输入数据进行预处理,此外,在data_dir文件夹中,我们的文件格式为.tsv格式,由于设定的分类为二分类,我们将label设置为了0,1
同时_create_examples()中,给定了如何获取guid以及如何给text_a, text_b和label赋值。
主函数的前两句代码看完了,继续看主函数
if __name__ == "__main__":
flags.mark_flag_as_required("data_dir")
flags.mark_flag_as_required("task_name")
flags.mark_flag_as_required("vocab_file")
flags.mark_flag_as_required("bert_config_file")
flags.mark_flag_as_required("output_dir")
tf.app.run()3,vocab_file, bert_config_file, output_dir
其中,vocab_file, bert_config_file分别是下载预训练模型的文件,output_dir表示输出的微调之后的model
此外,在前面所说的.tsv文件格式类似于.csv文件
train.tsv和dev.tsv文件格式
标签+“/t”(制表符)+句子
test文件为
句子
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"mrpc": MrpcProcessor }5,设定参数,进行fine-tune
python my_classifier.py \
--task_name=mprc \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/
一、Bert简介
1.1 简要说明
关于BERT的介绍,已经有铺天盖地的文章和博客或深或浅的介绍了,这里暂时先不展开详细介绍,后面会写一篇论文翻译和理解的博客,这里暂时简要带过,这里我们只简单说明下为什么我们选择在自己数据集上fine-tuning,然后用于预测。
1.2 fine-tune原理
在BERT论文中,作者说明了BERT的fine-tune原理。
BERT模型首先会对input进行编码,转为模型需要的编码格式,使用辅助标记符[CLS]和[SEP]来表示句子的开始和分隔。然后根据输入得到对应的embedding,这里的embedding是三种embedding的和,分别是token、segment、position级别。

得到整体的embedding后即使用相关模型进行学习,最终根据不同任务的分类层得到结果。
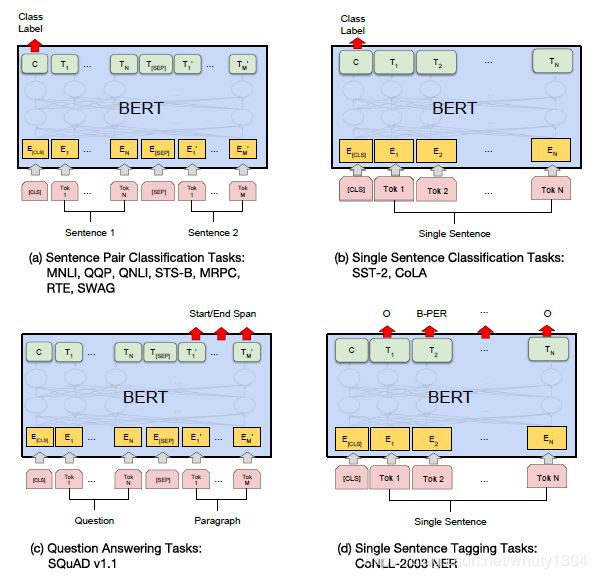
图a表示句子对的分类任务,例如预测下一句、语义相似度等任务,输入是两个句子A和B,中间用[SEP]分隔,最终得到的class label就表示是否下一句或者是否是语义相似的。
图b表示单句分类任务,如常见的文本分类、情感分析等。输入就是一个单独的句子,最终的class label就是表示句子属于哪一类,或者属于什么情感。
图c表示问答任务,主要用于SQuAD数据集,输入是一个问题和问题对应的段落,用[SEP]分隔,这里输出的结果就不是某个class label而是答案在给定段落的开始和终止位置,主要用于阅读理解任务。
图d表示单个句子标注任务,例如常见的命名实体识别任务,输入就是一个单独的句子,输出是句子中每个token对应的类别标注。
这里我主要是使用了前两个任务的方法,分别fine-tune了预测下一句模型和单句分类模型。
二、在项目数据集上fine-tune教程
因为之前主要使用的框架是Pytorch,因此fine-tune的代码也主要参考了pytorch版的bert复现代码(https://github.com/huggingface/pytorch-pretrained-BERT)。
先做的是文本分类任务,主要参考了examples/run_classifier.py(https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_classifier.py),可以看到,整个脚本代码有接近1000行,但是其实在我们的fine-tune过程中,需要理解的关键部分主要是DataProcessor类。我们的fine-tune说的直白一点,就是把我们自己的数据整理好,转换成BERT模型能够读取的输入,只要模型读到了inputs,后续的各种内部转换表示其实已经不需要我们关注了(但是最好还是要理解,学习最牛的模型的原理和思路)。
2.1整体流程
首先简要介绍下fine-tune的整体流程,如下图所示:

我们首先需要先进行一些预处理,就是把训练集、验证集、测试集标签化。接着会调用我们自定义的继承DataProcessor类的MyPro类,这一步就是实现将我们的训练数据,转换成模型能够获取的标准输入格式。这里是转换成论文定义的一种InputExamples格式,相关代码:
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""生成一个InputExample.
Args:
guid: 每个example的独有id.
text_a: 字符串,也就是输入的未分割的句子A,对于单句分类任务来说,text_a是必须有的
text_b: 可选的输入字符串,单句分类任务不需要这一项,在预测下一句或者阅读理解任务中需要输入text_b,
text_a和text_b中间使用[SEP]分隔
label: 也是可选的字符串,就是对应的文本或句子的标签,在训练和验证的时候需要指定,但是在测试的时候可以不选
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
接着会调用convert_examples_to_features()将所有的InputExamples转为一种train_features格式,相关代码:
class InputFeatures(object):
"""A single set of features of data.
Args:
input_ids: token的id,在chinese模式中就是每个分词的id,对应一个word vector,就是之前提到的混合embedding
input_mask: 真实字符对应1,补全字符对应0,在padding的时候可能会补0,需要记录一下真实的输入字符,模型的attention机制只关注这些字符
segment_ids: 句子标识符,第一句全为0,第二句全为1,主要是用于区分单句任务或者是句子对任务,
但其实我们通过使用[SEP]已经起到了区分作用,这里主要还是为了便于模型识别计算
label_id: 将Label_list转化为相应的id表示,这里的Label_list可以是数字,可以是字符串,这里统一转换成label_id便于后续加载到tensor中
"""
def __init__(self, input_ids, input_mask, segment_ids, label_id):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
后面的就是pytorch中的相关操作,先将train_features转为TensorDataset格式,再使用DataLoader将TensorDataset送到模型中进行训练。
2.2 自定义DataProcessor
接着重点讲一下fine-tune任务最重要的DataProcessor类和我们怎么继承DataProcessor类。
原始的DataProcessor类定义了获取训练集、验证集、测试集对应的examples方法,获取label的方法,至于在此基础之上的其他方法我们都可以自己再定义
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the test set."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
# 这里的_read_json并不是DataProcessor类中必须包含的,是我自己定义的读取json文件内容转为字典,再添加到list中用于转化为InputExample格式的辅助函数
@classmethod
def _read_json(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
dicts = []
with codecs.open(input_file, 'r', 'utf-8') as infs:
for inf in infs:
inf = inf.strip()
dicts.append(json.loads(inf))
return dicts
而我们需要继承重写的MyPro类,则必须要实现DataProcessor类中定义的几个方法,至于如何实现,以何种类型存储、读取,这些都是我们可以自己自定义的。我这里是使用json格式来存储获取的。相关代码如下:
class MyPro(DataProcessor):
"""自定义数据读取方法,针对json文件
data_dir是我们的训练集、验证集、测试集存放的文件路径,因为之前是在Linux环境后来改到Windows环境,增加了一个路径转化过程
_create_examples函数的作用是读取上面的_read_json函数返回的文件内容,这里的json文件格式为{'content':content, 'label':label},其中content表示文本内容,也就是每个句子,label表示句子对应的标签。然后依次转化成模型需要的InputExample格式
Returns:
examples: 数据集,包含index、中文文本、类别三个部分
"""
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_json(os.path.join(data_dir, "train.json").replace('\\', '/')), 'train')
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_json(os.path.join(data_dir, "val.json").replace('\\', '/')), 'dev')
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_json(os.path.join(data_dir, "test.json").replace('\\', '/')), 'test')
def get_labels(self):
return [0, 1]
def _create_examples(self, dicts, set_type):
examples = []
for (i, infor) in enumerate(dicts):
guid = "%s-%s" % (set_type, i)
text_a = infor['content']
label = infor['label']
examples.append(InputExample(guid=guid, text_a=text_a, label=label))
return examples
再次说明,我们fine-tune任务,其实就是把我们的项目数据,转换成BERT模型可以读取的输入格式。我们的关键任务就是在上面的自定义Processor中,自定义一些文件读取、转换函数,把我们的文本数据,输入到模型中,进行微调。输入文件类型可以是csv,可以是json,也可以是txt等,只要我们在继承的Processor类中定义好我们的读取和转换函数,把文件中的文本数据,转成InputExamples格式,其实我们的微调任务已经完成了一大半。至于在上面数据处理过程中涉及到的其他代码,例如padding,convert_example_to_features这些函数,这里就不一一展开细讲,后续如果有时间可以再写一个详细的源码解析博客。
2.3 参数设置
接下来,在我们已经处理好数据,能够将数据送到模型中去,我们就要准备开始fine-tune and train。huggingface的代码中,关于train部分的特别长一段,我也做了一些简要的注释说明,但是限于篇幅这里就不全贴了,重点需要说明一下相关的参数设置。
main函数一开始就是一大段的参数设置,我们需要重点关注的主要包括以下几个参数:
data_dir: 输入数据的文件目录,里面应该包含train val test三个文件分别用于训练、验证、测试
bert_model: 所使用的bert预训练模型,这里我们一般用到的是bert-base-chinese
task_name:训练任务的名称,其实就是用来获取我们为每个任务自定义的Processor类
model_save_pth: 训练完的模型参数的保存地址
max_seq_length:字符串的最大长度,越长需要越多的计算量,一般设置64或128
do_train/do_eval:是否训练或验证
train_batch_size:训练时的batch大小,一般设置为64
learning_rate:学习率,论文推荐了几个,5e-5, 3e-5, 2e-5
no_cuda:是否使用GPU加速,如果设置为False,双重否定表肯定,表示使用GPU训练模型,这里就会埋下一个坑
local_rank:这个参数可以不改,默认设置为-1,但是主要也涉及到一个坑
这里引出了一个小坑,开源代码里面把模型训练和预测都放在main函数里面,对一个任务,只需要初始化一次上面的参数即可按顺序完成训练和预测,代码使用的是python常用的命令行解析包ArgumentParser。但是也带来了一个问题,我们训练完模型保存好参数之后,预测的时候不需要再训练了,只需要读取权重矩阵进行预测即可,因此我们尝试把train和test分开,但是这样,我们就需要重新再设置一下相关的参数,最暴力的方法就是再在预测函数里面再用一次parser.add_argument()设置相关参数。但是我们经过考虑,改变了参数的获取形式,定义了一个参数类,保存了一些默认不需要修改的参数,把重要的,需要设置的参数开放接口让外部自定义,最后返回一个包含相关参数的字典,相对来说设置参数的步骤和代码更为精简和方便。
书接上回,继续准备train,设置完参数后,就是依次进行一些判断和初始化,包括:
设置processor
判断是否使用GPU或者16位精度,
判断输出路径是否存在,
选择任务名,加载processor,获取label_list,
调用tokenizer方法,
获取训练样本,也就是调用我们之前的自定义Processor方法将文本数据转为InputExamples。
准备模型,这里是使用bert预训练模型中的BertForSequenceClassification,预测下一句的时候选的是BertForNextSentencePrediction
判断是否使用16位精度加速,是否可以使用多GPU进行分布式计算(深坑!)
选择优化方法,这里一般都选的是BertAdam
开始迭代训练,训练之前先做好准备工作,先将InputExample转为train_features,再送到DataLoader,其实就是上面那张流程图。这些都完成之后,开始训练,model.train(),剩下的就是计算loss,反向传播,巴拉巴拉
然后有个小trick,每迭代一轮,在验证集上验证一次,记录最好效果,根据得到的f1值进行相关操作,如果新的f1值大于最好成绩,更新矩阵,如果连续n次都没有提升效果,则进行eraly_stop,将最好成绩的矩阵保存到模型存储路径。
接下来就是等待模型迭代训练完毕,完成fine-tune了。不得不说,Bert的效果确实不错,即使是在小数据集上,最终的效果几乎都能达到很高的效果。分类任务我自己测试了一个情感分类的数据集和清华的新闻分类数据集,几轮迭代后效果都已经超过90%了。也就是说,在我们的数据集上根据特定任务微调BERT模型,这条路是可行的。
2.4 预测函数
训练完之后,我们就可以在原有的test函数基础上扩展我们自己的预测功能,可以将预测函数写成一个类,初始化类的时候直接加载好我们已经训练得到的模型和各种参数,预测函数只开放数据输入接口,输入待分类的单句或者句子对,即可加载模型得到预测结果。我的相关工作主要就是使用文本分类做一些情感分析和意图识别,用预测下一句模型实现自然语言推理,效果都还不错。由于相关代码涉及到具体项目内容,不能直接贴上代码,后续会整理一个使用公开情感分析数据集的简单情感分析模型的训练和使用代码,欢迎star2333。
三、踩坑记录
当然,如果一切顺利,我们会发现fine-tune其实还是挺简单的,也没那么玄乎。但是,这其中还是存在不少大大小小的坑的。简要记录下在这个过程中遇到的问题和解决方案:
开源代码中埋下的坑:
当我把上面的步骤都走通了,数据准备好了,运行main函数进行训练的时候,每次都会报一个提示,需要下载相关文件到本地缓存,速度奇慢无比:

这个其实是一种缓存机制,第一次运行的时候是需要下载的,下载的缓存路径是代码中隐藏的一个变量,可以看到默认设置的是Path.home()/.pytorch_pretrained_bert,就是说他在我们的home路径下面新建了一个文件夹,把需要的东西都下载到这个文件夹,为了便于项目开发,我们可以在项目中新建一个缓存文件夹,把这个缓存路径的地址指向缓存文件夹。
PYTORCH_PRETRAINED_BERT_CACHE = Path(os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
Path.home() / '.pytorch_pretrained_bert'))
还有一个坑就是如果我们在选择模型的时候,需要选择from_pretrained(),并指定缓存地址为刚才设置的地址,此外我们还需要下载一个bert-base-chinese.tar.gz(https://pan.baidu.com/s/1tdwOyE-szhapovMmPgelDA)文件,提取密码75wm,并解压放到这个缓存地址即可。
model = BertForSequenceClassification.from_pretrained(args.get('bert_model'),
cache_dir=PYTORCH_PRETRAINED_BERT_CACHE / 'distributed_{}'.format(
args.get('local_rank')))
pytorch与BERT中与分类有关的问题
pytorch中,分类任务的类别不能为负数,否则会报错,例如原来用-1表示负例,需要进行处理,转为非负数表示。
此外,在选择BertForSequenceClassification模型时,模型默认的分类类别数是2,如果在训练集中指定的类别数大于2,则需要在上面那段代码中增加一个num_labels参数,最终效果如下所示:
model = BertForSequenceClassification.from_pretrained(args.get('bert_model'),
cache_dir=PYTORCH_PRETRAINED_BERT_CACHE / 'distributed_{}'.format(
args.get('local_rank')), num_labels=3)
还有一个巨坑折腾了我一两天,就是pytorch的nn.parallel.DistributedDataParallel()
我最开始是在GPU服务器上分布式计算的,4块1080ti,那个训练速度,嗖嗖的,训练完保存之后,在GPU上加载测试也没毛病,但是后来说要确保在CPU上也能运行,就把.pth文件复制到CPU服务器上,运行起来就报错了,报错结果如下图:

Google,Stack Overflow,CSDN,找了好多文章,最后总结错误原因为我们在训练的时候使用了nn.parallel.DistributedDataParallel()这个函数将数据和模型都分布式的分配到多GPU上,最后保存下来的模型中的矩阵前面多了一个module前缀,如下图所示,导致load_static_dict找不到对应的参数:

我们需要获取的是去掉module. 前缀的后面的key,从而获取到后面的tensor矩阵。最终的解决方法代码如下,还要设置一个map_location参数,选择cpu:
model = BertForSequenceClassification.from_pretrained(args.get('bert_model'))
# 加载已有的模型参数到cpu
state_dict = torch.load(args.get('model_save_path'), map_location='cpu')['state_dict']
# 创建一个新的state_dict加载预训练的模型参数进行预测
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = k[7:] # remove module.
new_state_dict[name] = v
# 获取真正的权重矩阵
model.load_state_dict(new_state_dict)
test(model, processor, args, label_list, tokenizer, device)
tensorlfow版本的bert微调
要想在中文情感分类任务中完成bert语言模型的微调,需要有bert开源的代码,然后在bert开源数据中下载chinese_L-12_H-768_A-12,最后还要有中文情感数据,数据格式为(类别id\t句子)。如果bert代码和中文情感数据没有,可以在我分享的资源中下载。如果三者都有了按照以下操作即可完成微调,并对微调后的模型进行使用。
run_classifier.py中找到
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"intentdetection":IntentDetectionProcessor,
"emotion":EmotionProcessor, #新加上这一行,emotion是在运行时用来调用的方法名,EmotionProcessor是你自己声明的类。
}然后在该文件中增加一个class,这个类名和你刚刚声明的那个“emotion":EmotionProcessor, 保持一致:
class EmotionProcessor(DataProcessor):
"""Processor for the MRPC data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "fine_tuning_train_data.tsv")), "train") #此处的名字和文件夹中的训练集的名字要保持一致
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "fine_tuning_val_data.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "fine_tuning_test_data.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1","2","3","4","5","6"] #七分类则从0到6
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
if set_type == "test":
label = "0"
text_a = tokenization.convert_to_unicode(line[0])
else:
label = tokenization.convert_to_unicode(line[0])
text_a = tokenization.convert_to_unicode(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples最后直接调用即可,运行的命令如下:
python run_classifier.py \
--task_name=emotion \#同第一段代码最后一行
--do_train=true \
--do_eval=true \
--data_dir=data \ #把中文情感数据解压到同一级的文件夹中,此处是该文件夹名字data
--vocab_file=chinese_L-12_H-768_A-12/vocab.txt \ #中文数据要微调的原始bert模型,这个自行下载,和run_classifier.py放同一级的路径
--bert_config_file=chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=chinese_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=output #生成文件所在的文件夹
(上面的注释自己去掉)大概9个小时,最后文件夹中会有三个文件 后缀分别为:index / meta / 00000-of-00001,
分别将这个改成bert_model.ckpt.index / bert_model.ckpt.meta / bert_model.ckpt.data-00000-of-00001,再在同一个文件夹中放入chinese_L-12_H-768_A-12中的vocab.txt和bert_config.json 即最后该文件夹中有5个文件。然后像调用chinese_L-12_H-768_A-12一样将文件夹名改成自己的文件夹名即可。
bert-serving-start -model_dir output -num_worfer=3 即可调用微调后的语言通用模型。