语义分割CVPR2020-Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision
Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision:基于自监督的非监督域内自适应语义分割
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.无人监督的领域适应
- 2.2.通过熵计算不确定性
- 2.3.课程式领域自适应
- 3.方法
-
- 3.1.域间的适应
- 3.2.基于熵的排名
- 3.3.域内适应
- 4.实验
-
- 4.1.数据集
- 4.2.结果
- 4.3.讨论
- 5.结论
- 6.方法部分精简总结
- 参考文献
论文下载
开源代码
0.摘要
基于卷积神经网络的语义分割方法已经取得了显著的进展。然而,这些方法严重依赖于注释数据,这是劳动密集型的。为了克服这一限制,从图形引擎中生成的自动标注数据被用来训练分割模型。然而,从合成数据中训练出来的模型很难转化为真实图像。为了解决这一问题,以往的工作考虑直接将模型从源数据调整到未标记的目标数据(以减少域间的差距)。尽管如此,这些技术并没有考虑目标数据本身之间的巨大分布差距(域内差距)。在本研究中,我们提出了一种两步自监督域自适应方法来最小化域间和域内的差距。首先,我们对模型进行域间适应;从这个适应中,我们使用基于熵的排序函数将目标域分割成简单和困难的分割。最后,为了减小域内差距,我们提出了一种自监督自适应技术,由容易分割到难分割。在大量基准数据集上的实验结果突出了我们的方法相对于现有先进方法的有效性。
1.概述
语义分割的目的是将图像中的每个像素分配给一个语义类。近年来,基于卷积神经网络的分割模型[14,34]取得了显著的进展,在计算机视觉系统中得到了各种应用,如自动驾驶[15,32,13]、机器人[16,24]、疾病诊断[36,33]。训练这样的分割网络需要大量的注释数据。然而,使用像素级的注释收集大规模的数据集进行语义分割是很困难的,因为它们昂贵且耗费人力。最近,来自模拟器和游戏引擎的具有精确像素级语义标注的逼真数据被用于训练分割网络。然而,由于[11]的跨域差异,由合成数据训练的模型很难转换为真实数据。为了解决这一问题,提出了无监督域适应(unsupervised domain adaptive, UDA)技术来对齐标记源数据和未标记目标数据之间的分布偏移。对于特定的语义分割任务,基于对抗学习的UDA方法在图像[17,11]或输出[27,26]水平上显示出高效的特征对齐。最近,由[29]提出的像素级输出预测熵也被用于输出电平对齐。其他方法[39,38]包括为目标数据生成伪标签,并通过迭代的自我训练过程进行细化。虽然许多模型考虑了单源-单目标的适应设置,但最近的研究[19,35]提出了解决多源域的问题;重点研究了多源单目标适应环境。最重要的是,以前的工作主要考虑将模型从源数据调整到目标数据(域间间隙)。
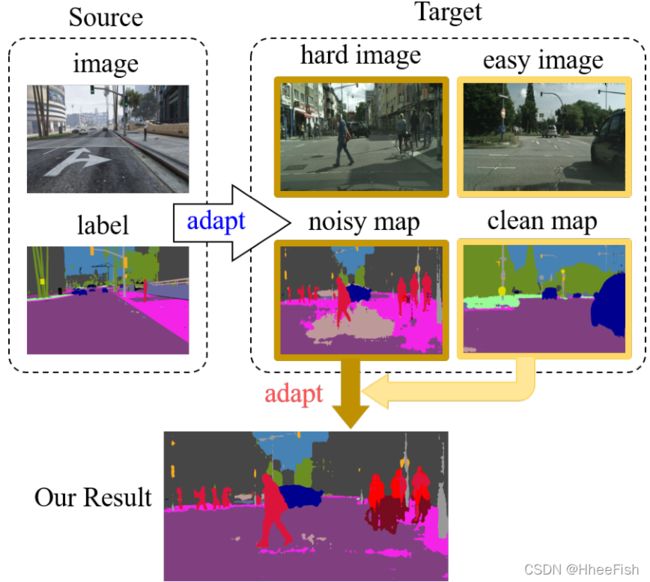
图1: 我们提出了一种两步自监督领域自适应技术用于语义分割。以前的工作只是将分割模型从源域调整到目标域。我们的工作还考虑了从干净的地图到目标域内的噪声地图的适应。
然而,从现实世界收集的目标数据具有不同的场景分布;这些分布是由各种因素造成的,例如移动对象、天气条件,这些因素导致目标中存在较大的间隙(域内间隙)。例如,图1所示的目标域中的噪波贴图和干净贴图是同一模型对不同图像的预测。虽然以前的研究仅仅关注于减少域间的差距,但域内差距的问题却没有引起足够的重视。
在本文中,我们提出了一种两步域自适应方法来最小化域间和域内的间隙。我们的模型由三部分组成,如图2所示,即:

图2:提出的自监督领域自适应模型
- 域间自适应模块,用于缩小标记源数据和未标记目标数据之间的域间差距;
- 基于熵的排名系统,用于将目标数据划分为简单和困难的部分
- 域内适配模块,用于闭合容易剥离和硬剥离之间的域内间隙(使用来自容易子域的伪标签)。
在语义分割方面,我们提出的方法在基准数据集上取得了良好的性能。此外,在数字分类方面,我们的方法优于以前的域自适应方法
我们工作的贡献: - 首先,引入目标数据的域间差异,提出一种基于熵的排序函数,将目标域划分为简单和困难的子域;
- 其次,我们提出了一种两步自监督的领域自适应方法来最小化域间和域内的差距
2.相关工作
2.1.无人监督的领域适应
无监督域自适应的目标是对齐标记源数据和未标记目标数据之间的分布偏移。最近,基于对抗的UDA方法在学习领域不变特征方面表现出了巨大的能力,甚至对于复杂的任务,如语义分割[29,4,27,26,22,11,18]。基于对抗性的UDA语义分割模型通常包含两个网络。其中一个网络作为一个发生器来预测输入图像的分割图,它可以是源图像也可以是目标图像。给定来自生成器的特征,第二个网络作为一个鉴别器来预测域标签。生成器试图欺骗鉴别器,以便使两个域的特征分布偏移对齐。除了特征级对齐外,其他方法尝试对齐图像级或输出级的域移动。在图像层面,[11]采用CycleGAN[37]构建生成图像进行域对齐。在输出层面,[26]提出了一种端到端模型,该模型涉及分布偏移的结构输出对齐。最近,[29]利用分割输出的像素预测熵来解决域间隙。虽然之前的所有研究都专门考虑对齐域间的差距,但我们的方法进一步最小化了域内的差距。因此,我们的技术可以与大多数现有的UDA方法相结合,以获得额外的性能收益。
2.2.通过熵计算不确定性
不确定度测量与无监督域适应有很强的联系。例如,[29]提出直接最小化模型输出的目标熵值或使用对抗学习[26,11]来缩小语义分割领域的差距。此外,模型输出[30]的熵被用作跨域传输样本[25]的置信度度量。我们提出利用熵对目标图像进行排序,将目标图像分为两种,容易和困难的分割。
2.3.课程式领域自适应
我们的工作也涉及到课程领域适应[23,32,7],这首先处理简单的样本。对于大雾场景理解的课程域自适应,[23]提出了一种将非大雾图像的语义分割模型应用于合成的轻雾图像,再应用于真实的重雾图像。为了推广这一概念,[7]通过引入无标记的中间域,将域差异分解为多个更小的差异。然而,这些技术需要额外的信息来分解域。为了克服这一局限性,[32]将学习图像的全局和局部标签分布作为目标域中正则化模型预测的首要任务。与此相反,我们提出了一种基于熵排序系统的更简单的数据驱动方法来学习容易的目标样本。
3.方法
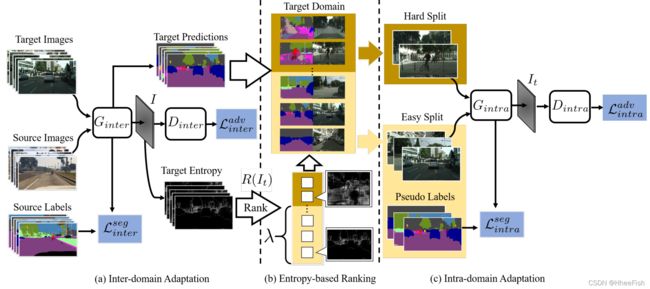
图二:提出的自监督域自适应模型包含域间生成器和鉴别器{Ginter, Dinter},域内生成器和鉴别器{Gintra, Dintra}。该模型由三个部分组成,即(a)域间适应,(b)基于熵的排名系统,©域内适应。在(a)中,给定源和未标记的目标数据,训练Dinter预测样本的域名标签,训练Ginter愚弄Dinter。{Ginter, Dinter}通过最小化分割损失Lseginter和对抗性损失Ladvinter来优化。在(b)中,使用一个基于熵的函数R(It)将所有目标数据分为易分割和难分割。超参数λ被引入作为分配到易于分割的目标图像的比率。在©中,使用域内适配来缩小易拆分和难拆分之间的差距。Ginter中易于分割的数据的分割预测可以用作伪标签。对于带有伪标签的容易分割数据和硬分割数据,Dintra被用来预测样本是容易分割还是硬分割,而Gintra则被训练来混淆Dintra。{Gintra和Dintra}使用域内分割损失Lsegintra和对抗损失Ladvintra进行优化
设S表示由一组图像∈RH×W×3及其相关的ground-truth C类分割图∈(1,C)H×W组成的源域;同样,让T表示包含一组未标记图像⊂RH×W×3的目标域。在本节中,我们将介绍一种两步自监督领域自适应语义分割方法。
- 第一步是域间适应,这是基于常用的UDA方法[29,26]。然后,生成目标数据的伪标签和预测熵映射,从而实现对目标数据进行聚类,分为容易和困难。具体来说,使用基于熵的排名系统将目标数据聚类为容易和困难的分割。
- 第二步是域内适配,包括将使用伪标签的容易分割与困难分割对齐,如图2所示。该网络由域间生成器和标识符{Ginter, Dinter}和域内生成器和标识符{Gintra, Dintra}组成。
3.1.域间的适应
样本Xs∈RH×W×3来自源域及其关联映射Ys。Y的每个对象Ys(h,w) =[Ys (h,w,c)]c提供了一个像素(h,w)的标签作为独热码向量。网络Ginter以Xs为输入,生成“软分割图”Ps = Ginter(Xs)。像素(h,w)处的每个C维向量[P(h,w,c)]c作为c类上的离散分布。给定Xs及其ground-truth标记Ys, Ginter通过最小化交叉熵损失,以监督的方式进行优化:
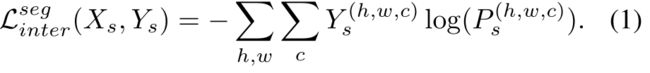
为了缩小源域和目标域之间的域间差距,[29]提出利用熵映射来对齐特征的分布偏移。[29]的假设是,经过训练的模型倾向于对类源图像产生过度自信(低熵)的预测,而对类目标图像产生低自信(高熵)的预测。由于[29]的简单性和有效性,我们在工作中采用了它来进行跨领域的适应。生成器Ginter以目标图像Xt为输入,生成分割映射Pt= Ginter(Xt);熵特征图It的表达式为:
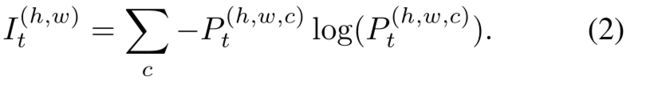
为了对齐域间间隙,训练Dinter预测熵图的域标签,训练Ginter愚弄Dinter;Ginter和Dinter的优化通过以下loss函数实现:
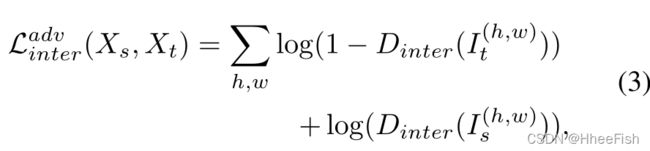
I:熵特征图;Dinter :域间标识符
对损耗函数Ladvinter和Lseginter进行优化,使源数据和目标数据之间的分布偏移保持一致。然而,仍然需要一种有效的方法来最小化域内的差距。为此,我们建议将目标域分为容易的和困难的两个部分,并进行域内适配。
3.2.基于熵的排名
由于不同的天气条件、运动物体和阴影,从现实世界采集的目标图像具有不同的分布。在图2中,一些目标预测图是干净的,而另一些则是非常嘈杂的,尽管它们是由相同的模型生成的。由于目标图像之间存在域内间隙,一个简单的解决方案是将目标域分解为小的子域或者小的分割块。然而,由于缺乏目标标签,这仍然是一个具有挑战性的任务。为了构建这些分割,我们利用熵图来确定目标预测的置信水平。生成器Ginter以目标图像Xt为输入,生成Pt和熵图It。在此基础上,我们采用了一种简单而有效的排序方法: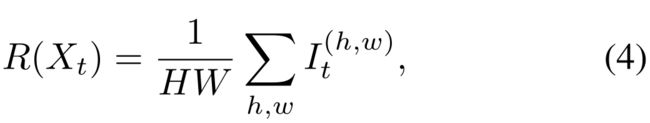
也就是熵映射It的均值。根据R(Xt)的分数排序,引入了超参数λ作为比率,将目标图像分成容易和困难的两部分。设Xte和Xth分别表示分配给易分割和难分割的目标图像。为了进行域分离,我们定义λ = |Xte|/|Xt|,其中|Xte|是容易分割的基数,|Xt|是整个目标图像集的基数。为了获取λ的影响,我们在表2中对如何优化λ进行了消融研究。注意,我们没有引入超参数作为分离的阈值,因为阈值依赖于特定的数据集。我们选择了一个比率超参数,这对其他数据集具有很强的泛化能力
3.3.域内适应
由于易分割没有标注,直接对齐易分割和难分割之间的差距是不可行的。但我们建议利用Ginter的预测作为伪标签。给定一个来自容易分割影像集合的Xte的图像,我们将Xte转发给Ginter,得到预测图Pte = Ginter(Xte)。虽然Pte是一个“软分割图”,但我们将Pte转换为在 Pte ,其中每个条目都是一个独热码向量。在伪标签的帮助下,通过最小化交叉熵损失来优化Gintra:
为了弥补容易分割和困难分割之间的域内差距,我们对两个分割都采用了熵映射上的对齐方法。取难以分割的影像集合中的图像Xth作为输入到生成器G,生成分割图Pth= G(Xth)和熵图Ith。为了缩小域内差距,训练域内判别器Dintra来预测Ite和Ith的分割标签:Ite来自容易分割,Ith来自难分割。G被训练去愚弄Dintra。优化Gintra和Dintra的对抗性学习损失公式为
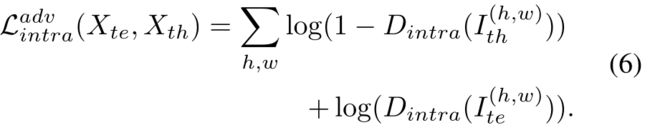
最后,我们的完整的损失函数L由以下所有损失函数构成:
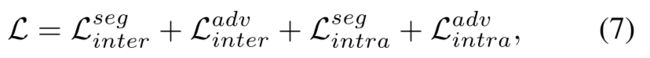
我们的目标是学习目标模型G,根据:
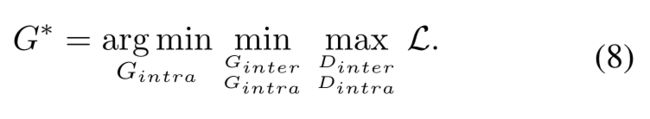
由于我们提出的模型是两步自监督方法,所以很难在一个训练阶段最小化L。因此,我们选择在三个阶段最小化它。首先,我们训练模型的域间适应性来优化Ginter和Dinter。其次,利用Ginter生成目标伪标签,并基于S(Xt)对所有目标图像进行排序。最后,我们训练域内自适应优化Gintra和Dintra。
4.实验
在本节中,我们介绍了语义分割的域间适配和域内适配的实验细节。
4.1.数据集
在语义分割的实验中,我们采用了从合成到真实域的自适应设置。要执行这一系列测试,将包括GTA5[20]、SYNTHIA[21]和Synscapes[31]在内的合成数据集用作源域,同时将真实数据集cityscapes[6]用作目标域。在给定有标记的源数据和未标记的目标数据时,对模型进行训练。我们的模型在cityscapes验证集上进行了评估。
- GTA5:合成数据集GTA5[20]包含24,966张合成图像,分辨率为1,914×1,052,以及相应的ground-truth注释。这些合成图像是从一个基于洛杉矶城市风景的电子游戏中收集来的。自动生成的ground-truth注释包含33个类别。对于训练,我们只考虑与cityscape数据集[6]兼容的19个类别,这与之前的工作类似。
- SYNTHIA: SYNTHIA- rand - cityscape[21]用作另一个合成数据集。它包含9,400张完整注释的RGB图像。在训练期间,我们使用cityscape数据集考虑16个常见类别。在评估过程中,使用16和13个类子集来评估性能。
- Synscapes: Synscapes[31]是一个逼真的合成数据集,由25,000张完整注释的RGB图像组成,分辨率为1,440×720。与城市景观一样,地面真相注释包含19个类别
- Cityscapes: Cityscapes[6]是一个从真实世界收集的数据集,它提供了3975张带有精细分割注释的图像。2975张图片是从训练集城市景观中拍摄的,用于训练。来自城市景观评价集的500幅图像被用来评价我们的模型的性能。
评价指标:交并比IoU(intersection-over-union metric)
实现细节:
在GTA5→城市景观和SYNTHIA→城市景观的实验中,我们利用AdvEnt[29]框架对Ginter和Dinter进行域间适应训练;Ginter的主干是ResNet-101架构[10],参数来自ImageNet [8];输入数据被标记为源图像和未标记的目标图像。域间适应Ginter的模型经过了70000次迭代的训练。训练之后,Ginter被用来为所有2975张来自cityscape训练集的图像生成分割和熵图。然后,利用R(Xt)对所有目标图像进行排序,并根据λ将目标图像分为容易分割和困难分割。我们在表2中对λ进行了消融研究以进行优化。对于域内适配,Gintra具有与Ginter相同的架构,Dintra具有与Dinter相同的架构;输入的数据是2975张带有易于分割的伪标签的城市景观训练图像。Gintra是用ImageNet和Dintra的预训练参数从零开始进行训练的,类似于AdvEnt。除了前面提到的实验,我们还进行了synscape→cityscape的实验。为了与AdaptSegNet[26]进行比较,我们将AdaptSegNet框架应用于域间适配和域内适配的实验中。
与[29]和[26]类似,我们利用conv4和conv5的多级特征输出进行域间自适应和域内自适应。为了训练Ginter和Gintra,我们应用了SGD优化器[2],其学习速率为2.5 × 10−4,动量为0.9,训练Ginter和Gintra的权值衰减为10−4。学习速率为10−4的Adam优化器[12]用于训练Dinter和Dintra。
4.2.结果


表3:GTA5→ Cityscapes的自训练和域内适应增益。
GTA5:在表1 (a)中,我们比较了我们的方法与其他最先进的方法[26,5,29]在cityscapes验证集上的分割性能。为了进行公平的比较,基线模型采用了来自DeepLabv2[3]的ResNet-101骨干。总的来说,我们提出的方法达到了46.3%的平均IoU。与AdvEnt相比,我们的方法的域内适应导致平均IoU提高了2.5%。
为了突出提出的域内适应的相关性,我们在表3中对分割损失Lseg和对抗适应损失Ladvintra进行了比较。基线AdvEnt[29]达到mIoU的43.8%。通过使用AdvEnt +域内自适应,即Lsegintra = 0,我们获得了45.1%,表明对抗学习对域内对齐的有效性。通过应用AdvEnt + self-training, λ = 1.0(所有用于self-training的伪标签),即Ladvintra = 0,我们实现了mIoU的45.5%,这说明了伪标签的重要性。最后,我们提出的模型达到了46.3%的mIOU(自训练+域内对齐)。
诚然,复杂的场景(包含许多对象)可能被归类为“困难”。为了提供一个更有代表性的“排序”,我们采用了一种新的归一化方法,将平均熵除以目标图像中预测的稀有类的数量。对于城市景观数据集,我们将这些罕见的类定义为“墙、栅栏、杆子、交通灯、交通标志、地形、骑手、卡车、公共汽车、火车、汽车”。熵归一化有助于将具有多个对象的图像移动到易于分割的位置。经过归一化处理,我们提出的模型达到了47.0%的mIoU,如表3所示。我们提出的方法对于某些类也有局限性。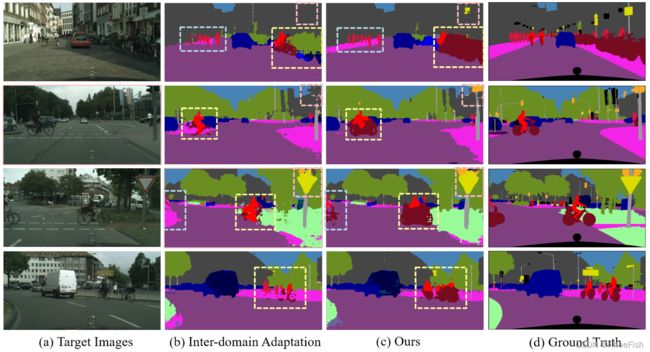
图3:GTA5→Cityscapes的评价示例结果。(a)和(d)为来自cityscape验证集的图像和相应的ground-truth注释。(b)为域间适配[29]的预测分割图。©是我们技术的预测图。
在图3中,我们从我们的技术中提供了一些可视化的分割映射。通过域间比对和域内比对训练得到的模型分割图,比只进行域间比对训练的基线模型AdvEnt更准确。图4中显示了一组属于“硬”分割的代表性图像。域内对齐后,我们生成(d)列中所示的分割映射。与©列相比,我们的模型可以转移到更困难的目标图像上。
在GTA5→Cityscapes的实验中,我们对超参数λ的合适值进行了研究。在表2中,不同的δ值用于建立域分离的决策边界。当λ = 0.67,即|Xte|与|Xt|的比值约为2/3时,该模型在citylandscape验证集上的最佳性能达到了46.3 mIoU。
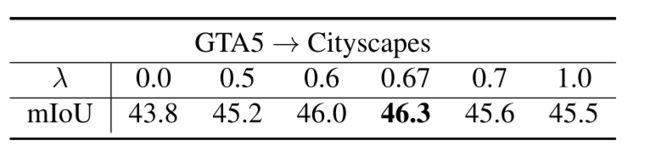
表2:超参数λ在目标领域分割中的消融研究。
SYNTHIA:我们使用SYNTHIA作为源域,并在表1的城市景观验证集上给出了本文方法和最先进的方法[26,29]的评价结果。为了进行比较,我们还采用了与ResNet-101架构相同的DeepLab-v2。我们的方法在16类和13类基线上进行评估。根据表1 (b)的结果,我们提出的方法在16级和13级基线上分别获得了41.7%和48.9%的平均IoU。如表1所示,我们的模型在汽车和摩托车类上比现有技术更精确。原因是我们应用域内适应来进一步缩小域间的差距

Synscapes:我们目前使用Syncapes数据集发现的唯一工作是[26]。因此,我们使用AdaptSegNet[26]作为基线模型。为了提供一个公平的比较,我们只考虑使用 vanilla-GAN 在我们的实验。在域间适配和域内适配的情况下,我们的模型达到了54.2%的mIoU,高于表1 ©所示的AdaptSegNet。

4.3.讨论
理论分析:
比较表1中的(a)、(b),GTA5→cityscapes比SYNTHIA→cityscape更有效。我们认为这是因为比起其他合成数据集,GTA5拥有更多与cityscapes相似的街景图像。本文还进行了理论分析。设H表示假设类,S和T是源域和目标域。由[1]理论提出了目标定义域上的期望误差T (h)的定界:∀h∈h, T (h)≤εS(h) + 1/2 dH(S, T) +Λ,其中,εS(h)为源定义域上的期望误差;dH(S, T) = 2sup|PrS(h)−PrT(h)|,为域散度距离;Λ在一般情况下被认为是一个常数。因此,T (h)是εS(h)和dH(S, T)的上界。我们提出的模型是利用域间对齐和域内对齐来最小化dH(S, T)。如果dH(S, T)值高,则域间适应第一阶段的上界越大,影响我们的熵排序系统,影响域内适应过程。因此,在领域差距较大的情况下,我们的模型效率较低。由于其局限性,我们的模型性能受到dH(S, T)和εS(h)的影响。首先,源域和目标域的散度越大,dH(S, T)值越大。由于误差的上界较高,所以我们的模型的有效性较低。其次,当模型使用较小的神经网络时,εS(h)会很高。在这种情况下,我们的模型也会不那么有效。
数字分类:
该模型也适用于数字分类任务。我们考虑了MNIST→USPS、USPS→MNIST和SVHN→MNIST的适应变化。我们的模型是使用训练集进行训练的:MNIST有60000张图像,USPS有7291张图像,标准SVHN有73257张图像。提出的模型在标准测试集上进行了评估:MNIST(10,000幅图像)和USPS(2,007幅图像)。在数字分类任务中,Ginter和Gintra作为具有相同架构的分类器,该架构是基于LeNet架构的一个变体。在域间适应方面,我们利用CyCADA[11]框架对Ginter和Dinter进行训练。在排名阶段,我们利用Ginter生成所有目标数据的预测,并使用R(Xt)计算其排名分数。对于λ,我们在所有实验中都采用了λ = 0.8。我们的域内适配网络也是基于CyCADA[11]。在表4中,我们提出的模型在MNIST→USPS上的准确率达到95.8±0.1%,在USPS→MNIST上的准确率达到97.8±0.1%,在SVHN→MNIST上的准确率达到95.1±0.3%。我们的模型优于基线模型CyCADA[11]。
5.结论
在本文中,我们提出了一种自监督的领域自适应方法,以同时最小化域间和域内的差距。我们首先使用现有方法的域间适应性训练模型。其次,生成目标图像熵映射,利用基于熵的排序函数分割目标区域;最后,我们进行域内适应,以进一步缩小领域差距。我们在交通场景中对合成真实图像进行了广泛的实验。我们的模型可以与现有的领域适应方法相结合。实验结果表明,该模型的性能优于现有的自适应算法。
6.方法部分精简总结

参考文献
[1] Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adaptation. In NeurIPS, pages 137–144, 2007. 7
[2] Léon Bottou. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010, pages 177–186. Springer, 2010. 6
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. PAMI, 40(4):834–848, 2017. 6
[4] Minghao Chen, Hongyang Xue, and Deng Cai. Domain adaptation for semantic segmentation with maximum squares loss. In ICCV, pages 2090–2099, 2019. 2
[5] Yuhua Chen, Wen Li, and Luc Van Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In CVPR, pages 7892–7901, 2018. 5, 6
[6] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 5
[7] Shuyang Dai, Kihyuk Sohn, Yi-Hsuan Tsai, Lawrence Carin, and Manmohan Chandraker. Adaptation across extreme variations using unlabeled domain bridges. arXiv preprint arXiv:1906.02238, 2019. 2
[8] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. Ieee, 2009. 6
[9] Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective. IJCV, 111(1):98–136, 2015. 5
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016. 6
[11] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In ICML, pages 1989–1998, 2018. 1, 2, 8
[12] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 6
[13] Seokju Lee, Junsik Kim, Tae-Hyun Oh, Yongseop Jeong, Donggeun Yoo, Stephen Lin, and In So Kweon. Visuomotor understanding for representation learning of driving scenes. In BMVC, 2019. 1
[14] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015. 1
[15] Pauline Luc, Natalia Neverova, Camille Couprie, Jakob Verbeek, and Yann LeCun. Predicting deeper into the future of semantic segmentation. In ICCV, pages 648–657, 2017. 1
[16] Andres Milioto, Philipp Lottes, and Cyrill Stachniss. Realtime semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in cnns. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 2229–2235. IEEE, 2018. 1
[17] Zak Murez, Soheil Kolouri, David Kriegman, Ravi Ramamoorthi, and Kyungnam Kim. Image to image translation for domain adaptation. In CVPR, pages 4500–4509, 2018. 1
[18] Kwanyong Park, Sanghyun Woo, Dahun Kim, Donghyeon Cho, and In So Kweon. Preserving semantic and temporal consistency for unpaired video-to-video translation. In Proceedings of the 27th ACM International Conference on Multimedia, pages 1248–1257, 2019. 2
[19] Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. In ICCV, pages 1406–1415, 2019. 2
[20] Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors, ECCV, volume 9906 of LNCS, pages 102– 118. Springer International Publishing, 2016. 1, 5
[21] German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, pages 3234–3243, 2016. 1, 5
[22] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tatsuya Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, pages 3723–3732, 2018. 2
[23] Christos Sakaridis, Dengxin Dai, Simon Hecker, and Luc Van Gool. Model adaptation with synthetic and real data for semantic dense foggy scene understanding. In ECCV, pages 687–704, 2018. 2
[24] Alexey A Shvets, Alexander Rakhlin, Alexandr A Kalinin, and Vladimir I Iglovikov. Automatic instrument segmentation in robot-assisted surgery using deep learning. In 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 624–628. IEEE, 2018. 1
[25] Jong-Chyi Su, Yi-Hsuan Tsai, Kihyuk Sohn, Buyu Liu, Subhransu Maji, and Manmohan Chandraker. Active adversarial domain adaptation. In WACV, pages 739–748, 2020. 2
[26] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, pages 7472–7481, 2018. 1, 2, 3, 5, 6, 7
[27] Yi-Hsuan Tsai, Kihyuk Sohn, Samuel Schulter, and Manmohan Chandraker. Domain adaptation for structured output via discriminative patch representations. In ICCV, pages 1456– 1465, 2019. 1, 2
[28] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, pages 7167–7176, 2017. 8
[29] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Pérez. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In CVPR, pages 2517–2526, 2019. 2, 3, 5, 6, 7, 8
[30] Keze Wang, Dongyu Zhang, Ya Li, Ruimao Zhang, and Liang Lin. Cost-effective active learning for deep image classification. IEEE Transactions on Circuits and Systems for Video Technology, 27(12):2591–2600, 2016. 2
[31] Magnus Wrenninge and Jonas Unger. Synscapes: A photorealistic synthetic dataset for street scene parsing. arXiv preprint arXiv:1810.08705, 2018. 5
[32] Yang Zhang, Philip David, and Boqing Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, page 6, Oct 2017. 1, 2
[33] Amy Zhao, Guha Balakrishnan, Fredo Durand, John V Guttag, and Adrian V Dalca. Data augmentation using learned transformations for one-shot medical image segmentation. In CVPR, pages 8543–8553, 2019. 1
[34] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR, 2017. 1
[35] Han Zhao, Shanghang Zhang, Guanhang Wu, José MF Moura, Joao P Costeira, and Geoffrey J Gordon. Adversarial multiple source domain adaptation. In NIPS, pages 8559– 8570, 2018. 2
[36] Yi Zhou, Xiaodong He, Lei Huang, Li Liu, Fan Zhu, Shanshan Cui, and Ling Shao. Collaborative learning of semisupervised segmentation and classification for medical images. In CVPR, pages 2079–2088, 2019. 1
[37] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In ICCV, 2017. 2
[38] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In ECCV, pages 289–305, 2018. 2
[39] Yang Zou, Zhiding Yu, Xiaofeng Liu, B.V.K. Vijaya Kumar, and Jinsong Wang. Confidence regularized self-training. In ICCV, October 2019. 2