拯救消防员!AI提前30秒预测火灾闪燃;12个Python项目的全流程:从构思、执行到部署;『系统设计』面试资料大全;高性能图数据处理和嵌入的Rust/Python库 | ShowMeAI资讯日报

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
AI 或能拯救消防员,研究团队开发出可提前 30 秒预测闪燃的预测神经模型
https://doi.org/10.1016/j.engappai.2022.105258
近日,香港理工大学与国外研究机构发表了一篇利用 AI 完成消防任务的新研究『A spatial temporal graph neural network model for predicting flashover in arbitrary building floorplans』,开发出了一款名为 FlashNet 的预测神经模型,预测火灾中致命的『闪燃 flashover』现象——环境中几乎所有可燃物突然着火,令执行救火任务的消防员无法躲避。
在超过 41000 次的数字火灾模拟测试中,该模型提前 30 秒预测了闪燃的发生,并且准确率高达 92.1%,相关研究结果已发表在近期的《人工智能工程应用》杂志上。不过要将这一神经模型投入实际应用中,还有很长的路要走。

工具&框架
『Flet』开发网页、桌面端与移动应用的python工具库
https://github.com/flet-dev/flet
https://flet.dev/
Flet是一个框架,能帮助开发者基于 Python 轻松建立实时网络、移动端和桌面应用程序。重要的是,它无需任何前端经验,大家不再需要掌握复杂的 JavaScript 前端、REST API 后端、数据库、缓存等架构,只需用 Python 编写一个有状态的单体应用,就可以得到多用户、实时的单页应用(SPA)。
『pynapple』Python神经生理数据分析工具包
https://github.com/PeyracheLab/pynapple
https://peyrachelab.github.io/pynapple/notebooks/pynapple-quick-start/
pynapple 是一个用于神经生理学数据分析的轻量级 python 库。它提供了一套通用的工具来研究该领域的典型数据,包括时间序列(尖峰时间、行为事件等)和时间间隔(试验、大脑状态等)。它还为用户提供了神经科学的通用功能,如调谐曲线和交叉重合图。
『GRAPE』一个用于高性能图数据处理和嵌入的Rust/Python库
https://github.com/AnacletoLAB/grape
https://anacletolab.github.io/grape/index.html
GRAPE(Graph Representation leArning, Predictions and Evaluation)是一个快速的图处理和嵌入库,希望提高大型图数据上的伸缩能力,让其在现成的笔记本电脑和台式电脑或者高性能计算工作站集群上都可以运行。工具库用Rust和Python编程语言编写,由AnacletoLAB(米兰大学计算机科学系),Robinson实验室-杰克逊基因组医学实验室和BBOP-劳伦斯伯克利国家实验室合作开发。

博文&分享
『System Design』分享:系统设计面试准备资料
https://github.com/codersguild/System-Design
https://codersguild.github.io/System-Design/
系统设计是一个非常广泛的话题。即使是一个在顶级IT公司有多年工作经验的软件工程师也不一定是系统设计的专家。如果你想成为专家,你需要阅读许多书籍、文章,并解决真正的大规模系统设计问题。本资源库以简洁的方式总结梳理了系统设计面试中的诸多问题。

『Practical Python Projects』实用Python项目书籍,讲解项目从构思、执行到最终部署的一切
https://practicalpython.yasoob.me/
https://practicalpython.yasoob.me/toc.html
在学习编程时,大多数书籍、网站和教程都侧重于讲解语法细节,并不重视创建和实施端到端项目,本书将尝试解决这个问题——讲解项目从构思、执行到最终部署的一切。全书共 12 章,包含 12 个项目的代码,不仅可以展示完整实现流程,还可以激发项目创意、丰富工程经验。
- Twilio 机器人,随时了解 FIFA 世界杯的最新比赛比分
- Facebook Messenger 机器人,分享从 Reddit 上抓取的最新笑话
- 自动发票生成器,并使用 Flask 进行部署
- 通过使用 moviepy下载并拼接相关电影预告片,来制作自动电影预演
- 生成自动文章摘要,并将其覆盖在图像之上
- 使用 vanilla Python 理解和解码 JPEG 图像
- 使用 PyQt 创建下载在线视频的 GUI 应用程序
- 实现 TUI 电子邮件客户端,允许在终端中阅读电子邮件

数据&资源
『Awesome Vision Transformer Collection 』视觉Transformer及其下游任务相关工作资源大列表
https://github.com/GuanRunwei/Awesome-Vision-Transformer-Collection
本资源列表包括Vision Transformer的各种变种,以及其下游各类任务解决方案。资源列表包含:
- Image Backbone / 图像骨干网络
- Multi-label Classification / 多标签分类
- Point Cloud Processing / 点云处理
- Video Processing / 视频处理
- Model Compression / 模型压缩
- Transfer Learning & Pretraining / 迁移学习和预训练
- Multi-Modal / 多模态
- Detection / 检测
- Segmentation / 分割
- Pose Estimation / 姿势估计
- Tracking and Trajectory Prediction / 跟踪和轨迹预测
- Generative Model and Denoising / 生成模型和去噪
- Self-Supervised Learning / 自监督学习
- Depth and Height Estimation / 深度和高度估计
- Explainable / 可解释性
- Robustness / 稳健性
- Deep Reinforcement Learning / 深度强化学习
- Calibration / 校准
- Radar / 雷达
- Traffic / 交通
- AI Medicine / 人工智能医学
- Hardware / 硬件

研究&论文

可以点击 这里 回复关键字日报,免费获取整理好的论文合辑。
公众号回复关键字日报,免费获取整理好的论文合辑。
科研进展
- 2022.07.15 『图像生成』WaveGAN: Frequency-aware GAN for High-Fidelity Few-shot Image Generation
- 2022.07.25 『单目深度估计』MonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer
- 2022.08.02 『文本到图像生成』An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- 2022.08.10 『语言模型』Language Supervised Training for Skeleton-based Action Recognition
⚡ 论文:WaveGAN: Frequency-aware GAN for High-Fidelity Few-shot Image Generation
论文时间:15 Jul 2022
领域任务:Image Generation,图像生成
论文地址:https://arxiv.org/abs/2207.07288
代码实现:https://github.com/kobeshegu/eccv2022_wavegan
论文作者:Mengping Yang, Zhe Wang, Ziqiu Chi, Wenyi Feng
论文简介:Concretely, we disentangle encoded features into multiple frequency components and perform low-frequency skip connections to preserve outline and structural information./具体来说,我们将编码的特征分解成多个频率成分,并进行低频跳接以保留轮廓和结构信息。
论文摘要:现有的几张照片的生成方法通常采用基于融合的策略,无论是在图像还是在特征层面,以产生新的图像。然而,以前的方法难以合成具有精细细节的高频信号,使合成质量下降。为了解决这个问题,我们提出了WaveGAN,一个用于生成少量图像的频率感知模型。具体来说,我们将编码的特征分解成多个频率分量,并进行低频跳接(skip connection)以保留轮廓和结构信息。然后,我们通过采用高频跳过连接来减轻生成器在合成精细细节方面的困难,从而为生成器提供信息丰富的频率信息。此外,我们在生成的图像和真实的图像上利用频率L1-loss来进一步阻碍频率信息的损失。大量的实验证明了我们的方法在三个数据集上的有效性和先进性。值得注意的是,我们在Flower、Animal Faces和VGGFace上分别取得了FID 42.17、LPIPS 0.3868、FID 30.35、LPIPS 0.5076和FID 4.96、LPIPS 0.3822的先进水平。GitHub: https://github.com/kobeshegu/ECCV2022_WaveGAN



⚡ 论文:MonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer
论文时间:6 Aug 2022
领域任务:Monocular Depth Estimation,单目深度估计
论文地址:https://arxiv.org/abs/2208.03543
代码实现:https://github.com/zxcqlf/monovit
论文作者:Chaoqiang Zhao, Youmin Zhang, Matteo Poggi, Fabio Tosi, Xianda Guo, Zheng Zhu, Guan Huang, Yang Tang, Stefano Mattoccia
论文简介:Self-supervised monocular depth estimation is an attractive solution that does not require hard-to-source depth labels for training./自监督的单目深度估计是一个有吸引力的解决方案,它不需要用于训练的硬源深度标签。
论文摘要:自监督的单目深度估计是一个有吸引力的解决方案,它不需要用于训练的硬源深度标签。卷积神经网络(CNN)最近在这项任务中取得了巨大成功。然而,它们有限的感受野限制了现有的网络结构只能进行局部推理,抑制了自监督范式的有效性。鉴于视觉Transformer(ViTs)最近取得的成功,我们提出了MonoViT,这是一个全新的框架,将ViT模型的全局推理与自监督的单目深度估计的灵活性相结合。通过将普通卷积与Transformer块相结合,我们的模型可以进行局部和全局推理,产生更高层次的细节和准确性的深度预测,使MonoViT在既定的KITTI数据集上取得最先进的性能。此外,MonoViT在其他数据集(如Make3D和DrivingStereo)上证明了其卓越的泛化能力。

⚡ 论文:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
论文时间:2 Aug 2022
领域任务:Text to image generation, Text-to-Image Generation,文本到图像生成
论文地址:https://arxiv.org/abs/2208.01618
代码实现:https://github.com/rinongal/textual_inversion
论文作者:Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
论文简介:Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes./然而,目前还不清楚如何行使这种自由来生成特定的独特概念的图像,修改它们的外观,或将它们组成新的角色和新的场景。
论文摘要:文本-图像模型提供了前所未有的自由,通过自然语言指导创作。然而,目前还不清楚如何行使这种自由来生成特定的独特概念的图像,修改它们的外观,或将它们组成新的角色和新的场景。换句话说,我们要问:我们如何利用语言引导的模型把我们的猫变成一幅画,或者在我们最喜欢的玩具的基础上想象一个新产品?在这里,我们提出了一个简单的方法,允许这种创造性的自由。只需使用3-5张用户提供的概念的图片,比如一个物体或一种风格,我们就可以在一个冻结的文本-图像模型的嵌入空间中学习通过新的 "词 "来表现它。这些 "词 "可以组成自然语言的句子,以直观的方式指导个性化的创作。值得注意的是,我们发现有证据表明,单个词的嵌入足以捕捉到独特和多样的概念。我们将我们的方法与广泛的基线进行比较,并证明它能更忠实地描绘一系列应用和任务中的概念。我们的代码、数据和新词将在以下网站提供:https://textual-inversion.github.io


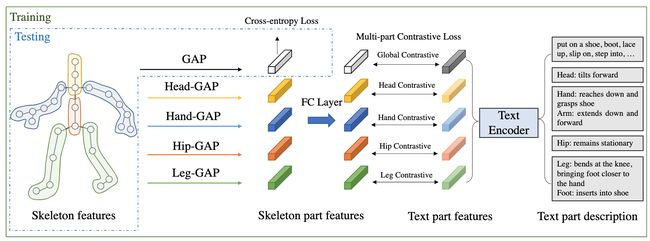
⚡ 论文:Language Supervised Training for Skeleton-based Action Recognition
论文时间:10 Aug 2022
领域任务:Action Recognition, Language Modelling, 动作检测,语言模型
论文地址:https://arxiv.org/abs/2208.05318
代码实现:https://github.com/martinxm/lst
论文作者:Wangmeng Xiang, Chao Li, Yuxuan Zhou, Biao Wang, Lei Zhang
论文简介:More specifically, we employ a large-scale language model as the knowledge engine to provide text descriptions for body parts movements of actions, and propose a multi-modal training scheme by utilizing the text encoder to generate feature vectors for different body parts and supervise the skeleton encoder for action representation learning./更具体地说,我们采用大规模的语言模型作为知识引擎,为动作的身体部位运动提供文本描述,并提出了一种多模式的训练方案,利用文本编码器生成不同身体部位的特征向量,监督骨架编码器进行动作表示学习。
论文摘要:基于骨架的动作识别因其计算效率和对光照条件的鲁棒性而引起了广泛的关注。现有的基于骨架的动作识别方法通常被表述为单次分类任务,没有充分利用动作之间的语义关系。例如,"做胜利的手势 "和 "竖起大拇指 "是两个手势动作,其主要区别在于手的运动。这一信息与动作类别的分类一热编码无关,但可以在动作的语言描述中被揭示出来。因此,在训练中利用动作语言描述有可能有利于表征学习。在这项工作中,我们为基于骨架的动作识别提出了一种语言监督训练(LST)方法。更具体地说,我们采用一个大规模的语言模型作为知识引擎,为动作的身体部位运动提供文本描述,并提出一个多模式的训练方案,利用文本编码器生成不同身体部位的特征向量,监督骨架编码器进行动作表示学习。实验表明,我们提出的LST方法比各种基线模型取得了明显的改进,而且在推理时没有额外的计算成本。LST在流行的基于骨架的动作识别基准上达到了新的水平,包括NTU RGB+D、NTU RGB+D 120和NW-UCLA。该代码可以在 https://github.com/MartinXM/LST 获取。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~