CenterNet目标检测模型及CenterFusion融合目标检测模型
CenterNet是一种端到端的基于free-anchor的目标检测模型,其继承自CornerNet目标检测模型,可以很容易迁移到例如3D目标检测和人体关键点检测等任务。该模型发表自2019年,在MS COCO 数据集上在速度与准确率方面取得了最好的平衡, 142 FPS时有28.1% AP , 52 FPS时有37.4% AP,多尺度测试时可以达到45.1% AP和 1.4 FPS。CenterNet并没有完全超越STOA,而是在速度和精度之间的一种平衡。
CenterFusion是一种通过融合毫米波雷达数据和可见光相机数据进行3D目标检测模型,其包含一个CenterNet的3D目标检测子网络,该模型属于中端融合模型,其发表于2021的WACV,论文名称 “CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection“,作者在nuScenes数据集上评估了该方法,使用了challenging 3D检测基准,结果该方法比其他最优的基于图像的目标检测算法效果都好!
CenterNet论文:https://arxiv.org/abs/1904.07850
CenterNet代码:https://github.com/xingyizhou/CenterNet
CenterFusion论文:https://arxiv.org/pdf/2011.0484
CenterFusion代码:https://github.com/mrnabati/CenterFusion
一、CenterNet目标检测模型
CenterNet是端到端的无anchor的模型,采用编码器+解码器的沙漏型结构,上采样前均采用了可变形卷积模块,上采样均采用转置卷积,最终输出矩阵的分辨率是输入图片的1/4,具有更高的输出分辨率,所以不用采用fpn的结构进行多尺度输出,由于该模型直接回归出目标物的中心点坐标和宽高,不再采用anchor,所以也不用耗时的nms等后处理手段【2】。
1. 网络结构
模型的基本结构如下图所示【1】,该模型主干为一层一层的卷积网络层,输出包含3个head,分别对应深度为nclass的类别、深度为2的中心点偏移量、深度为2的宽高。每个head的空间分辨率是输入图片的1/4,如下图输入图片是3*512*512,输出矩阵是80*128*128、2*128*128、2*128*128。
 论文中使用了3种backbone做对比实验,结论是:
论文中使用了3种backbone做对比实验,结论是:
a:Hourglass沙漏网络,45.1% COCO AP and 1.4 FPS。
b:ResNet,同时增加转置卷积(deformable conv),28.1% COCO AP and 142 FPS。
c:原始的DLA-34语义分割网络。
d:修改过的DLA-34,增加了FPN结构,37.4% COCO AP and 52 FPS。
所以DLA-34是一种比较折中的选择,这里的DLA-34并非原生模型,原生模型的输出分辨率是输入分辨率的1/2,且没有使用可变形卷积和最后的FPN结构【7】。
2. 模型推理
模型的前向推理结构和训练结构如下图所示【3】,输入图片经过层层卷积得到三个矩阵,分别对应着类别、中心点偏移量和宽高。后处理过程为:
1. 对类别矩阵进行sigmoid操作和3*3的即8邻域范围内的极大值提取,该操作通过MaxPooling实现,实现代码见【6】,该操作代替了base-anchor中的nms操作,所以该模型不需要耗时的nms操作,据说把3*3的极大值提取更换为5*5或者7*7,mAP能有轻微提升【6】。为了说明CenterNet不依赖NMS,作者做了实验,发现在DLA-34上使用NMS比不使用NMS,AP从39.2%提升到39.7%;Hourglass-104则没有提升,保持在42.2%,所以CenterNet可以不用NMS【0】;
2. 在类别矩阵中从每一类的热力图矩阵中找到值最大的前100个点,组合不同类别后,寻找值大于响应阈值的热力图点,筛选后获得的所有热力图点就是模型所检测到的所有目标的中心点;
3. 通过每个目标物的中心点坐标在中心点偏移矩阵和宽高矩阵中寻找中心点偏移量和bbox的宽高。经过以上步骤后便可以得到所有被检测目标物的bbox。
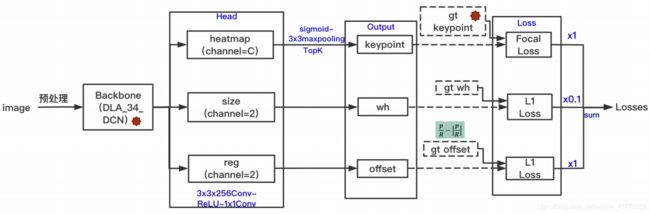
3. 模型训练
为了训练模型需要三步:第一步确定target输出,第二步设计loss函数,第三步根据loss数值计算梯度并更新模型。
关于类别矩阵的target输出形式,如下图所示【4】,在每个目标物的几何中心处设置一个高斯圆,高斯圆的峰值是1,方差通过目标物的大小进行计算【1】,类别矩阵heatmap上的关键点之所以采用二维高斯核来表示,是由于对于在目标中心点附近的一些点,期预测出来的box和gt_box的IOU可能会大于0.7,不能直接对这些预测值进行惩罚,需要温和一点,所以采用高斯核。

关于中心点偏移量矩阵和宽高矩阵的target输出,首先需要在类别矩阵中目标范围内找到几个极值点,计算这些极值点到目标中心真值的距离,进而得到中心点偏移量矩阵的target输出,在这些极值点的对应坐标处设置目标物宽高,进而得到宽高矩阵的target输出。(该段内容需要再去代码中核实,本段内容为猜测,也有可能是在中心点附近一片范围内均设置中心点偏移量和宽高)
得到三个target输出矩阵后,需要设置相应的loss函数,中心点偏移量和宽高矩阵均采用L1损失函数,这个没必要详细介绍,需要详细介绍的是类别热力图的损失函数,该损失函数为变形的Focal Loss函数,具体函数形式如下所示【3】

这里有很多需要讲解的地方,首先解释下交叉熵损失函数的来源,如果一个事件的发生概率是p,那这个事件的信息量是-log p,一个完备事件中所有事件的信息量期望就是这个完备事件的信息熵![]() 。描述两个完备事件的相似度的方式是KL散度,经过公式推导,KL散度等于A完备事件的信息熵减去A完备事件与B完备事件的交叉熵。我们应用时一般把A作为真值,B作为预测值,那A的信息熵是固定值,所以评价预测值与真值的相似度的度量便从计算KL散度等效到计算预测值与真值的交叉熵。所以评价预测值q与真值p的相似度的度量是
。描述两个完备事件的相似度的方式是KL散度,经过公式推导,KL散度等于A完备事件的信息熵减去A完备事件与B完备事件的交叉熵。我们应用时一般把A作为真值,B作为预测值,那A的信息熵是固定值,所以评价预测值与真值的相似度的度量便从计算KL散度等效到计算预测值与真值的交叉熵。所以评价预测值q与真值p的相似度的度量是![]() ,注意预测值和真值都必须是一个完备事件,所以必须有求和符号。
,注意预测值和真值都必须是一个完备事件,所以必须有求和符号。
在我们常用的分类模型中,我们经常把每个神经元的输出看做是一个完备事件(即每个神经元输出都通过一个sigmoid函数处理),不同神经元输出之间隶属于不同的完备事件,那分类模型整体的损失函数就是![]() ,第一个求和函数是求和所有的神经元输出,第二个求和函数是对完备事件的所有可能事件进行求和,而大部分情况下,每个神经元都是一个二分类神经元,所以分类模型整体的损失函数就是
,第一个求和函数是求和所有的神经元输出,第二个求和函数是对完备事件的所有可能事件进行求和,而大部分情况下,每个神经元都是一个二分类神经元,所以分类模型整体的损失函数就是![]() ,在大部分情况下,我们用0和1来表示真值的两种情况,所以我们最常见的交叉熵损失函数便出现了,即真值为1时
,在大部分情况下,我们用0和1来表示真值的两种情况,所以我们最常见的交叉熵损失函数便出现了,即真值为1时![]() ,真值为0时
,真值为0时![]() ,在这两项前面分别加入调整正负样本数量不均衡的参数和调整难易样本权重的系数便是focal Loss了。但是,一定要注意这种loss是建立在每个神经元的输出是一个0/1的二分类器的情况下,如果每个神经元不是离散分类,那就不能使用交叉熵损失函数,例如线形回归问题一般使用L1或L2损失函数;如果每个神经元不是0/1分类,而是其他介于0~1之间的数值,那必须使用
,在这两项前面分别加入调整正负样本数量不均衡的参数和调整难易样本权重的系数便是focal Loss了。但是,一定要注意这种loss是建立在每个神经元的输出是一个0/1的二分类器的情况下,如果每个神经元不是离散分类,那就不能使用交叉熵损失函数,例如线形回归问题一般使用L1或L2损失函数;如果每个神经元不是0/1分类,而是其他介于0~1之间的数值,那必须使用![]() 函数形式,这个形式也可以按照focal loss进行修改,例如常用的label smoothing手段,就需要用这种形式的损失函数;如果不是把每个神经元的多次输出看做一个完备事件,而是把所有神经元同一次的输出看做一个完备事件(即所有神经元的输出统一通过softmax进行处理),那一个输入数据单次推理的损失就是
函数形式,这个形式也可以按照focal loss进行修改,例如常用的label smoothing手段,就需要用这种形式的损失函数;如果不是把每个神经元的多次输出看做一个完备事件,而是把所有神经元同一次的输出看做一个完备事件(即所有神经元的输出统一通过softmax进行处理),那一个输入数据单次推理的损失就是![]() ,只包含一个求和符号,表示的是所有神经元输出求和。
,只包含一个求和符号,表示的是所有神经元输出求和。
在CenterNet中,相比标准focal loss,在下面一行中多了![]() ,且热力图中有一部分真值介于0~1之间,在上面公式中,当为
,且热力图中有一部分真值介于0~1之间,在上面公式中,当为![]() 为1时,loss等于上面一行,是标准的focal loss正向损失;当
为1时,loss等于上面一行,是标准的focal loss正向损失;当![]() 为0时,是下面一行去除
为0时,是下面一行去除![]() 的结果,是标准的focal loss负向损失;当
的结果,是标准的focal loss负向损失;当![]() 介于0~1之间时,按照上面的分析,属于非0/1二分类问题,所以标准的损失函数是
介于0~1之间时,按照上面的分析,属于非0/1二分类问题,所以标准的损失函数是![]() ,而在CenterNet中并没有使用这种标准形式,而是采用了负向损失乘以权重系数的形式,权重系数就是
,而在CenterNet中并没有使用这种标准形式,而是采用了负向损失乘以权重系数的形式,权重系数就是![]() 。原因有两点,第一点,虽然
。原因有两点,第一点,虽然 ![]() 是介于0~1之间数值x,但是我们希望这个完备事件的概率之和就是x而不是1,即正事件的概率(或表示)是x,负事件的概率(或表示)是0,或者说,这些神经元输出并不是一个完备事件,不能用KL散度来描述,所以不能用标准focal loss来计算损失;第二点,如果仅仅采用负向损失来描述
是介于0~1之间数值x,但是我们希望这个完备事件的概率之和就是x而不是1,即正事件的概率(或表示)是x,负事件的概率(或表示)是0,或者说,这些神经元输出并不是一个完备事件,不能用KL散度来描述,所以不能用标准focal loss来计算损失;第二点,如果仅仅采用负向损失来描述 ![]() 介于0~1之间神经元损失,显然是不合适的,负向损失描述的是神经元输出趋向于0的程度,而不是趋向于x的程度,所以x数值越大,用负向损失描述loss的误差越大,当x数值趋近于0时,用负向损失描述loss的误差也趋近于0,为了解决这一问题,作者在负向损失前增加了一个权重系数
介于0~1之间神经元损失,显然是不合适的,负向损失描述的是神经元输出趋向于0的程度,而不是趋向于x的程度,所以x数值越大,用负向损失描述loss的误差越大,当x数值趋近于0时,用负向损失描述loss的误差也趋近于0,为了解决这一问题,作者在负向损失前增加了一个权重系数![]() ,当x数值很大时,即loss的误差很大时,该系数很小,减小了这个误差很大的loss在总loss中的占比,当x数值很小时,即loss的误差很小时,该系数很大,增大了这个误差很大的loss在总loss中的占比。以上便是对CenterNet中损失函数的分析,感觉对于类别损失函数中真值介于0~1之间的部分有优化的空间。关于这个损失函数还有类似的其他版本的解释【0】
,当x数值很大时,即loss的误差很大时,该系数很小,减小了这个误差很大的loss在总loss中的占比,当x数值很小时,即loss的误差很小时,该系数很大,增大了这个误差很大的loss在总loss中的占比。以上便是对CenterNet中损失函数的分析,感觉对于类别损失函数中真值介于0~1之间的部分有优化的空间。关于这个损失函数还有类似的其他版本的解释【0】
有了损失函数以后,按照一定比例组合不同Head的loss得到总的loss,然后进行反向训练,变实现了模型的训练。在论文中,作者还对训练推理过程图片分辨率,回归Loss是选L1还是Smooth L1,各个Loss的权重,训练策略做了实验说明。
4. 模型优劣
CenterNet模型的优点是输出分辨率高,不需要多分辨率输出和nms结构,不需要设置anchor的超参,是端到端的模型,实现了精度和速度的更好的平衡,其模型结构很容易扩展到3D目标检测和人体骨架检测等任务。缺点是两个目标中心点重合时,网络是不能有效区分的,针对这个问题,作者统计了COCO数据集中在下采样4倍以后,发生这样情况的概率,最终得到的结果是小于0.1%,作者认为比例不是很高,CenterNet整体效果好,瑕不掩瑜。当然这是作者在COCO数据集上的分析,CenterNet天生存在,实际应用过程中,我们还得结合自己的数据集做具体分析,可以通过多分辨率输出等方式尝试解决。
5. anchor_based和anchor_free优缺点
CenterNet模型是一个anchor_free的模型,常用的yolov5v6是anchor_based模型,他们各有优缺点【8】。
anchor based
优点
1. 使用anchor机制产生密集的anchor box,使得网络可直接在此基础上进行目标分类及边界框坐标回归。加入先验,训练更容易更稳定。
2. 密集的anchor box可有效提高网络目标召回能力,对于小目标检测来说提升非常明显。
缺点
1. anchor机制中,需要设定的超参,这需要较强的先验知识。
2. 冗余框非常之多,一张图像内的目标毕竟是有限的,基于每个anchor设定大量anchor box会产生大量的负样本,即完全不包含目标的背景框。这会造成正负样本严重不平衡问题,也是one-stage算法难以赶超two-stage算法的原因之一。
3. 网络实质上是看不见anchor box的,在anchor box的基础上进行边界回归更像是一种在范围比较小时候的强行记忆。
4. 基于anchor box进行目标类别分类时,IOU阈值超参设置也是一个超参问题。
anchor free
优点
1. 更大更灵活的解空间、摆脱了使用anchor而带来计算量从而让检测和分割都进一步走向实时高精度
缺点
1. 正负样本极端不平衡
2. 语义模糊性(两个目标中心点重叠),现在这两者大多是采用Focus Loss和FPN来缓解的,但并没有真正解决。
3. 检测结果不稳定,需要设计更多的方法来进行re-weight
对比
anchor-free和anchor-based实际上最大的区别应该是解空间上的区别。anchor-free本质上都是dense prediction的方法,庞大的解空间使得简单的anchor-free的方法容易得到过多的false positive,而获得高recall但是低precision的检测结果;anchor-based由于加入了人为先验分布,同时在训练的时候prediction(尤其是regression)的值域变化范围实际上是比较小的,这就使得anchor-based的网络更加容易训练也更加稳定。
6. 扩展
CenterNet模型很容易扩展到3D目标检测和人体骨架检测等任务。
姿态估计:
将目标类别数量设置为17,对应人体姿态估计的17 个关键点,预测17维的热力图得到所有17类别的中心点,然后回归一个34(2*17)维的每个人体中心点到17个关键点的偏移值(因为有17 个x,y坐标偏移),人体中心点加上这个34 维的偏移量可以得到每个物体的17个关键点,再将17维的热力图中心点分配到距离最近的每个人体上,再回归一个二维的关键点偏移量作为最终的准确关键点。
3D目标检测:
这里回归的将是3维的box size, 加上一个1维的深度,和一个8维的方向,最终得到3D box。
二、CenterFusion融合目标检测模型
自动驾驶汽车的感知系统负责对周围环境进行检测和跟踪物体。这个通常通过利用多种传感方式来提高鲁棒性和准确性,这使得传感器融合成为感知系统的关键部分。
本文针对毫米波雷达和相机传感器的融合问题,提出了一种利用毫米波雷达和摄像机数据进行三维目标检测的中间融合方法。我们称为CenterFusion的方法首先使用中心点检测网络,通过识别图像上的中心点来检测对象。然后利用一种新的基于视锥的方法来解决关键的数据关联问题,将毫米波雷达探测到的目标与其对应的目标中心点关联起来。相关的毫米波雷达检测用于生成基于雷达的特征图,以补充图像特征,并回归到目标的深度、旋转和速度等属性。【9】
论文主要贡献:
1、论文提出了CenterFusion,一种利用毫米波雷达和摄像机数据进行三维目标检测的中间融合方法。
2、CenterFusion的重点是将毫米波雷达检测与从图像中获得的初步检测结果关联起来,然后生成雷达特征图,并将其与图像特征一起用于精确估计物体的三维边界框。
3、论文使用关键点检测网络生成初步的三维检测结果,并提出了一种新的基于截锥的雷达关联方法,以准确地将毫米波雷达检测与三维空间中的相应目标关联起来。然后,这些雷达检测被映射到图像平面,并用于创建特征映射,以补充基于图像的特征。最后,利用融合后的特征精确估计物体的三维属性,如深度、旋转和速度。
1. 数据来源【10】
相机和激光雷达:
- 相机和激光雷达对于恶劣环境都很敏感,会大大降低 fov 和感知效果。
- 相机和激光雷达在没有时间信息的情况下,不能检测物体的速度。
- 在时间紧迫的情况下,依赖时间信息可能不是一个可行的解决方案。
毫米波雷达:
- 毫米波雷达在极端环境下的鲁棒性很好,且能检测非常远的距离。
- 毫米波雷达使用多普勒效应能够准确的估计所有检测无的速度,且不需要依赖时间信息。
- 与激光雷达相比,雷达点云在用作目标检测结果之前需要的处理更少。
- 由于激光雷达与雷达点云的内在差异,将现有的基于激光雷达的算法应用到雷达点云中或对其进行自适应是非常困难的。
- 雷达点云明显比激光雷达的对应部分稀疏,这使得它无法用于提取目标的几何信息。
- 聚合多个雷达扫描会增加点的密度,但也会给系统带来延迟。
- 没有 z 轴信息,有也不准。
- 只能识别动态目标,对于静态目标容易错检。
2. 网络结构
CenterFusion的网络结构如下图所示,该模型的主体结构就是一个CenterNet模型,相比原生CenterNet模型,只是多了一个特征融合层和新的几个head而已。

3. 模型推理

从上面的流程图可以看出,输入可见光图片首先经过CenterNet模型,完成基于图像的2D和3D预测,得到目标物的中心点热力图、中心点偏移量、2D宽高、3D维度、距离和旋转角度,其中,中心点热力图、中心点偏移量、2D宽高、3D维度就是最终输出,不会再次预测,(这一步操作对应流程图中左上部分)。同步的,需要对毫米波雷达数据进行Pillar Expansion操作【11】,然后通过自车坐标系关联关系,将刚刚模型预测的物体范围映射到毫米波雷达数据中,在这个物体范围内提取毫米波雷达数据,这在论文中称之为RoI截锥关联方法,示意图如下图【12】,(这一步操作对应流程图中左下部分)。从物体截锥体范围内提取的毫米波雷达数据就是深度信息和速度信息,将radar的深度和速度信息,作为图像的补充特征,生成3个热力图通道 d, vx, vy【11】,将这3个新的热力图通道与之前CenterNet模型的bachbone的输出特征沿深度维拼接在一起,如此便实现了毫米波雷达信息与可见光相机数据的中段融合,(这一步操作对应流程图中中间部分的img+Rad Features)。在这个新的特征的基础上加入4个head实现对深度、速度、旋转角度和属性的预测,(这一步操作对应流程图中右下部分)。最后将第一次纯可见光图片的预测结果与第二次融合毫米波雷达数据后的预测结果进行联合解析,得到最终输出结果,(这一步操作对应流程图中右上部分)。

在nuScenes数据集上应用评估,在3D目标检测标签下,比之前所有基于Camera的目标检测方法都要好!!! 利用radar信息,提高目标的速度检测精度,不使用任何时间信息 !!!部分代码解析可见【13】
三、参考
0. Centernet论文详解
1. CenterNet原理详解
2. 超越yolov3,Centernet 原理详解(object as points)
3. [目标检测]CenterNet
4. CenterNet(Object as Points)
5. 论文也撞衫,你更喜欢哪个无锚点CenterNet?
6. CenterNet测试推理过程
7. DLA模型(分类模型+改进版分割模型) + 可变形卷积
8. 目标检测之anchor_based和anchor_free优缺点
9. CenterFusion: 基于Radar和Camera融合的3D检测算法
10. 雷达相机融合:CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection
11. 【论文笔记】CenterFusion:Radar+Camera融合
12. CenterFusion 项目网络架构详细论述
13. 多传感器融合目标检测系列:CenterFusion(基于CenterNet)源码深度解读: :DLA34 (四)