Hadoop 完全分布式(3.1.3)部署(清爽版)
1. Hadoop部署
1.1 集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器。
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HSFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
1.2 上传hadoop压缩包到集群
使用 xftp 或 其他工具,上传压缩包到 /opt/software/
1.3 解压hadoop
# 进入到 /opt/software
[harry@hadoop102 module]cd /opt/software
# 解压 注意:/opt/module 需要提前创建好
[harry@hadoop102 module]tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
1.4 重命名(可选)
[harry@hadoop102 module]mv /opt/module/hadoop-3.1.3 /opt/module/hadoop
1.5 配置环境变量
# 用vim编辑器(没有的话就vi)打开 /etc/profile.d/my_env.sh
[harry@hadoop102 module]sudo vim /etc/profile.d/my_env.sh
# 添加以下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 保存退出
:wq
1.6 分发环境变量
[harry@hadoop102 module]scp /etc/profile.d/my_env.sh hadoop103:/etc/profile.d/
[harry@hadoop102 module]scp /etc/profile.d/my_env.sh hadoop104:/etc/profile.d/
1.7 生效环境变量
[harry@hadoop102 module]$ source /etc/profile.d/my_env.sh
[harry@hadoop103 module]$ source /etc/profile.d/my_env.sh
[harry@hadoop104 module]$ source /etc/profile.d/my_env.sh
2. 配置集群
2.1 core-site.xml
# 编辑core-site.xml
[harry@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[harry@hadoop102 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop102:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>harryvalue>
property>
<property>
<name>hadoop.proxyuser.harry.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.harry.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.harry.usersname>
<value>*value>
property>
configuration>
2.2 hdfs-site.xml
# 编辑hdfs-site.xml
[harry@hadoop102 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop102:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop104:9868value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
configuration>
2.3 yarn-site.xml
# 编辑yarn-site.xml
[harry@hadoop102 hadoop]$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop103value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>512value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>4096value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>4096value>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>truevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
configuration>
2.4 mapred-site.xml
# 编辑mapred-site.xml
[harry@hadoop102 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
2.5 workers
# 编辑workers
[harry@hadoop102 hadoop]$ vim workers
# 注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop102
hadoop103
hadoop104
3. 配置历史服务器(可选)
3.1 mapred-site.xml
[harry@hadoop102 hadoop]$vim mapred-site.xml
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop102:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop102:19888value>
property>
4. 配置日志的聚集(可选)
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
4.1 yarn-site.xml
[harry@hadoop102 hadoop]$vim yarn-site.xml
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://hadoop102:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
5. 分发Hadoop
[harry@hadoop102 hadoop]$scp -r /opt/module/hadoop hadoop103:/opt/module/
[harry@hadoop102 hadoop]$scp -r /opt/module/hadoop hadoop104:/opt/module/
6. 启动Hadoop集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[harry@hadoop102 hadoop]$ bin/hdfs namenode -format
(2)启动HDFS
[harry@hadoop102 hadoop]$ sbin/start-dfs.sh
(3)在配置了ResourceManager的节点(hadoop103)启动YARN
[harry@hadoop103 hadoop]$ sbin/start-yarn.sh
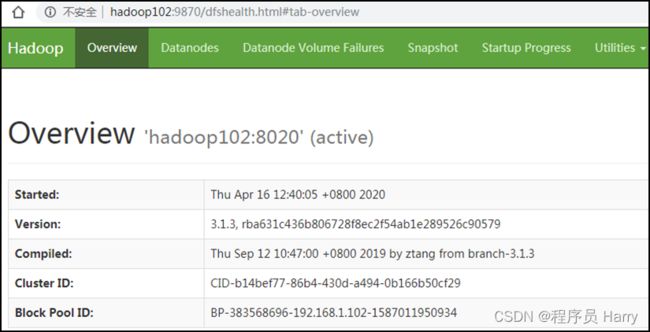
(4)Web端查看HDFS的Web页面:http://hadoop102:9870/ 或 http://(hadoop102 ip 地址):9870/
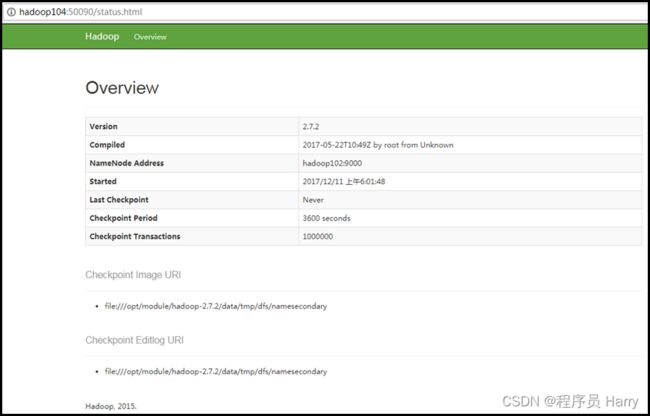
(5)Web端查看SecondaryNameNode 浏览器中输入:http://hadoop104:9868/status.html
7. 群起脚本(可选)
[harry@hadoop102 bin]$ pwd
/home/harry/bin
[harry@hadoop102 bin]$ vim hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
# 赋予权限
[harry@hadoop102 bin]$ chmod 777 hdp.sh