hadoop完全分布式搭建(最通俗易懂)
1、首先创建好虚拟机并且上传jdk,hadoop到虚拟机上
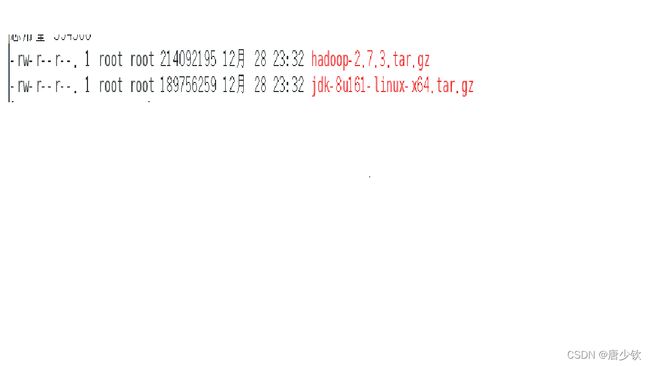 这边我上传的位置为/opt/module 下,并将其解压到/opt/software下并且重命名为hadoop和jdk
这边我上传的位置为/opt/module 下,并将其解压到/opt/software下并且重命名为hadoop和jdk
2、设置好ip地址、主机名
设置ip地址首先点击vm上的编辑按钮下虚拟网络编辑器查看VMnet8的ip地址是多少,例如我这ip地址为192.168.119.0,那么我的hadoop的ip地址前3位就需要设置为192.168.119,然后进入我们的虚拟机里面进行ip地址的设置,输入命令vi /etc/sysconfig/network-scripts/ifcfg-ens33 进行ip地址的设置

第一步设置为静态获取,更改BOOTPROTO=static
第二步添加IP地址,在最下方添加IPADDR=192.168.119.50 注:IP地址最后一位取决你的网段分配情况,不是随便填写,随便填写很有可能导致不能联网。
第三步添加网关地址,添加GATEWAY=192.168.119.2
第四步添加子网掩码,添加NETMASK=255.255.255.0
第五步添加DNS地址,添加DNS1=114.114.114.114
设置完毕后按键盘上的esc键然后按下shift+;输入wq进行保存退出
退出后,输入命令进行网卡重置 systemctl restart network
再输入ifconfig查看IP地址是否设置成功
IP地址设置完成后设置自己的主机号,这里我将主机号设置为了hadoop101,主机号不做要求可按自己的想法去进行设置。
输入命令 hostnamectl set-hostname hadoop101进行主机号的设置
3、进行虚拟机的克隆
首先对当前虚拟机进行关机操作,然后右击虚拟机下的管理下的克隆,克隆分为两种,一种是创建链接克隆,一种是创建完整克隆,这里我们选择创建完整克隆,一共需要创建两个克隆,创建完成后在创建好的两台克隆虚拟机上进行第二步的操作,修改IP地址以及主机名,因为我们是进行克隆的所以我们修改IP地址只需要修改IPADDR那一项就行了,我这边修改后是第一台虚拟机IP地址为:192.168.119.50 主机号为hadoop101 第二台虚拟机IP地址为:192.168.119.51 主机号为hadoop102 第三台虚拟机IP地址为:192.168.119.52 主机号为hadoop103 ,设置好后使用工具xshell将3台虚拟机进行连接上
4、设置主机的映射
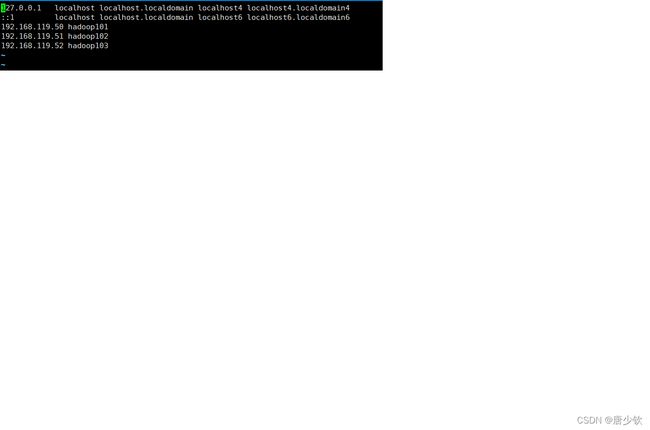
因为我们是搭建完全分布式,所以在设置映射的时候需要设置3台虚拟机的映射关系
输入命 vi /etc/hosts进行主机 ip的映射设置
5、配置免密
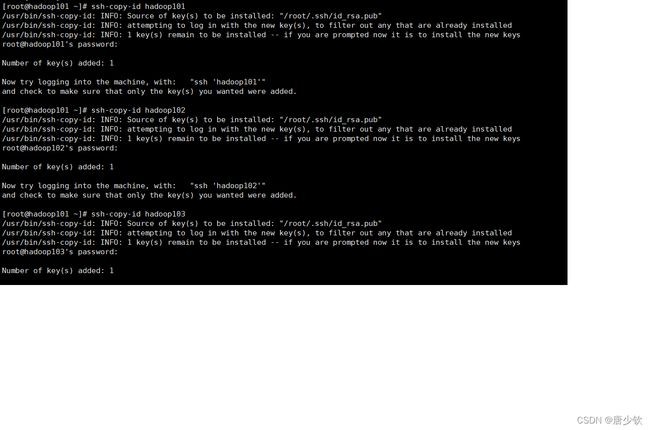
在任意一台虚拟机上输入命令 ssh-keygen -t rsa 然后连续按下三次回车然后输入命令
ssh-copy-id hadoop101(之前设置的主机名)按下回车后输入hadoop101所对应的虚拟机密码
ssh-copy-id hadoop102(之前设置的主机名)按下回车后输入hadoop102所对应的虚拟机密码
ssh-copy-id hadoop103(之前设置的主机名)按下回车后输入hadoop103所对应的虚拟机密码
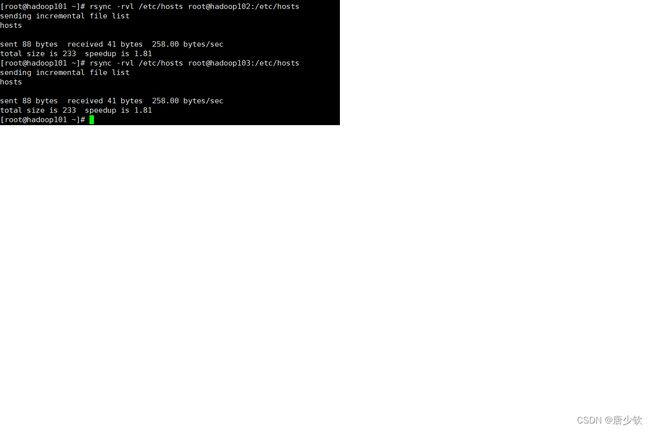
设置完后进行rsync命令操作进行另外两台虚拟机的文件更新
输入rsync -rvl /etc/hosts root@hadoop102:/etc/host
输入rsync -rvl /etc/hosts root@hadoop103:/etc/host
更新完映射关系后在另外两台进行重复免密操作,也就是上面所写的ssh-keygen -t rsa 和ssh-copy-id xx 的操作
6、设置jdk和hadoop的配置文件
输入命令 vi /etc/profile
光标移动到命令行的最后一行输入配置文件如下图所示
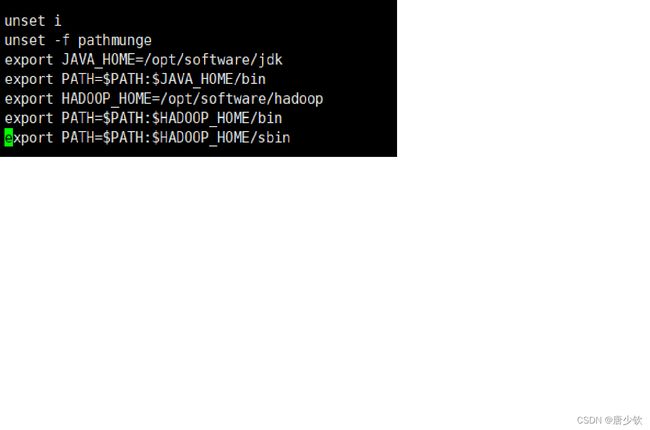
输入好后保存退出,然后输入source /etc/profile进行配置文件的更新
进行使用rsync命令进行另外两台虚拟机的更新
rsync -rvl /etc/profile root@hadoop102:/etc/profile
rsync -rvl /etc/profile root@hadoop103:/etc/profile
然后进入另外两台虚拟机中输入source /etc/profile
7、设置hadoop配置文件
首先进入hadoop配置文件的目录下,也就是刚才解压后的hadoop文件下的etc下的hadoop,如果不是按照我的目录来写的就使用自己的方法进入hadoop配置文件目录下,如果目录和我的是一样的就输入 cd /opt/software/hadoop/etc/hadoop
vi core-site.xml
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/software/hadoop/data/tmp
vi hadoop-env.sh
export JAVA_HOME=/opt/software/jdk vi hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop103:50090
vi yarn-env.sh
export JAVA_HOME=/opt/software/jdk vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop102
vi mapred-env.sh
export JAVA_HOME=/opt/software/jdk cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
vi slaves 注意:slaves内的东西需要全部删完再输入配置文件
hadoop101
hadoop102
hadoop103然后使用rsync 进行另外两台的hadoop配置文件更新
rsync -rvl /opt/software/hadoop/etc/hadoop/ root@hadoop102:/opt/software/hadoop/etc/hadoop/
rsync -rvl /opt/software/hadoop/etc/hadoop/ root@hadoop103:/opt/software/hadoop/etc/hadoop/
8、格式化namenode
输入命令:hdfs namnoe -format
注
如果需要重新格式化
在重新格式化之前一定要先删除data数据和log日志。然后再进行格式化。
1、停止使用hadoop进程(stop-all.sh)
2、删除配置文件core-site.xml和hdfs-site.xml中指定目录下的文件
9、启动hdfs、启动yarn
首先进入hadoop主目录
输入 cd /opt/software/hadoop
启动hdfs,输入 sbin/start-dfs.sh
然后用3台虚拟机进行jps测试,和下图出现的进程一样就成功了

然后启动yarn,yarn的启动需要在ResouceManager所在的机器上进行,在 yarn-site.xml中设置过,我这边设置的是hadoop102,所以我需要进入到hadoop102所在的虚拟机上操作yarn的启动命令。
输入 cd /opt/software/hadoop
启动yarn,输入 sbin/start-yarn.sh
然后用3台虚拟机进行jps测试,和下图出现的进程一样就成功了

10、关闭防火墙进行网站访问
在三台虚拟机上都输入命令:systemctl stop firewalld.service即可关闭防火墙
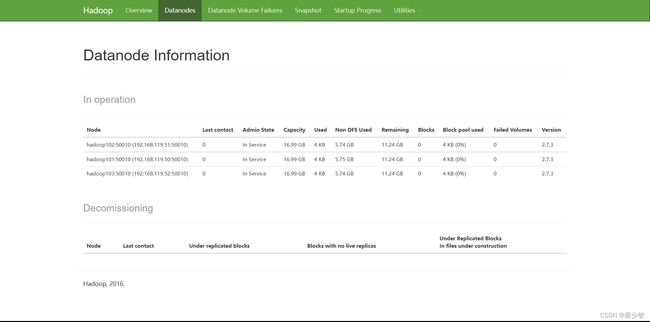
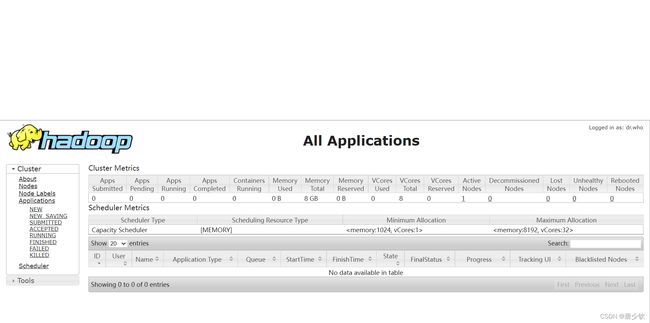
然后进入浏览器输入网站http://192.168.119.50:50070/和http://192.168.119.51:8088/,即可测试是否搭建成功。
最后一句话:这完全分布式有手就行