Hadoop完全分布式部署
目录
- Hadoop完全分布式
- 部署准备
- jdk配置
- ssh实现主从节点之间的免密登陆
- Hadoop环境变量
- 配置Hadoop相关文件
- hadoop-env.sh
- core-site.xml
- hdfssite.xml
- mapred-site.xml
- yarn-site.xml
- 启动Hadoop
Hadoop完全分布式
Hadoop完全分布式,集群,Hadoop的守护进程(NameNode,DataNode,SecondaryNameNode,JobTracker,TaskTracker)全部运行在集群里。
部署准备
jdk-8u231-linux-x64.tar.gzhadoop-3.2.1.tar.gz
以下一共是4个节点,一个NameNode,三个DataNode。
192.168.200.88 weekeight (NameNode)
192.168.200.81 weekone (DataNode)
192.168.200.82 weektwo (DataNode)
192.168.200.83 weekthree (DataNode)
首先设置4个节点的hosts,在/etc/hosts文件里添加4个节点的IP地址与主机名
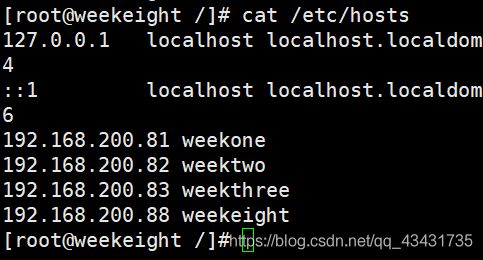
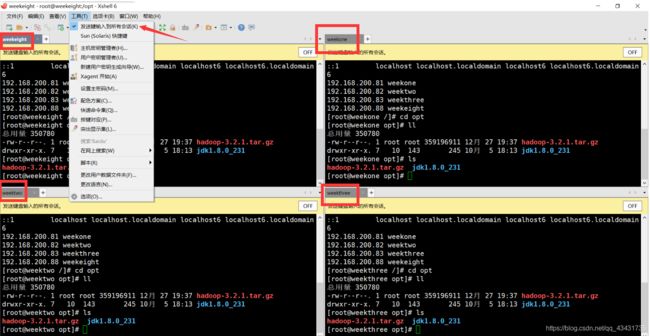
使用工具Xshell连接4台虚拟机,可以点开工具里的发送键输入到所有会话来同步四台机器的命令。
jdk配置
软件包都在opt目录里
ln -s jdk1.8.0_231 jdk #感觉文件名字太长可以创建一个软链接容易记忆

vim /etc/profile #编辑系统配置文件
export JAVA_HOME=/opt/jdk #在文件最后添加配置
export PATH=$PATH:$JAVA_HOME/bin
网上好多都配置了classpath其实早在jdk1.5官方就已经说明不必配置classpath

source /etc/profile #配置后需要执行一下才能生效,使用jps命令验证成功
ssh实现主从节点之间的免密登陆
ssh 127.0.0.1 #使用ssh连接本地让其产生一个/root/.ssh文件夹
关闭4台命令的同步,设置NameNode
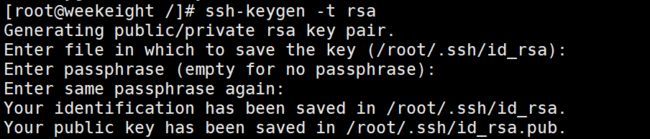
ssh-keygen -t rsa #使用此命令一直回车,密钥及公钥就存在/root/.ssh里
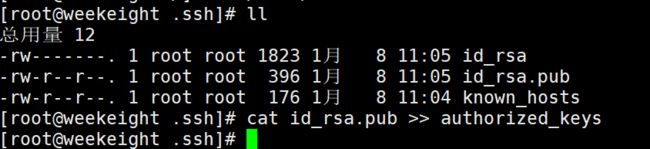
cd /root/.ssh
cat id_rsa.pub >> authorized_keys #授权密钥
使用scp命令将NameNode的密钥传递给其他三个节点
cd /root/.ssh
scp id_rsa.pub weekone:`pwd`/weekeight.pub
scp id_rsa.pub weektwo:`pwd`/weekeight.pub
scp id_rsa.pub weekthree:`pwd`/weekeight.pub
同步one,two,three三台机器的命令(除去weekeight),将传递来的weekeight.pub追加到authorized_keys里
cd /root/.ssh
cat weekeight.pub >> authorized_keys
关闭同步命令,在weekeight上进行测试
ssh weekone #ssh连接weekone无需密码
exit #退出weekone
ssh weektwo
exit
ssh weektwo
exit
Hadoop环境变量
开启4台机器命令同步cd opt
tar -zxvf hadoop-3.2.1.tar.gz #同jdk配置一样,解压压缩包
ln -s hadoop-3.2.1 hadoop #创建软链接
vim /etc/profile #配置环境变量
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME=/sbin
source /etc/profile #执行文件,命令行输入hadoop验证配置成功

配置Hadoop相关文件
说明:此处配置可以参考官网的默认配置来配置
Hadoop配置文件全部在 /opt/hadoop/etc/hadoop
本文所出现的weekeight可换成自己的hostname
配置文件在/opt/hadoop/etc/hadoop下
相关文件配置时开启机器命令同步
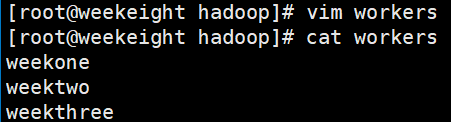
首先配置DataNode启动文件workers
cd /opt/hadoop/etc/hadoop
vim workers #Hadoop3.0以上的是workers,2.0可能是slaves
weekone
weektwo
weekthree
hadoop-env.sh
vim hadoop-env.sh #在此文件再次配置Java的路径

core-site.xml
core-site.xml的全部默认配置项,可进行参考来配置
在文件的最后的configuration标签里添加一下配置
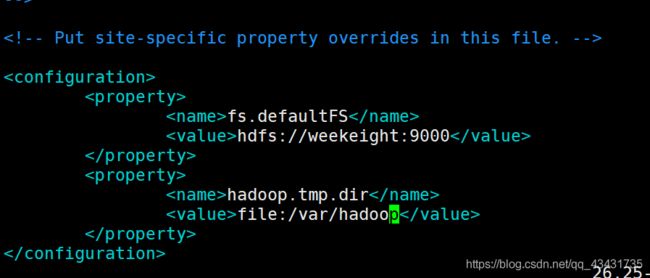
1.指定HDFS的的路径地址
2.hadoop的工作目录,存放hadoop进程的临时文件
<property>
<name>fs.defaultFS</name>
<value>hdfs://weekeight:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/var/hadoop</value>
</property>
hdfssite.xml
hdfssite.xml的全部默认配置项,可进行参考来配置
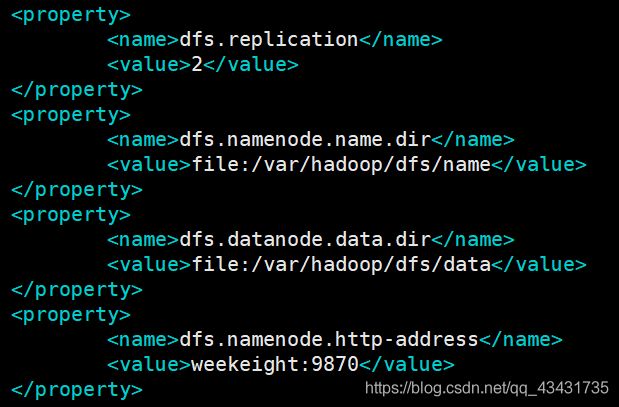
1.指定副本数(默认为3)
2.指定namenode当前数据的目录(路径需为hadoop.tmp.dir配置的目录下)
3.指定datanode当前数据的目录(同上)
4.namenode将监听的地址和基本端口(3.0以后的端口都是9870,之前版本大多50070)
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/var/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/var/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>weekeight:9870</value>
</property>
mapred-site.xml
mapred-site.xml的全部默认配置项,可进行参考来配置
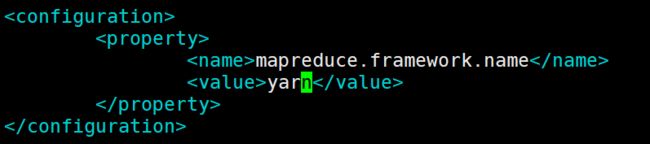
1.执行MapReduce时官方默认的为local(本地)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
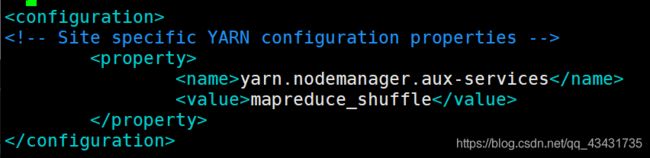
yarn-site.xml
yarn-site.xml的全部默认配置项,可进行参考来配置
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
启动Hadoop
所有的配置都已经配置完了,我们剩下的步骤只剩格式化,启动,验证。
这里把命令同步关了,只操作weekeight一台机器。
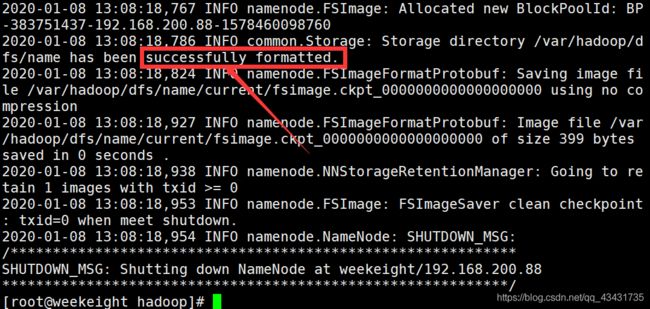
格式化,出现图中字样格式化成功。
hdfs namenode -format #格式化
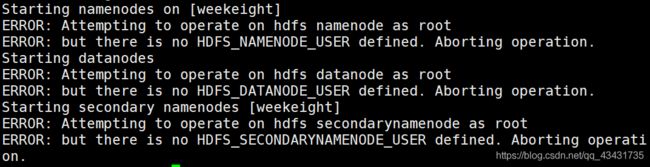
start-dfs.sh #启动,启动后使用jps验证

启动时出现错误,参考Hadoop单点安装FAQ
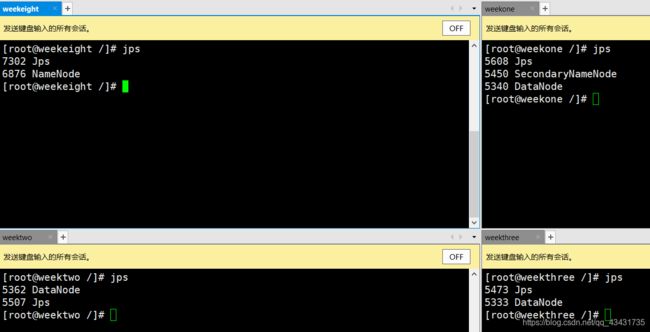
使用jps查看当前进程
也可以在网站上打开weekeight:9870(此处为自己设置的),查看自己的节点数对不对,如果发现0节点,查看datanode的日志显示datanode连接不上namenode,可能是你的防火墙没关。

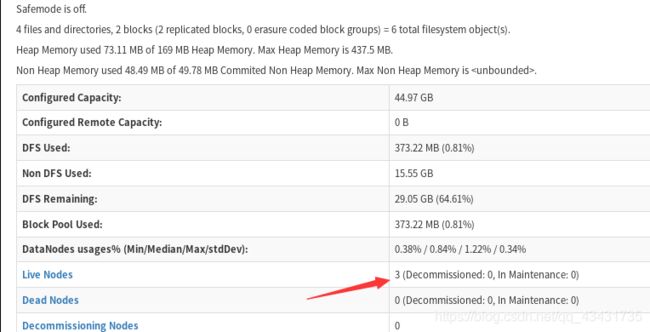
到此处表示Hadoop完全分布式部署成功。