ResNet残差网络一维复现pytorch-含残差块复现思路分析
ResNet残差网络复现
由于深度学习的会面临退化的问题,也就是当深度学习的网络加深到某一程度之后再加深会导致准确率降低,为了保证加深的网络的性能不低于浅层次的网络,为此2015年何凯明大佬发表了著名了ResNet残差网络,既再GoogLeNet在横向维度的创新之后,在网络结构上进行了新的创新。
LeNet-AlexNet-ZFNet: LeNet-AlexNet-ZFNet一维复现pytorch
VGG: VGG一维复现pytorch
GoogLeNet: GoogLeNet一维复现pytorch
ResNet: ResNet残差网络一维复现pytorch-含残差块复现思路分析
DenseNet: DenseNet一维复现pytorch
ResNet原文链接: Deep Residual Learning for Image Recognition
残差结构
结构的原理并不复杂,看一下从原文截取出来的这个残差结构,很好理解就是把输入最后加入到的输出上,构造一个类似短路的结构。
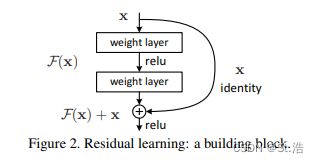
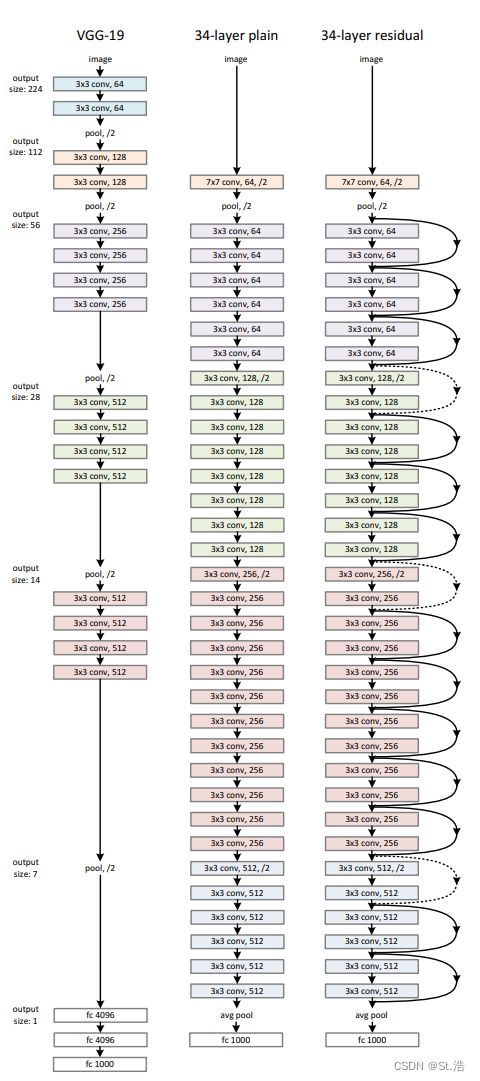
实践中,原文作者针对VGG19进行了改进,首先是增加了卷积层,然后每两个卷积层之之间进行残差链接,值得注意的是,这里实现的链接是输入和输出尺寸相同的链接,虚线表示输出和输出的尺寸不一致,所以在进行残差运算之前输入要经过一个卷积核大小为1的卷积层,对尺寸做一些改变。这里带一句图中/2表示下采样。就是经过该层后样本点数量减少为原来的1/2。
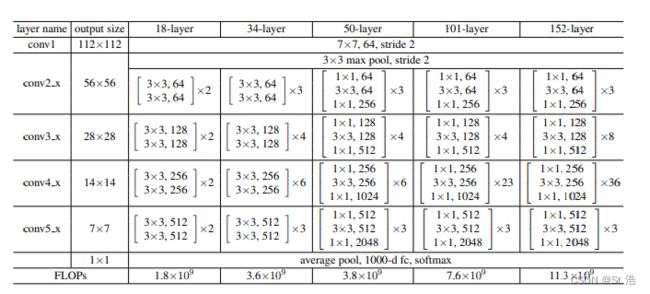
接着作者改变卷积层数量,已经将一个残差块内的两个卷积核为3×3的卷积层改成两个1×1的卷积层减少参数数量,衍生了五种残差网络的结构。本文要复现的就是应用比较广泛的ResNet50。
代码实现
构建残差块
由上图可见残差块的结构是类似的,所以只需要构建一个可变参数的残差块然后再反复调用就可以了,这里并没有选择去改造pytorch的官方程序,因为官方写的不是很好理解,选择了自己复现。复现二维的网络也是同样的思路和步骤,首先梳理残差块需要实现的自适应参数。由于我们要复现的是一维的ResNet因此残差块的基本结构是两个卷积核大小为1卷积层中间夹一个卷积核大小为3的卷积核。
在这个基础上我们需要满足:
1.可以选择是否进行下1/2采样
2.可以判断输入时候是否经过变换尺寸的卷积层再与输出进行相加
为此我们需要四个参数:
1.输入通道数
2.过渡通道数
3.输出通道数
4.是否进行降采样的一个布尔变量
然后通过这些变量来实现两个关键逻辑
1.当输出通道数与输出通道数不一致的时让输入经过一个卷积核大小为1的卷积层,让输入经过该卷积层后的输出与主主体卷积输出通道数一致,为了之后可以直接相加。
2.当时是否进行降采样的布尔变量为Ture时通过改变卷积层步长的方式来实现降采样
这里又两种情况
1.当输入通道和输出通道数一致需要进行降采样时,只需要改变主体三个卷积层种第一个卷积核为1的卷积层的步长为2
2.当输入通道和输出通道数不一致又需要进行降采样时,不但要改变主体卷积层中第一个卷积核大小为1的卷积层的步长为2,也要把为了将输入通道数变成和输出通道数一致的卷积核为1的卷积层的步长改成2
ok如果你认真读完上面的话那相信你对下面的代码的具体过程就能理解了
import torch
class Bottlrneck(torch.nn.Module):
def __init__(self,In_channel,Med_channel,Out_channel,downsample=False):
super(Bottlrneck, self).__init__()
self.stride = 1
if downsample == True:
self.stride = 2
self.layer = torch.nn.Sequential(
torch.nn.Conv1d(In_channel, Med_channel, 1, self.stride),
torch.nn.BatchNorm1d(Med_channel),
torch.nn.ReLU(),
torch.nn.Conv1d(Med_channel, Med_channel, 3, padding=1),
torch.nn.BatchNorm1d(Med_channel),
torch.nn.ReLU(),
torch.nn.Conv1d(Med_channel, Out_channel, 1),
torch.nn.BatchNorm1d(Out_channel),
torch.nn.ReLU(),
)
if In_channel != Out_channel:
self.res_layer = torch.nn.Conv1d(In_channel, Out_channel,1,self.stride)
else:
self.res_layer = None
def forward(self,x):
if self.res_layer is not None:
residual = self.res_layer(x)
else:
residual = x
return self.layer(x)+residual
if __name__ == '__main__':
x = torch.randn(size=(1,64,224))
model = Bottlrneck(64,64,256,True)
output = model(x)
print(f'输入尺寸为:{x.shape}')
print(f'输出尺寸为:{output.shape}')
print(model)
运行的结果如下

ResNet
实现了可以调用的残差块,由于层数也不是很多,主要是为了减轻代码的阅读负担,根据50-layer的参数表则堆出的ResNet50网络代码如下
import torch
class Bottlrneck(torch.nn.Module):
def __init__(self,In_channel,Med_channel,Out_channel,downsample=False):
super(Bottlrneck, self).__init__()
self.stride = 1
if downsample == True:
self.stride = 2
self.layer = torch.nn.Sequential(
torch.nn.Conv1d(In_channel, Med_channel, 1, self.stride),
torch.nn.BatchNorm1d(Med_channel),
torch.nn.ReLU(),
torch.nn.Conv1d(Med_channel, Med_channel, 3, padding=1),
torch.nn.BatchNorm1d(Med_channel),
torch.nn.ReLU(),
torch.nn.Conv1d(Med_channel, Out_channel, 1),
torch.nn.BatchNorm1d(Out_channel),
torch.nn.ReLU(),
)
if In_channel != Out_channel:
self.res_layer = torch.nn.Conv1d(In_channel, Out_channel,1,self.stride)
else:
self.res_layer = None
def forward(self,x):
if self.res_layer is not None:
residual = self.res_layer(x)
else:
residual = x
return self.layer(x)+residual
class ResNet(torch.nn.Module):
def __init__(self,in_channels=2,classes=5):
super(ResNet, self).__init__()
self.features = torch.nn.Sequential(
torch.nn.Conv1d(in_channels,64,kernel_size=7,stride=2,padding=3),
torch.nn.MaxPool1d(3,2,1),
Bottlrneck(64,64,256,False),
Bottlrneck(256,64,256,False),
Bottlrneck(256,64,256,False),
#
Bottlrneck(256,128,512, True),
Bottlrneck(512,128,512, False),
Bottlrneck(512,128,512, False),
#
Bottlrneck(512,256,1024, True),
Bottlrneck(1024,256,1024, False),
Bottlrneck(1024,256,1024, False),
#
Bottlrneck(1024,512,2048, True),
Bottlrneck(2048,512,2048, False),
Bottlrneck(2048,512,2048, False),
torch.nn.AdaptiveAvgPool1d(1)
)
self.classifer = torch.nn.Sequential(
torch.nn.Linear(2048,classes)
)
def forward(self,x):
x = self.features(x)
x = x.view(-1,2048)
x = self.classifer(x)
return x
if __name__ == '__main__':
x = torch.randn(size=(1,1,224))
# x = torch.randn(size=(1,64,224))
# model = Bottlrneck(64,64,256,True)
model = ResNet(in_channels=1)
output = model(x)
print(f'输入尺寸为:{x.shape}')
print(f'输出尺寸为:{output.shape}')
print(model)
运行结果如下
输入尺寸为:torch.Size([1, 1, 224])
输出尺寸为:torch.Size([1, 125])
ResNet50(
(features): Sequential(
(0): Conv1d(1, 64, kernel_size=(7,), stride=(2,), padding=(3,))
(1): MaxPool1d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(2): Bottlrneck(
(layer): Sequential(
(0): Conv1d(64, 64, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(64, 256, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
(res_layer): Conv1d(64, 256, kernel_size=(1,), stride=(1,))
)
(3): Bottlrneck(
(layer): Sequential(
(0): Conv1d(256, 64, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(64, 256, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(4): Bottlrneck(
(layer): Sequential(
(0): Conv1d(256, 64, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(64, 256, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(5): Bottlrneck(
(layer): Sequential(
(0): Conv1d(256, 128, kernel_size=(1,), stride=(2,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(128, 512, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
(res_layer): Conv1d(256, 512, kernel_size=(1,), stride=(2,))
)
(6): Bottlrneck(
(layer): Sequential(
(0): Conv1d(512, 128, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(128, 512, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(7): Bottlrneck(
(layer): Sequential(
(0): Conv1d(512, 128, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(128, 512, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(8): Bottlrneck(
(layer): Sequential(
(0): Conv1d(512, 128, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(128, 512, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(9): Bottlrneck(
(layer): Sequential(
(0): Conv1d(512, 256, kernel_size=(1,), stride=(2,))
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(256, 1024, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
(res_layer): Conv1d(512, 1024, kernel_size=(1,), stride=(2,))
)
(10): Bottlrneck(
(layer): Sequential(
(0): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(256, 1024, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(11): Bottlrneck(
(layer): Sequential(
(0): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(256, 1024, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(12): Bottlrneck(
(layer): Sequential(
(0): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(256, 1024, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(13): Bottlrneck(
(layer): Sequential(
(0): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(256, 1024, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(14): Bottlrneck(
(layer): Sequential(
(0): Conv1d(1024, 256, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(256, 1024, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(15): Bottlrneck(
(layer): Sequential(
(0): Conv1d(1024, 512, kernel_size=(1,), stride=(2,))
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(512, 2048, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
(res_layer): Conv1d(1024, 2048, kernel_size=(1,), stride=(2,))
)
(16): Bottlrneck(
(layer): Sequential(
(0): Conv1d(2048, 512, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(512, 2048, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(17): Bottlrneck(
(layer): Sequential(
(0): Conv1d(2048, 512, kernel_size=(1,), stride=(1,))
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv1d(512, 2048, kernel_size=(1,), stride=(1,))
(7): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
)
)
(18): AdaptiveAvgPool1d(output_size=1)
)
(classifer): Sequential(
(0): Linear(in_features=2048, out_features=125, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv1d-1 [-1, 64, 112] 512
MaxPool1d-2 [-1, 64, 56] 0
Conv1d-3 [-1, 256, 56] 16,640
Conv1d-4 [-1, 64, 56] 4,160
BatchNorm1d-5 [-1, 64, 56] 128
ReLU-6 [-1, 64, 56] 0
Conv1d-7 [-1, 64, 56] 12,352
BatchNorm1d-8 [-1, 64, 56] 128
ReLU-9 [-1, 64, 56] 0
Conv1d-10 [-1, 256, 56] 16,640
BatchNorm1d-11 [-1, 256, 56] 512
ReLU-12 [-1, 256, 56] 0
Bottlrneck-13 [-1, 256, 56] 0
Conv1d-14 [-1, 64, 56] 16,448
BatchNorm1d-15 [-1, 64, 56] 128
ReLU-16 [-1, 64, 56] 0
Conv1d-17 [-1, 64, 56] 12,352
BatchNorm1d-18 [-1, 64, 56] 128
ReLU-19 [-1, 64, 56] 0
Conv1d-20 [-1, 256, 56] 16,640
BatchNorm1d-21 [-1, 256, 56] 512
ReLU-22 [-1, 256, 56] 0
Bottlrneck-23 [-1, 256, 56] 0
Conv1d-24 [-1, 64, 56] 16,448
BatchNorm1d-25 [-1, 64, 56] 128
ReLU-26 [-1, 64, 56] 0
Conv1d-27 [-1, 64, 56] 12,352
BatchNorm1d-28 [-1, 64, 56] 128
ReLU-29 [-1, 64, 56] 0
Conv1d-30 [-1, 256, 56] 16,640
BatchNorm1d-31 [-1, 256, 56] 512
ReLU-32 [-1, 256, 56] 0
Bottlrneck-33 [-1, 256, 56] 0
Conv1d-34 [-1, 512, 28] 131,584
Conv1d-35 [-1, 128, 28] 32,896
BatchNorm1d-36 [-1, 128, 28] 256
ReLU-37 [-1, 128, 28] 0
Conv1d-38 [-1, 128, 28] 49,280
BatchNorm1d-39 [-1, 128, 28] 256
ReLU-40 [-1, 128, 28] 0
Conv1d-41 [-1, 512, 28] 66,048
BatchNorm1d-42 [-1, 512, 28] 1,024
ReLU-43 [-1, 512, 28] 0
Bottlrneck-44 [-1, 512, 28] 0
Conv1d-45 [-1, 128, 28] 65,664
BatchNorm1d-46 [-1, 128, 28] 256
ReLU-47 [-1, 128, 28] 0
Conv1d-48 [-1, 128, 28] 49,280
BatchNorm1d-49 [-1, 128, 28] 256
ReLU-50 [-1, 128, 28] 0
Conv1d-51 [-1, 512, 28] 66,048
BatchNorm1d-52 [-1, 512, 28] 1,024
ReLU-53 [-1, 512, 28] 0
Bottlrneck-54 [-1, 512, 28] 0
Conv1d-55 [-1, 128, 28] 65,664
BatchNorm1d-56 [-1, 128, 28] 256
ReLU-57 [-1, 128, 28] 0
Conv1d-58 [-1, 128, 28] 49,280
BatchNorm1d-59 [-1, 128, 28] 256
ReLU-60 [-1, 128, 28] 0
Conv1d-61 [-1, 512, 28] 66,048
BatchNorm1d-62 [-1, 512, 28] 1,024
ReLU-63 [-1, 512, 28] 0
Bottlrneck-64 [-1, 512, 28] 0
Conv1d-65 [-1, 128, 28] 65,664
BatchNorm1d-66 [-1, 128, 28] 256
ReLU-67 [-1, 128, 28] 0
Conv1d-68 [-1, 128, 28] 49,280
BatchNorm1d-69 [-1, 128, 28] 256
ReLU-70 [-1, 128, 28] 0
Conv1d-71 [-1, 512, 28] 66,048
BatchNorm1d-72 [-1, 512, 28] 1,024
ReLU-73 [-1, 512, 28] 0
Bottlrneck-74 [-1, 512, 28] 0
Conv1d-75 [-1, 1024, 14] 525,312
Conv1d-76 [-1, 256, 14] 131,328
BatchNorm1d-77 [-1, 256, 14] 512
ReLU-78 [-1, 256, 14] 0
Conv1d-79 [-1, 256, 14] 196,864
BatchNorm1d-80 [-1, 256, 14] 512
ReLU-81 [-1, 256, 14] 0
Conv1d-82 [-1, 1024, 14] 263,168
BatchNorm1d-83 [-1, 1024, 14] 2,048
ReLU-84 [-1, 1024, 14] 0
Bottlrneck-85 [-1, 1024, 14] 0
Conv1d-86 [-1, 256, 14] 262,400
BatchNorm1d-87 [-1, 256, 14] 512
ReLU-88 [-1, 256, 14] 0
Conv1d-89 [-1, 256, 14] 196,864
BatchNorm1d-90 [-1, 256, 14] 512
ReLU-91 [-1, 256, 14] 0
Conv1d-92 [-1, 1024, 14] 263,168
BatchNorm1d-93 [-1, 1024, 14] 2,048
ReLU-94 [-1, 1024, 14] 0
Bottlrneck-95 [-1, 1024, 14] 0
Conv1d-96 [-1, 256, 14] 262,400
BatchNorm1d-97 [-1, 256, 14] 512
ReLU-98 [-1, 256, 14] 0
Conv1d-99 [-1, 256, 14] 196,864
BatchNorm1d-100 [-1, 256, 14] 512
ReLU-101 [-1, 256, 14] 0
Conv1d-102 [-1, 1024, 14] 263,168
BatchNorm1d-103 [-1, 1024, 14] 2,048
ReLU-104 [-1, 1024, 14] 0
Bottlrneck-105 [-1, 1024, 14] 0
Conv1d-106 [-1, 256, 14] 262,400
BatchNorm1d-107 [-1, 256, 14] 512
ReLU-108 [-1, 256, 14] 0
Conv1d-109 [-1, 256, 14] 196,864
BatchNorm1d-110 [-1, 256, 14] 512
ReLU-111 [-1, 256, 14] 0
Conv1d-112 [-1, 1024, 14] 263,168
BatchNorm1d-113 [-1, 1024, 14] 2,048
ReLU-114 [-1, 1024, 14] 0
Bottlrneck-115 [-1, 1024, 14] 0
Conv1d-116 [-1, 256, 14] 262,400
BatchNorm1d-117 [-1, 256, 14] 512
ReLU-118 [-1, 256, 14] 0
Conv1d-119 [-1, 256, 14] 196,864
BatchNorm1d-120 [-1, 256, 14] 512
ReLU-121 [-1, 256, 14] 0
Conv1d-122 [-1, 1024, 14] 263,168
BatchNorm1d-123 [-1, 1024, 14] 2,048
ReLU-124 [-1, 1024, 14] 0
Bottlrneck-125 [-1, 1024, 14] 0
Conv1d-126 [-1, 256, 14] 262,400
BatchNorm1d-127 [-1, 256, 14] 512
ReLU-128 [-1, 256, 14] 0
Conv1d-129 [-1, 256, 14] 196,864
BatchNorm1d-130 [-1, 256, 14] 512
ReLU-131 [-1, 256, 14] 0
Conv1d-132 [-1, 1024, 14] 263,168
BatchNorm1d-133 [-1, 1024, 14] 2,048
ReLU-134 [-1, 1024, 14] 0
Bottlrneck-135 [-1, 1024, 14] 0
Conv1d-136 [-1, 2048, 7] 2,099,200
Conv1d-137 [-1, 512, 7] 524,800
BatchNorm1d-138 [-1, 512, 7] 1,024
ReLU-139 [-1, 512, 7] 0
Conv1d-140 [-1, 512, 7] 786,944
BatchNorm1d-141 [-1, 512, 7] 1,024
ReLU-142 [-1, 512, 7] 0
Conv1d-143 [-1, 2048, 7] 1,050,624
BatchNorm1d-144 [-1, 2048, 7] 4,096
ReLU-145 [-1, 2048, 7] 0
Bottlrneck-146 [-1, 2048, 7] 0
Conv1d-147 [-1, 512, 7] 1,049,088
BatchNorm1d-148 [-1, 512, 7] 1,024
ReLU-149 [-1, 512, 7] 0
Conv1d-150 [-1, 512, 7] 786,944
BatchNorm1d-151 [-1, 512, 7] 1,024
ReLU-152 [-1, 512, 7] 0
Conv1d-153 [-1, 2048, 7] 1,050,624
BatchNorm1d-154 [-1, 2048, 7] 4,096
ReLU-155 [-1, 2048, 7] 0
Bottlrneck-156 [-1, 2048, 7] 0
Conv1d-157 [-1, 512, 7] 1,049,088
BatchNorm1d-158 [-1, 512, 7] 1,024
ReLU-159 [-1, 512, 7] 0
Conv1d-160 [-1, 512, 7] 786,944
BatchNorm1d-161 [-1, 512, 7] 1,024
ReLU-162 [-1, 512, 7] 0
Conv1d-163 [-1, 2048, 7] 1,050,624
BatchNorm1d-164 [-1, 2048, 7] 4,096
ReLU-165 [-1, 2048, 7] 0
Bottlrneck-166 [-1, 2048, 7] 0
AdaptiveAvgPool1d-167 [-1, 2048, 1] 0
Linear-168 [-1, 125] 256,125
================================================================
Total params: 16,229,117
Trainable params: 16,229,117
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 10.16
Params size (MB): 61.91
Estimated Total Size (MB): 72.07
----------------------------------------------------------------
总结
主要是思路其他维度和其他类型的残差也是一样
如果需要训练模板,可以在下面的浩浩的科研笔记中的付费资料购买,赠送所有一维神经网络模型的经典代码,可以在模板中随意切换。