【ML】数据增强
在我们的训练数据拆分上评估数据增强,以增加高质量训练样本的数量。
介绍
我们经常希望通过数据增强来增加训练数据的大小和多样性。它涉及使用现有样本来生成合成但现实的示例。
-
拆分数据集。我们希望首先拆分我们的数据集,因为如果我们允许将生成的样本放置在不同的数据拆分中,许多增强技术将导致某种形式的数据泄漏。
例如,一些扩充涉及为句子中的某些关键标记生成同义词。如果我们允许从同一原始句子生成的句子进入不同的拆分,我们可能会在我们的不同拆分中泄漏具有几乎相同嵌入表示的样本。
-
增加训练拆分。我们只想在训练集上应用数据增强,因为我们的验证和测试拆分应该用于提供对实际数据点的准确估计。
-
检查和验证. 如果增强的数据样本不是我们的模型在生产中可能遇到的可能输入,那么仅仅为了增加我们的训练样本大小而增加是没有用的。
数据增强的确切方法很大程度上取决于数据类型和应用程序。以下是可以增强不同模式的数据的几种方法:
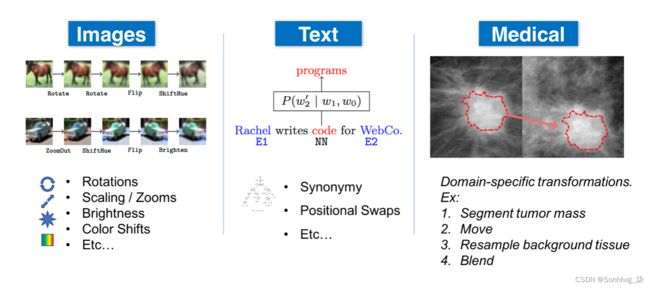
- 一般:归一化、平滑、随机噪声、合成过采样 ( SMOTE ) 等。
- 自然语言处理 (NLP):替换(同义词、tfidf、嵌入、掩码模型)、随机噪声、拼写错误等。
- 计算机视觉 (CV):裁剪、翻转、旋转、填充、饱和、增加亮度等。.
警告
虽然某些数据模式(例如图像)的转换很容易检查和验证,但其他模式可能会引入静默错误。例如,改变文本中标记的顺序可以显着改变含义(“这真的很酷”→“这真的很酷吗”)。因此,重要的是测量我们的增强策略将引入的噪声,并对发生的转换进行精细控制。
图书馆
根据特征类型和任务,有许多数据增强库允许我们扩展训练数据。
自然语言处理 (NLP)
- NLPAug:NLP 的数据增强。
- TextAttack:NLP 中对抗性攻击、数据增强和模型训练的框架。
- TextAugment:文本增强库。
计算机视觉 (CV)
- Imgaug:用于机器学习实验的图像增强。
- Albumentations:快速图像增强库。
- Augmentor:用于机器学习的 Python 图像增强库。
- Kornia.augmentation:在 GPU 中执行数据增强的模块。
- SOLT:深度学习的数据增强库,支持图像、分割掩码、标签和关键点。
其他
- Snorkel:用于生成具有弱监督的训练数据的系统。
- DeltaPy:表格数据增强和特征工程。
- Audiomentations:一个用于音频数据增强的 Python 库。
- Tsaug:用于时间序列增强的 Python 包。
应用
让我们使用nlpaug库来扩充我们的数据集并评估生成样本的质量。
pip install nlpaug==1.1.0 transformers==3.0.2 -q
pip install snorkel==0.9.8 -qimport nlpaug.augmenter.word as naw# Load tokenizers and transformers
substitution = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased", action="substitute")
insertion = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased", action="insert")
text = "Conditional image generation using Variational Autoencoders and GANs."hierarchical risk mapping using variational signals and gans.
替换对我们来说似乎不是一个好主意,因为某些关键字为我们的标签提供了强烈的信号,所以我们不想改变它们。另外,请注意,这些增强不是确定性的,每次运行时都会有所不同。让我们尝试插入...
# 插入
insertion.augment(text)automated conditional inverse image generation algorithms using multiple variational autoencoders and gans.
稍微好一点但仍然很脆弱,现在它可以潜在地插入可能影响误报标签出现的关键词。也许不是替换或插入新的标记,让我们尝试简单地将机器学习相关的关键字与其别名交换。我们将使用 Snorkel 的转换函数来轻松实现这一点。
# 替换标签和别名中的短划线
def replace_dash(x):
return x.replace("-", " ")# 别名
aliases_by_tag = {
"computer-vision": ["cv", "vision"],
"mlops": ["production"],
"natural-language-processing": ["nlp", "nlproc"]
}# 扁平化字典
flattened_aliases = {}
for tag, aliases in aliases_by_tag.items():
tag = replace_dash(x=tag)
if len(aliases):
flattened_aliases[tag] = aliases
for alias in aliases:
_aliases = aliases + [tag]
_aliases.remove(alias)
flattened_aliases[alias] = _aliasesprint (flattened_aliases["natural language processing"])
print (flattened_aliases["nlp"])['nlp', 'nlproc'] ['nlproc', 'natural language processing']
现在我们将使用标签和别名,但我们可以使用inflectaliases_by_tag包来解释多个标签,或者在替换别名之前应用词干提取等。
# 我们只想与整个单词匹配
print ("gan" in "This is a gan.")
print ("gan" in "This is gandalf.")# \b matches spaces
def find_word(word, text):
word = word.replace("+", "\+")
pattern = re.compile(fr"\b({word})\b", flags=re.IGNORECASE)
return pattern.search(text)# Correct behavior (single instance)
print (find_word("gan", "This is a gan."))
print (find_word("gan", "This is gandalf."))None
现在让我们使用 snorkeltransformation_function系统地将这种转换应用于我们的数据。
from snorkel.augmentation import transformation_function@transformation_function()
def swap_aliases(x):
"""Swap ML keywords with their aliases."""
# Find all matches
matches = []
for i, tag in enumerate(flattened_aliases):
match = find_word(tag, x.text)
if match:
matches.append(match)
# Swap a random match with a random alias
if len(matches):
match = random.choice(matches)
tag = x.text[match.start():match.end()]
x.text = f"{x.text[:match.start()]}{random.choice(flattened_aliases[tag])}{x.text[match.end():]}"
return x# Swap
for i in range(3):
sample_df = pd.DataFrame([{"text": "a survey of reinforcement learning for nlp tasks."}])
sample_df.text = sample_df.text.apply(preprocess, lower=True, stem=False)
print (swap_aliases(sample_df.iloc[0]).text)# Undesired behavior (needs contextual insight)
for i in range(3):
sample_df = pd.DataFrame([{"text": "Autogenerate your CV to apply for jobs using NLP."}])
sample_df.text = sample_df.text.apply(preprocess, lower=True, stem=False)
print (swap_aliases(sample_df.iloc[0]).text)autogenerate vision apply jobs using nlp autogenerate cv apply jobs using natural language processing autogenerate cv apply jobs using nlproc
现在我们将定义一个增强策略来应用具有特定规则的转换函数(生成多少样本,是否保留原始数据点等)
from snorkel.augmentation import ApplyOnePolicy, PandasTFApplier# 转换函数 (TF) 策略
policy = ApplyOnePolicy(n_per_original=5, keep_original=True)
tf_applier = PandasTFApplier([swap_aliases], policy)
train_df_augmented = tf_applier.apply(train_df)
train_df_augmented.drop_duplicates(subset=["text"], inplace=True)
train_df_augmented.head()| text | tags | |
|---|---|---|
| 0 | laplacian pyramid reconstruction refinement se... | computer-vision |
| 1 | extract stock sentiment news headlines project... | natural-language-processing |
| 2 | big bad nlp database collection 400 nlp datasets... | natural-language-processing |
| 2 | big bad natural language processing database c... | natural-language-processing |
| 2 | big bad nlproc database collection 400 nlp dat... | natural-language-processing |
len(train_df), len(train_df_augmented)(668, 913)
现在,我们将跳过数据增强,因为它非常变幻无常,并且从经验上看它并没有太大的提高性能。但是我们可以看到,一旦我们可以控制要扩充的词汇类型以及要扩充的内容,这将如何非常有效。
警告
无论我们使用什么方法,重要的是要验证我们不仅仅是为了增强而增强。我们可以通过执行任何现有的数据验证测试,甚至创建特定的测试来应用于增强数据来做到这一点。