YOLOv5+TensorRT+Win11(Python版)
快速上手YOLOv5
- 快速上手YOLOv5
-
- 一、YOLOv5算法
-
- 1. 算法对比
-
- (1)传统目标检测方法
- (2)基于深度学习的目标检测算法
- (2-1)Two-Stage(R-CNN/Fast R-CNN/Faster R-CNN)
- (2-2)One-Stage(SSD/YOLO)
- (2-3)One-Stage VS Two-Stage
- 二、环境配置
-
- 1. NVIDIA独立显卡
- 2. 环境要求
- 3. 安装Visual Studio
- 4. 安装Anaconda
- 5. 安装CUDA Toolkit
- 6. 安装cuDNN
- 7. 安装TensorRT
- 8. 安装OpenCV
- 9. 安装CMake
- 10. 安装Pytorch
- 11. 安装YOLOv5必要依赖包
- 12. YOLOv5使用TensorRT加速
- 三、获取数据集
-
- 1. 公共数据集Kaggle、MakeML等:
- 2. 百度图片爬虫:
- 3. FFmpeg视频帧截取:
- 四、图像标注
-
- 1. Labelme图片标注工具:
-
- 半自动辅助标注:
- 2. AI标注:
- 五、训练平台
-
- 1. 免费算力平台:
- 六、Demo
- 七、参考资料
快速上手YOLOv5
一、YOLOv5算法
1. 算法对比
(1)传统目标检测方法
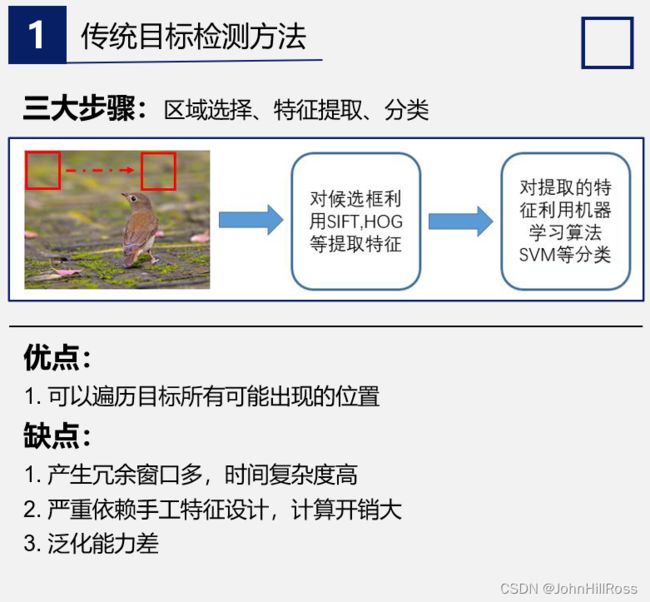
(2)基于深度学习的目标检测算法

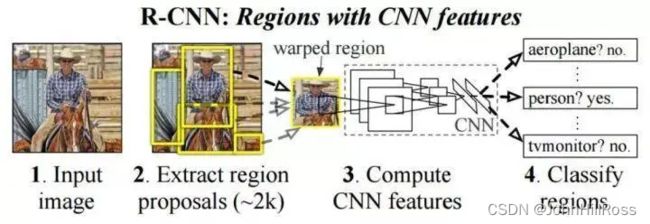
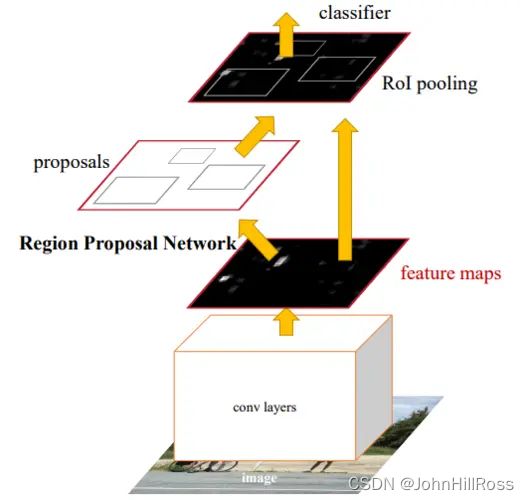
(2-1)Two-Stage(R-CNN/Fast R-CNN/Faster R-CNN)
Two-Stage:先产生候选区域,后对目标分类与位置精修,准确率高但速度较慢
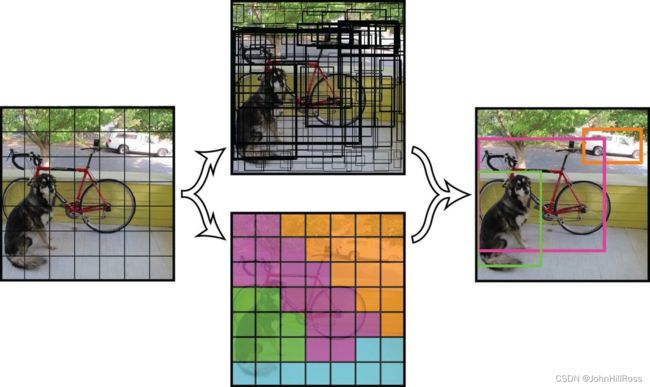
(2-2)One-Stage(SSD/YOLO)
One-Stage:直接回归目标类别与位置,速度快但准确率较低
(2-3)One-Stage VS Two-Stage

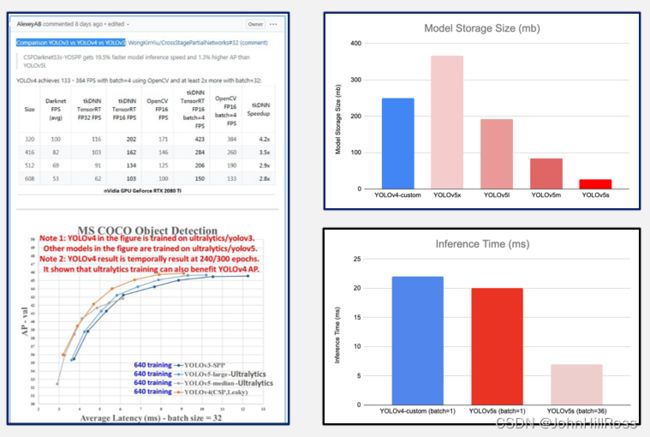
YOLO v5s:模型小、推理时间短、准确率较高
二、环境配置
1. NVIDIA独立显卡
打开设备管理器查看是否拥有NVIDIA独立显卡:

查看NVIDIA独立显卡是否支持CUDA:
https://developer.nvidia.com/cuda-gpus
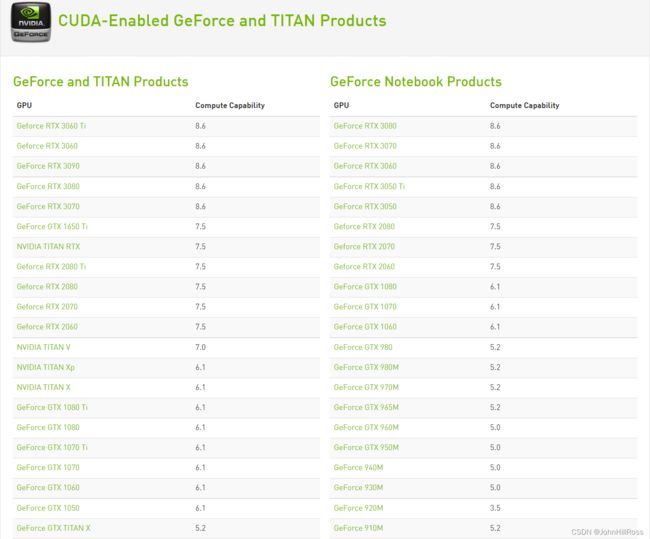
2. 环境要求
| 环境 | 版本 | 地址 |
|---|---|---|
| Visual Studio | Visual Studio 2019 版本 16.11 Community | 点击下载 |
| CMake | cmake-3.24.0-rc2-windows-x86_64 | 点击下载 |
| OpenCV | OpenCV – 3.4.16 | 点击下载 |
| Anaconda | 64-Bit Graphical Installer (594 MB) | 点击下载 |
| CUDA Toolkit | CUDA Toolkit 11.3.1 | 点击下载 |
| cuDNN | cuDNN v8.2.1 (June 7th, 2021), for CUDA 11.x | 点击下载 |
| TensorRT | TensorRT 8.2 GA Update 4 for x86_64 Architecture | 点击下载 |
3. 安装Visual Studio
安装Visual Studio 2019勾选C++桌面开发工具:

4. 安装Anaconda
添加系统环境变量:
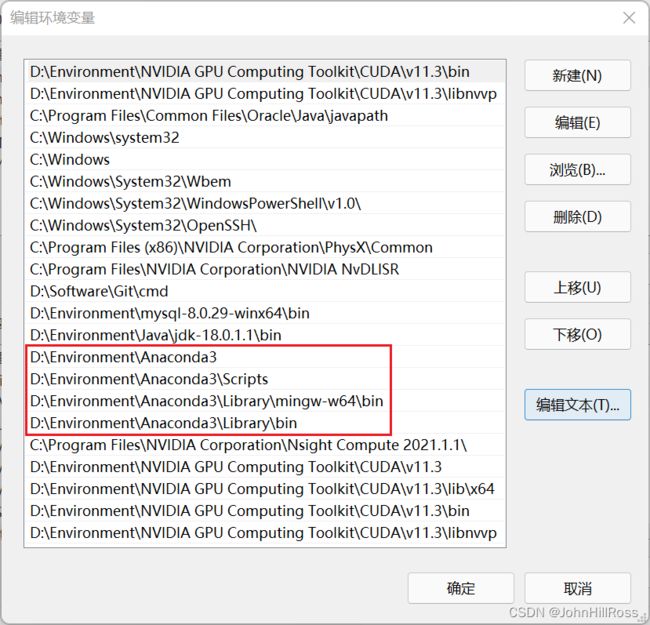
测试:

换国内源:
新建.condarc文件保存以下代码,并替换C:\Users\XXX下的.condarc文件
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
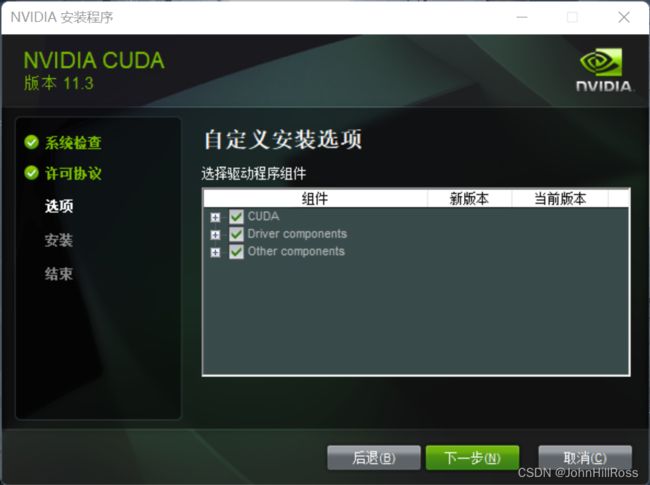
5. 安装CUDA Toolkit
选择自定义

全部安装
添加系统环境变量:
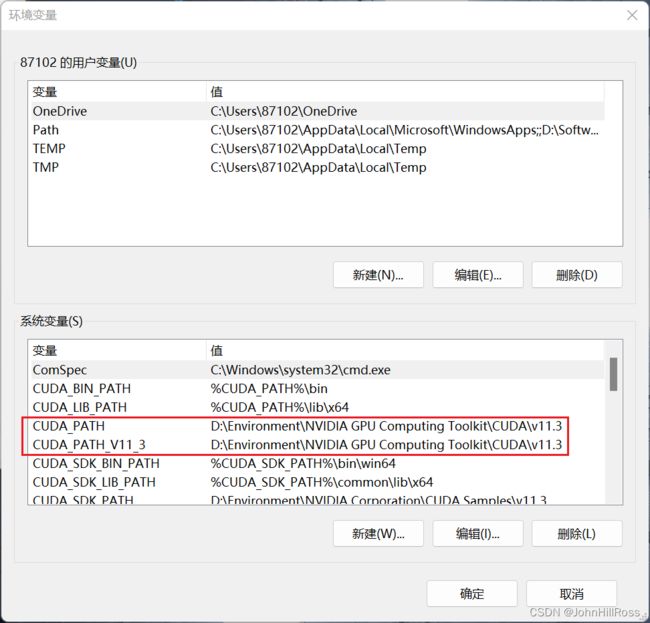
上述两项是安装完成Cuda后,已自动生成的环境变量的配置,我们需要自行添加的下述变量:
CUDA_BIN_PATH: %CUDA_PATH%\bin
CUDA_LIB_PATH: %CUDA_PATH%\lib\x64
CUDA_SDK_PATH: XXX\NVIDIA Corporation\CUDA Samples\v11.1
CUDA_SDK_BIN_PATH: %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH: %CUDA_SDK_PATH%\common\lib\x64
并在系统变量Path中,添加一下四个信息:
%CUDA_BIN_PATH%
%CUDA_LIB_PATH%
%CUDA_SDK_BIN_PATH%
%CUDA_SDK_LIB_PATH%
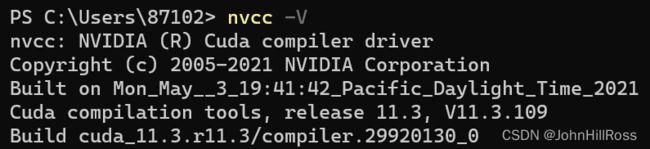
测试:
nvcc -V
6. 安装cuDNN
复制XXX\cudnn-11.3-windows-x64-v8.2.1.32\cuda全部内容到XXX\NVIDIA GPU Computing Toolkit\CUDA\v11.3

7. 安装TensorRT
添加环境变量:
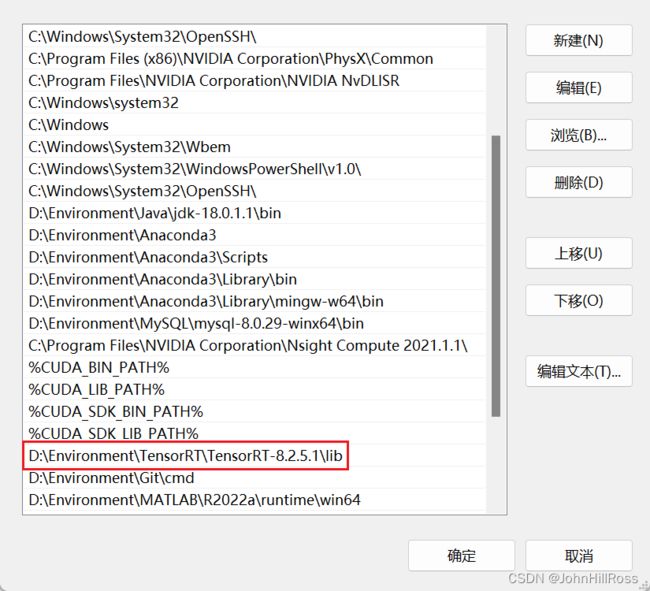
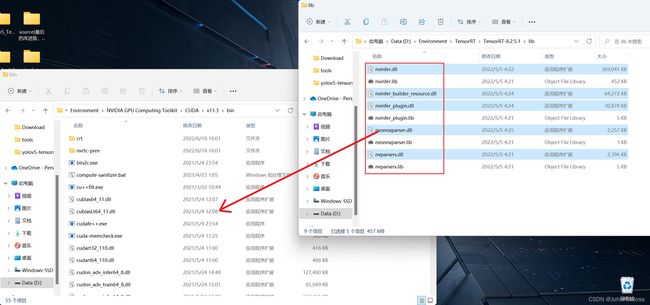
复制XXX\TensorRT-8.2.5.1\lib以下所有dll文件到XXX\NVIDIA GPU Computing Toolkit\CUDA\v11.3\bin下
安装XXXTensorRT\TensorRT-8.2.5.1\python目录下tensorrt-8.2.5.1-cp39-none-win_amd64.whl:
activate pytorch
pip install tensorrt-8.2.5.1-cp39-none-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
8. 安装OpenCV
添加环境变量:
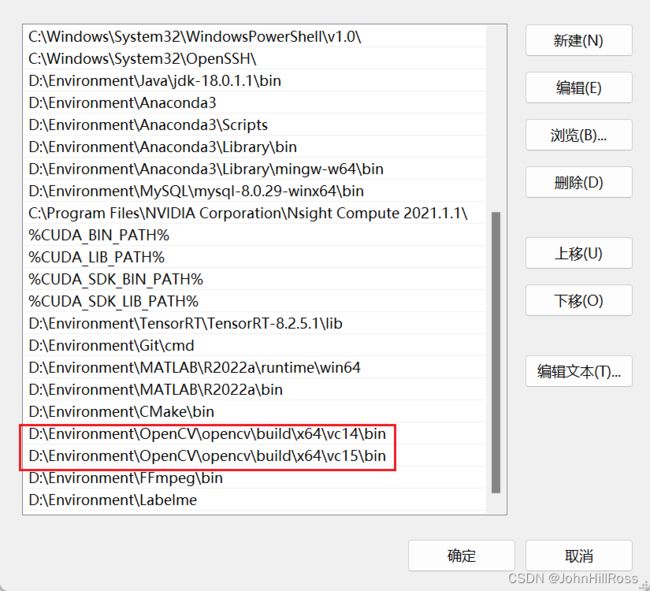
9. 安装CMake
添加环境变量:
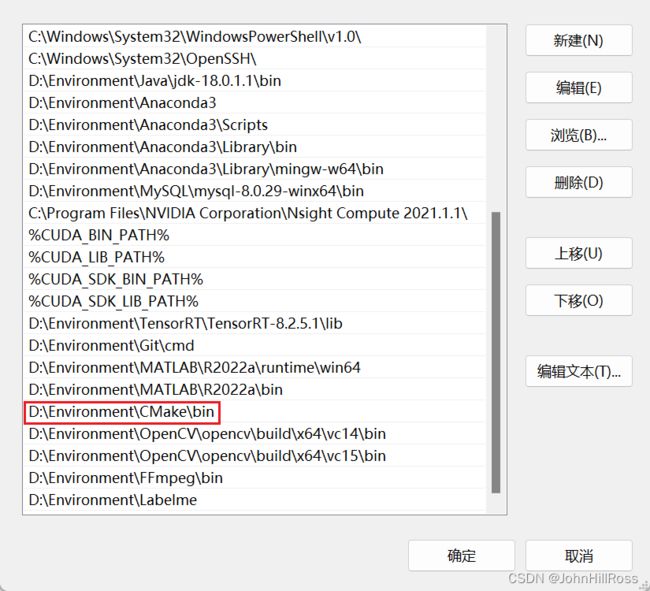
10. 安装Pytorch
https://pytorch.org/get-started/locally/
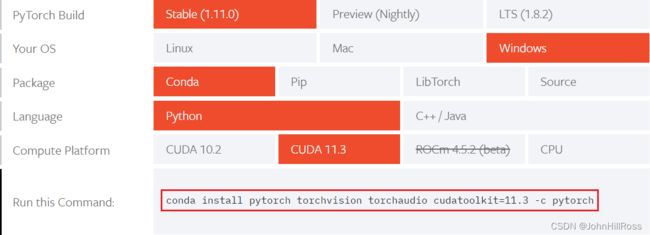
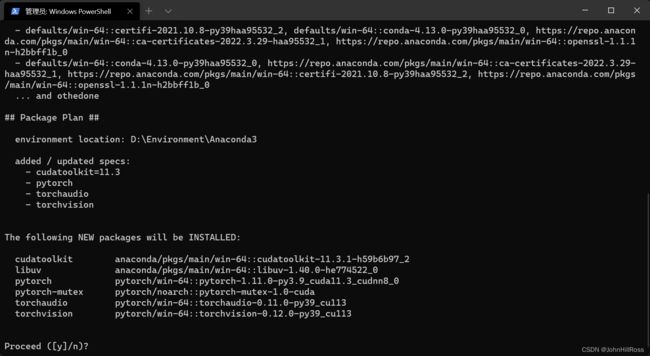
以管理员模式在命令行中运行:
conda create -n pytorch python=3.9
activate pytorch
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
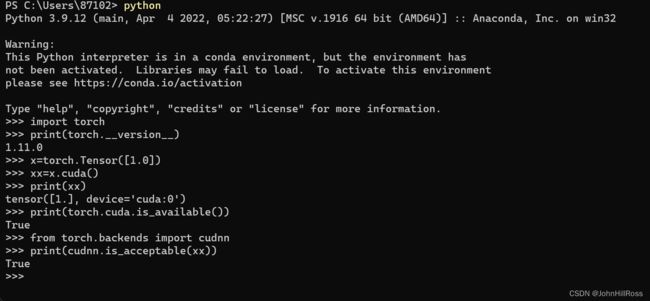
测试:
# cuda test
import torch
print(torch.__version__)
x = torch.Tensor([1.0])
xx = x.cuda()
print(xx)
print(torch.cuda.is_available())
# cudnn test
from torch.backends import cudnn
print(cudnn.is_acceptable(xx))
11. 安装YOLOv5必要依赖包
下载YOLOv5源代码:
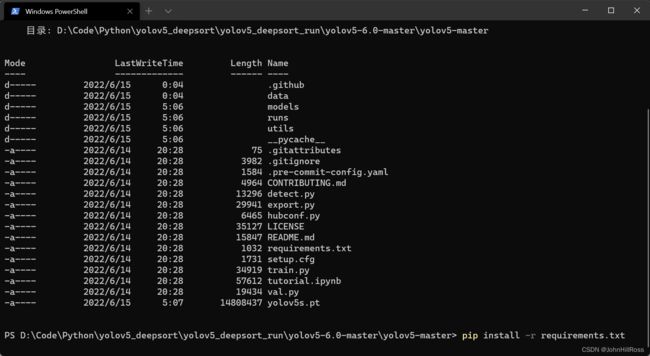
进入XXX\yolov5-master目录执行:
activate pytorch
pip install -r requirements.txt
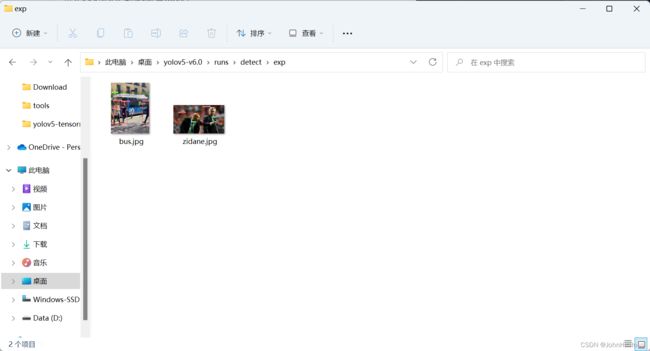
测试:
activate pytorch
python detect.py
运行结果保存在XXX\yolov5-master\runs\detect\exp下
12. YOLOv5使用TensorRT加速
下载YOLOv5 TensorRT加速版本:
https://github.com/wang-xinyu/tensorrtx
在XXX\tensorrtx下创建include文件夹,下载文件dirent.h放置在include文件夹中,
下载地址 https://github.com/tronkko/dirent/tree/master/include/dirent.h
修改XXX\tensorrtx\yolov5目录下CMakeLists.txt内容为(按自己的安装目录修改#1 #2 #3 #4):
cmake_minimum_required(VERSION 2.6)
project(yolov5)
set(OpenCV_DIR "D:/Environment/OpenCV/opencv/build") ##1
set(OpenCV_INCLUDE_DIRS "D:/Environment/OpenCV/opencv/build/include") ##2
set(OpenCV_LIBS "D:\\Environment\\OpenCV\\opencv\\build\\x64\\vc14\\lib\\opencv_world3416.lib") ##3
set(TRT_DIR "D:/Environment/TensorRT/TensorRT-8.2.5.1") ##4
add_definitions(-DAPI_EXPORTS)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(THREADS_PREFER_PTHREAD_FLAG ON)
find_package(Threads)
# setup CUDA
find_package(CUDA REQUIRED)
message(STATUS "libraries: ${CUDA_LIBRARIES}")
message(STATUS "include path: ${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS})
####
enable_language(CUDA) # add this line, then no need to setup cuda path in vs
####
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(${TRT_DIR}\\include)
include_directories(D:\\Environment\\TensorRT\\tensorrtx\\include) ##5
#find_package(OpenCV)
include_directories(${OpenCV_INCLUDE_DIRS})
include_directories(${OpenCV_INCLUDE_DIRS}\\opencv2) #6
# -D_MWAITXINTRIN_H_INCLUDED for solving error: identifier "__builtin_ia32_mwaitx" is undefined
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -D_MWAITXINTRIN_H_INCLUDED")
# setup opencv
find_package(OpenCV QUIET
NO_MODULE
NO_DEFAULT_PATH
NO_CMAKE_PATH
NO_CMAKE_ENVIRONMENT_PATH
NO_SYSTEM_ENVIRONMENT_PATH
NO_CMAKE_PACKAGE_REGISTRY
NO_CMAKE_BUILDS_PATH
NO_CMAKE_SYSTEM_PATH
NO_CMAKE_SYSTEM_PACKAGE_REGISTRY
)
message(STATUS "OpenCV library status:")
message(STATUS "version: ${OpenCV_VERSION}")
message(STATUS "libraries: ${OpenCV_LIBS}")
message(STATUS "include path: ${OpenCV_INCLUDE_DIRS}")
include_directories(${OpenCV_INCLUDE_DIRS})
link_directories(${TRT_DIR}\\lib)
link_directories(${OpenCV_DIR}\\x64\\vc14\\lib) #8
add_executable(yolov5 ${PROJECT_SOURCE_DIR}/calibrator.cpp yolov5 ${PROJECT_SOURCE_DIR}/yolov5.cpp ${PROJECT_SOURCE_DIR}/yololayer.cu ${PROJECT_SOURCE_DIR}/yololayer.h ${PROJECT_SOURCE_DIR}/preprocess.cu ${PROJECT_SOURCE_DIR}/preprocess.h)
target_link_libraries(yolov5 "nvinfer" "nvinfer_plugin") #9
target_link_libraries(yolov5 ${OpenCV_LIBS}) #10
target_link_libraries(yolov5 ${CUDA_LIBRARIES}) #11
target_link_libraries(yolov5 Threads::Threads) #12
在XXX\tensorrtx\yolov5目录下新建build文件夹
运行XXX\CMake\bin\cmake-gui.exe配置:
Where is the source code: XXX\tensorrtx\yolov5
Where to build the binaries: XXX\tensorrtx\yolov5\build

依次执行Configure -> Generate -> Open Project
下载YOLOv5 TensorRT Win10加速版本:
https://github.com/Monday-Leo/Yolov5_Tensorrt_Win10
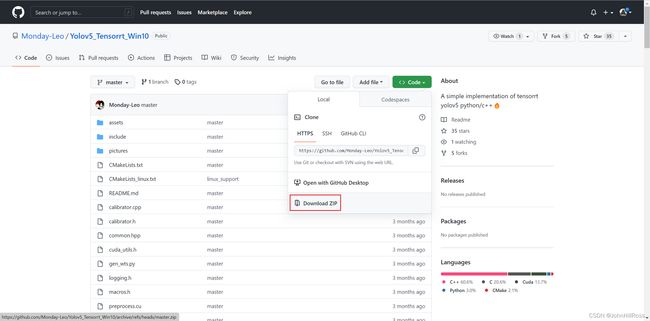
复制XXX\Yolov5_Tensorrt_Win10-master\yolov5.cpp文件内容,替换XXX\tensorrtx\yolov5\yolov5.cpp内容

修改yololayer.h文件20行中的类别数(按需修改)
static constexpr int CLASS_NUM = 4; # 修改类别数
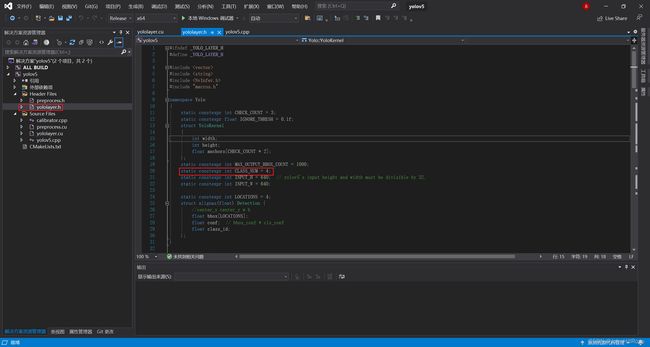
选择重新生成yolov5项目

复制XXX\tensorrtx\yolov5\gen_wts.py到XXX\yolov5-master目录,执行以下代码:
activate pytorch
python gen_wts.py -w yolov5s.pt -o yolov5s.wts
复制XXX\yolov5-master\yolov5s.wts到XXX\tensorrtx\yolov5\build\Release下,执行以下代码:
yolov5.exe -s yolov5s.wts yolov5s.engine s
执行XXX\tensorrtx\yolov5\build下yolov5.sln
右键选择yolov5项目属性
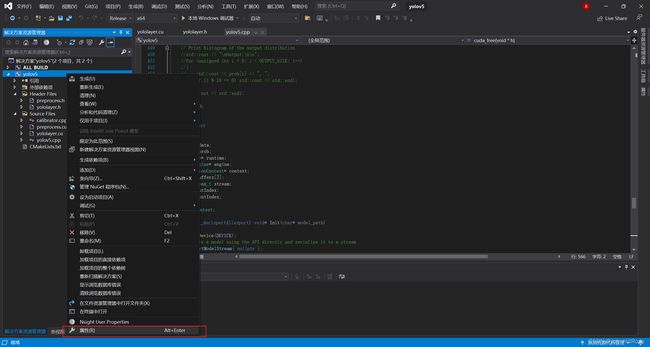
修改配置属性->常规->配置类型为动态库(.dll)

修改配置属性->高级->目标文件扩展名为.dll
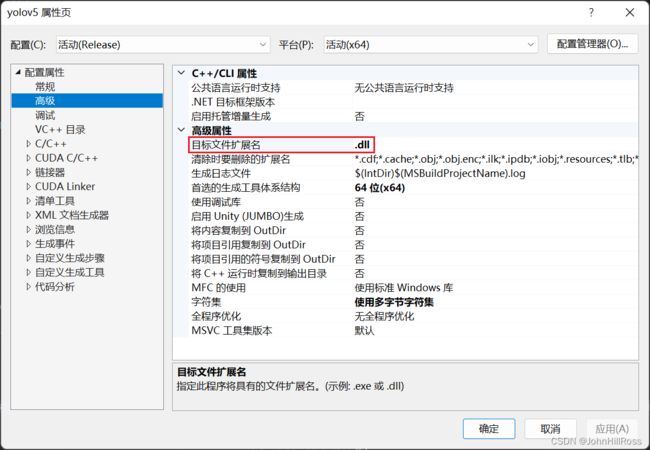
选择重新生成yolov5项目
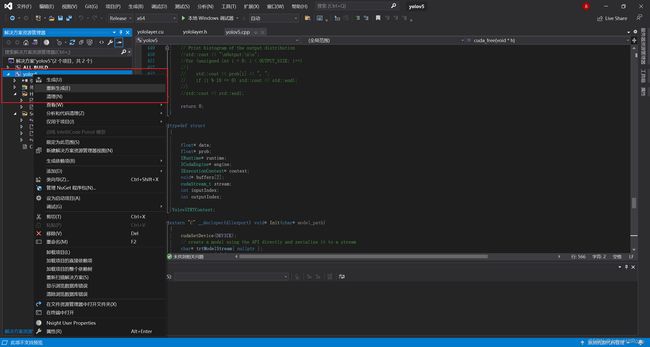
复制XXX\tensorrtx\yolov5\build\Release下yolov5.dll和yolov5s.wts到XXX\Yolov5_Tensorrt_Win10-master
复制XXX\yolov5-master\data\images到XXX\Yolov5_Tensorrt_Win10-master
修改python_trt.py:
img = cv2.imread("./images/bus.jpg")

测试:
activate pytorch
python python_trt.py
三、获取数据集
1. 公共数据集Kaggle、MakeML等:
https://www.kaggle.com/datasets
https://makeml.app/dataset-store
2. 百度图片爬虫:
import json
import itertools
import urllib
import requests
import os
import re
import sys
word = input("请输入关键字:")
pageNum = input("爬取页面数(每个页面含有30张图片):")
path = "D:/Data/CrawlImg"
if not os.path.exists(path):
os.mkdir(path)
urls = []
word = urllib.parse.quote(word)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
url = r"https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=0%2C0&fp=detail&logid=7181752122064024928&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=0&lpn=0&st=-1&word={word}&ic=0&hd=undefined&latest=undefined©right=undefined&s=undefined&se=&tab=0&width=&height=&face=undefined&istype=2&qc=&nc=&fr=&simics=&srctype=&bdtype=0&rpstart=0&rpnum=0&cs=604827192%2C704143832&catename=&force=undefined&album_id=&album_tab=&cardserver=&tabname=&pn={pn}&rn=30&gsm=1&1619190981089="
for i in range(int(pageNum)):
urls.append(url.format(word=word,pn=i*30))
str_table = {
'_z2C$q': ':',
'AzdH3F': '/',
'_z&e3B': '.'
}
char_table = {
'w': 'a',
'k': 'b',
'v': 'c',
'1': 'd',
'j': 'e',
'u': 'f',
'2': 'g',
'i': 'h',
't': 'i',
'3': 'j',
'h': 'k',
's': 'l',
'4': 'm',
'g': 'n',
'5': 'o',
'r': 'p',
'q': 'q',
'6': 'r',
'f': 's',
'p': 't',
'7': 'u',
'e': 'v',
'o': 'w',
'8': '1',
'd': '2',
'n': '3',
'9': '4',
'c': '5',
'm': '6',
'0': '7',
'b': '8',
'l': '9',
'a': '0'
}
i=1
char_table = {ord(key): ord(value) for key, value in char_table.items()}
for url in urls:
html=requests.get(url,headers=headers).text
a=re.compile(r'"objURL":"(.*?)"')
downURL=re.findall(a,html)
for t in downURL:
for key, value in str_table.items():
t = t.replace(key, value)
t=t.translate(char_table)
print(t)
try:
html_1=requests.get(t)
if str(html_1.status_code)[0]=="4":
print('请求失败')
continue
except Exception as e:
print('图片链接不存在')
continue
with open(path+"/"+str(i)+".jpg",'wb') as f:
f.write(html_1.content)
i=i+1
3. FFmpeg视频帧截取:
ffmpeg -i [video] -r [interval] -q:v [quality] -f image2 [name]%03d.jpeg
-r 表示每一秒几帧
-q:v表示存储jpeg的图像质量,一般2是高质量
ffmpeg -i input.mp4 -r 1 -q:v 2 -f image2 pic-%03d.jpeg
如此,ffmpeg会把input.mp4,每隔一秒,存一张图片下来。假设有60s,那会有60张
四、图像标注
1. Labelme图片标注工具:
下载地址https://github.com/wkentaro/labelme/releases/download/v5.0.1/Labelme.exe
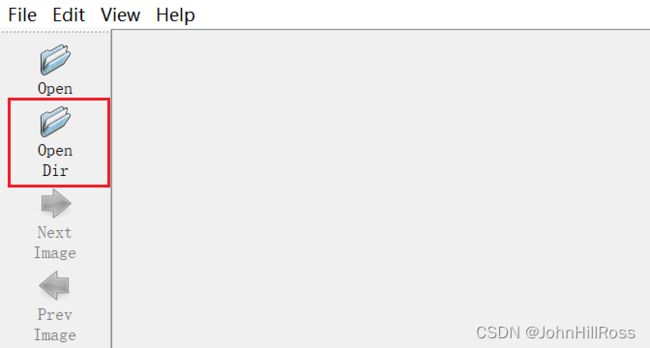
Open Dir设置为图片所在文件夹
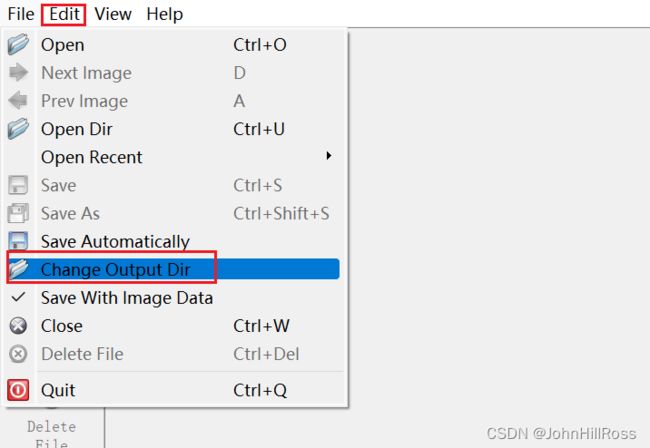
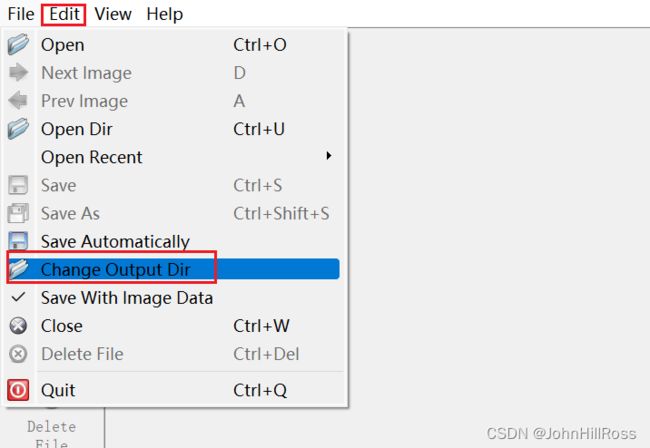
Edit -> Change Output Dir设置lJSON格式标签保存位置
创建数据集目录树
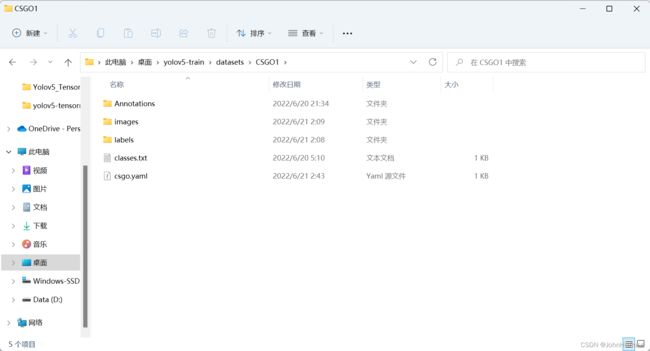
Annotation文件夹保存labelme标注格式标签
images文件夹存放图片
labels文件夹保存YOLO格式标签
classes.txt存储类别名,必须按顺序一行一个类别名

labelme标注格式为JSON需转换为YOLO格式,并划分train、val、test数据集
labelme to yolo
# coding:utf-8
import os
import shutil
import json
import argparse
from sklearn.model_selection import train_test_split
'''
1. One row per object
2. Each row is class x_center y_center width height format.
3. Box coordinates must be in normalized xywh format (from 0 - 1).
If your boxes are in pixels, divide x_center and width by image width, and y_center and height by image height.
4. Class numbers are zero-indexed (start from 0).
'''
parser = argparse.ArgumentParser()
parser.add_argument('--img_dir', default='./datasets/CSGO2/images',type=str, help="path of images")
parser.add_argument('--json_dir', default='./datasets/CSGO2/Annotations', type=str, help="path of json")
parser.add_argument('--classes_path', default='./datasets/CSGO2/classes.txt', type=str, help="path of classes.txt")
parser.add_argument('--txt_dir', default='./datasets/CSGO2/labels', type=str, help="save path of txt")
parser.add_argument('--split_ratio', default=[0.8, 0.1, 0.1], type=str, help="random split the dataset [train, val, test], default ratio is 8:1:1")
arg = parser.parse_args()
sets = ['train', 'val', 'test']
def train_test_val_split_random(img_dir, json_dir, classes_path, txt_dir, split_ratio):
ratio_train = split_ratio[0]
ratio_val = split_ratio[1]
ratio_test = split_ratio[2]
assert int(ratio_train+ratio_test+ratio_val) == 1
imgset_path_list = {}
imgset_path_list[0], middle_img_path = train_test_split(os.listdir(img_dir),test_size=1-ratio_train, random_state=233)
ratio=ratio_val/(1-ratio_train)
imgset_path_list[1], imgset_path_list[2] = train_test_split(middle_img_path,test_size=ratio, random_state=233)
print("NUMS of train:val:test = {}:{}:{}".format(len(imgset_path_list[0]), len(imgset_path_list[1]), len(imgset_path_list[2])))
for index, set in enumerate(sets, 0):
split_imgset_dir = os.path.join(img_dir, set)
if not os.path.exists(split_imgset_dir):
os.makedirs(split_imgset_dir)
for imgset_path in imgset_path_list[index]:
shutil.copy(os.path.join(img_dir, imgset_path), split_imgset_dir)
split_txt_dir = os.path.join(txt_dir, set)
if not os.path.exists(split_txt_dir):
os.makedirs(split_txt_dir)
labelme_to_yolo(split_imgset_dir, json_dir, classes_path, split_txt_dir)
def labelme_to_yolo(split_imgset_dir, json_dir, classes_path, split_txt_dir):
with open(classes_path) as f:
classes = f.read().strip().split()
img_path_list = os.listdir(split_imgset_dir)
for img_path in img_path_list:
if img_path.startswith('.'):
continue
name, suffix = os.path.splitext(img_path)
save_path = os.path.join(split_txt_dir, name + '.txt')
json_path = os.path.join(json_dir, name + '.json')
print('processing -> %s' % json_path)
label_dict = json.load(open(json_path, 'r'))
height = label_dict['imageHeight']
width = label_dict['imageWidth']
loc_info_list = label_dict['shapes']
label_info_list = list()
for loc_info in loc_info_list:
obj_name = loc_info.get('label')
label_id = classes.index(obj_name)
loc = loc_info.get('points')
x0, y0 = loc[0] # 左上角点
x1, y1 = loc[1] # 右下角点
x_center = (x0 + x1) / 2 / width
y_center = (y0 + y1) / 2 / height
box_w = (abs(x1 - x0)) / width # 这里使用绝对值是因为有时候先标注的右下角点
box_h = (abs(y1 - y0)) / height
assert box_w > 0, print((int(x0), int(y0)), (int(x1), int(y1)))
assert box_h > 0
label_info_list.append([str(label_id), str(x_center), str(y_center), str(box_w), str(box_h)])
with open(save_path, 'a') as f:
for label_info in label_info_list:
label_str = ' '.join(label_info)
f.write(label_str)
f.write('\n')
if __name__ == '__main__':
train_test_val_split_random(arg.img_dir, arg.json_dir, arg.classes_path, arg.txt_dir, arg.split_ratio)
复制images和labels文件夹到XXX\yolov5-master\datasets\XXX目录
设置训练数据配置文件xxx.yaml即可用YOLOv5对数据集进行训练

path设置为数据集文件夹
nc设置为类别数
names设置为类别名,必须按顺序
修改XXX\yolov5-master\train.py
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path') # 训练已有模型绝对路径,为空时即重新训练新的模型
parser.add_argument('--data', type=str, default=ROOT / 'datasets/CSGO/csgo.yaml', help='dataset.yaml path') # 训练数据配置文件xxx.yaml绝对路径
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch') # 批大小,提示显存不够设置数值减少一半
parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)') # Windows系统下设置为0
开始训练:
activate pytorch
python train.py
半自动辅助标注:
利用XXX\yolov5-master\detect.py半自动辅助标注,设置detect.py中222行为:
parser.add_argument('--save-txt', default=True, action='store_true', help='save results to *.txt')
运行detect.py:
activate pytorch
python detect.py
标签结果保存在XXX\yolov5-master\runs\detect\expX\labels中,复制labels到数据集目录下的lables中,执行以下代码即可在Annotation文件夹下生成labelme的标注格式JSON文件
yolo to labelme
# coding:utf-8
import os
import cv2
import json
import argparse
import base64
parser = argparse.ArgumentParser()
parser.add_argument('--img_dir', default='./datasets/CSGO2/images',type=str, help="path of images")
parser.add_argument('--txt_dir', default='./datasets/CSGO2/labels', type=str, help="path of txt")
parser.add_argument('--classes_path', default='./datasets/CSGO2/classes.txt', type=str, help="path of classes.txt")
parser.add_argument('--json_dir', default='./datasets/CSGO2/Annotations', type=str, help="save path of json")
arg = parser.parse_args()
def parse_tta_label(img_path, txt_path, classes_path, json_dir):
file_name = img_path.split('\\')[-1].split('.')[0]
imagePath = img_path.split('/')[-1]
img = cv2.imread(img_path)
h, w = img.shape[:2]
with open(img_path, 'rb') as f:
image = f.read()
image_base64 = str(base64.b64encode(image), encoding='utf-8')
version = '5.0.1'
data_dict = dict()
data_dict.__setitem__('version', version)
data_dict.__setitem__('imagePath', imagePath)
data_dict.__setitem__("imageData", image_base64)
data_dict.__setitem__('imageHeight', h)
data_dict.__setitem__('imageWidth', w)
data_dict.__setitem__('flags', {})
data_dict['shapes'] = list()
with open(txt_path, 'r') as f:
label_info_list = f.readlines()
for label_info in label_info_list:
label_info = label_info.strip()
label_info = label_info.split(' ')
class_name = label_info[0]
c_x = float(label_info[1]) * w
c_y = float(label_info[2]) * h
b_w = float(label_info[3]) * w
b_h = float(label_info[4]) * h
x1 = c_x - b_w / 2
x2 = c_x + b_w / 2
y1 = c_y - b_h / 2
y2 = c_y + b_h / 2
points = [[x1, y1], [x2, y2]]
shape_type = 'rectangle'
shape = {}
with open(classes_path) as f:
classes = f.read().strip().split()
shape.__setitem__('label', classes[int(class_name)])
shape.__setitem__('points', points)
shape.__setitem__('shape_type', shape_type)
shape.__setitem__('flags', {})
shape.__setitem__('group_id', None)
data_dict['shapes'].append(shape)
save_json_path = os.path.join(json_dir, '%s.json' % file_name)
json.dump(data_dict, open(save_json_path, 'w'), indent=4)
def generate_labelme_prelabel(img_dir, txt_dir, classes_path, json_dir):
img_name_list = os.listdir(img_dir)
for img_name in img_name_list:
if img_name.startswith('.'):
continue
txt_name = img_name.replace('images','txt').replace('.jpg','.txt').replace('.jpeg','.txt').replace('.png','.txt')
print('processing -> %s' % txt_name)
img_path = os.path.join(img_dir, img_name)
txt_path = os.path.join(txt_dir, txt_name)
parse_tta_label(img_path, txt_path, classes_path, json_dir)
if __name__ == '__main__':
generate_labelme_prelabel(arg.img_dir, arg.txt_dir, arg.classes_path, arg.json_dir)
Open Dir设置为图片所在文件夹

Edit -> Change Output Dir设置lJSON格式标签保存位置
利用labelme进行人工修整后,按labelme to yolo方法转换标签格式再给YOLOv5训练
2. AI标注:
飞桨BML:
https://blog.csdn.net/weixin_42217041/article/details/119250959
五、训练平台
1. 免费算力平台:
Google Colab:
利用Google Colab训练YOLOv5
教程:
https://blog.csdn.net/djstavav/article/details/112261905
MultCloud:
利用MultCloud把OneDrive数据集传出到Google Colab
教程:
https://blog.csdn.net/AWhiteDongDong/article/details/107928536
六、Demo
https://github.com/johnhillross/YOLOv5_TensorRT_Win
顺便臭不要脸要个Star⭐️
七、参考资料
[1] https://github.com/ultralytics/yolov5
[2] https://github.com/wang-xinyu/tensorrtx
[3] https://github.com/Monday-Leo/Yolov5_Tensorrt_Win10
[4] https://blog.csdn.net/qq_41319718/article/details/123075288