Bidirectional Learning for Domain Adaptation of Semantic Segmentation翻译
Bidirectional Learning for Domain Adaptation of Semantic Segmentation
Abstract(摘要)
Domain adaptation for semantic image segmentation is very necessary since manually labeling large datasets with pixel-level labels is expensive and time consuming. Existing domain adaptation techniques either work on limited datasets, or yield not so good performance compared with supervised learning. In this paper, we propose a novel bidirectional learning framework for domain adaptation of segmentation. Using the bidirectional learning,the image translation model and the segmentation adaptation model can be learned alternatively and promote to each other. Furthermore, we propose a self-supervised learning algorithm to learn a better segmentation adaptation model and in return improve the image translation model. Experiments show that our method is superior to
the state-of-the-art methods in domain adaptation of segmentation with a big margin. The source code is available at https://github.com/liyunsheng13/BDL.
对于语义图像分割而言,域自适应非常必要,因为使用像素级标签手动标记大型数据集既昂贵又耗时。 现有的领域自适应技术要么在有限的数据集上起作用,要么与有监督的学习相比效果不佳。 在本文中,我们提出了一种新颖的双向学习框架,用于分段的领域适应。 使用双向学习,可以交替学习图像翻译模型和分割适应模型并相互促进。 此外,我们提出了一种自我监督的学习算法,以学习更好的分割自适应模型并反过来改善图像翻译模型。 实验表明,在分割的领域自适应方面,我们的方法优于最新方法。 源代码可从https://github.com/liyunsheng13/BDL获得。
Introduction(介绍)
Recent progress on image semantic segmentation [18] has been driven by deep neural networks trained on large datasets. Unfortunately, collecting and manually annotating large datasets with dense pixel-level labels has been extremely costly due to large amount of human effort is required. Recent advances in computer graphics make it possible to train CNNs on photo-realistic synthetic images with computer-generated annotations [27, 28]. Despite this, the domain mismatch between the real images (target) and the synthetic data (source) cripples the models’ performance.Domain adaptation addresses this domain shift problem.Specifically, we focus on the hard case of the problem where no labels from the target domain are available. This class of techniques is commonly referred to as Unsupervised Domain Adaptation.
在大型数据集上训练的深度神经网络已经推动了图像语义分割的最新进展[18]。 不幸的是,由于需要大量的人工,收集具有密集像素级标签的大型数据集并对其进行手动注释非常昂贵。 计算机图形学的最新进展使得可以在具有计算机生成的注释的逼真的合成图像上训练CNN [27,28]。 尽管如此,实际图像(目标)和合成数据(源)之间的域不匹配会破坏模型的性能。域自适应解决了该域偏移问题,特别是,我们专注于问题的棘手情况,即标签中没有标签 目标域可用。 这类技术通常称为无监督域自适应。
Traditional methods for domain adaptation involve minimizing some measure of distance between the source and the target distributions. Two commonly used measures are the first and second order moment [2], and learning the distance metrics using Adversarial approaches [34, 35]. Both
approaches have had good success in the classification problems (e.g., MNIST [16], USPS [7] and SVHN [22]); however, as pointed out in [37], their performance is quite limited on the semantic segmentation problem.
传统的域自适应方法包括最小化源和目标分布之间距离的某种度量。 两种常用的度量是一阶矩和二阶矩[2],以及使用对抗性方法学习距离度量[34,35]。 两种方法都在分类问题上取得了成功(例如,MNIST [16],USPS [7]和SVHN [22]); 然而,正如[37]中指出的那样,它们的性能在语义分割问题上非常有限。
Recently, domain adaptation for semantic segmentation has made good progress by separating it into two sequential steps. It firstly translates images from the source domain to the target domain with an image-to-image translation model (e.g., CycleGAN [38]) and then add a discriminator on top of the features of the segmentation model to further decrease the domain gap [12, 36]. When the domain gap is reduced by the former step, the latter one is easy to learn and can further decrease the domain shift. Unfortunately, the segmentation model very relies on the quality of imageto-image translation. Once the image-to-image translation
fails, nothing can be done to make it up in the following stages.
最近,用于语义分段的域自适应通过将其分为两个连续步骤而取得了良好的进展。 它首先使用图像到图像转换模型(例如,CycleGAN [38])将图像从源域转换为目标域,然后在分割模型的特征之上添加鉴别符以进一步减小域间隙[ 12、36]。 当通过前一步减小域间隙时,后一个步骤易于学习并且可以进一步减小域偏移。 不幸的是,分割模型非常依赖于图像到图像翻译的质量。 一旦图像到图像转换失败,则在以下阶段将无法进行任何处理。
In this paper, we propose a new bidirectional learning
framework for domain adaptation of image semantic segmentation. The system involves two separated modules:image-to-image translation model and segmentation adaptation model similar to [12, 36], but the learning process involves two directions (i.e., “translation-to-segmentation”and “segmentation-to-translation”). The whole system forms a closed-loop learning. Both models will be motivated to promote each other alternatively, causing the domain gap to be gradually reduced. Thus, how to allow one of both modules providing positive feedbacks to the other is
the key to success.
在本文中,我们提出了一种新的双向学习框架,用于图像语义分割的领域自适应。 该系统包括两个分离的模块:图像到图像翻译模型和类似于[12,36]的分段适应模型,但是学习过程涉及两个方向(即“翻译到分段”和“分段到翻译” ”)。 整个系统形成闭环学习。 两种模型都会相互促进,相互促进,从而导致域差距逐渐减小。 因此,如何允许两个模块中的一个向另一个模块提供正面反馈是成功的关键。
On the forward direction (i.e., “translation-tosegmentation”, similar to [12, 36]), we propose a self-supervised learning (SSL) approach in training our
segmentation adaptation model. Different from segmentation models trained on real data, the segmentation adaptation model is trained on both synthetic and real datasets, but the real data has no annotations. At every
time, we may regard the predicted labels for real data with high confidence as the approximation to the ground truth labels, and then use them only to update the segmentation adaptation model while excluding predicted labels with low confidence. This process is referred as self-supervised
learning, which aligns two domains better than one-trial learning that is widely used in existing approaches. Furthermore, better segmentation adaptation model would contribute to better translation model through our backward direction learning。
在向前的方向上(即类似于[12,36]的“翻译到细分”),我们提出了一种自我监督学习(SSL)方法来训练我们的细分适应模型。 与在真实数据上训练的分割模型不同,分割适应模型在合成和真实数据集上训练,但是真实数据没有注释。 每次,我们都可以将具有高置信度的真实数据的预测标签视为与地面真值标签的近似值,然后仅将其用于更新分段适应模型,同时排除具有低置信度的预测标签。 此过程称为自我监督学习,它比在现有方法中广泛使用的一次尝试学习更好地将两个领域对齐。 此外,更好的细分适应模型将通过我们的反向学习为更好的翻译模型做出贡献。
On the backward direction (i.e., “segmentation-totranslation”), our translation model would be iteratively improved by the segmentation adaptation model, which is different from [12, 36] where the image-to-image translation is not updated once the model is trained. For the purpose,we propose a new perceptual loss, which forces the semantic consistency between every image pixel and its translated version, to build the bridge between translation model and segmentation adaptation model. With the constraint in the translation model, the gap in visual appearance (e.g., lighting, object textures), between the translated images and real
datasets (target) can be further decreased. Thus, the segmentation model can be further improved through our forward direction learning.
在向后的方向上(即“从分段到翻译”),我们将通过分段自适应模型来迭代地改进我们的翻译模型,这与[12,36]不同,后者[12,36]中的图像-图像翻译不会立即更新一旦模型受过训练。 为此,我们提出了一种新的感知损失,它迫使每个图像像素与其翻译版本之间的语义一致性,从而在翻译模型与分段适应模型之间架起桥梁。 利用翻译模型中的约束,可以进一步减小翻译图像与真实数据集(目标)之间的视觉外观(例如,照明,物体纹理)之间的差距。 因此,可以通过我们的前向学习进一步细分模型。
From the above two directions, both the translation model and the segmentation adaptation model complement each other, which helps achieve state-of-theart performance in adapting large-scale rendered image dataset SYNTHIA [28]/GTA5 [27], to real image dataset,
Cityscapes [5], and outperform other methods by a large margin. Moreover, the proposed method is general to different kinds of backbone networks。
从以上两个方向来看,翻译模型和分段自适应模型两者相辅相成,这有助于在将大规模渲染图像数据集SYNTHIA [28] / GTA5 [27]适应实际图像数据集时达到最新的性能 ,Cityscapes [5],并且在很大程度上优于其他方法。 而且,该方法适用于不同类型的骨干网。
In summary, our key contributions are:
- We present a bidirectional learning system for semantic segmentation, which is a closed loop to learn the segmentation adaptation model and the image translation model alternatively.
- We propose a self-supervised learning algorithm for the segmentation adaptation model, which incrementally align the source domain and the target domain at the feature level, based on the translated results.
- We introduce a new perceptual loss to the image-toimage translation, which supervises the translation by the updated segmentation adaptation model.
总而言之,我们的主要贡献是:
1.我们提出了一种用于语义分割的双向学习系统,它是一个闭环,可以交替学习分割自适应模型和图像翻译模型。
2.我们为分割自适应模型提出了一种自我监督的学习算法,该算法根据翻译的结果在特征级别上逐步对齐源域和目标域。
3.我们在图像到图像的翻译中引入了新的感知损失,它通过更新的分割适应模型来监督翻译。
Related Work(相关工作)
Domain Adaptation. When transferring knowledge from virtual images to real photos, it is often the case that there exists some discrepancy from the training to the test stage.Domain adaptation aims to rectify this mismatch and tune the models toward better generalization at testing [24]. The existing work on domain adaptation has mainly focused on image classification [30]. A lot of work aims to learn domain-invariant representations through minimizing the domain distribution discrepancy. Maximum Mean Discrepancy (MMD) loss [8], computing the mean of representations, is a common distance metric between two domains.
As the extension to MMD, some statistics of feature distributions such as mean and covariance [2, 21] are used to match two different domains. Unfortunately, when the distribution is not Gaussian, solely matching mean and covariance is not enough to align the two different domains well.
域适应。 当将知识从虚拟图像转换为真实照片时,通常是从培训到测试阶段存在一些差异。 域自适应的目的是纠正这种不匹配,并在测试时将模型调整为更好的泛化[24]。 现有的领域适应工作主要集中在图像分类上[30]。 许多工作旨在通过最小化域分布差异来学习域不变表示。 最大平均差异(MMD)损失[8],是计算表示形式的平均值,是两个域之间的通用距离度量。作为对MMD的扩展,使用了一些特征分布的统计数据,例如平均值和协方差[2,21]。 匹配两个不同的域。 不幸的是,当分布不是高斯分布时,仅均值和协方差匹配不足以使两个不同的域很好地对齐。
Adversarial learning [9] recently becomes popular, and another kind of domain adaptation methods. It reduces the domain shift by forcing the features from different domains to fool the discriminator. [34] would be the pioneer work,which introduces an adversarial loss on top of the high-level
features of the two domains with the classification loss for the source dataset and achieves a better performance than the statistical matching methods. Expect for adversarial loss, some work proposed some extra loss functions to further decrease the domain shift, such as reweighted function for each class [4], and disentangled representations for separated matching [35]. All of these methods work on simple and small classification datasets (e.g., MNIST [16] and SVHN [22]), and may have quite limited performance in more challenging tasks, like segmentation.
对抗学习[9]最近变得流行,这是另一种领域适应方法。 它通过强制来自不同域的要素来欺骗区分符来减少域偏移。 [34]将是开创性的工作,它在两个域的高级特征之上引入对抗性损失,并对源数据集进行分类损失,并且比统计匹配方法具有更好的性能。 期望对抗性损失,一些工作提出了一些额外的损失函数以进一步减少域偏移,例如,针对每个类别的重新加权函数[4],以及用于分离匹配的解缠结表示[35]。 所有这些方法都可用于简单和小的分类数据集(例如MNIST [16]和SVHN [22]),并且在更具挑战性的任务(如分段)中的性能可能非常有限。
Domain Adaptation for Semantic Segmentation. Recently, more domain adaptation techniques are proposed for semantic segmentation models, since an enormous amount of labor-intensive work is required to annotate so many images that are needed to train high-quality segmentation networks. A possible solution to alleviate the human efforts
is to train networks on virtual data which is labeled automatically. For example, GTA5 [27] and SYHTHIA [28] are two popular synthetic datasets of city streets with overlapped categories, similar views to the real datasets (e.g.,CITYSCAPE [5], CamVid [1]). Domain adaptation can be used to align the synthetic and the real datasets.
语义分割的域自适应。 最近,由于语义标注模型需要大量的劳动密集型工作来注释训练训练高质量的分割网络所需的大量图像,因此提出了更多的领域自适应技术。 减轻人为负担的一种可能的解决方案是在自动标记的虚拟数据上训练网络。 例如,GTA5 [27]和SYHTHIA [28]是两个热门的城市街道合成数据集,具有重叠的类别,与真实数据集的视图相似(例如,CITYSCAPE [5],CamVid [1])。 域自适应可用于对齐合成数据集和真实数据集。
The first work to introduce domain adaptation for semantic segmentation is [13], which does the global and local alignments between two domains in the feature level. Curriculum domain adaptation [37] estimates the global distribution and the labels for the superpixel, and then learns a segmentation model for the finer pixel. In [33], multiple discriminators are used for different level features to reduce domain discrepancy. In [31], foreground and background classes are separately treated for decreasing the domain shift respectively. All these methods target to directly align features between two domains. Unfortunately, the visual (e.g.,appearance, scale, etc.) domain gap between synthetic and real data usually makes it difficult for the network to learn transferable knowledge.
引入用于语义分割的域自适应的第一项工作是[13],它在特征级别对两个域进行了全局和局部对齐。 课程域适应[37]估计超像素的全局分布和标签,然后学习较精细像素的分割模型。 在[33]中,多个鉴别符用于不同级别的特征以减少域差异。 在[31]中,分别对前景类和背景类进行处理,以分别减小域偏移。 所有这些方法都旨在直接在两个域之间对齐要素。 不幸的是,合成数据和真实数据之间的视觉(例如外观,比例等)域间隙通常使网络难以学习可传递的知识。
Motivated by the recent progress of unpaired image-toimage translation work (e.g., CycleGAN [38], UNIT [17],MUNIT [14]), the mapping from virtual to realistic data is regarded as the image synthesis problem. It can help reduce the domain discrepancy before training the segmentation models. Based on the translated results, Cycada [12] and DCAN [36] further align features between two domains in feature level. By separately reducing the domain shift in learning, these approaches obtained the state-of-the-art performance. However, the performance is limited by the
quality of image-to-image translation. Once it fails, nothing can be done in the following step. To address this problem,we introduce a bidirectional learning framework where both translation and segmentation adaption models can promote each other in a closed loop.
受近期不成对的图像到图像翻译工作的推动(例如CycleGAN [38],UNIT [17],MUNIT [14]),从虚拟数据到现实数据的映射被视为图像合成问题。 在训练分割模型之前,它可以帮助减少域差异。 根据翻译结果,Cycada [12]和DCAN [36]在特征级别进一步在两个域之间对齐特征。 通过分别减少学习中的领域转移,这些方法获得了最新的性能。 但是,性能受到图像到图像转换质量的限制。 一旦失败,则在接下来的步骤中将无法执行任何操作。 为了解决这个问题,我们引入了双向学习框架,其中翻译和分段适应模型都可以在闭环中相互促进。
There are two most related work. In [6], the segmentation model is also used to improve the image translation, but not to adapt the source domain to the target domain since it is only trained on source data. [39] also proposed a selftraining method for training the segmentation model iteratively. However, the segmentation model is only trained on source data and uses none of image translation techniques。
有两项最相关的工作。 在[6]中,分割模型还用于改善图像翻译,但由于源模型仅在源数据上进行训练,因此无法使源域适应目标域。 [39]也提出了一种自训练方法来迭代训练分割模型。 但是,分割模型仅在源数据上训练,并且不使用任何图像翻译技术。
Bidirectional Learning. The kind of techniques were first proposed to solve the neural machine translation problem, such as [10, 23], which train a language translation model for both directions of a language pair. It improves the performance compared with the uni-direction learning and reduces the dependency on large amount of data. Bidirectional learning techniques were also extended to image generation problem [25], which trains a single network for both classification and image generation problem from both top-to-down and down-to-top directions. A more related work [29] proposed bidirectional image translation (i.e.,source-to-target, and target-to-source), then trained two classifiers on both domains respectively and finally fuses the classification results. By contrast, our bidirectional learning refers to translation boosting the performance of segmentation and vise verse. The proposed method is used to deal with the semantic segmentation task.
双向学习。 首先提出了解决神经机器翻译问题的技术,例如[10,23],该技术训练了语言对的两个方向的语言翻译模型。 与单向学习相比,它提高了性能,并减少了对大量数据的依赖性。 双向学习技术也扩展到了图像生成问题[25],它从上到下和从上到下的方向训练了一个用于分类和图像生成问题的单一网络。 一项更相关的工作[29]提出了双向图像翻译(即,源到目标和目标到源),然后分别在两个域上训练了两个分类器,最后融合了分类结果。 相比之下,我们的双向学习指的是翻译,它提高了分段和台词的表现。 该方法用于处理语义分割任务。
Method
Given the source dataset S with segmentation labels YS(e.g., synthetic data generated by computer graphics) and the target dataset T with no labels (i.e., real data), we want to train a network for semantic segmentation, which is finally tested on the target dataset T . Our goal is to make its performance to be as close as possible to the model trained on T with ground truth labels YT . The task is unsupervised domain adaptation for semantic segmentation. The task is not easy since the visual (e.g., lighting, scale, object textures, etc.) domain gap between S and T makes it difficult for the network to learn transferable knowledge at once.
假设源数据集S具有分段标签YS(例如,计算机图形生成的合成数据)和目标数据集T没有标签(即实际数据),我们希望训练一个用于语义分段的网络,最后对该网络进行测试 目标数据集T。 我们的目标是使它的性能尽可能接近在带有地面真实性标签YT的T上训练的模型。 该任务是用于语义分割的无监督域自适应。 由于S和T之间的视觉(例如照明,比例尺,对象纹理等)域间隙使网络难以立即学习可传递的知识,因此该任务并不容易。
To address this problem, the recent work [12] proposed two separated subnetworks. One is image-to-image translation subnetwork F which learn to translate an image from S to T in absence of paired examples. The another is segmentation adaptation subnetwork M that is trained on translated results F(S), which have the same labels YS to S, and the
target images T with no labels. Both subnetworks are learnt in a sequential way shown in Figure 1(a). Such a two-stage solution has two advantages: 1) F helps decrease the visual domain gap; 2) when domain gap is reduced, M is easy to learn, causing better performance. However, the solution has some limitations. Once F is learnt, it is fixed. There is
no feedback from M to boost the performance of F. Besides, one-trial learning for M seems to just learn limited transferable knowledge.
为了解决这个问题,最近的工作[12]提出了两个分离的子网。 一个是图像到图像转换子网络F,它学习在没有配对示例的情况下将图像从S转换为T。 另一个是分割适应子网M,其在翻译结果F(S)上进行训练,翻译结果F(S)具有相同的标签YS到S,而目标图像T没有标签。 两个子网以图1(a)所示的顺序方式学习。 这样的两阶段解决方案具有两个优点:1)F帮助减小视域间隙; 2)当域间隙减小时,M很容易学习,从而导致更好的性能。 但是,该解决方案有一些限制。 一旦学习到F,就将其固定。 M没有反馈可以提高F的性能。此外,M的一次尝试学习似乎只是学习有限的可转让知识。
In this section, we propose a new learning framework which can address the above two issues well. We inherit the way of separated subnetworks, but employ a bidirectional learning instead (in Section 3.1), which uses a closed-loop to iteratively update both F and M. Furthermore, we introduce a self-supervised learning to allow M being selfmotivated in training (in Section 3.2). The network architecture and loss functions are presented in Section 3.3.
在本节中,我们提出了一个新的学习框架,可以很好地解决上述两个问题。 我们继承了分离子网的方式,但是采用了双向学习(在3.1节中),它使用闭环来迭代更新F和M。此外,我们引入了一种自我监督学习,以使M在训练中自我激励 (在第3.2节中)。 网络架构和丢失功能在第3.3节中介绍。
Bidirectional Learning(双向学习)
Our learning consists of two directions shown in Figure 1(b)
我们的学习包括两个方向,如图1(b)所示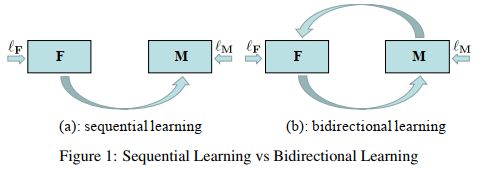
 前进方向(即F-> M)类似于先前顺序学习的行为[12]。 我们首先使用来自T和S的图像训练图像到图像的翻译模型F,然后获得翻译结果S0 = F(S)。请注意,F不会更改S0的标签,这与 YS(S的标签)。 接下来,我们使用带有YS和T的S0训练分段自适应模型M。 学习M的损失函数可以定义为:
前进方向(即F-> M)类似于先前顺序学习的行为[12]。 我们首先使用来自T和S的图像训练图像到图像的翻译模型F,然后获得翻译结果S0 = F(S)。请注意,F不会更改S0的标签,这与 YS(S的标签)。 接下来,我们使用带有YS和T的S0训练分段自适应模型M。 学习M的损失函数可以定义为:
![]()
 其中ladv是对抗性损失,它使S0的特征表示与T的特征表示之间的距离(在S0,T馈入M后获得)尽可能小。 lseg测量语义分割的损失。 由于只有S0具有标签,因此我们仅测量翻译后的源图像S0的准确性。
其中ladv是对抗性损失,它使S0的特征表示与T的特征表示之间的距离(在S0,T馈入M后获得)尽可能小。 lseg测量语义分割的损失。 由于只有S0具有标签,因此我们仅测量翻译后的源图像S0的准确性。
The backward direction (i.e., M->F) is newly added. The motivation is to promote F using updated M. In [35,14], a perceptual loss, which measures the distance of features obtained from a pre-trained network on object recognition, is used in the image translation network to improve the quality of translated result. Here, we use M to compute features for measuring the perceptual loss. By adding theother two losses: GAN loss and image reconstruction loss,the loss function for learning F can be defined as:
向后的方向(即M-> F)是新添加的。其动机是使用更新的M来促进F。在[35,14]中,感知损失用于衡量从预先训练的网络获得的特征的距离。 目标识别,用于图像翻译网络中以提高翻译结果的质量。 在这里,我们使用M来计算用于测量感知损失的特征。 通过将GAN损失和图像重建损失这两个损失相加,可以将学习F的损失函数定义为:
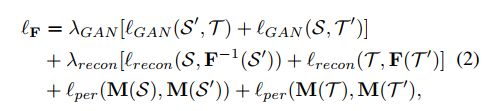

其中对称地计算三个损失,即S-> T和T-> S,以确保图像到图像的转换一致。 GAN损失lGAN强制S0和T之间的两个分布彼此相似。 T 0 = F-1(T),其中F-1是F的反函数,它将图像从T映射到S。
当从S0的图像转换回S时,损失’重构测量重建误差。lper是我们建议维持S和S0之间或T和T 0之间的语义一致性的感知损失。 即使S和S0之间或T和T 0之间存在可视间隙,理想的分割自适应模型M(无论S和S0还是T和T 0都应具有相同的标签)。
Self-supervised Learning for Improving M自我监督学习以提高M
 在正向方向(即F-> M),如果标签对源域S和目标域T均可用,则完全监督的分段损失lseg始终是减少域差异的最佳选择。 但是在我们的例子中,目标数据集的标签丢失了。 众所周知,自监督学习(SSL)以前曾用于半监督学习中,尤其是在数据集标签不足或嘈杂的情况下。 在这里,我们使用SSL来帮助提升细分适应模型M。
在正向方向(即F-> M),如果标签对源域S和目标域T均可用,则完全监督的分段损失lseg始终是减少域差异的最佳选择。 但是在我们的例子中,目标数据集的标签丢失了。 众所周知,自监督学习(SSL)以前曾用于半监督学习中,尤其是在数据集标签不足或嘈杂的情况下。 在这里,我们使用SSL来帮助提升细分适应模型M。
 基于T的预测概率,我们可以获得具有较高置信度的伪标记YbT。 一旦有了伪标签,相应的像素就可以根据分割损失直接与S对齐。 因此,我们将用于学习M(等式1)的总体损失函数修改为:
基于T的预测概率,我们可以获得具有较高置信度的伪标记YbT。 一旦有了伪标签,相应的像素就可以根据分割损失直接与S对齐。 因此,我们将用于学习M(等式1)的总体损失函数修改为:

 其中Tssl⊂T是目标数据集的子集,其中像素具有伪标记YbT。 一开始可以为空。 当获得更好的分割适应模型M时,我们可以使用M预测T的更多高可信度标签,从而导致Tssl的大小增加。 最近的工作[39]也使用SSL进行分段自适应。 相比之下,我们的工作中使用的SSL与对抗性学习相结合,这对于细分适应模型可以更好地工作。
其中Tssl⊂T是目标数据集的子集,其中像素具有伪标记YbT。 一开始可以为空。 当获得更好的分割适应模型M时,我们可以使用M预测T的更多高可信度标签,从而导致Tssl的大小增加。 最近的工作[39]也使用SSL进行分段自适应。 相比之下,我们的工作中使用的SSL与对抗性学习相结合,这对于细分适应模型可以更好地工作。

 我们使用插图(如图2所示)来解释此过程的原理。 当我们第一次学习分段自适应模型时,Tssl为空,并且可以通过等式1所示的损耗来减小S和T之间的域间隙。此过程如图2(a)所示。 然后,我们在目标域T中选取与S完全对齐的点,以构建子集Tssl。第二步,我们可以轻松地将Tssl移至S并借助由 伪标签。 此过程显示在图2(b)的中间。 因此,减少了T中需要与S对齐的数据量。 我们可以继续将剩余数据移至与步骤1相同的S,如图2(b)的右侧所示。 值得注意的是,由于ladv几乎无法更改已很好对齐的S和Tssl中的数据,因此SSL有助于对抗性学习过程专注于未在每个步骤中完全对齐的其余数据。
我们使用插图(如图2所示)来解释此过程的原理。 当我们第一次学习分段自适应模型时,Tssl为空,并且可以通过等式1所示的损耗来减小S和T之间的域间隙。此过程如图2(a)所示。 然后,我们在目标域T中选取与S完全对齐的点,以构建子集Tssl。第二步,我们可以轻松地将Tssl移至S并借助由 伪标签。 此过程显示在图2(b)的中间。 因此,减少了T中需要与S对齐的数据量。 我们可以继续将剩余数据移至与步骤1相同的S,如图2(b)的右侧所示。 值得注意的是,由于ladv几乎无法更改已很好对齐的S和Tssl中的数据,因此SSL有助于对抗性学习过程专注于未在每个步骤中完全对齐的其余数据。
 Network and Loss Function网络和损失函数
Network and Loss Function网络和损失函数
In this section, we introduce the network architecture(shown in Figure 3), details of loss functions and the training process (shown in Algorithm 1). The network is mainly composed with two components – the image translation model and segmentation adaptation model.
在本节中,我们介绍网络架构(如图3所示),损失函数的详细信息和训练过程(如算法1所示)。 该网络主要由两个部分组成-图像转换模型和分段适应模型。
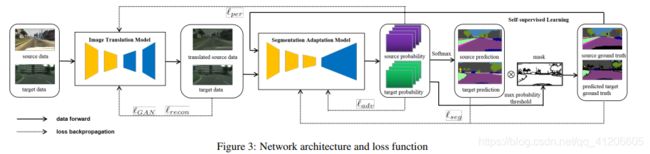
 在学习转换模型的同时,损耗lGAN和损耗lrecon(如图3和公式2所示)可以定义为:
在学习转换模型的同时,损耗lGAN和损耗lrecon(如图3和公式2所示)可以定义为:
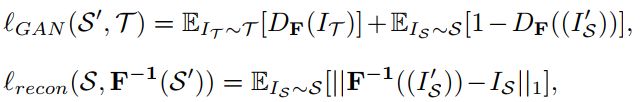

 其中IS和IT是来自源数据集和目标数据集的输入图像。 IS0是F给定的转换图像。DF是添加的区分符,以减少IT和I0S之间的差异。 对于重建损失,当F-1是F的逆函数时,L1范数用于保持IS和F-1(IS0)之间的循环一致性。这里,我们仅显示一个方向的两个损失,而lGAN(S; T 0); 可以类似地定义lrecon(T; F(T 0))。
其中IS和IT是来自源数据集和目标数据集的输入图像。 IS0是F给定的转换图像。DF是添加的区分符,以减少IT和I0S之间的差异。 对于重建损失,当F-1是F的逆函数时,L1范数用于保持IS和F-1(IS0)之间的循环一致性。这里,我们仅显示一个方向的两个损失,而lGAN(S; T 0); 可以类似地定义lrecon(T; F(T 0))。

如图3所示,感知损失Lper连接翻译模型和分段自适应模型。 当我们学习翻译模型的感知损失lper时,我们不仅仅保持IS及其翻译结果IS0之间的语义一致性,还添加了另一个以λperrecon加权的术语,以保持IS及其对应的重构之间的语义一致性(F− 1(IS0))。 使用新术语,翻译模型可以更稳定,尤其是对于重建部分而言。 lper定义为:
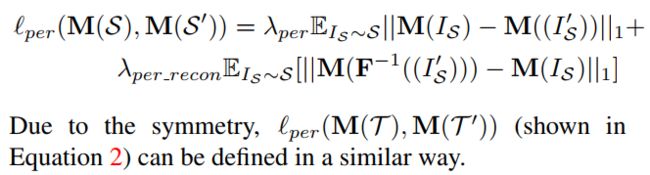
由于对称,lper(M(T); M(T 0))(如图所示公式2)可以用类似的方式定义。
 训练分段适应模型时,它需要使用损失ladv进行对抗学习,并使用损失lseg进行自我监督学习(如公式3所示)。 对于对抗性学习,我们添加了一个鉴别器DM来减小图3所示的源概率和目标概率之间的差异。ladv可以定义为:
训练分段适应模型时,它需要使用损失ladv进行对抗学习,并使用损失lseg进行自我监督学习(如公式3所示)。 对于对抗性学习,我们添加了一个鉴别器DM来减小图3所示的源概率和目标概率之间的差异。ladv可以定义为:


分割损失lseg使用交叉熵损失。 对于源映像IS,lseg可以定义为:



其中yS是IS的标签图,C是类数,H和W是输出概率图的高度和宽度。 PS是可以被定义为PS = M(IS0)的分段自适应模型的源概率。 对于目标图像IT,我们需要定义如何为其选择伪标签图ybT。 我们选择使用一种称为“最大概率阈值(MPT)”的常见方法来过滤对IT具有高预测置信度的像素。 因此,我们可以将ybT定义为ybT = argmax M(IT),将ybT的掩码映射定义为mT = 1 [argmax M(IT)>阈值]。 因此,IT的细分损失可以表示为:

 们在算法1中介绍了训练过程。训练过程包括两个循环。 外循环主要是通过正向和反向学习翻译模型和分段适应模型。 内部循环主要用于实现SSL流程。 在以下部分中,我们将介绍如何选择用于学习F,M的迭代次数,以及如何估算SSL的MPT。
们在算法1中介绍了训练过程。训练过程包括两个循环。 外循环主要是通过正向和反向学习翻译模型和分段适应模型。 内部循环主要用于实现SSL流程。 在以下部分中,我们将介绍如何选择用于学习F,M的迭代次数,以及如何估算SSL的MPT。
Discussion
To know the effectiveness of bidirectional learning and self-supervised learning for improving M, we conduct some ablation studies. We use GTA5 [27] as the source dataset and Cityscapes [5] as the target dataset. The
translation model is CycleGAN [38] and the segmentation adaptation model is DeepLab V2 [3] with the backbone ResNet101 [11]. All the following experiments use the same model, unless it is specified.
为了了解双向学习和自我监督学习对改善M的有效性,我们进行了一些消融研究。 我们使用GTA5 [27]作为源数据集,使用Cityscapes [5]作为目标数据集。 转换模型是CycleGAN [38],而分段适应模型是带有主干ResNet101 [11]的DeepLab V2 [3]。 除非指定,以下所有所有实验均使用相同的模型。
Here, we first provide the description of notations used in the following ablation study and tables. M(0) is the initial model to start the bidirectional learning and is trained only with source data. M(1) is trained with source and target data with adversarial learning. For M(0)(F(1)), a translation model F(1) is used to translate the source data and then a segmentation model M(0) is learned based on the translated source data. M(k)
i (F(k)) for k = 1; 2 and i = 0; 1; 2 refers to the model of k-th iteration for the outer loop and i-th iteration for the inner loop in Algorithm 1.
在这里,我们首先提供以下消融研究和表格中使用的符号的描述。 M(0)是开始双向学习的初始模型,并且仅使用源数据进行训练。 M(1)通过对抗性学习使用源数据和目标数据进行训练。 对于M(0)(F(1)),使用转换模型F(1)转换源数据,然后基于转换后的源数据学习分割模型M(0)。 M(k)i(F(k))对于k = 1,2和i = 0,1,2指的是算法1中外循环的第k次迭代和内循环的第i次迭代模型 。
Bidirectional Learning without SSL
We show the results obtained by the model trained in a bidirectional learning system without SSL. In Table 1, M(0) is our baseline model that gives the lowerbound for mIoU.We find a similar performance between the model M(1) and M(0)(F(1)) both of which achieve more than 7% improvement compared to M(0) and about 1:6% further improvement is given by M(1)(F(1)). It means segmentation adaptation model and the translation model can work independently and when combined together which is basically one iteration of the bidirectional learning they can be complementary to each other. We further show that through continue training the bidirectional learning system, in which case M(1)(F(1)) is used to replace M(0) for the backward direction, a better performance can be given by the new model M(2)0 (F(2)).
我们显示了在没有SSL的双向学习系统中训练的模型所获得的结果。 在表1中,M(0)是给出mIoU的下限的基线模型,我们发现模型M(1)和M(0)(F(1))之间的性能相似,两者均达到7%以上 相较于M(0)和约1:6%的改进,M(1)(F(1))给出了进一步的改进。 这意味着分段适应模型和翻译模型可以独立工作,并且当组合在一起时(基本上是双向学习的一次迭代),它们可以彼此互补。 我们进一步表明,通过继续训练双向学习系统,在这种情况下,M(1)(F(1))用于向后替换M(0),新模型M( 2)0(F(2))。
Bidirectional Learning with SSL
In this section, we show how the SSL can further improve the ability of segmentation adaption model and in return influence the bidirectional learning process. In Table 2,we show results given by two iterations(k = 1; 2) based on Algorithm 1. In Figure 4, we show the segmentation results
and the corresponding mask map given by the max probability threshold (MPT) which is 0:9. In Figure 4, the white pixels are the ones with prediction confidence higher than MPT and the black pixels are the low confident pixels.
在本节中,我们将展示SSL如何进一步提高细分适应模型的能力,并反过来影响双向学习过程。 在表2中,我们显示了基于算法1的两次迭代(k = 1; 2)给出的结果。在图4中,我们显示了分割结果以及最大概率阈值(MPT)为0给出的相应掩码映射: 9。 在图4中,白色像素是预测置信度高于MPT的像素,黑色像素是低置信度像素。
While k = 1, when model M(1) 0 (F(1)) is updated to M(1) 2 (F(1)) with SSL, the mIoU can be improved by 4:5%. We can find for each category when the IoU is below 50, a big improvement can be got from M(1) 0 (F(1)) to M(1) 2 (F(1)). It can prove our previous analysis in section 3.2 that with SSL the well aligned data from source and target domain can be kept and the rest data can be further aligned through the adversarial learning process。
当k = 1时,使用SSL将模型M(1)0(F(1))更新为M(1)2(F(1))时,mIoU可以提高4.5%。 我们可以发现,当IoU低于50时,对于每个类别,从M(1)0(F(1))到M(1)2(F(1))都可以得到很大的改善。 可以证明我们先前在3.2节中的分析表明,使用SSL,可以保留源域和目标域中对齐的数据,而其余数据可以通过对抗性学习过程进行进一步对齐。
While k = 2, we first replace M(0) with M(1) 2 (F(1)) to start the backward direction. Without SSL the mIoU is 44.3 which is a larger improvement compared to the results shown in Table 1. It can further prove our discussion in section 4.1 about the importance role played by the segmentation adaptation model in the backward direction. Furthermore, we can find from Table 2, although in the beginning of the second iteration the mIoU drops from 47.2 to 44.3,while SSL is induced, the mIoU can be promoted to 48.5 which outperforms the results in the first iteration. From
the segmentation results shown in Figure 4, our findings can be further confirmed and the most important thing is as we improve the segmentation performance, the segmentation adaptation model can give more confident prediction which can be observed by the increasing white area in the
mask map. It gives us the motivation to use the mask map to choose the threshold and number of iterations for the SSL process in Algorithm 1.
当k = 2时,我们首先用M(1)2(F(1))替换M(0)以开始向后的方向。 没有SSL的mIoU为44.3,与表1所示的结果相比有较大改进。它可以进一步证明我们在第4.1节中对分段自适应模型在向后方向上发挥的重要作用的讨论。 此外,我们可以从表2中找到,尽管在第二次迭代开始时mIoU从47.2下降到44.3,而在诱发SSL的同时,mIoU可以提升到48.5,其性能优于第一次迭代。 从图4所示的分割结果可以进一步证实我们的发现,最重要的是,随着我们提高分割性能,分割适应模型可以给出更可靠的预测,可以通过蒙版图中白色区域的增加来观察 。 它使我们有动机使用掩码映射为算法1中的SSL过程选择阈值和迭代次数。
Hyper Parameter Learning
We will describe how to choose the threshold to filter out data with high confidence and the iteration number N in Algorithm 1.
我们将描述如何选择阈值以高可信度过滤数据和算法1中的迭代次数N。
When we choose the threshold, we have to balance between two folds. On one hand, we desire the predicted labels with high confidence as many as possible (presented as white areas in Figure 4). On the other hand, we want to avoid inducing too much noise caused by the incorrect prediction, namely, the threshold should be as high as possible. We present the relationship of the prediction confidence (maximum class probability of per pixel from M) and the ratio between selected pixels and all pixels (i.e., percentage of all white areas shown in Figure 4) on the left side of Figure 5, then show the slope in the right side of Figure 5. We can find when the prediction confidence increases from 0.5 to 0.9, the ratio decreases almost linearly and the slope stays almost unchanged. But from 0.9 to 0.99, the ratio decreases much faster. Based on the observation, we choose the inflection point 0.9 as the threshold as the trade-off between the number and the quality of selected labels.
当选择阈值时,我们必须在两个折痕之间保持平衡。 一方面,我们希望预测标签具有尽可能高的置信度(在图4中显示为白色区域)。 另一方面,我们希望避免由于不正确的预测而引起过多的噪声,即阈值应尽可能高。 我们在图5的左侧表示预测置信度(每个像素从M的最大类别概率)与所选像素和所有像素之间的比率(即,图4中显示的所有白色区域的百分比)之间的关系,然后显示 图5右侧的斜率。我们可以发现,当预测置信度从0.5增加到0.9时,比率几乎呈线性下降,并且斜率几乎保持不变。 但是从0.9到0.99,该比率下降得更快。 基于观察,我们选择拐点0.9作为阈值,作为所选标签的数量和质量之间的权衡。
In order to further prove our choice, in Table 3, we show segmentation results using different thresholds to the selfsupervised learning of (MK N) when K = 1 and N = 1 in Algorithm 1. As another option, we also consider soft threshold instead of hard one, namely, every pixel being weighted by its maximum class probability. We show the result on the bottom row. All the results confirm our analysis. When the threshold is lower than 0.9, the uncorrected prediction becomes the key issue to influence the performance of SSL. While we increase the threshold to 0.95, the SSL process is more sensitive to the number of pixels that can be used.When we use soft threshold, the result is still worse. It is probably because an amount of labeling noise are involved and the bad impact cannot be well alleviated by assigning a lower weight to the noise label. Thus, 0.9 seems to be a good choice for the threshold in the following experiments.
为了进一步证明我们的选择,在表3中,我们显示了在算法1中当K = 1和N = 1时,使用不同阈值对(MK N)进行自监督学习的分割结果。作为另一种选择,我们也考虑使用软阈值 硬像素,即每个像素都按其最大类别概率加权。 我们在底行显示结果。 所有结果证实了我们的分析。 当阈值低于0.9时,未校正的预测将成为影响SSL性能的关键问题。 当我们将阈值提高到0.95时,SSL进程对可以使用的像素数量更加敏感,当我们使用软阈值时,结果仍然更糟。 可能是因为涉及大量标签噪声,并且通过为噪声标签分配较低的权重无法很好地缓解不良影响。 因此,在以下实验中,对于阈值,0.9似乎是一个不错的选择。
For the iteration number N, we select a proper value according to the predicted labels as well. When N increases,the segmentation adaptation model becomes much stronger,causing more labels to be used for SSL. Once the pixel ratio for SSL stops increasing, it means that the learning for
the segmentation adaptation model is converged and nearly no improved. We definitely increase the value of K to start another iteration. In Table 4, we show some segmentation results with the theshold 0.9 as we increase the value of N. We can find the mIoU becomes better with the increasing of N. When N = 2 or 3, the mIoU almost stopped increasing,and the pixel ratio stay around the same. It may suggest that N = 2 is a good choice, and we use it in our work.
对于迭代次数N,我们也根据预测的标签选择合适的值。 当N增加时,分段自适应模型将变得更强大,从而导致更多标签可用于SSL。 一旦SSL的像素比率停止增加,这意味着细分自适应模型的学习将收敛并且几乎没有改善。 我们肯定会增加K的值来开始另一个迭代。 在表4中,随着N值的增加,我们在阈值0.9处显示了一些分割结果。我们发现mIoU随着N的增加而变得更好。当N = 2或3时,mIoU几乎停止增加,并且像素 比率保持不变。 可能表明N = 2是一个不错的选择,我们在工作中会使用它。
Conclusion
In this paper, we propose a bidirectional learning method with self-supervised learning for segmentation adaptation problem. We show via a lot of experiments that segmentation performance for real dataset can be improved when the model is trained bidirectionally and achieve the stateof-the-art result for multiple tasks with different networks.
在本文中,我们提出了一种具有自我监督学习的双向学习方法,用于分割自适应问题。 我们通过大量实验表明,当模型进行双向训练时,可以提高实际数据集的分割性能,并可以针对具有不同网络的多个任务实现最新的结果。