swin_transformer----基于移动窗口的层级(多尺度)视觉transformer
基于移动窗口的层级(多尺度)视觉transformer
论文主要创新点,层级式结构,多尺度,信息交互。窗口内计算自注意力,大大减小了计算复杂度。
目录
(1)摘要
(2)引言
(3)前向传播过程:
(4)复杂度计算:
(5)掩码操作:
(1)摘要
ViT在CV领域做了分类任务,下游任务(分割,目标检测)未进行进一步的研究。NLP领域用在CV领域的挑战:一是一个词‘树’就可代表一棵树,但一幅图中可能几百几千个像素点才能表示一棵树。词是高层次的、复杂的;像素点是低层次的、简单的。二是图片的分辨率(resolution)越来越大,对应的序列就非常长,解决方法就是打成patch,ViT中每个patch是由16*16的像素点构成。
基于以上两个难点,swin_transformer提出移动窗口的概念,只在窗口内计算自注意力,可以有效减小序列的长度,并结合移动shift_window,使得相邻窗口间有了信息交互,这就体现出来多尺度的思想。另外,随着patch_merging的使用,使得感受野不断变大,这时计算自注意力,就汇聚了全局信息。即关注了局部特征,也考虑了全局信息(一张图中相距较远的patch也产生了交互)。
由于swin_transformer拥有多尺度的信息,所以可以很容易的用在下游任务中,比如密集型任务物体检测COCO数据集58.7AP(+2.7个点),语义分割ADE数据集上53.5(+3.2个点)。
(2)引言
Transformer可以作为一个通用的骨干网络,对所有的视觉任务都能取得很好的成绩。

vit的patch_size=16*16是一成不变的,相当于16倍下采样率,拥有全局建模的能力,但没有体现多尺度的概念。但是对于目标检测和语义分割等下游任务来说,多尺度的特征是非常关键的比如目标检测的FPN和语义分割的UNet。并且,vit计算复杂度是根据图像尺寸成平方关系,检测和分割领域的图像尺寸达到了800*800甚至1000*1000,这养的计算复杂度来说太高了。

swin_transformer使用了卷积网络中局部性的先验知识,同一物体不同部位或语义相近的不同物体大概率出现在相邻的位置。因此,一个的窗口大小的视野也是可用的,毕竟一直计算全局自注意力是非常浪费资源的。
在小窗口内计算自注意力,而不像vit一样在整张图上计算注意力,计算复杂度固定在窗口内,整张图的计算复杂度是窗口计算复杂度的叠加,随尺寸呈线性关系而非平方关系。
patch_merging操作类似于pooling,将相邻patch(相邻窗口也说得过去吧)合成一个patch(窗口),增大了感受野,抓取了多尺寸特征。
移动窗口shift操作

由于shift操作,是的相邻窗口发生重叠,信息可以交互。再配合上patch_merging,合并到最后几个stage时,感受野已经足够大,完全可以学习全局特征,变相的全局自注意力,这样做即提高了计算效率,又学了多尺度的特征。
patch_merging:pooling,合并patch,减小HW的维度,通道数加倍,相当于2倍下采样。

(3)前向传播过程:
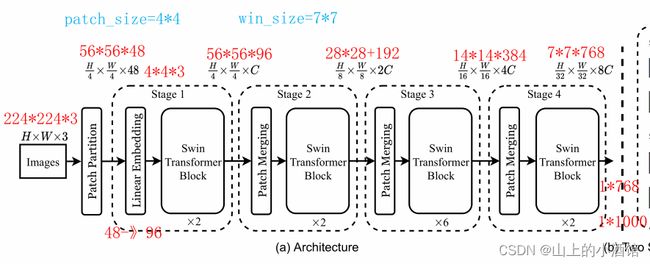
输入224*224*3(HWC),经过patch_partition,56*56*48(patch_size=4,48=4*4*3),
经过Linear Embedding,56*56*96(HWC)增加了通道数,flatten3196*96
经过第一个stage,输出56*56*96,transformer不会改变输入的形状,
进入第二个stage,patch_merging后输出28*28*192,stage输出28*28*192,
进入第三个stage,patch_merging后输出14*14*384,stage输出14*14*384,
进入第四个stage,patch_merging后输出7*7*768,stage输出7*7*768,
如果做1k分类,接两个线性层,49*768—>1*768—>1*1000
第三个stage的transformer块较多,应该是作者经过试验发现这样效果最好。
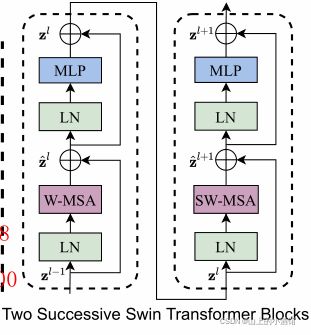
每次输入到Transformers Blocks中,先进入一个W-MSA(window_Mutil-head_Self_Attention),在进入滑动窗口SW-MSA(Shift_window_Mutil-head_Self_Attention)
(4)复杂度计算:
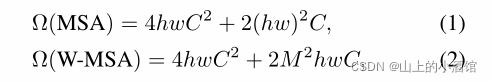

[QKV投影]+[QK相乘、V的加权平均]+[最后投影]:3*hw*C2+2*(hw)2*C+hw*C2
每个窗口做自注意力,hw用M2代替,共有(h/M)*(w/M)个窗口,
(h/M)*(w/M)*3*M2*C2+2*M4*C+M2*C2=3*hw*C2+2*M2*C+hw*C2
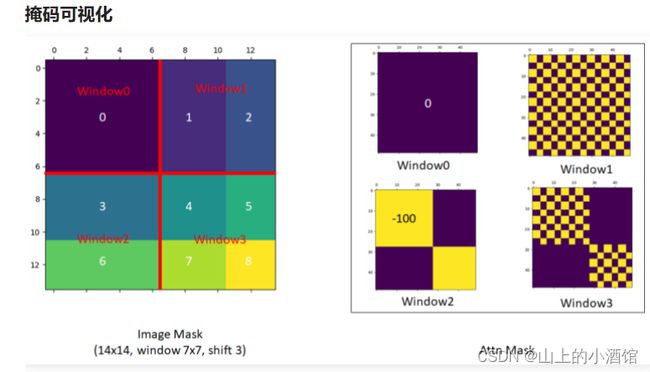
(5)掩码操作:
移动窗口后,由于每个窗口内patch的数目不一致了,需要对新的窗口补齐。右下角由A、B、C、原图四个不相连的块组成(可以理解成一种噪声干扰?这种不连续的特征学出来是不好的),计算自注意力时进行掩码,使得A、B、C、原图分别计算自己的注意力,与其他位置的注意力利用矩阵掩码,加一个很大的负数,softmax操作时会变成0。

论文也使用了相对位置编码,个人理解是可以提高精度。