线上业务 coredump 是一件让工程师很紧张的事情,特别是每次崩溃都是出现在凌晨。我自己十几年前亲身经历过一次,当时为了定位这个只有凌晨才出现的“幽灵”bug,整个团队是下午回家睡觉,晚上 12 点到公司一起等待崩溃的现场,然后逐个服务来排查。想象一下,漆黑的夜晚和办公楼,只有几个工位亮着灯,守着屏幕上不断跳动的监控数据和日志,既紧张又刺激。我们守了三个晚上,才定位到bug并解决掉,这是难忘的一段经历。
没想到,这种经历又来了一次。只不过这次不是我们自己的服务,而是客户的线上服务出现了 coredump。这比我们自己完全可控的环境更有挑战:
- 只有线上业务发生错误,在预生产和测试环境都无法复现;
- 在开源的 Apache APISIX 基础上有自定代码,这部分代码在单独签署 NDA 之前看不到;
- 不能增加调试日志;
- 只在凌晨 3 点出现,需要调动客户更多资源才能即时处理。
也就是:没有复现方法,没有完整源代码,没有可以折腾的环境,但我们要定位原因,给出复现办法,并给出最终修复方案。期间有挑战有收获,在这里记录下解决问题过程中碰到的一些技术点,希望对大家排查 NGINX 和 APISIX 问题有借鉴。
问题描述
用户原来使用 APISIX 2.4.1 版本,没有出现问题,升级到 2.13.1 版本后,开始周期性出现 coredump,信息如下:

从 coredump 信息中能看出来 segmentation fault 发生在 lua-var-nginx-module 中。对应的内存数据(只粘贴了部分数据)如下:
#0 0x00000000005714d4 in ngx_http_lua_var_ffi_scheme (r=0x570d700, scheme=0x7fd2c241a760)
at /tmp/vua-openresty/openresty-1.19.3.1-build/openresty-1.19.3.1/../lua-var-nginx-module/src/ngx_http_lua_var_module.c:152
152 /tmp/vua-openresty/openresty-1.19.3.1-build/openresty-1.19.3.1/../lua-var-nginx-module/src/ngx_http_lua_var_module.c: No such file or directory.
(gdb) print *r
$1 = {signature = 0, connection = 0x0, ctx = 0x15, main_conf = 0x5adf690, srv_conf = 0x0, loc_conf = 0x0, read_event_handler = 0xe, write_event_handler = 0x5adf697,
cache = 0x2, upstream = 0x589c15, upstream_states = 0x0, pool = 0x0, header_in = 0xffffffffffffffff}可以发现,此时内存数据是存在问题的。
分析前的想法
对于 segmentation fault 的错误,一般有两种情况:
- 问题代码产生了一个非法地址的读/写,例如数组越界,这种情况下会立即出现 segmentation fault。
- 问题代码产生了一个错误的写,但是修改的是合法地址,并没有马上产生 segmentation fault。在后续程序的运行过程中,因为访问了该地址的数据,产生了 segmentation fault, 例如错误修改了指针的值,后续在访问这个指针的时候,就可能触发 segmentation fault。
对于情况 1,如果能拿到调用栈,直接查看调用栈,可以很快定位到问题。
对于情况 2,由于不是问题发生的第一现场,产生错误的代码和触发 segmentation fault 的代码可能不在同一个位置,甚至毫不相干,排查起来就相当麻烦,这时我们只能尽可能多的采集崩溃位置的上下文信息,比如:
- 当前的 APISIX 配置具体细节
- 当前的请求处理阶段
- 当前的请求细节
- 当前有多少并发连接数
- 当前的错误日志等
通过这些信息,尝试找到问题的复现场景和通过 review 代码来发现问题。
分析过程
排查现场
经过仔细的排查,发现问题都集中出现在晚上 3 点和 4 点,并且 coredump 前可能会有如下错误日志:
![]()
最后发现错误日志跟用户的操作有关,因为一些原因这个时间点所有的上游信息都会被清空。所以初步怀疑问题跟清空上游的操作有关,可能是因为错误返回后进入了某个异常分支引发了 coredump 。
拿到 Lua 调用栈
因为 GDB 不能追踪 Lua 调用栈,不能确定是在哪个位置的调用出现了问题。因此首先要做的肯定是拿到完整的调用栈,我们可以通过以下两种方式获取到调用栈:
- 在 lua-var-nginx-module 库中相应的地方加上打印调用栈的操作,例如
print(`debug.traceback(...`)),缺点就是会产生非常多的错误日志,影响到线上环境。 - 使用 API7.ai 维护的 openresty-gdb-utils ,这个库通过 GDB 的 DSL 和 python 接口扩展了分析 Lua 调用栈的能力,但是注意编译 Luajit 时需要开启调试符号,这个在 APISIX 中是默认开启的。
忽略中间过程,最后拿到了如下调用栈。

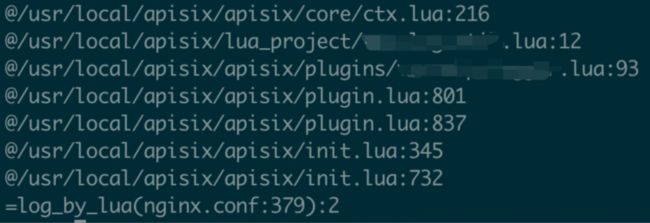
结合 Lua 和 c 的调用栈,可以查到 coredump 是因为在用户的 prometheus 插件中调用了 ngx.ctx.api_ctx.var.scheme,但是为什么会崩溃,我们还需要进一步分析。
确认是缓存引起的问题
出错发生在从ngx.ctx.api_ctx.var中获取变量的场景,调用了上文提到的lua-var-nginx-module 模块,它为了提升效率缓存了当前请求,联想到出问题时请求体值有异常,这个提前缓存的请求体是否正确值得怀疑。为了验证这一点,我们不再使用缓存, 改为每次都重新获取。
else
--val = get_var(key, t._request)
val = get_var(key, nil) <============ t._request change to nil
end用户使用新版本挂测了一晚上,问题不再出现,证明了缓存的请求体确实存在问题。
找到出问题的 ngx.ctx
缓存的请求体保存在 ngx.ctx 中,而可能修改ngx.ctx的只有如下位置 apisix/init.lua。
function _M.http_header_filter_phase()
if ngx_var.ctx_ref ~= '' then
-- prevent for the table leak
local stash_ctx = fetch_ctx()
-- internal redirect, so we should apply the ctx
if ngx_var.from_error_page == "true" then
ngx.ctx = stash_ctx <================= HERE
end
end
core.response.set_header("Server", ver_header)
local up_status = get_var("upstream_status")
if up_status then
set_resp_upstream_status(up_status)
end这里为什么需要恢复 ngx.ctx?因为 ngx.ctx 保存在 Lua 注册表中,通过注册表的索引可以找到对应的 ngx.ctx。而索引保存在 nginx 请求结构体的 ctx 成员里,每次内部跳转,nginx 都会清空 ctx,导致找不到索引。
APISIX 为了解决这个问题,创建了一个 table,在跳转前先在 table 中保存当前的 ngx.ctx,然后用 ngx.var 记录 ngx.ctx 在这个 table 中的位置,等到需要恢复的时候,就可以直接从 table 中拿到 ngx.ctx。更多细节可以参考文章:对 ngx.ctx 的一次 hack 。
上图中的代码需要用户配置 error_page 指令, 发生错误后内部跳转才能触发。
而用户刚好在升级版本后打开了 error_page 指令,再加上前面排查到的因上游变更产生的错误,似乎串联起来了,难道是因为错误处理的过程中恢复 ngx.ctx 出错了?
ngx.ctx 为什么会有问题
带着这个疑问,我们继续排查了 ngx.ctx 备份恢复相关的代码,随后发现了更奇怪的问题。
在 set_upstream 失败后,压根就不会走恢复 ngx.ctx 的流程,因为这个时候提前退出了,不会备份ngx.ctx,也就不会走到恢复的流程。
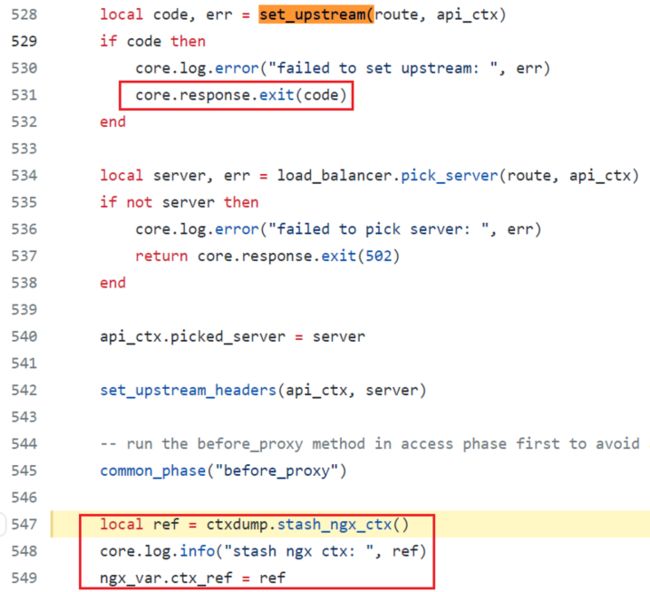
这显然是个 bug!因为跳转之后应该是需要恢复 ngx.ctx 的。那到底是怎么进到这个流程里恢复了 ngx.ctx?ngx.ctx 又是如何出现的问题?现在的疑问太多了,我们需要收集更多的信息。
经过协商,我们在线上第二次增加了日志,最后发现:请求在发生错误跳转后没有经过恢复 ngx.ctx 的流程,直接 coredump 了!
这是一个令人匪夷所思的现象,要知道内部跳转后,如果不恢复的话,ngx.ctx 为空。代码里有对空值进行判断,是不会走到插件里触发 coredump 的代码的。
local function common_phase(phase_name)
local api_ctx = ngx.ctx.api_ctx
if not api_ctx then <============ HERE
return
end
plugin.run_global_rules(api_ctx, api_ctx.global_rules, phase_name)所以是触发 error_page 后的内部跳转这个动作导致 ngx.ctx 出现了问题?
得到初步结论
其实定位到现在,出现问题的流程已经基本都清楚了:
set_upstream 失败后跳转到 error_page 的错误处理阶段,原来应该为空的 ngx.ctx 出现了不符合预期的值。而由于 APISIX 的 bug, 没有恢复跳转前的 ngx.ctx,导致接下来访问了 ngx.ctx 内的脏数据,发生了 coredump。所以只要跳转后能恢复 ngx.ctx,就能解决这个问题,具体修复的 commit 细节已放在文末,可直接参考。
虽然截止到这里,已经能够给用户提供解决方案,但是我们仍然还没有找到问题复现的完整逻辑。因为用户并没有修改 ngx.ctx 的逻辑,开源版本应该可以复现,为了不继续影响用户的线上环境和正常发布流程,我们决定继续刨根问底。
线下成功复现
从已知的条件还不能复现出问题,经过分析,我们打算从以下两个方面进行排查:
- 内部跳转是否有特殊的处理流程。
- ngx.ctx 是否有特殊的处理流程。
对于第一点,在经过 nginx 各个 filter 模块的处理过程中,可能存在某些异常的分支,影响了请求结构体中的 ctx 成员,从而影响了 ngx.ctx。我们排查了用户编译进 nginx 的模块,查看是否有相关的异常分支,但没有发现类似的问题。
对于第二点,经过排查发现 ssl 握手过程中存在 ngx.ctx 复用的问题。HTTP 阶段如果获取不到 ngx.ctx,会尝试从 SSL 阶段获取,SSL 阶段有自己单独的 ngx.ctx,有可能导致 ngx.ctx 出现问题。
基于此,我们设计了如下几个条件,最终复现了问题:
- 特定的 APISIX 版本(跟用户版本相同)
- 启用 SSL 证书
- 内部错误,触发 error_page(比如指定上游时,无上游节点)
- 长连接
- Prometheus 插件(用户在插件中引发 coredump)
虽然“无米”,但我们最后也做成了这顿“饭”,通过猜想+验证,终于摸索出了这个 bug 的完整复现流程。一旦有完整复现流程,那么解决问题自然不再是难点,最终定位过程也不再详述,相信大家对能准确复现的问题都有着丰富的经验。
梳理与总结
本次问题的根本原因:由于进入 error_page 后没有恢复 ngx.ctx, 导致长连接上的所有请求都复用了 SSL 阶段的同一个 ngx.ctx。最终导致 ngx.ctx 出现了脏数据,产生了 coredump。
后续针对该问题我们也提出了相应的解决方案:确保内部跳转后,能够正常恢复 ngx.ctx。具体修复 PR 可参考:
https://github.com/apache/api...
如果你的 APISIX 有使用到 error_page 等涉及到内部跳转的功能,推荐升级到最新的版本。
编写程序和 debug,都是科学严谨的工作,容得不半点含糊。收集信息、不放过蛛丝马迹、分析调用栈,再搞清楚上下文之后做到有的放矢,通过复现才能最终解决问题。