Kubernetes进阶使用(一)—集群管理 && ETCD && 资源对象介绍
一、kubernetes 集群管理
集群管理主要是添加master、添加node,删除master和删除node等节点管理
当前集群状态:
root@master1:~# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 8d v1.20.2
10.0.0.102 Ready,SchedulingDisabled master 8d v1.20.2
10.0.0.111 Ready node 8d v1.20.2
10.0.0.112 Ready node 8d v1.20.2
1.1 添加node
root@master1:/etc/kubeasz# ./ezctl add-node k8s-01 10.0.0.113
root@master1:/etc/kubeasz# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 8d v1.20.2
10.0.0.102 Ready,SchedulingDisabled master 8d v1.20.2
10.0.0.111 Ready node 8d v1.20.2
10.0.0.112 Ready node 8d v1.20.2
10.0.0.113 Ready node 2m57s v1.20.2 #添加了一个node
1.2 添加master
root@master1:/etc/kubeasz# ./ezctl add-master k8s-01 10.0.0.103
root@master1:/etc/kubeasz# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 8d v1.20.2
10.0.0.102 Ready,SchedulingDisabled master 8d v1.20.2
10.0.0.103 Ready,SchedulingDisabled master 5m45s v1.20.2 #添加新的master
10.0.0.111 Ready node 8d v1.20.2
10.0.0.112 Ready node 8d v1.20.2
10.0.0.113 Ready node 12m v1.20.2
二、kubernetes 集群版本升级
kubernetes包下载地址:https://github.com/kubernetes/kubernetes/releases
准备好升级的包
root@master1:/usr/local/src# pwd
/usr/local/src
root@master1:/usr/local/src# ll
total 463460
drwxr-xr-x 2 root root 4096 Oct 5 14:13 ./
drwxr-xr-x 10 root root 4096 Aug 24 16:42 ../
-rw-r--r-- 1 root root 29275714 Oct 5 13:59 kubernetes-client-linux-amd64.tar.gz
-rw-r--r-- 1 root root 118424850 Oct 5 14:00 kubernetes-node-linux-amd64.tar.gz
-rw-r--r-- 1 root root 326345382 Oct 5 14:01 kubernetes-server-linux-amd64.tar.gz
-rw-r--r-- 1 root root 517251 Oct 5 13:59 kubernetes.tar.gz
root@master1:/usr/local/src# tar xf kubernetes
kubernetes-client-linux-amd64.tar.gz kubernetes-server-linux-amd64.tar.gz
kubernetes-node-linux-amd64.tar.gz kubernetes.tar.gz
root@master1:/usr/local/src# tar xf kubernetes-client-linux-amd64.tar.gz
root@master1:/usr/local/src# tar xf kubernetes-server-linux-amd64.tar.gz
root@master1:/usr/local/src# tar xf kubernetes-node-linux-amd64.tar.gz
root@master1:/usr/local/src# tar xf kubernetes.tar.gz
#查看升级包的版本
root@master1:/usr/local/src/kubernetes# ./server/bin/kube-apiserver --version
Kubernetes v1.21.5
#查看当前master的版本
root@master1:/usr/local/src# /etc/kubeasz/bin/kube-apiserver --version
Kubernetes v1.21.0
2.1 升级master
#更新node的kube-lb的配置文件,把master1注释,3个node都做这个操作
root@node1:~# cat /etc/kube-lb/conf/kube-lb.conf
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
#server 10.0.0.101:6443 max_fails=2 fail_timeout=3s; #注释掉
server 10.0.0.102:6443 max_fails=2 fail_timeout=3s;
server 10.0.0.103:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
#进行重启生效
root@node1:~# systemctl restart kube-lb.service
#在master进行升级
root@master1:/usr/local/src# systemctl stop kube-apiserver kube-scheduler kube-controller-manager kube-proxy kubelet
root@master1:/usr/local/src/kubernetes/server/bin# pwd
/usr/local/src/kubernetes/server/bin
#把要升级的包拷贝进去替换
root@master1:/usr/local/src/kubernetes/server/bin# \cp kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubelet kubectl /usr/local/bin/
root@master1:/usr/local/src/kubernetes/server/bin# systemctl start kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubelet
#更新完master,把node上面的kube-lb修改回来,重启生效
root@node1:~# cat /etc/kube-lb/conf/kube-lb.conf
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 10.0.0.101:6443 max_fails=2 fail_timeout=3s;
server 10.0.0.102:6443 max_fails=2 fail_timeout=3s;
server 10.0.0.103:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
#进行重启生效
root@node1:~# systemctl restart kube-lb.service
#进行验证
root@master1:/usr/local/src/kubernetes/server/bin# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 61m v1.21.5 #升级成功
10.0.0.102 Ready,SchedulingDisabled master 58m v1.21.0
10.0.0.103 Ready,SchedulingDisabled master 58m v1.21.0
10.0.0.111 Ready node 56m v1.21.0
10.0.0.112 Ready node 56m v1.21.0
10.0.0.113 Ready node 56m v1.21.0
更新完master1之后就可以接着更新master2,master3,也是同样的操作
#全部升级升级完
root@master1:/usr/local/src/kubernetes/server/bin# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 84m v1.21.5
10.0.0.102 Ready,SchedulingDisabled master 81m v1.21.5
10.0.0.103 Ready,SchedulingDisabled master 82m v1.21.5
10.0.0.111 Ready node 79m v1.21.0
10.0.0.112 Ready node 79m v1.21.0
10.0.0.113 Ready node 79m v1.21.0
2.2 升级node
升级node和升级master的操作差不多,也是先把服务停了,更新配置文件
#node停服务
root@node1:~# systemctl stop kubelet kube-proxy
#更新配置文件
root@master1:/usr/local/src/kubernetes/server/bin# scp kubectl kube-proxy kubelet 10.0.0.111:/usr/local/bin/
kubectl 100% 44MB 104.2MB/s 00:00
kube-proxy 100% 41MB 85.0MB/s 00:00
kubelet 100% 113MB 84.0MB/s 00:01
#node启动服务
root@node1:~# systemctl start kubelet kube-proxy
#验证
root@node1:~# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 90m v1.21.5
10.0.0.102 Ready,SchedulingDisabled master 87m v1.21.5
10.0.0.103 Ready,SchedulingDisabled master 87m v1.21.5
10.0.0.111 Ready node 84m v1.21.5 #升级完成
10.0.0.112 Ready node 84m v1.21.0
10.0.0.113 Ready node 84m v1.21.0
node全部升级完成
root@master1:/usr/local/src/kubernetes/server/bin# kubectl get node
NAME STATUS ROLES AGE VERSION
10.0.0.101 Ready,SchedulingDisabled master 92m v1.21.5
10.0.0.102 Ready,SchedulingDisabled master 89m v1.21.5
10.0.0.103 Ready,SchedulingDisabled master 89m v1.21.5
10.0.0.111 Ready node 87m v1.21.5
10.0.0.112 Ready node 87m v1.21.5
10.0.0.113 Ready node 87m v1.21.5
三、yaml文件解析
Kubernetes只支持YAML和JSON格式创建资源对象
JSON格式用于接口之间消息的传递,YAML格式用于配置和管理
YAML是专门用来写配置文件的语言,非常简洁和强大,使用比json更方便。它实质上是一种通用的数据串行化格式
YAML文件优点:
- YAML 文件易于人类阅读,具有表达性和可扩展性。
- YAML 文件易于实现和使用。
- 可在编程语言之间轻松移植。
- 与敏捷语言的原生数据结构相匹配。
- YAML 文件具有一致模型,支持通用工具。
- YAML 文件支持 One-pass 处理。
- 使用方便,因此您无需再将所有的参数添加到命令行中。
- 易于维护 – 可以将 YAML 文件添加到源控件中以跟踪更改。
- 灵活便捷 – 可以使用 YAML 创建更加复杂的结构
3.1 yaml与json
3.1.1 json格式
json 不能注释
json 可读性比较差
json 语法很严格
json 比较适用于API返回值,也可用于配置文件
3.1.2 yaml格式
大小写敏感
使用缩写表示层级关系
缩进不允许使用Tal键,只允许使用空格
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
使用"#"表示注释,从这个字符一直到行尾,都会被解析器忽略
比json更适用于配置文件
3.2 Nginx业务yaml文件详解
必要字段:
- apiVersion 创建该对象所使用的kubernetes API的版本
- kind 想要创建的对象的类型
- metadata 帮助识别对象唯一性的数据,包括一个name名称,可选的namespace
- spec 期望的状态
- status 实际状态
命令详解:
cat nginx-demo1.yaml
apiversion: apps/v1 #指定api版本标签】
kind: Deployment #定义资源的类型/角色】,deployment为副本控制器,此处资源类型可以是Deployment、Job、Ingress、Service等
metadata : #定义资源的元数据信息,比如资源的名称、namespace、标签等信息
name: nginx-demo1 #定义资源的名称,在同一个namespace空间中必须是唯一的
labels: #定义资源标签(Pod的标签)
app: nginx
spec: #定义deployment资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 3 #定义副本数量
selector: #定义标签选择器
matchLabels : #定义匹配标签
app: nginx #匹配上面资源的标签,需与上面的标签定义的app的保持一致
template: #定义业务模版,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata:
labels:
app: nginx
spec:
containers: #定义容器属性
- name: nginx #定义一个容器名,一个- name:定义一个容器
image: nginx:1.15.4 #定义容器使用的镜像以及版本
imagePullPolicy: IfNotPresent #镜像拉取策略
ports:
- containerPort: 80 #定义容器的对外的端口
四、etcd的使用
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
etcd作为服务发现系统,有以下的特点:
- 简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
- 安全:支持SSL证书验证
- 快速:根据官方提供的benchmark数据,单实例支持每秒2k+读操作
- 可靠:采用raft算法,实现分布式系统数据的可用性和一致性
4.1 etcd客户端使用
4.1.1 查看成员信息
root@etcd1:~# ETCDCTL_API=3 etcdctl member list
5b0169bf3716a723, started, etcd-10.0.0.107, https://10.0.0.107:2380, https://10.0.0.107:2379, false
a37c25f4054f324f, started, etcd-10.0.0.108, https://10.0.0.108:2380, https://10.0.0.108:2379, false
c2c2f0c1e34e347f, started, etcd-10.0.0.106, https://10.0.0.106:2380, https://10.0.0.106:2379, false
4.1.2 验证当前etced所有成员状态
验证集群状态
4.1.2.1 心跳信息
root@etcd1:~# export NODE_IPS="10.0.0.106 10.0.0.107 10.0.0.108"
root@etcd1:~# for ip in $NODE_IPS; do ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://$ip:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health;done
https://10.0.0.106:2379 is healthy: successfully committed proposal: took = 16.511288ms
https://10.0.0.107:2379 is healthy: successfully committed proposal: took = 11.843728ms
https://10.0.0.108:2379 is healthy: successfully committed proposal: took = 9.56824ms
4.1.2.2 显示集群成员信息
root@etcd1:~# ETCDCTL_API=3 etcdctl --write-out=table member list --endpoints=https://10.0.0.106:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem
+------------------+---------+-----------------+-------------------------+-------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-----------------+-------------------------+-------------------------+------------+
| 5b0169bf3716a723 | started | etcd-10.0.0.107 | https://10.0.0.107:2380 | https://10.0.0.107:2379 | false |
| a37c25f4054f324f | started | etcd-10.0.0.108 | https://10.0.0.108:2380 | https://10.0.0.108:2379 | false |
| c2c2f0c1e34e347f | started | etcd-10.0.0.106 | https://10.0.0.106:2380 | https://10.0.0.106:2379 | false |
+------------------+---------+-----------------+-------------------------+-------------------------+------------+
4.1.2.3 以表格显示节点的纤细信息
root@etcd1:~# export NODE_IPS="10.0.0.106 10.0.0.107 10.0.0.108"
root@etcd1:~# for ip in $NODE_IPS; do ETCDCTL_API=3 /usr/local/bin/etcdctl --write-out=table endpoint status --endpoints=https://$ip:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health;done
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.0.0.106:2379 | c2c2f0c1e34e347f | 3.4.13 | 5.5 MB | false | false | 5 | 19588 | 19588 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.0.0.107:2379 | 5b0169bf3716a723 | 3.4.13 | 5.5 MB | false | false | 5 | 19588 | 19588 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.0.0.108:2379 | a37c25f4054f324f | 3.4.13 | 5.5 MB | true | false | 5 | 19588 | 19588 | |
+-------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
4.1.3 查看etcd数据信息
4.1.3.1 查看所有key
#以路径形式获取所有key
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only
#获取pod信息
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only|grep pod
#获取namespace信息
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only|grep namespace
#获取控制器信息
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only|grep deployment
#获取calico组件信息
root@etcd1:~# ETCDCTL_API=3 etcdctl get / --prefix --keys-only|grep -w calico
4.1.3.2 查看指定key
root@etcd1:~# ETCDCTL_API=3 etcdctl get /calico/ipam/v2/assignment/ipv4/block/10.200.104.0-26
/calico/ipam/v2/assignment/ipv4/block/10.200.104.0-26
{"cidr":"10.200.104.0/26","affinity":"host:node2","allocations":[0,null,null,1,2,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],"unallocated":[5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,2,1],"attributes":[{"handle_id":"ipip-tunnel-addr-node2","secondary":{"node":"node2","type":"ipipTunnelAddress"}},{"handle_id":"k8s-pod-network.66d89e8236514f11ad17651ab97431f340fa7ba580d9b407892e70bab6c5a6b7","secondary":{"namespace":"default","node":"node2","pod":"net-test1"}},{"handle_id":"k8s-pod-network.87cf71336a71693a798474ffebbbae173ca30555ecc8796e4ae54c04a5315e4a","secondary":{"namespace":"kubernetes-dashboard","node":"node2","pod":"kubernetes-dashboard-79b875f7f8-2hnpx"}}],"deleted":false}
4.1.4 etcd增删改查
#增
root@etcd1:~# ETCDCTL_API=3 etcdctl put /test linux
OK
#查
root@etcd1:~# ETCDCTL_API=3 etcdctl get /test
/test
linux
#改
```c
root@etcd1:~# ETCDCTL_API=3 etcdctl put /test window
OK
root@etcd1:~# ETCDCTL_API=3 etcdctl get /test
/test
window
#删
root@etcd1:~# ETCDCTL_API=3 etcdctl del /test
1
root@etcd1:~# ETCDCTL_API=3 etcdctl get /test
root@etcd1:~#
4.1.5 etcd数据watch机制
Watch是监听一组或者一个的key,key的任何变化都会发出消息。KV接口的具体实现是store结构体。Watch的实现是在store上封装了一层,叫做:watchableStore,重写了store的Write方法。
watch测试
#监控
root@etcd1:~# ETCDCTL_API=3 etcdctl watch /test
#数据测试
root@etcd1:~# ETCDCTL_API=3 etcdctl put /test test
OK
root@etcd1:~# ETCDCTL_API=3 etcdctl watch /test
PUT
/test
test
4.2 etcd数据备份和数据恢复机制
wal: 存放预写式日志,最大的作用就是记录整个数据变化的全部过程,在etcd中,所有数据的修改在提交前,都要写入wal中
4.2.1 etcd v3版本数据备份与恢复
#etcd v3版本数据备份
root@etcd1:~# ETCDCTL_API=3 etcdctl snapshot save etcd-20211006.db
{"level":"info","ts":1633515214.219298,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"etcd-20211006.db.part"}
{"level":"info","ts":"2021-10-06T18:13:34.220+0800","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1633515214.2206643,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2021-10-06T18:13:34.268+0800","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1633515214.3104687,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"5.5 MB","took":0.090834957}
{"level":"info","ts":1633515214.3105779,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"etcd-20211006.db"}
Snapshot saved at etcd-20211006.db
#etcd v3版本数据恢复
#--data-dir一定是一个不存在的,将数据恢复到一个新的不存在的目录中
root@etcd1:~# ETCDCTL_API=3 etcdctl snapshot restore etcd-20211006.db --data-dir=/tmp/etcd
{"level":"info","ts":1633515415.6740751,"caller":"snapshot/v3_snapshot.go:296","msg":"restoring snapshot","path":"etcd-20211006.db","wal-dir":"/tmp/etcd/member/wal","data-dir":"/tmp/etcd","snap-dir":"/tmp/etcd/member/snap"}
{"level":"info","ts":1633515415.7049475,"caller":"mvcc/kvstore.go:380","msg":"restored last compact revision","meta-bucket-name":"meta","meta-bucket-name-key":"finishedCompactRev","restored-compact-revision":24401}
{"level":"info","ts":1633515415.7179449,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"cdf818194e3a8c32","local-member-id":"0","added-peer-id":"8e9e05c52164694d","added-peer-peer-urls":["http://localhost:2380"]}
{"level":"info","ts":1633515415.729402,"caller":"snapshot/v3_snapshot.go:309","msg":"restored snapshot","path":"etcd-20211006.db","wal-dir":"/tmp/etcd/member/wal","data-dir":"/tmp/etcd","snap-dir":"/tmp/etcd/member/snap"}
五、kubernetes集群维护常用命令
| 命令集 | 命令 | 用途 |
|---|---|---|
| 基本命令 | create/delete/edit/get/describe/logs/exec/scale | 增删改查 |
| explain | 命令说明 | |
| 配置命令 | Label:给node打标记label,实现pod与node亲和性 | 标签管理 |
| apply | 动态配置 | |
| 集群管理命令 | cluster-info/top | 集群状态 |
| cordon:警戒线,标记node不被调度 | node节点管理 | |
| uncordon:取消警戒线,标记为cordon的node | node节点管理 | |
| drain:驱逐node上的pod,用于node下线等场景 | node节点管理 | |
| taint:给node标记污点,实现反亲pod与node反亲和性 | node节点管理 | |
| api-resources/api-versions/version | api资源 | |
| config | 客户端kube-config配置 |
六、资源对象介绍
6.1 Pod : k8s中最小单元
- pod是k8s中的最小单元
- 一个pod中可以运行一个容器,也可以运行多个容器
- 运行多个容器的话,这些容器是一起被调度的
- pod的生命周期是短暂的,不会自愈,是用完就销毁的实体
- 一般我们可以使用controller来创建和管理pod的
Pod生命周期
初始化容器、启动前操作、就绪探针、删除pod操作

| 阶段 | 描述 |
|---|---|
| Pending | Pod 已被 Kubernetes 接受,但尚未创建一个或多个容器镜像。这包括被调度之前的时间以及通过网络下载镜像所花费的时间,执行需要一段时间 |
| Running | Pod 已经被绑定到了一个节点,所有容器已被创建。至少一个容器正在运行,或者正在启动或重新启动 |
| Succeeded | pod中的所有容器都已经成功终止并且不会被重启 |
| Failed | 所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的退出状态或已经被系统终止 |
| Unknown | 由于一些原因,Pod 的状态无法获取,通常是与 Pod 通信时出错导致的 |
Pod阶段描述
Pod的状态属性是一个PodStatus对象,拥有一个phase字段。它简单描述了 Pod 在其生命周期的阶段。
pod创建过程
pod是k8s的基础单元,一个pod资源创建过程如下:
1、用户通过kubectl或其他api客户端提交pod spec给api server
2、api server尝试着将pod对象的相关信息存入etcd中
3、将相关信息存入etcd中,api server即会返回确认信息至客户端,api server开始反映etcd中的状态变化
4、所有的k8s组件均使用watch机制来跟踪检查api server上的相关变动
5、kube-scheduler通过其watch觉察到api server创建了新的pod对象但尚未绑定至任何工作节点
6、kube-scheduler为pod对象挑选一个工作节点并将结果信息更新至api server
7、调度结果信息由api server更新至etcd,而且api server也开始反映此pod对象的调度结果
8、pod被调度到目标工作节点上的kubelet尝试在当前节点上调用docker启动容器,并将容器的结果状态回送至api server
9、api server将pod状态信息存入etcd中
10、在etcd确认写入操作成功完成后,api server将确认信息发送至相关的kubelet。
6.2 Controller : 控制器
- 第一代pod副本控制器 : Replication Controller
- 第二代pod副本控制器 : ReplicaSet
- 第三代pod副本控制器 : Deployment
6.2.1 Replication Controller(RC) : 副本控制器
摘自 :https://kubernetes.io/zh/docs/concepts/workloads/controllers/replicationcontroller/
ReplicationController 确保在任何时候都有特定数量的 Pod 副本处于运行状态。 换句话说,ReplicationController 确保一个 Pod 或一组同类的 Pod 总是可用的
ReplicationController 如何工作
- 当 Pod 数量过多时,ReplicationController 会终止多余的 Pod。当 Pod 数量太少时,ReplicationController 将会启动新的 Pod。 与手动创建的 Pod 不同,由 ReplicationController 创建的 Pod 在失败、被删除或被终止时会被自动替换。 例如,在中断性维护(如内核升级)之后,你的 Pod 会在节点上重新创建。 因此,即使你的应用程序只需要一个 Pod,你也应该使用 ReplicationController 创建 Pod。 ReplicationController 类似于进程管理器,但是 ReplicationController 不是监控单个节点上的单个进程,而是监控跨多个节点的多个 Pod。
- 在讨论中,ReplicationController 通常缩写为 “rc”,并作为 kubectl 命令的快捷方式。
- 一个简单的示例是创建一个 ReplicationController 对象来可靠地无限期地运行 Pod 的一个实例。 更复杂的用例是运行一个多副本服务(如 web 服务器)的若干相同副本。
6.2.2 ReplicaSet (RS): 副本控制集,和副本控制器的区别是 : 对控制器的支持
摘自 : https://kubernetes.io/zh/docs/concepts/workloads/controllers/replicaset/#how-a-replicaset-works
ReplicaSet 的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
ReplicaSet 的工作原理:
-
RepicaSet 是通过一组字段来定义的,包括一个用来识别可获得的 Pod 的集合的选择算符、一个用来标明应该维护的副本个数的数值、一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板等等。 每个 ReplicaSet 都通过根据需要创建和 删除 Pod 以使得副本个数达到期望值, 进而实现其存在价值。当 ReplicaSet 需要创建新的 Pod 时,会使用所提供的 Pod 模板。
-
ReplicaSet 通过 Pod 上的 metadata.ownerReferences 字段连接到附属 Pod,该字段给出当前对象的属主资源。 ReplicaSet 所获得的 Pod 都在其 ownerReferences 字段中包含了属主 ReplicaSet 的标识信息。正是通过这一连接,ReplicaSet 知道它所维护的 Pod 集合的状态, 并据此计划其操作行为。
-
ReplicaSet 使用其选择算符来辨识要获得的 Pod 集合。如果某个 Pod 没有 OwnerReference 或者其 OwnerReference 不是一个 控制器,且其匹配到 某 ReplicaSet 的选择算符,则该 Pod 立即被此 ReplicaSet 获得。
何时使用 ReplicaSet
- ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。 然而,Deployment 是一个更高级的概念,它管理 ReplicaSet,并向 Pod 提供声明式的更新以及许多其他有用的功能。 因此,我们建议使用 Deployment 而不是直接使用 ReplicaSet,除非 你需要自定义更新业务流程或根本不需要更新。
- 这实际上意味着,你可能永远不需要操作 ReplicaSet 对象:而是使用 Deployment,并在 spec 部分定义你的应用。
6.2.3 Deployment : 比rs更高级的控制器,除了有rs的功能之外,还有很多高级的功能,比如说最重要的:滚动升级、回滚等
摘自 :https://kubernetes.io/zh/docs/concepts/workloads/controllers/deployment/
一个 Deployment 为 Pods 和 ReplicaSets 提供声明式的更新能力。
你负责描述 Deployment 中的 目标状态,而 Deployment 控制器(Controller) 以受控速率更改实际状态, 使其变为期望状态。你可以定义 Deployment 以创建新的 ReplicaSet,或删除现有 Deployment, 并通过新的 Deployment 收养其资源。
说明: 不要管理 Deployment 所拥有的 ReplicaSet 。 如果存在下面未覆盖的使用场景,请考虑在 Kubernetes 仓库中提出 Issue。
用例:
- 创建 Deployment 以将 ReplicaSet 上线。 ReplicaSet 在后台创建 Pods。 检查 ReplicaSet 的上线状态,查看其是否成功。
- 通过更新 Deployment 的 PodTemplateSpec,声明 Pod 的新状态 。 新的 ReplicaSet 会被创建,Deployment 以受控速率将 Pod 从旧 ReplicaSet 迁移到新 ReplicaSet。 每个新的 ReplicaSet 都会更新 Deployment 的修订版本。
- 如果 Deployment 的当前状态不稳定,回滚到较早的 Deployment 版本。 每次回滚都会更新 Deployment 的修订版本。
- 扩大 Deployment 规模以承担更多负载。
- 暂停 Deployment 以应用对 PodTemplateSpec 所作的多项修改, 然后恢复其执行以启动新的上线版本。
- 使用 Deployment 状态 来判定上线过程是否出现停滞。
- 清理较旧的不再需要的 ReplicaSet 。
6.3 Service
Kubernetes Service 定义了这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector实现的。
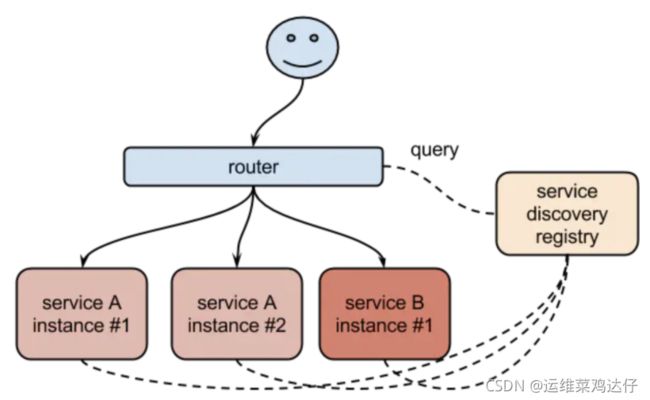
Kubernetes提供了Service对象,它定义了一组Pod的逻辑集合和一个用于访问它们的策略,这个概念和微服务非常类似。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。这样就可以不用去管后端的Pod如何变化,只需要指定Service的地址就可以了,这厮因为我们在中间添加了一层服务发现的中间件,Pod销毁或者重启后,把这个Pod的地址注册到这个服务发现中心去。Service的这种抽象就可以帮我们达到这种解耦的目的
6.4 Volume
摘自:https://kubernetes.io/zh/docs/concepts/storage/volumes/
常见的几种卷:
- emptyDir : 本地临时卷
- hostPath : 本地卷
- nfs等: 共享卷
- configmap : 配置文件
6.4.1 emptyDir
当 Pod 分派到某个 Node 上时,emptyDir 卷会被创建,并且在 Pod 在该节点上运行期间,卷一直存在。 就像其名称表示的那样,卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
说明:
容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃期间 emptyDir 卷中的数据是安全的。
emptyDir 的一些用途:
- 缓存空间,例如基于磁盘的归并排序。
- 为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
- 在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
取决于你的环境,emptyDir 卷存储在该节点所使用的介质上;这里的介质可以是磁盘或 SSD 或网络存储。但是,你可以将 emptyDir.medium 字段设置为 “Memory”,以告诉 Kubernetes 为你挂载 tmpfs(基于 RAM 的文件系统)。 虽然 tmpfs 速度非常快,但是要注意它与磁盘不同。 tmpfs 在节点重启时会被清除,并且你所写入的所有文件都会计入容器的内存消耗,受容器内存限制约束。
6.4.2 hostPath
hostPath 卷能将主机节点文件系统上的文件或目录挂载到你的 Pod 中。 虽然这不是大多数 Pod 需要的,但是它为一些应用程序提供了强大的逃生舱。
hostPath 的一些用法有:
- 运行一个需要访问 Docker 内部机制的容器;可使用 hostPath 挂载 /var/lib/docker 路径。
- 在容器中运行 cAdvisor 时,以 hostPath 方式挂载 /sys。
- 允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在。
除了必需的 path 属性之外,用户可以选择性地为 hostPath 卷指定 type。
6.5 nfs等共享存储
nfs 卷能将 NFS (网络文件系统) 挂载到你的 Pod 中。 不像 emptyDir 那样会在删除 Pod 的同时也会被删除,nfs 卷的内容在删除 Pod 时会被保存,卷只是被卸载。 这意味着 nfs 卷可以被预先填充数据,并且这些数据可以在 Pod 之间共享。
注意: 在使用 NFS 卷之前,你必须运行自己的 NFS 服务器并将目标 share 导出备用。
6.6 configmap
configMap 卷 提供了向 Pod 注入配置数据的方法。 ConfigMap 对象中存储的数据可以被 configMap 类型的卷引用,然后被 Pod 中运行的 容器化应用使用。
引用 configMap 对象时,你可以在 volume 中通过它的名称来引用。 你可以自定义 ConfigMap 中特定条目所要使用的路径。
说明:
- 在使用 ConfigMap 之前你首先要创建它。
- 容器以 subPath 卷挂载方式使用 ConfigMap 时,将无法接收 ConfigMap 的更新。
- 文本数据挂载成文件时采用 UTF-8 字符编码。如果使用其他字符编码形式,可使用 binaryData 字段。
6.7 PersistentVolume(PV)
是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期(pod被删除了,我们的PV依然会被保留,类似于卷)。此 API 对象包含存储实现的细节,即 NFS、iSCSI 或特定于云供应商的存储系统。
pv支持以下类型:
- GCEPersistentDisk
- AWSElasticBlockStore
- NFS
- iSCSI
- RBD (Ceph Block Device)
- Glusterfs
- AzureFile
- AzureDisk
- CephFS
- cinder
- FC
- FlexVolume
- Flocker
- PhotonPersistentDisk
- Quobyte
- VsphereVolume
- HostPath (single node testing only – local storage is not supported in any way and WILL NOT WORK in a multi-node cluster)
6.8 PersistentVolumeClaim(PVC)
PVC 的全称是PersistentVolumeClaim(持久化卷声明),PVC 是用户存储的一种声明,PVC 和 Pod 比较类似,Pod 消耗的是节点,PVC 消耗的是 PV 资源,Pod 可以请求 CPU 和内存,而 PVC 可以请求特定的存储空间和访问模式,例如,可以以读/写一次或 只读多次模式挂载。对于真正使用存储的用户不需要关心底层的存储实现细节,只需要直接使用 PVC 即可。也就是我们集群中会有一个个的PV,可以被直接挂在到某个pod,也可以被PVC绑定,然后挂载到某个pod。
6.9 Statefulset
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
如果希望使用存储卷为工作负载提供持久存储,可以使用 StatefulSet 作为解决方案的一部分。 尽管 StatefulSet 中的单个 Pod 仍可能出现故障, 但持久的 Pod 标识符使得将现有卷与替换已失败 Pod 的新 Pod 相匹配变得更加容易。
使用 StatefulSets
StatefulSets 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和缩放。
- 有序的、自动的滚动更新。
在上面描述中,“稳定的”意味着 Pod 调度或重调度的整个过程是有持久性的。 如果应用程序不需要任何稳定的标识符或有序的部署、删除或伸缩,则应该使用 由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment 或者 ReplicaSet 可能更适用于你的无状态应用部署需要。
限制
- 给定 Pod 的存储必须由 PersistentVolume 驱动 基于所请求的 storage class 来提供,或者由管理员预先提供。
- 删除或者收缩 StatefulSet 并不会删除它关联的存储卷。 这样做是为了保证数据安全,它通常比自动清除 StatefulSet 所有相关的资源更有价值。
- StatefulSet 当前需要无头服务 来负责 Pod 的网络标识。你需要负责创建此服务。
- 当删除 StatefulSets 时,StatefulSet 不提供任何终止 Pod 的保证。 为了实现 StatefulSet 中的 Pod 可以有序地且体面地终止,可以在删除之前将 StatefulSet 缩放为 0。
- 在默认 Pod 管理策略(OrderedReady) 时使用 滚动更新,可能进入需要人工干预 才能修复的损坏状态。
6.10 DaemonSet
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。 一个稍微复杂的用法是为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。